*The original content of GreatSQL community cannot be used without authorization. Please contact Xiaobian and indicate the source for reprint.
*This article is from the contribution: by homework to help the DBA team
1, Architecture requirements:
- Under normal circumstances, the business program of each cloud (APP in the figure below) is written to the local MGR node through the local cetus (the local MGR node is configured as RW through cetus by default at startup); Read requests are routed to MGR nodes of different clouds according to the cetus read / write separation policy
- When the local MGR node fails, cetus will automatically detect the backend MGR node in the configuration and select a new surviving node as the rw node. At this time, the business can read and write across the cloud.
- When a single cloud fails as a whole (single cloud Island), the remaining nodes in the cluster can provide services normally. The business layer needs to cut off the flow and point the business flow to other normal cloud services (APP)

2, Test process
1. Performance test comparison
- The same machine room means that the nodes of sysbench and pressure measurement are in the same machine room; Cross machine room refers to MySQL configured in sysbench and pressure test script_ Host in different computer rooms
- Mainly for Read_Write and Write_Only compare the two modes
Host configuration: 35C 376G MySQL edition: GreatSQL 8.0.25 buffer_pool: 24G test data: sbtest 8 Zhang Biao * 3000w sysbench Pressure test script: - oltp_read_write.lua - oltp_write_only.lua
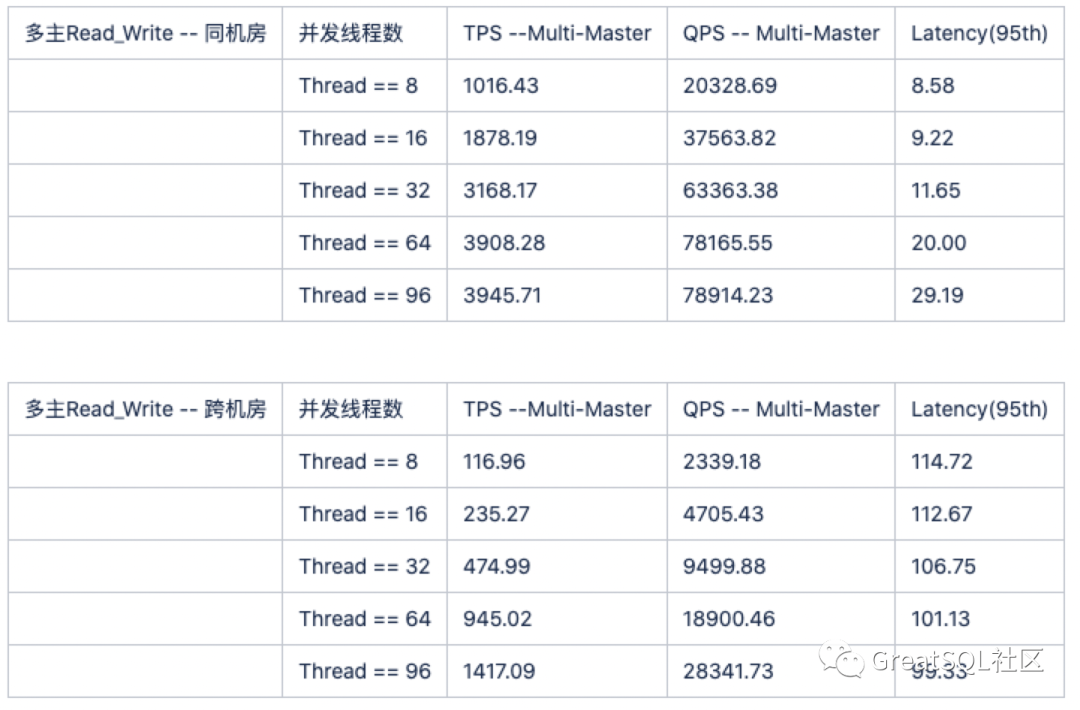
=> Read_ Write pressure measurement comparison
In the case of cross machine room, the cluster throughput decreases significantly and the time consumption increases significantly
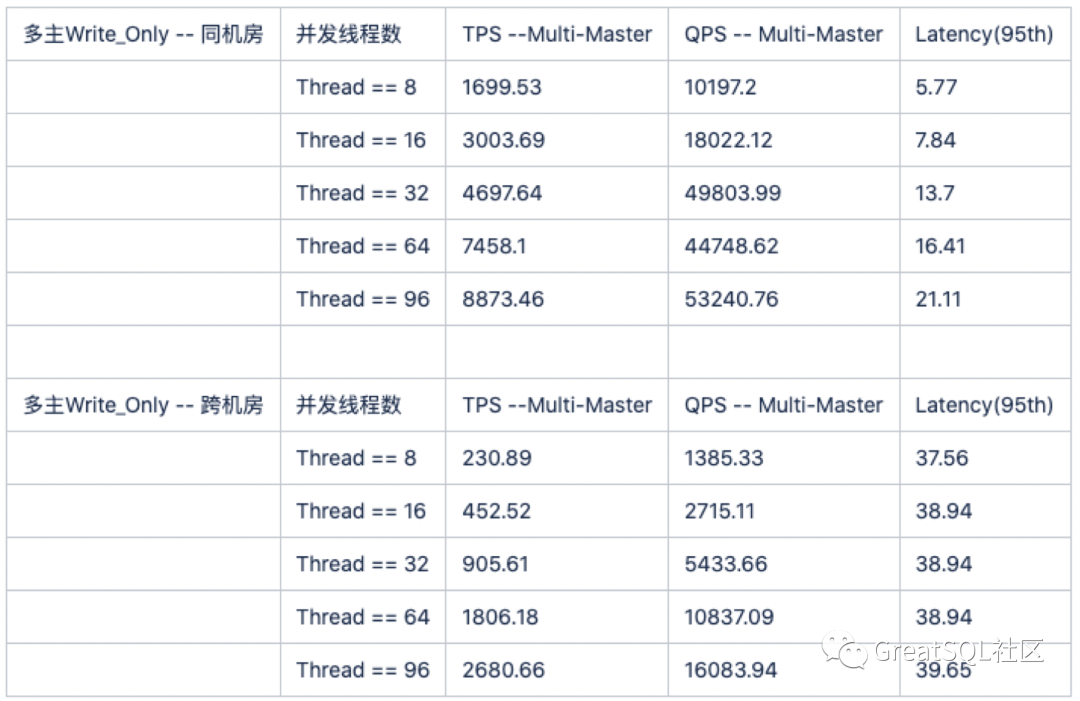
=> Write_ Only pressure measurement comparison
Compared with the same machine room, the time consumption of cross machine room increases by about 20ms
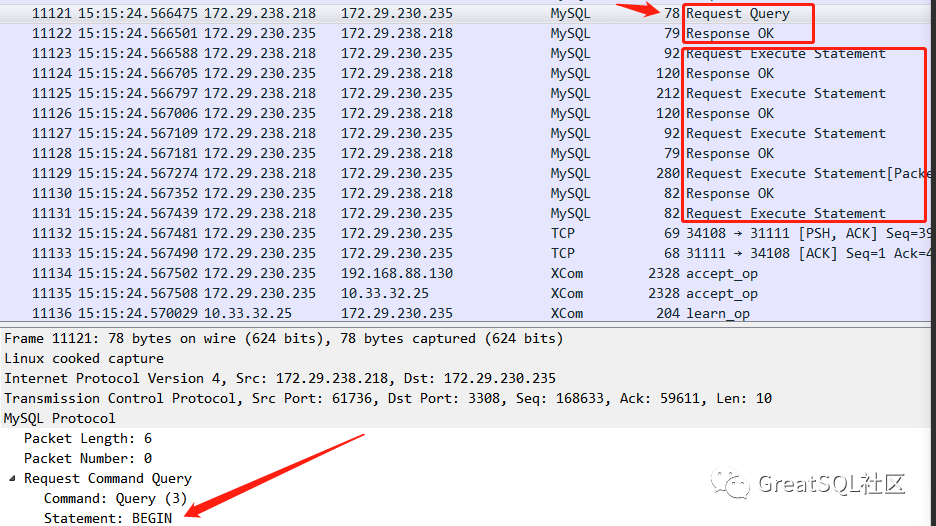
Troubleshooting of high time-consuming under cross machine room:
After packet capture analysis, the transactions in the scripts used in the pressure test are all with begin and commit. Each statement before commit needs to add a rtt delay time (the time between machine rooms is about 3ms).
Therefore, in the case of cross machine rooms, the response time of each transaction will increase at least an additional time (the number of sql in each transaction * 3ms).
2. Fault scenario test
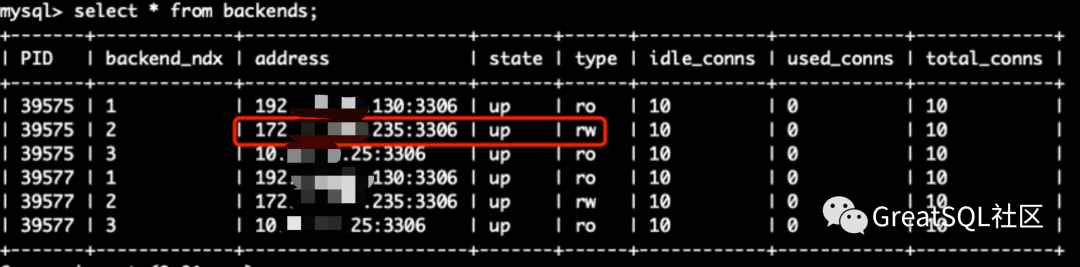
It mainly tests the expected impact on the business in case of single node failure, multi node failure and overall failure of single room, as well as the coping strategies on the DB side. The initial state of the cluster: (3 hosts, one MGR node + cetus node for each host)

The rw node in Cetus is on 172
==>Single instance fault scenario:
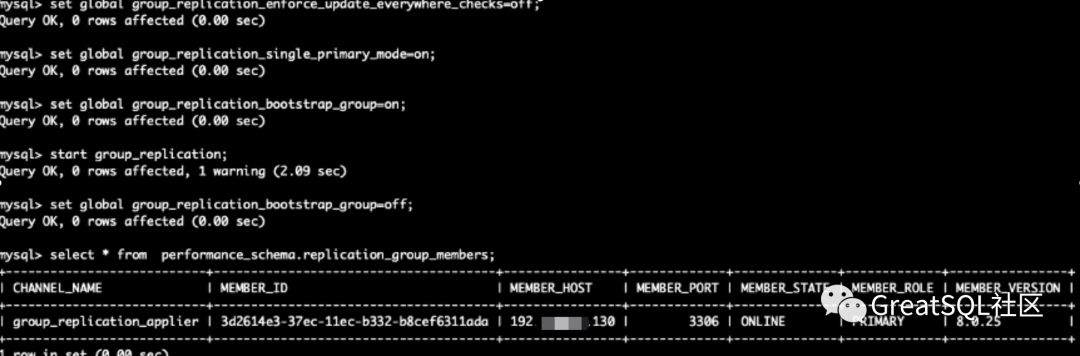
1. After killing 172 instances, observe the cluster status on 192 and 10 instances. 172 is kicked out of the MGR cluster. The rw node in Cetus is switched to 192, and 172 instances are in offline+ro status
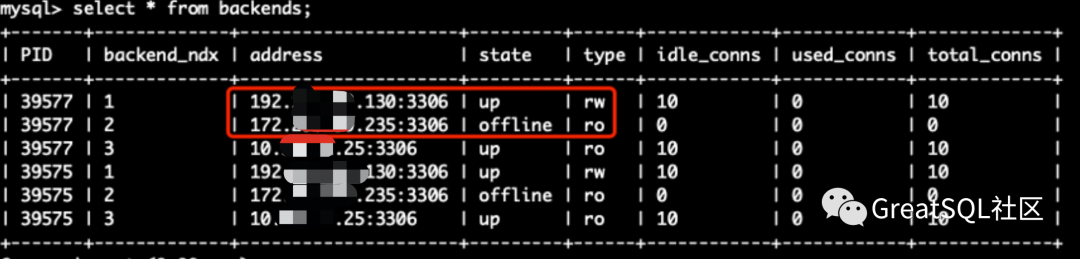
2. Restart 172 instances and start group_replication join replication group

mysql> start group_replication; mysql> select * from information_schema.replication_group_member

Observe the status of the backend in cetus: 172 instances restore the up + ro status
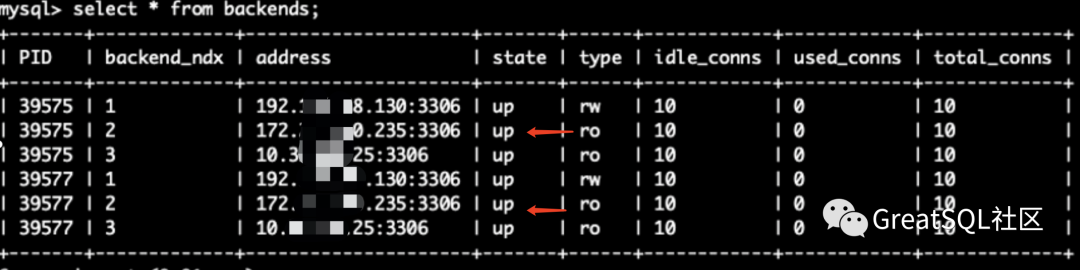
Note: Cetus user has super permission. When the DB instance is restarted, Cetus will try to automatically start group_replication, if start group_replication fails. Cetus will keep trying to restart. It is not recommended to start it
Conclusion: MGR Restart a few instances in the cluster after they are down, start group_replication Automatically join after MGR Cluster and supplement data (if any) binlog Presence), Cetus The instance state in will also be restored to up+ro Problem: if the instance fails before Cetus Zhongwei rw Status, when the instance fails Cetus Medium rw The node will switch to another instance. After the failed instance recovers, the Cetus Zhongwei ro Status, if recovery is required rw Status, manual maintenance required
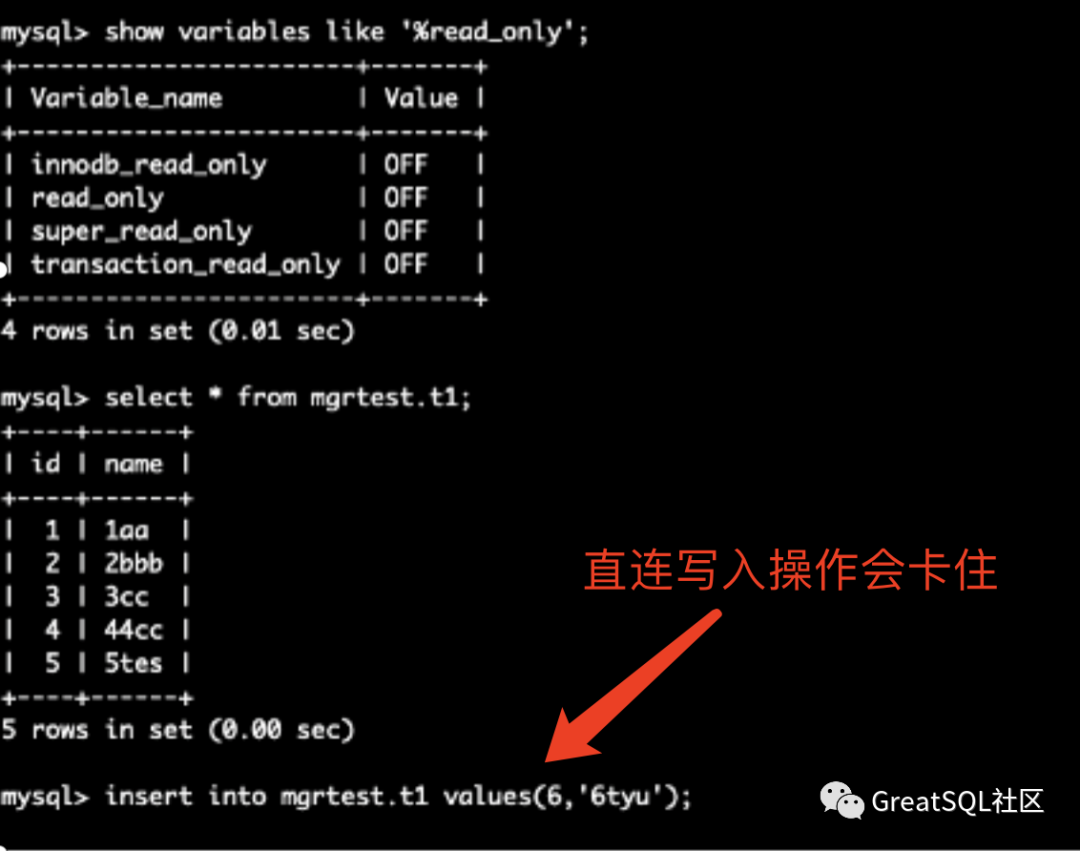
==>Multi instance fault
Kill two instances of 172 and 10. Query the members status on the surviving instance 192. 172 and 10 instances are UNREACHABLE

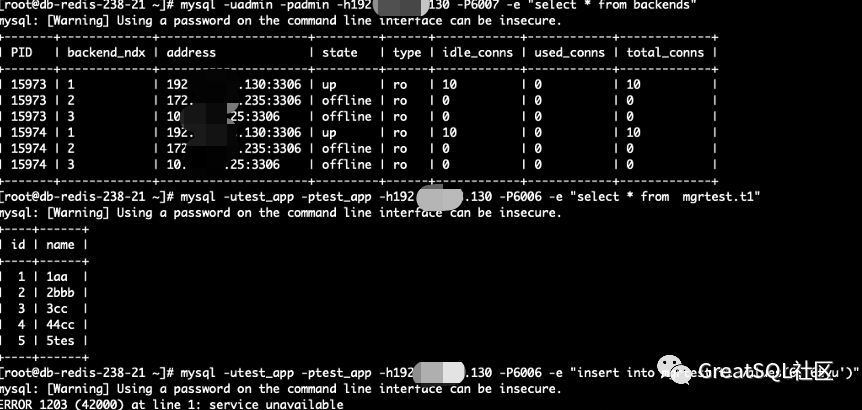
The surviving instance 192 in Cetus is readable but not writable, and the write error service is unavailable
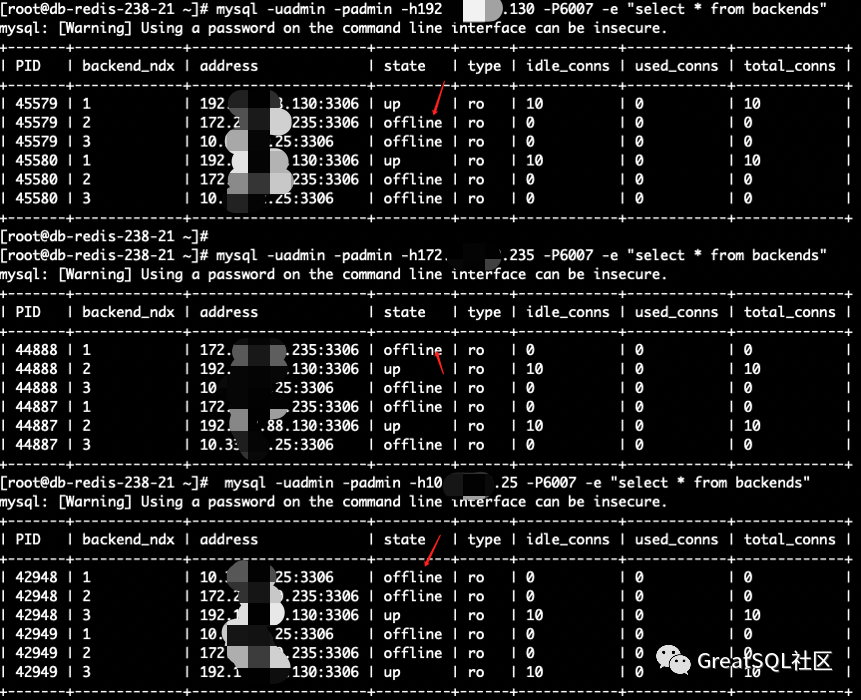
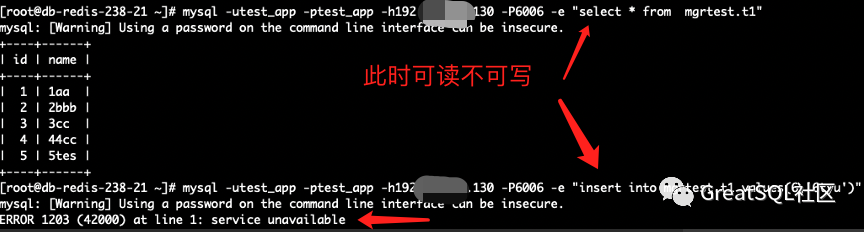
If the direct connection instance is written, hang will die
After restarting 172 and 10 instances, start the group_replication failed. The replication group needs to be rebooted
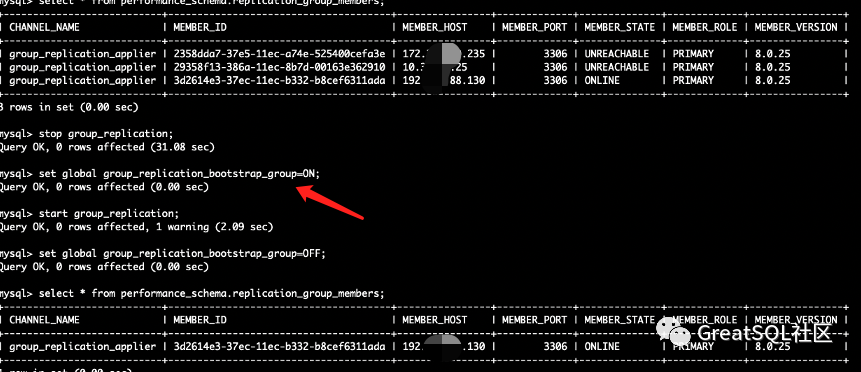
Start group on instances 172 and 10_ Replication joined MGR cluster successfully
Conclusion: MGR Restart most instances in the cluster after they are down, start group_replication Will fail at this time MGR The cluster no longer exists. You need to reinitialize the cluster to add the original instance to the cluster Question: MGR The failure of most instances in the cluster will cause the cluster to crash, and the whole cluster can not be read or written. If the failed instance can be recovered in a short time, it can be reset manually MGR The cluster allows the instance to rejoin the cluster. The non writable time is relatively short and has little impact on the business. If the failed instance cannot be recovered in a short time, a few surviving nodes need to be forcibly activated as new nodes MGR Cluster (single master mode), restore the write capacity, provide services to the business, and then use the surviving node data backup to rebuild DB Restore the new multi master instance MGR colony
==>Single room network isolation
192 instance single cloud network isolation. At this time, when the current business in the cloud reads and writes through cetus on 192, it is readable but not writable, and the write error service is unavailable; The MGR cluster composed of two other nodes can normally provide the status of 192 cetus instances
172 and 10 node MGR cluster status, data writing is normal
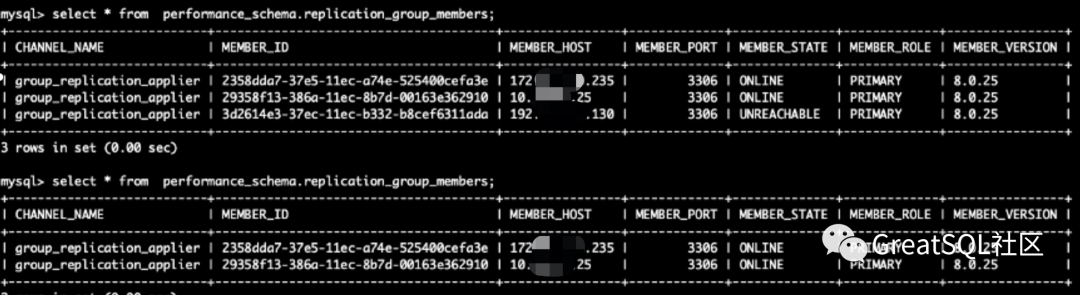
After network recovery, 192 isolated instances automatically join the MGR cluster and supplement the data written by the MGR cluster during network isolation
Problem point: if the main traffic is in the isolated machine room and the upper layer cannot cut to most nodes MGR Cluster, you need to forcibly activate the isolated machine room instance to single instance multi master mode MGR Cluster, restore the write capacity (add an instance later), and the original MGR The cluster will be split into two simultaneously available clusters MGR Cluster (single instance multi master mode with few nodes) MGR Multi instance and multi master mode of cluster and most nodes MGR Cluster) If data is written to both clusters, the subsequent data will conflict or gtid Inconsistent data cannot be merged into one cluster. If you want to merge data later, you'd better do data regression through the business layer
==>Multi machine room network isolation
At this time, if the computer rooms cannot access each other, multiple readable and non writable instances will be formed
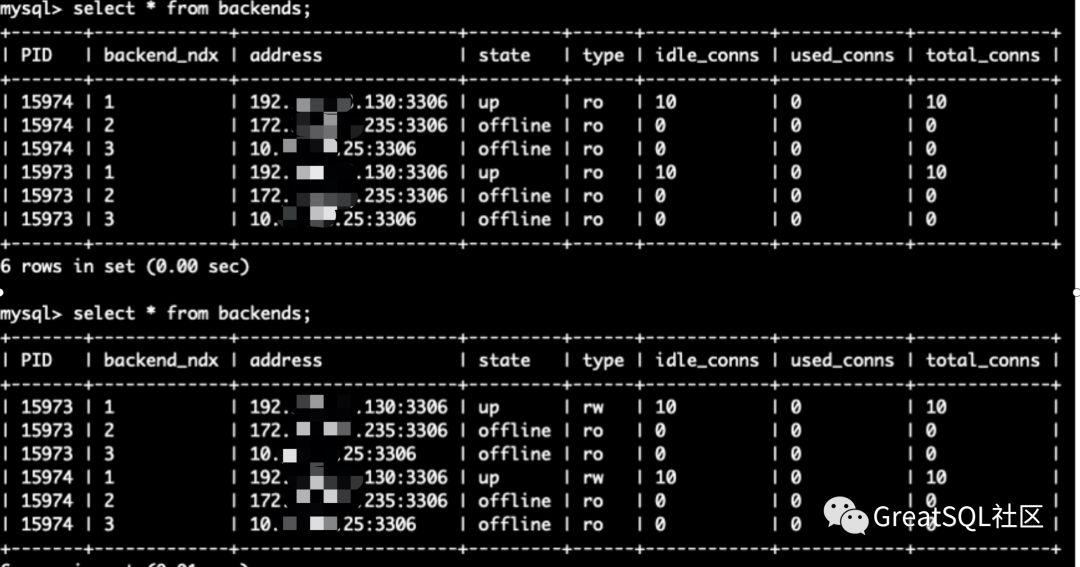
- The network cannot be restored in a short time. It is necessary to forcibly activate an instance to restore the read-write ability. Observe that the other two nodes on 192 become UNREACHABLE
192 instances in Cetus are restored from up+ro to up+rw
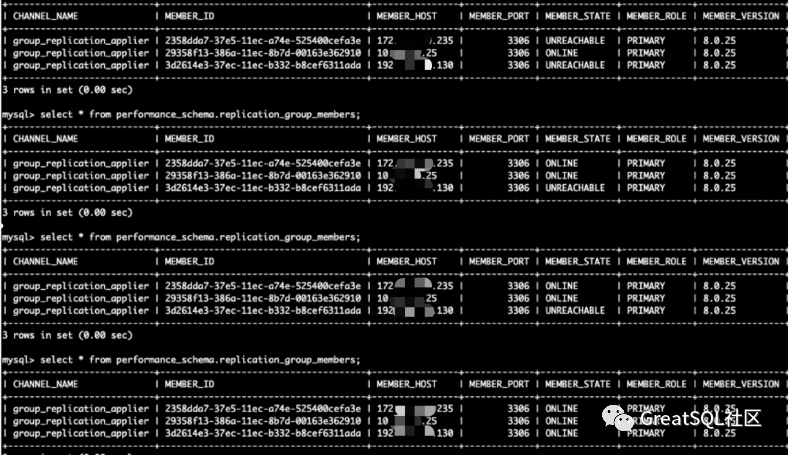
- The network jitter between machine rooms will be restored automatically by MGR cluster as the network recovers
It can withstand the jitter time and can not be read or written. It is not necessary to forcibly activate the node to restore the write capacity. After the network is restored, the MGR cluster will recover automatically
Test summary:
The current test mainly combines CETUS To meet our business needs in various scenarios. Different businesses of different companies have different forms. Using other proxy When testing,Note the expected status of the business under various scenarios. - For example, in single cloud isolation,Do businesses in the isolated cloud want to continue reading data or are they unreadable and writable; - Allow cross cloud access,What is the acceptable time-consuming range? The above needs to be used proxy Or other plug-in means to set different read-write policies. Overall test down MGR The performance of multi master mode and fault handling meet our needs.
Enjoy GreatSQL :)