K8s design mode
Kubernetes is a container choreography tool with universal significance. It provides a set of basic dependencies for building distributed systems based on containers. Its significance is equivalent to the position of Linux in the operating system, which can be considered as a distributed operating system.
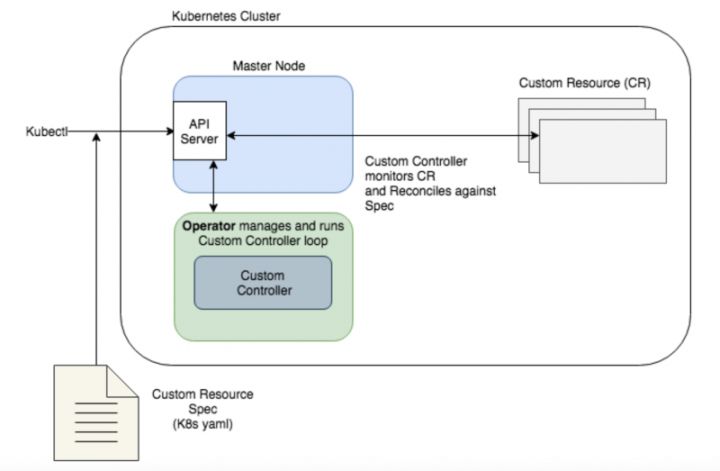
Custom resources
K8s provides a series of basic resource definitions such as Pod, Service and Volume. In order to provide better scalability, CRD function was introduced in version 1.7.
Users can add customized Kubernetes object resources (CRD s) according to their own needs. It is worth noting that the Kubernetes object resources added by users here are all native, first-class citizens, and the same object resources as the native Pod and Deployment in Kubernetes. According to Kubernetes' API Server, they are first-class resources existing in etcd. At the same time, user-defined resources, like native built-in resources, can be created and viewed with kubectl, and also enjoy RBAC and security functions. Users can develop custom controllers to sense or operate the changes of custom resources.
Operator
On the basis of user-defined resources, K8s Operator provides the corresponding development framework for how to realize the logical behavior when creating or updating user-defined resources. By extending Kubernetes, the Operator defines the Custom Controller and the custom resources corresponding to list/watch, and triggers the custom logic when the corresponding resources change.
Operator developers can define the expected end state of a group of business applications in a declarative way like using the native API for application management, and write the corresponding controller logic according to the characteristics of the business application, so as to complete the management of the application runtime life cycle and continuously maintain the consistency with the expected end state.
Popular understanding
CRD is K8s's standardized resource expansion capability. Taking java as an example, int, long, Map and Object are built-in classes in java. Users can customize the Class to realize Class expansion. CRD is the user-defined Class in K8s, and CR is an instance of the corresponding Class.
Operator mode = user-defined class + observer mode. Operator mode makes it very simple and fast for everyone to write K8s extensions, and gradually becomes the standard for K8s design.
The Operator provides a standardized design process:
- Create a new Operator project using SDK
- Define a new resource API by adding a custom resource (CRD)
- Specify the resources to use SDK API to watch
- The custom Controller implements K8s reconcile logic
With a hammer, all you see is nails
Our team (KubeOne team) has been working on how to deploy complex middleware applications to K8s. Naturally, it is also a practitioner of the Operator model. After nearly two years of development, the deployment of Middleware in K8s in various environments has been preliminarily solved. At present, there are many detours and pits in the middle.
KubeOne kernel has also undergone three major versions of iterations. The first two development processes are basically developed and designed according to the standard development process of follow Operator. Following a standard and typical Operator design process, everything seems to be so perfect, but every design is very painful. After practicing the Operator model, the most worthy of reflection and reference is "with a hammer, only nails can be seen". To sum up, there are four things:
- All designs are yaml
- Everything is one
- Everything is final
- All interactions are complete
Myth 1 all designs are yaml
The API of K8s is in yaml format, and the design process of Operator also allows you to define crd first, so the team directly adopted yaml format when starting design.
case
According to the standardized process, the team's design process for yaml is generally as follows:
- First, sort out a large and comprehensive yaml according to the known data and make a preliminary classification. For example, the application probably includes basic information, dependent services, operation and maintenance logic, monitoring and collection, etc. each classification is made into a sub part
- Meeting to discuss whether the specific content can meet the requirements, as a result, it is difficult to reach a consensus in each meeting
- Because there are always new needs that can not be met, when discussing A, someone mentioned B, C and D, and there are new needs constantly
- The properties of each part are very difficult to unify, because different implementation properties are quite different
- Different understanding, the same name, but everyone has different understanding when using it
- Due to the tight construction period, we can only make a temporary compromise and make an intermediate state, which will be further optimized later
- For subsequent optimization and upgrading, it is still difficult to reach a consensus when the same process is repeated
This is the second version of the design:
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "A"
name: A-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: A //chart-name
version: 1.0 //chart-version
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
workloadSettings: //Note: workload settings identifies the attribute that type should use
- name: "deployToK8SName"
value: ""
- name: "deployToNamespace"
value: ${resources:namespace-resource.name}
parameterValues: //Note parameterValues identifies business attributes
- name: "enableTenant"
value: "1"
- name: "CPU"
value: "1"
- name: "MEM"
value: "2Gi"
- name: "jvm"
value: "flag;gc"
- name: vip.fileserver-edas.ip
value: ${resources:fileserver_edas.ip}
- name: DB_NAME
valueFromConfigMap:
name: ${resources:rds-resource.cm-name}
expr: ${database}
- name: DB_PASSWORD
valueFromSecret:
name: ${instancename}-rds-secret
expr: ${password}
- name: object-storage-endpoint
value: ${resources:object-storage.endpoint}
- name: object-storage-username
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${username}
- name: object-storage-password
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${password}
- name: redis-endpoint
value: ${resources:redis.endpoint}
- name: redis-password
value: ${resources:redis.password}
resources:
- name: tolerations
type: apps.mwops.alibaba-inc.com/tolerations
parameterValues:
- name: key
value: "sigma.ali/is-ecs"
- name: key
value: "sigma.ali/resource-pool"
- name: namespace-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.namespace
parameterValues:
- name: name
value: edas
- name: fileserver-edas
type: apps.mwops.alibaba-inc.com/v1alpha1.database.vip
parameterValues:
- name: port
value: 21,80,8080,5000
- name: src_port
value: 21,80,8080,5000
- name: type
value: ClusterIP
- name: check_type
value: ""
- name: uri
value: ""
- name: ip
value: ""
- name: test-db
type: apps.mwops.alibaba-inc.com/v1alpha1.database.mysqlha
parameterValues:
- name: name
value: test-db
- name: user
value: test-user
- name: password
value: test-passwd
- name: secret
value: test-db-mysqlha-secret
- name: service-slb
type: apps.mwops.alibaba-inc.com/v1alpha1.slb
mode: post-create
parameterValues:
- name: service
value: "serviceA"
- name: annotations
value: "app:a,version:1.0"
- name: external-ip
value:
- name: service-resource2
type: apps.mwops.alibaba-inc.com/v1alpha1.service
parameterValues:
- name: second-domain
value: edas.console
- name: ports
value: "80:80"
- name: selectors
value: "app:a,version:1.0"
- name: type
value: "loadbalance"
- name: service-dns
type: apps.mwops.alibaba-inc.com/v1alpha1.dns
parameterValues:
- name: domain
value: edas.server.${global:domain}
- name: vip
value: ${resources:service-resource2.EXTERNAL-IP}
- name: dns-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.dns
parameterValues:
- name: domain
value: edas.console.${global:domain}
- name: vip
value: "127.0.0.1"
- name: cni-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.cni
parameterValues:
- name: count
value: 4
- name: ip_list
value:
- name: object-storage
type: apps.mwops.alibaba-inc.com/v1alpha1.objectStorage.minio
parameterValues:
- name: namespace
value: test-ns
- name: username
value: test-user
- name: password
value: test-password
- name: storage-capacity
value: 20Gi
- name: secret-name
value: minio-my-store-access-keys
- name: endpoint
value: minio-instance-external-service
- name: redis
type: apps.mwops.alibaba-inc.com/v1alpha1.database.redis
parameterValues:
- name: cpu
value: 500m
- name: memory
value: 128Mi
- name: password
value: i_am_a_password
- name: storage-capacity
value: 20Gi
- name: endpoint
value: redis-redis-cluster
- name: accesskey
type: apps.mwops.alibaba-inc.com/v1alpha1.accesskey
parameterValues:
- name: name
value: default
- name: userName
value: ecs_test@aliyun.com
exposes:
- name: dns
value: ${resources:dns-resource.domain}
- name: db-endpoint
valueFromConfigmap:
name: ${resources:rds-resource.cm-name}
expr: ${endpoint}:3306/${database}
- name: ip_list
value: ${resources:cni-resource.ip_list}
- name: object-storage-endpoint
value: ${resources:object-storage.endpoint}.${resource:namespace-resource.name}
- name: object-storage-username
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${username}
- name: object-storage-password
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${password}
- name: redis-endpoint
value: ${resources:redis.endpoint}.${resource:namespace-resource.name}
- name: redis-password
value: ${resources:redis.password}reflect
Such pain is difficult to express in words. I feel that everything is out of control. There is no unified judgment standard and design standard. The public says that the public is reasonable and the woman says that the woman is reasonable. The content has been added and the field has been changed. No more than three times, during the third design, we collectively discussed and reflected on why it was so difficult to reach a consensus? Why does everyone understand differently? Why is it always changing?
Only UML, the most efficient design language, has experienced the test of object-oriented design, and only the most mature design language is yaml.
From the huge yaml above, we can understand the complexity of our design, but this is not the most painful. The most painful thing is that we abandoned the original design process and design language and tried to use an open Map to describe everything. When there is no object or relationship in the design, there is only one attribute in the Map, so it doesn't matter whether it's right or wrong, or whether it's good or bad. In the end, it was just another field to fight for loneliness.
Scope of application
Is it wrong for the Operator to design CRD first and then develop controller?
Answer: partially correct
Applicable scenario
Like Java Class, simple objects do not need to go through complex design processes. Designing yaml directly is simple and efficient.
Not applicable scenario
When designing a complex system, such as application management, including multiple objects, complex relationships between objects and complex user stories, UML and object-oriented design are very important.
Only UML and domain language are considered in the design. After the design is completed, CRD can be regarded as java Class or database table structure, which is only an option when it is finally implemented. Moreover, many objects do not need to be persistent, nor do they need to trigger the corresponding logic through the Operator mechanism, so there is no need to design a CRD, but directly implement a controller.
Yaml is a formatted expression of interface or Class declaration. Conventional yaml should be as small as possible, as single as possible and as abstract as possible. Complex yaml is an arrangement result of simple CRD resources, which provides a similar one-stop resource matching scheme.
In the third version and PAAS core design, we adopted the following process:
- UML use case diagram
- Sort out user stories
- Align domain objects based on user stories to determine key business objects and relationships between objects
- For objects that need Operator, each object is described as a CRD. Of course, CRD lacks object-oriented capabilities such as interface and inheritance, and can be expressed by curves in other ways
- For objects that do not require Operator, write the Controller directly
Myth 2 everything is one
In order to ensure the final state of an application, or to manage an application using gitops, should the application related content be put into a CRD or an IAC file? According to the design of gitops, the whole document needs to be distributed every time it is changed?
case
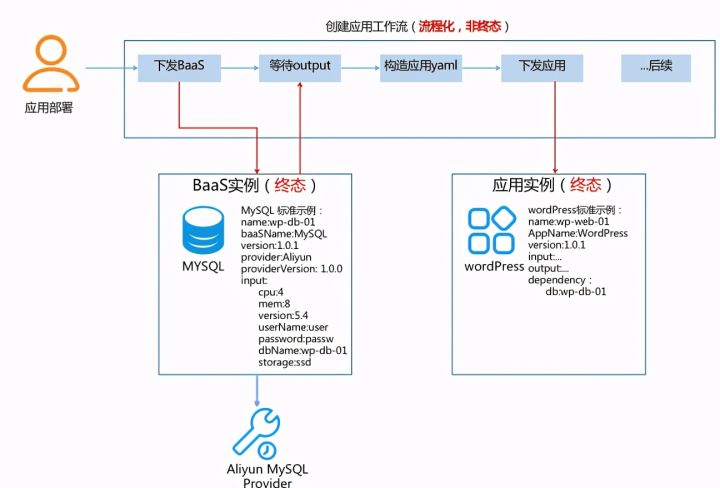
Case 1: the application of WordPress needs to rely on a MySQL. How to define the final state?
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "WordPress"
name: WordPress-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: WordPress //chart-name
version: 1.0 //chart-version
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
parameterValues: //Note parameterValues identifies business attributes
- name: "enableTenant"
value: "1"
- name: "CPU"
value: "1"
- name: "MEM"
value: "2Gi"
- name: "jvm"
value: "flag;gc"
- name: replicas
value: 3
- name: connectstring
valueFromConfigMap:
name: ${resources:test-db.exposes.connectstring}
expr: ${connectstring}
- name: db_user_name
valueFromSecret:
....
resources:
- name: test-db //Create a new DB
type: apps.mwops.alibaba-inc.com/v1alpha1.database.mysqlha
parameterValues:
- name: cpu
value: 2
- name: memory
value: 4G
- name: storage
value: 20Gi
- name: username
value: myusername
- name: password
value: i_am_a_password
- name: dbname
value: wordPress
exposes:
- name: connectstring
- name: username
- name: password
exposes:
- name: dns
value: ...Is the code above the final state of the wordPress application? This file contains the definition of DB and application required by the application. As long as it is distributed once, the corresponding database can be created first, and then the application can be pulled up.
Case 2: during each change, some contents of the whole yaml are modified directly, and then directly distributed to K8s, causing unnecessary changes. For example, to expand the capacity from 3 nodes to 5 nodes, after modifying the replica of the above yaml file, you need to distribute the whole yaml. The whole distributed yaml is parsed into the underlying stateful set or Deployment twice. After the parsing logic is upgraded, it may produce unexpected changes, resulting in the reconstruction of all pod s.
reflect
First answer the first question. The yaml file above is not the final state of the application, but an arrangement, which contains the definition of DB and application. The final state of an application should only contain its own necessary dependency references, not how dependencies are created. Because this dependency reference can be newly created, an existing one, or filled in manually. How to create a dependency has nothing to do with the final application state.
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "WordPress"
name: WordPress-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: WordPress //chart-name
version: 1.0 //chart-version
name: WordPress-test
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
parameterValues: //Note parameterValues identifies business attributes
- ....
resources:
- name: test-db-secret
value: "wordPress1Secret" //Reference existing secret
exposes:
- name: dns
value: ...When creating an application, can't you create db first and then create an application?
Yes, the dependency between multiple objects is realized through choreography. Choreography can be created by a single application or a complex site. Take Argo as an example.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: wordPress-
spec:
templates:
- name: wordPress
steps:
# Create db
- - name: wordpress-db
template: wordpress-db
arguments:
parameters: [{name: wordpress-db1}]
# Create application
- - name:
template: wordpress
arguments:
parameters: [{db-sercet: wordpress-db1}]For the second case, do you need to issue all complete yaml for each interaction?
answer:
- Orchestration is a one-time configuration. After the orchestration file is distributed once, subsequent operations are to operate on a single object. For example, when changing, only wordPress or wordPressDB will be changed separately, rather than two objects at the same time.
- When changing the application alone, whether it is necessary to issue the whole final state yaml should be designed according to the actual situation, which is worth considering. The design of state machine for the whole application life cycle will be put forward later, which is explained in detail.
Scope of application
Applicable scenario
When CRD or Iac is defined, the final state of a single object should only contain itself and references to dependencies. As with object-oriented design, we should not put all Class definitions in one Class.
Not applicable scenario
Multiple objects need to be created at one time, and they need to be created in order. There are dependencies, which need to be realized through the orchestration layer.
Myth 3 everything is final
After experiencing the final state of K8s, we must call the final state in the design, as if we can't use the final state design. Without issuing a yaml statement, the final state of the object is outdated, that is, the design of the previous generation.
case
Case 1: application orchestration or take WordPress as an example, deploy WordPressDB and WordPress together, deploy DB first, and then create an application. The example yaml is the same as above.
Case 2: application Publishing: the first Deployment and subsequent upgrade of an application will directly distribute a complete application yaml, and the system will automatically help you reach the final state. However, in order to fine-grained control the publishing process, efforts should be made on Deployment or stateful set to control the partition and try to add a little bit of interactivity in the final state.
reflect
When it comes to the final state, we must mention imperative and declarative programming. The final state is actually the final execution result of declarative programming. Let's first review imperative and final programming.
Imperative programming
The main idea of imperative programming is to pay attention to the steps executed by the computer, that is, tell the computer what to do first and then what to do step by step.
For example, if you want to filter numbers greater than 5 in a number collection (variable name), you need to tell the computer:
1. The first step is to create a set variable results that stores the results;
2. Step 2: traverse the digital collection;
3. Step 3: judge whether each number is greater than 5 one by one. If so, add this number to the result set variable results.
The code implementation is as follows:
List results = new List();
foreach(var num in collection)
{
if (num > 5)
results.Add(num);
}Obviously, this kind of code is very common. Whether you use C, C + + or C#, Java, Javascript, BASIC, Python, Ruby, etc., you can write it in this way.
Declarative programming
Declarative programming is to express the logic of program execution in the form of data structure. Its main idea is to tell the computer what to do, but not specify how to do it.
SQL statement is the most obvious example of declarative programming, for example:
SELECT * FROM collection WHERE num > 5
In addition to SQL, HTML and CSS used in web page programming also belong to declarative programming.
By observing the code of declarative programming, we can find that it does not need to create variables to store data.
Another feature is that it does not contain code for loop control, such as for and while.
In other words
• imperative programming: command the "machine" how to do things, so that no matter what you want, it will be implemented according to your command.
• explicit programming: tell the "machine" what you want and let the machine figure out how to do it.
The more the interface expresses "what you want", the more explicit it is; The more you express "how to", the more imperative you are. SQL is expressing what I want (data), not how to get the data I want, so it is very "declarative".
In short, the closer the expression of the interface is to human language - the serial connection of words (a word is actually a concept) - the more "declarative"; The closer to the computer language - "sequence + branch + loop" operation process - the more "imperative".
The more declarative, it means that the lower level has to do more things, or the stronger the ability, it also means the loss of efficiency. The more imperative, it means that the upper layer has more operation space for the lower layer, and the lower layer can be required to deal with it in some way according to its specific needs.
In short, the Imperative Programming Language generally has a control flow and has the ability to interact with other devices. Declarative Programming language generally cannot do this.
Based on the above analysis, orchestration or workflow is essentially a process of process control, which is generally a one-time process, and there is no need to force the finalization. Moreover, the final state cannot be maintained after the execution of site establishment orchestration, because it will be released and upgraded according to a single application in the future. Case 1 is a typical choreography, which only creates two object DB and the final state of the application at one time.
Application publishing is actually a process of controlling the finalization of two different versions of application nodes and traffic through a release order or workflow. It should not be a part of the final application state, but an independent control process.
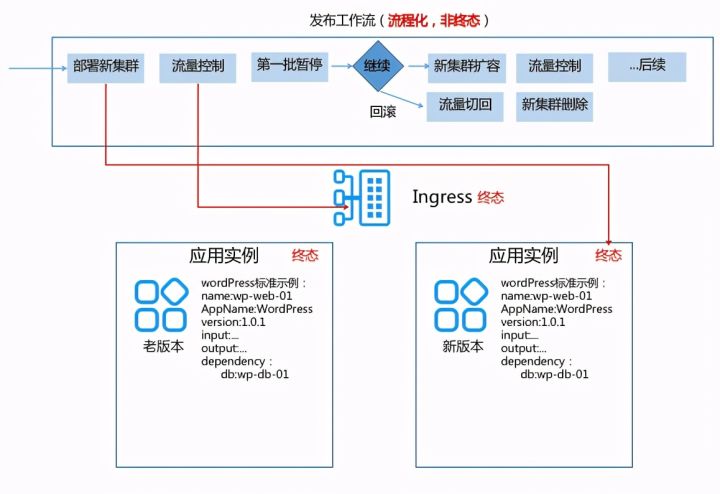
Scope of application
Declarative or final design
Applicable scenario
Without too much interaction, there is no need to pay attention to the scenario of the underlying implementation, that is, after the declaration is provided to the system, the system will automatically reach the state required by the declaration without human intervention.
Not applicable scenario
One time process arrangement and frequent interactive control process
Imperative and declarative are two complementary programming modes. It's like that after object-oriented, some people despise process oriented programming. Now with declarative, they begin to despise imperative programming. That's the house!
Myth 4 all interactions are cr
Because the API interaction of K8s can only pass yaml, everyone's design is centered on cr. all interactions are designed to issue a Cr and trigger the corresponding logic through watch cr.
case
- To call an http interface or function, you need to issue a cr
- Application crud issues complete cr
reflect
Case 1
Does all logic need to issue a cr?
In fact, issuing cr has done a lot of things. The process is very long and the efficiency is not high. The process is as follows:
- Pass in cr through API and save cr to etcd
- Trigger informer
- The controller receives the corresponding event and triggers the logic
- Update cr status
- Clean up cr, otherwise etcd storage will be occupied
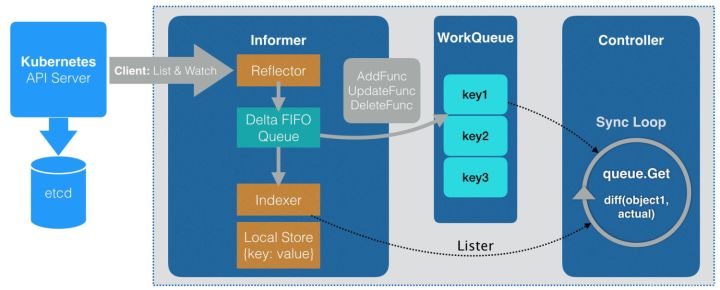
If you need to call the corresponding interface frequently, try to call it directly through sdk.
Case 2
K8s has create, apply, patch, delete, get and other yaml operation commands, but the life cycle state machine of an application can be covered by more than these commands. Let's compare the application state machine (upper) with yaml state machine (lower):
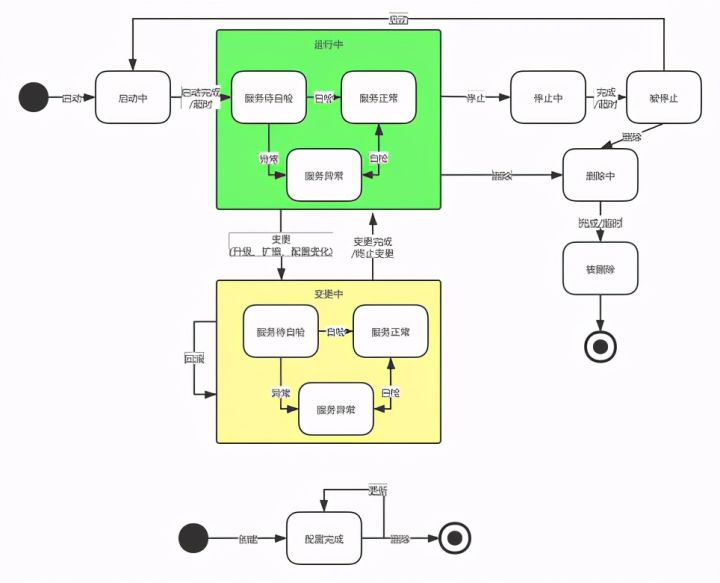
Different stateful applications need to trigger different logic when receiving different instructions. For example, when MQ receives the stop instruction, it needs to stop writing first to check whether the data consumption is completed. Events related to the application state machine cannot be covered only through yaml state machine, so we must break the mode of issuing cr. For applications, the ideal interaction mode is to apply the change of state machine through event driven, and trigger the corresponding logic when the state changes.
Scope of application
Applicable scenario
Data that needs to be persisted and maintained in the final state
Not applicable scenario
High frequency service calls without persistent data
Drive of complex state machine
summary
K8s has opened a door for us and brought us many excellent designs and ideas, but these designs and ideas also have their own applicable scenes, which are not universal. We should not blindly follow k8s the design and rules and abandon the previous excellent design concept.
After more than 10 years of development, software design has formed a set of effective design methodology, k8s which is also designed with the support of these design methodologies. Taking the essence to remove its dross is what our programmers should do.
This article is the original content of Alibaba cloud and cannot be reproduced without permission.