converter
Most machine learning algorithms are easier to deal with numbers, so let's turn these texts into numbers first. sklearn provides a converter for such tasks.
Data to convert
# Load Library
import os
import tarfile
import pandas as pd
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
# Load data
def load_housing_data(housing_path=HOUSING_PATH):
csv_path=os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
housing.head() # View the first five lines of information
housing_cat = housing[['ocean_proximity']]
housing_cat.head(10)
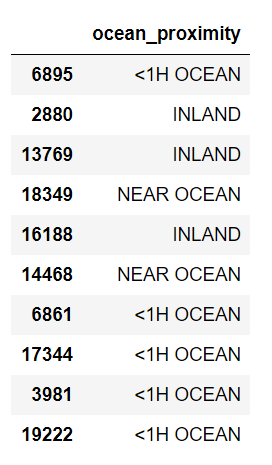
Text information is' < 1H ocean ',' Outland ',' ISLAND ',' NEAR BAY ',' NEAR OCEAN ', which shall be converted into digital information. Multiple ideas:
- Ordinary encoder converter: directly convert '< 1H ocean', 'Outland', 'ISLAND', 'NEAR BAY', 'NEAR BAY'
'OCEAN' corresponds to numbers 1, 2, 3, 4, 5. Output as a column. - One hot transcoder: '< 1H ocean', 'Outland', 'ISLAND', 'NEAR BAY', 'NEAR BAY'
OCEAN 'is a Boolean quantity divided into 5 columns. For example, the 13769 line 'Insert' corresponds to 0,1,0,0,0.
Ordinary encoder
#Set ocean_ Convert text of proximity to numbers from sklearn.preprocessing import OrdinalEncoder #Common Encoder ordinal_encoder = OrdinalEncoder() housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) housing_cat_encoded[:10] #View ocean_ Category of text for proximity print(ordinal_encoder.categories_)
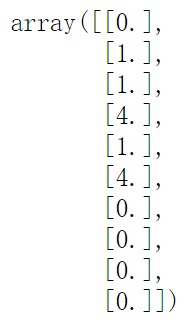
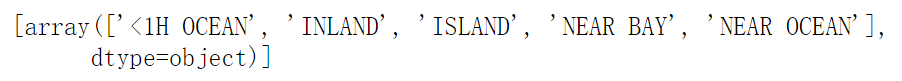
Disadvantages: the computer will think that two similar numbers are more similar than those far away. However, this is not the case. The similarity between 0 and 4 may be higher than that between 0 and 1
One hot encoder
Return sparse matrix
from sklearn.preprocessing import OneHotEncoder #OneHot encoder cat_encoder = OneHotEncoder() housing_cat_1hot = cat_encoder.fit_transform(housing_cat) housing_cat_1hot #View ocean_ Category of text for proximity cat_encoder.categories_ # By default, when returning, the sparse matrix only stores the position of non-0 value elements, saves memory, and is converted to Numpy array for display housing_cat_1hot.toarray()

Returns a two-dimensional matrix
from sklearn.preprocessing import OneHotEncoder #OneHot encoder # Specify sparse=False to return a two-dimensional matrix instead of a sparse matrix cat_encoder = OneHotEncoder(sparse=False) housing_cat_1hot = cat_encoder.fit_transform(housing_cat) housing_cat_1hot #View ocean_ Category of text for proximity cat_encoder.categories_

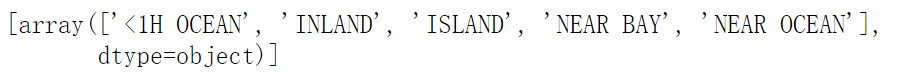
Custom converter
Use custom converters to add feature rooms_per_household population_per_household
Custom function: remove the medium_ housing_ value; Added rooms_per_household population_per_household two columns
Processing object: partial housing columns

BaseEstimator& TransformerMixin
Hard code (hard coding in English): it means that in software implementation, the output or input related parameters (such as path, output form and format) are directly written in the original code, rather than making appropriate response to the settings, resources, data or format specified by the outside world during execution.
def init: Define a class
The init() method is called by default when creating an object and does not need to be called manually
In init(self), there is one parameter named self by default
init(self,x,y) passes two arguments when creating an object, then__ init__ In (self), self is listed as the first formal parameter, and two formal parameters are required
The self parameter in init(self) does not need to be passed by the developer. The python interpreter will automatically pass in the current object reference
#Converter 1
from sklearn.base import BaseEstimator, TransformerMixin
#Converter 1
from sklearn.base import BaseEstimator, TransformerMixin
# get the right column indices: safer than hard-coding indices 3, 4, 5, 6
#Get the data to be calculated
rooms_ix, bedrooms_ix, population_ix, household_ix = [
list(housing.columns).index(col)
for col in ("total_rooms", "total_bedrooms", "population", "households")]
class CombinedAttributesAdder(BaseEstimator, TransformerMixin): #Combined attribute adder
def __init__(self, add_bedrooms_per_room = True): # no *args or **kwargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household, #Pair array array1 with array array2 and output
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
#Converter 2
from sklearn.preprocessing import FunctionTransformer
def add_extra_features(X, add_bedrooms_per_room=True): #Add other characteristic functions add_bedrooms_per_room logo
rooms_per_household = X[:, rooms_ix] / X[:, household_ix] #Number of rooms per household
population_per_household = X[:, population_ix] / X[:, household_ix] #Number of people per household
if add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix] #Proportion of bedrooms in the room
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = FunctionTransformer(add_extra_features, #Parameter func: user defined functions and other features added
validate=False, #validate: bool quantity, default=False, input validation off
kw_args={"add_bedrooms_per_room": False}) #kw_argsdict, default=None Dictionary of additional keyword parameters to pass to func.
housing_extra_attribs = attr_adder.fit_transform(housing.values)
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()
Before conversion
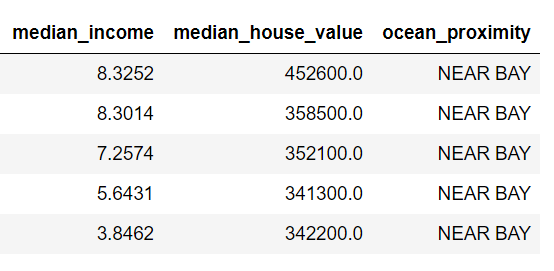
After conversion
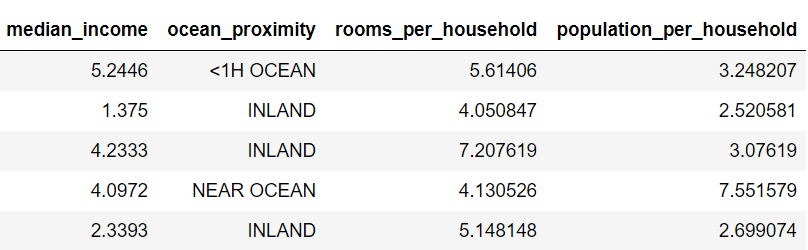
The converted IDs are not in order
median_ Neither income nor its previous columns have changed
github source code
Thank you guys!