K-Nearest Neighbor Classification Algorithm Case
My friend Helen has been using the online dating website to find the right person for her. Although dating websites recommend different people, she doesn't find anyone she likes. After some summary, she found that she has met three types of people: "people who don't like it", "people who are charming" and "people who are very charming". Despite finding these patterns, Helen still can't categorize the matches recommended by dating websites appropriately. She feels that she can date the most attractive people from Monday to Friday, while she prefers to spend the weekend with the most attractive people. Helen wants our categorization software to better help her categorize matches into exact categories. Helen also collects data that dating websites haven't recorded, which she believes will help her categorize matches better.
1. Data preparation
Helen has been collecting dating data for some time, and she keeps it in a text file dating TestSet. In the txt, each sample takes up one row, with a total of 106 Helen samples featuring three main features:'Flight frequent miles per year','Percentage of time spent playing video Games'and'Ice cream liters consumed per week'.
2. Data Preprocessing
Due to inconsistent dimensions of data attributes, normalization is required.
3. Data Modeling
Under the guidance of classification accuracy criterion, the optimal parameter k is determined by ten-fold cross-validation.
4. Model prediction
Now that we've tested the classifier on our data, we can finally use it to classify people for Helen. We'll give Helen a little program where she finds someone on the dating website and enters his information. The program gives her a prediction of how much she likes her partner.
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
df=pd.read_csv("datingTestSet.txt",sep="\t",names=['flight','ice','game','type'])
features=df.drop(columns=['type'],axis=0)
targets=df['type']
X_train,X_test,y_train,y_test=train_test_split(features,targets,test_size=0.25,random_state=2022)
#Standardization
scaler=StandardScaler()
X_train=scaler.fit_transform(X_train)
X_test=scaler.fit_transform(X_test)
# Combining K-fold cross-validation with learning curve to obtain optimal K-value
scores_cross = []
Ks = []
for k in range(3, 20):
knn = KNeighborsClassifier(n_neighbors=k) # Instantiate Model Object
score_cross = cross_val_score(knn, X_train, y_train, cv=6).mean() # Cross-validation based on training data and return the score of cross-validation
scores_cross.append(score_cross)
Ks.append(k)
# Convert to Array Type
scores_arr = np.array(scores_cross)
Ks_arr = np.array(Ks)
# Draw learning curve
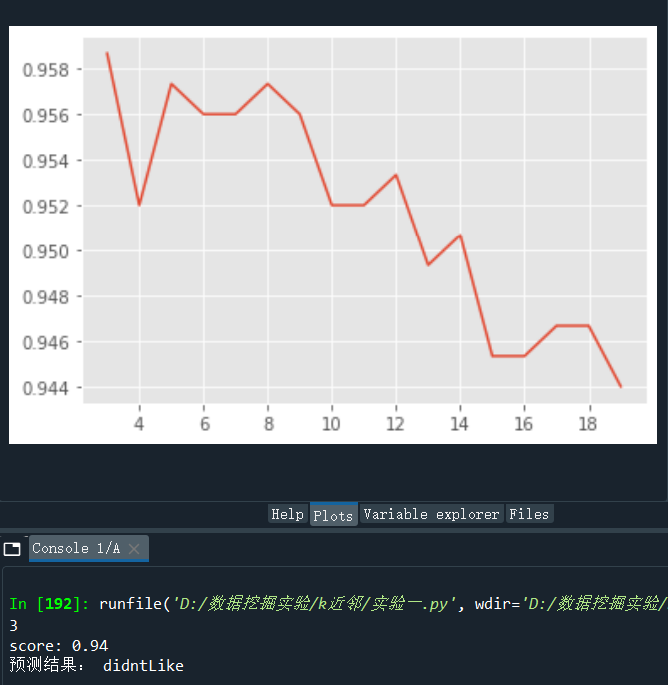
plt.plot(Ks, scores_cross)
plt.show()
# Get the highest score and the array subscript corresponding to the highest score to get the optimal K value
score_best = scores_arr.max() # Find the highest score in the array of stored scores
index_best = scores_arr.argmax() # Find the subscript corresponding to the highest score in array
Ks_best = Ks_arr[index_best] # Find the K value corresponding to the highest score based on the subscript
print(Ks_best)
# The optimal K value found by the combination of K-fold cross validation and learning curve is used to instantiate the model object
knn=KNeighborsClassifier(n_neighbors=Ks_best)
knn.fit(X_train,y_train)
score=knn.score(X_test,y_test)
print("score:",score)
dscore=knn.predict([[40000,10,0.5]])
print("Forecast results:",dscore[0])
Handwriting recognition is a common image recognition task. Computers recognize characters in pictures by handwriting pictures. Unlike typefaces, handwriting styles and sizes vary from person to person, making it difficult for computers to recognize handwriting. Digital handwriting recognition has become a relatively simple handwriting recognition task due to its limited categories (0~9 of 10 numbers).
1. Data preparation
There are 204 txt files in the file "trainingDigits" folder of the compressed file "digits.zip", each of which corresponds to one of the numbers "1-9" (processed as a 0-1 digital matrix of 3232), as shown below. Read this 204 file and convert the data in each file into 1024-dimensional row vectors for training set. Note: Take "0_2.txt" as an example, where 0 in the file name represents the corresponding number 0 for this file, that is, the class label for this data vector is 2. Tip: Get all the files in the current folder using from os import listdir, convert them to vectors, and use the split("") of the string [0] Method gets the class label of each data.
2. Model building
The optimal number of neighbors K is selected by cross-validation.
3. Forecast classification
Reads all the data files in the folder testDigits in "digits.zip", vectorizes them using the above methods, and predicts them using the built model.
4. Model evaluation
What is the prediction classification accuracy of the model?
from os import listdir
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
name1=listdir('digits/trainingDigits')
name2=listdir('digits/testDigits')
train_data=[]
train_label=[]
test_data=[]
test_label=[]
for name in name1:
label=int(name.split("_")[0])
train_label.append(label)
Vect = np.zeros((1, 1024))
fr = open("./digits/trainingDigits/{}".format(name))
for i in range(32):
lineStr = fr.readline()
for j in range(32):
Vect[0, 32*i+j] = int(lineStr[j])
train_data.append(list(Vect[0]))
for name in name2:
label=int(name.split("_")[0])
test_label.append(label)
Vect = np.zeros((1, 1024))
fr = open("./digits/trainingDigits/{}".format(name))
for i in range(32):
lineStr = fr.readline()
for j in range(32):
Vect[0, 32*i+j] = int(lineStr[j])
test_data.append(list(Vect[0]))
train_data=np.array(train_data)
test_data=np.array(test_data)
# Combining K-fold cross-validation with learning curve to obtain optimal K-value
scores_cross = []
Ks = []
for k in range(3, 20):
knn = KNeighborsClassifier(n_neighbors=k) # Instantiate Model Object
score_cross = cross_val_score(knn, train_data, train_label, cv=6).mean() # Cross-validation based on training data and return the score of cross-validation
scores_cross.append(score_cross)
Ks.append(k)
# Convert to Array Type
scores_arr = np.array(scores_cross)
Ks_arr = np.array(Ks)
# learning curve
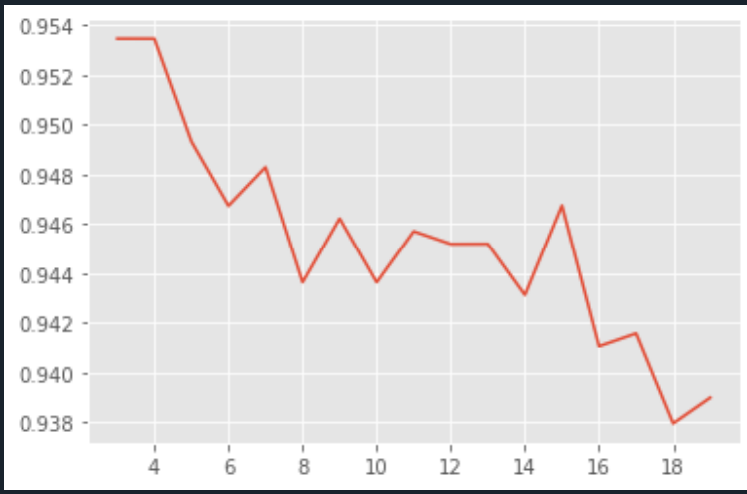
plt.plot(Ks, scores_cross)
plt.show()
# Get the highest score and the array subscript corresponding to the highest score to get the optimal K value
score_best = scores_arr.max() # Find the highest score in the array of stored scores
index_best = scores_arr.argmax() # Find the subscript corresponding to the highest score in array
Ks_best = Ks_arr[index_best] # Find the K value corresponding to the highest score based on the subscript
print(Ks_best)
#model training
knn=KNeighborsClassifier(n_neighbors=Ks_best)
knn.fit(train_data,train_label)
score=knn.score(test_data,test_label)
print("score:",score)
#Scoring curve
import matplotlib.pyplot as plt
k_range = range(1, 51)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(train_data,train_label)
score=knn.score(test_data,test_label)
k_scores.append(score)
plt.plot(k_range, k_scores)
plt.xlabel('Vlaue of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
Also attached is image processing, because our data is processed txt, the real data is png pictures
from PIL import Image
import matplotlib.pylab as plt
import numpy as np
def picTo01(filename):
#Read pictures
img=Image.open(filename).convert('RGBA')
raw_data=img.load()
#Noise reduction based on the RGB value of the picture
for y in range(img.size[1]):
for x in range(img.size[0]):
if raw_data[x,y][0]<90:
raw_data[x,y]=(0,0,0,255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if raw_data[x,y][1]<136:
raw_data[x,y]=(0,0,0,255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if raw_data[x,y][2]>0:
raw_data[x,y]=(255,255,255,255)
# Convert pictures to 32x32
img=img.resize((32,32),Image.LANCZOS)
#Save the processed pictures for easy comparison
img.save('test'+filename.split('.')[0]+'.png')
#Make the black part of the picture 1 and the white part 0 according to the formula
array=plt.array(img)
gray_array=np.zeros((32,32))
for x in range(array.shape[0]):
for y in range(array.shape[1]):
gray=0.299*array[x][y][0]+0.587 * array[x][y][1] + 0.114 * array[x][y][2]
#white
if gray==255:
gray_array[x][y]=0
#black
else:
gray_array[x][y]=1
#Name the txt file this number and save it
name01=filename.split('.')[0]
name01=name01+'.txt'
np.savetxt(name01,gray_array,fmt='%d',delimiter='')
picTo01('./png/0_03.png')
# import os.path
# import numpy as np
# #Convert 32*32 to 1*1024
# def img32to1024(filename):
# returnVect=np.zeros((1,1024))
# fr=open(filename,'r')
# for i in range(32):
# lineStr=fr.readline()
# for j in range(32):
# returnVect[0,32*i+j]=int(lineStr[j])
# return returnVect
# #Collate train data and labels (file name label)
# hwLabels=[]
# trainingFileList=os.listdir('png')
# m=len(trainingFileList)
# trainingMat=np.zeros((m,1024))
# for i in range(m):
# fileNameStr=trainingFileList[i]
# fileStr=fileNameStr.split('.')[0]
# classNumStr=int(fileStr.split('_')[0])
# hwLabels.append(classNumStr)
# trainingMat[i,:]=img32to1024('trainingDigits/%s' % fileNameStr)
# import os.path
# import numpy as np
# import train as tr
# def classify(inX,k):
# dataSetSize=tr.m
# diffMat=inX-tr.trainingMat
# sqDiffMat=diffMat**2
# sqDistances=sqDiffMat.sum(axis=1)
# distances=sqDistances**0.5
# #get the rank
# sortedDistances=distances.argsort()
# classCount={}
# for i in range(k):
# voteIlabel=tr.hwLabels[sortedDistances[i]]
# classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
# sortedClassCount=sorted(classCount.items(),reverse=True)
# return sortedClassCount[0][0]