replicaset controller analysis
Introduction to replicaset controller
Replicaset controller is one of many controllers in Kube controller manager component. It is the controller of replicaset resource object. It monitors replicaset and pod resources. When these two resources change, it will trigger the replicaset controller to tune the corresponding replicaset object, so as to complete the tuning of the expected number of replicas of replicaset, Create a pod when the actual number of pods does not meet the expectation, and delete a pod when the actual number of pods exceeds the expectation.
The replicaset controller is mainly used to compare the number of pods expected by the replicaset object with the number of existing pods, then create / delete pods according to the comparison results, and finally make the number of pods expected by the replicaset object equal to the number of existing pods.
replicaset controller architecture diagram
The general composition and processing flow of the replicaset controller are shown in the following figure. The replicaset controller registers an event handler for pod and replicaset objects. When there is an event, it will watch, and then put the corresponding replicaset object into the queue. Then, the syncReplicaSet method tunes the core processing logic of the replicaset object for the replicaset controller, Take out the replicaset object from the queue for tuning.
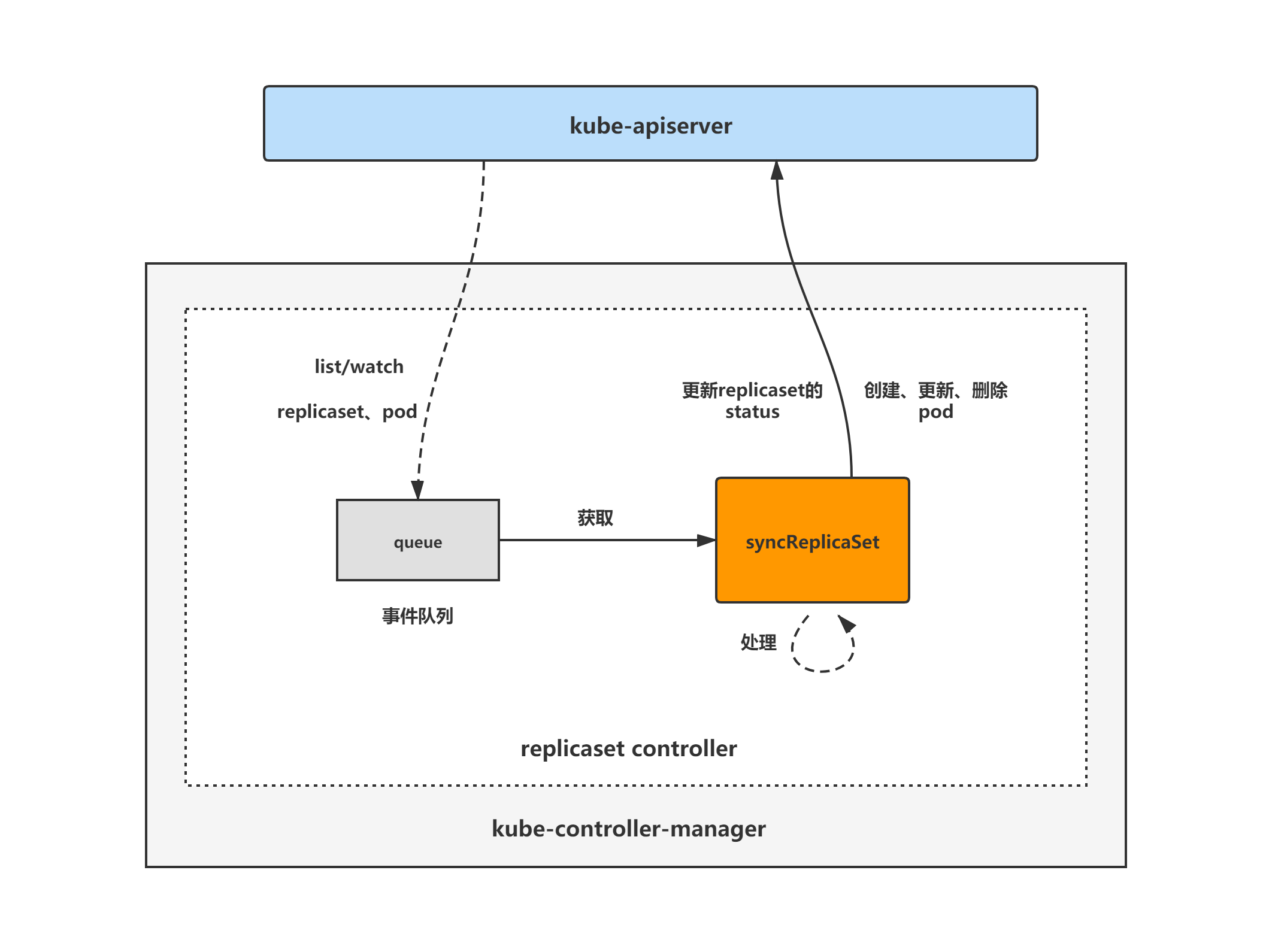
replicaset controller analysis will be divided into three parts:
(1) replicaset controller initialization and startup analysis;
(2) replicaset controller core processing logic analysis;
(3) replicaset controller expectations mechanism analysis.
This blog starts with the initialization and startup analysis of replicaset controller.
Initialization and startup analysis of ReplicaSetController
Based on tag v1.17.4
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
Directly use the startReplicaSetController function as the initialization and start source code analysis entry of the garbage collector.
In startReplicaSetController, replicaset.NewReplicaSetController is called to initialize ReplicaSetController, and Run is initialized after initialization.
Note the parameter ctx.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs passed into the Run method, which will be analyzed in detail later.
// cmd/kube-controller-manager/app/apps.go
func startReplicaSetController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "replicasets"}] {
return nil, false, nil
}
go replicaset.NewReplicaSetController(
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("replicaset-controller"),
replicaset.BurstReplicas,
).Run(int(ctx.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs), ctx.Stop)
return nil, true, nil
}
Initialization analysis
Analysis portal NewReplicaSetController
NewReplicaSetController is mainly used to initialize ReplicaSetController, define the informer of replicaset and pod objects, and register EventHandler addfund, UpdateFunc and deletefund to monitor the changes of replicaset and pod objects.
// pkg/controller/replicaset/replica_set.go
// NewReplicaSetController configures a replica set controller with the specified event recorder
func NewReplicaSetController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int) *ReplicaSetController {
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: kubeClient.CoreV1().Events("")})
return NewBaseController(rsInformer, podInformer, kubeClient, burstReplicas,
apps.SchemeGroupVersion.WithKind("ReplicaSet"),
"replicaset_controller",
"replicaset",
controller.RealPodControl{
KubeClient: kubeClient,
Recorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "replicaset-controller"}),
},
)
}
// NewBaseController is the implementation of NewReplicaSetController with additional injected
// parameters so that it can also serve as the implementation of NewReplicationController.
func NewBaseController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int,
gvk schema.GroupVersionKind, metricOwnerName, queueName string, podControl controller.PodControlInterface) *ReplicaSetController {
if kubeClient != nil && kubeClient.CoreV1().RESTClient().GetRateLimiter() != nil {
ratelimiter.RegisterMetricAndTrackRateLimiterUsage(metricOwnerName, kubeClient.CoreV1().RESTClient().GetRateLimiter())
}
rsc := &ReplicaSetController{
GroupVersionKind: gvk,
kubeClient: kubeClient,
podControl: podControl,
burstReplicas: burstReplicas,
expectations: controller.NewUIDTrackingControllerExpectations(controller.NewControllerExpectations()),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), queueName),
}
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.addRS,
UpdateFunc: rsc.updateRS,
DeleteFunc: rsc.deleteRS,
})
rsc.rsLister = rsInformer.Lister()
rsc.rsListerSynced = rsInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.addPod,
// This invokes the ReplicaSet for every pod change, eg: host assignment. Though this might seem like
// overkill the most frequent pod update is status, and the associated ReplicaSet will only list from
// local storage, so it should be ok.
UpdateFunc: rsc.updatePod,
DeleteFunc: rsc.deletePod,
})
rsc.podLister = podInformer.Lister()
rsc.podListerSynced = podInformer.Informer().HasSynced
rsc.syncHandler = rsc.syncReplicaSet
return rsc
}
queue
Queue is the key for replica controller to perform sync operation. When the replicaset or pod object changes, the corresponding EventHandler will add the object to queue, and rsc.worker in the Run method of replicaset controller (later analysis) will get the object from the queue and do the corresponding tuning operation.
Format of objects stored in queue: namespace/name
type ReplicaSetController struct {
...
// Controllers that need to be synced
queue workqueue.RateLimitingInterface
}
The source of queue is the EventHandler of replicaset and pod objects. Let's analyze them one by one.
1 rsc.addRS
This method is called when a new replicaset object is found.
Main logic: call rsc.enqueues to add the object to the queue.
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) addRS(obj interface{}) {
rs := obj.(*apps.ReplicaSet)
klog.V(4).Infof("Adding %s %s/%s", rsc.Kind, rs.Namespace, rs.Name)
rsc.enqueueRS(rs)
}
rsc.enqueueRS
Assemble the key and add the key to the queue.
func (rsc *ReplicaSetController) enqueueRS(rs *apps.ReplicaSet) {
key, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for object %#v: %v", rs, err))
return
}
rsc.queue.Add(key)
}
2 rsc.updateRS
This method is called when the replicaset object is found to have changed.
Main logic:
(1) If the UIDs of the old and new replicaset objects are inconsistent, call rsc.deleteRS (rsc.deleteRS will be analyzed later);
(2) Call rsc.enqueues, assemble the key, and add the key to the queue.
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) updateRS(old, cur interface{}) {
oldRS := old.(*apps.ReplicaSet)
curRS := cur.(*apps.ReplicaSet)
// TODO: make a KEP and fix informers to always call the delete event handler on re-create
if curRS.UID != oldRS.UID {
key, err := controller.KeyFunc(oldRS)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for object %#v: %v", oldRS, err))
return
}
rsc.deleteRS(cache.DeletedFinalStateUnknown{
Key: key,
Obj: oldRS,
})
}
// You might imagine that we only really need to enqueue the
// replica set when Spec changes, but it is safer to sync any
// time this function is triggered. That way a full informer
// resync can requeue any replica set that don't yet have pods
// but whose last attempts at creating a pod have failed (since
// we don't block on creation of pods) instead of those
// replica sets stalling indefinitely. Enqueueing every time
// does result in some spurious syncs (like when Status.Replica
// is updated and the watch notification from it retriggers
// this function), but in general extra resyncs shouldn't be
// that bad as ReplicaSets that haven't met expectations yet won't
// sync, and all the listing is done using local stores.
if *(oldRS.Spec.Replicas) != *(curRS.Spec.Replicas) {
klog.V(4).Infof("%v %v updated. Desired pod count change: %d->%d", rsc.Kind, curRS.Name, *(oldRS.Spec.Replicas), *(curRS.Spec.Replicas))
}
rsc.enqueueRS(curRS)
}
3 rsc.deleteRS
This method is called when the replicaset object is found to be deleted.
Main logic:
(1) Call the rsc.expectations.DeleteExpectations method to delete the expectations of the rs (the expectations mechanism will be analyzed separately later. Just have an impression here);
(2) Assemble the key and put it into the queue.
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) deleteRS(obj interface{}) {
rs, ok := obj.(*apps.ReplicaSet)
if !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("couldn't get object from tombstone %#v", obj))
return
}
rs, ok = tombstone.Obj.(*apps.ReplicaSet)
if !ok {
utilruntime.HandleError(fmt.Errorf("tombstone contained object that is not a ReplicaSet %#v", obj))
return
}
}
key, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for object %#v: %v", rs, err))
return
}
klog.V(4).Infof("Deleting %s %q", rsc.Kind, key)
// Delete expectations for the ReplicaSet so if we create a new one with the same name it starts clean
rsc.expectations.DeleteExpectations(key)
rsc.queue.Add(key)
}
4 rsc.addPod
This method is called when a new pod object is found.
Main logic:
(1) If the deleteiontimestamp property of pod is not empty, call rsc.deletePod (analyze later) and return;
(2) Call metav1.GetControllerOf to obtain the OwnerReference of the pod object and judge whether the pod has an upper controller. If yes, call rsc.resolveControllerRef to query whether the replica set to which the pod belongs exists. If not, it will be returned directly;
(3) Call the rsc.expectations.CreationObserved method to reduce the expected number of created pod s of the rs by 1 (the expectations mechanism will be analyzed separately later, and just have an impression here);
(4) Assemble the key and put it into the queue.
be careful: pod of eventHandler The processing logic is still pod Corresponding replicaset Object join queue Instead of pod Add to queue Yes.
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) addPod(obj interface{}) {
pod := obj.(*v1.Pod)
if pod.DeletionTimestamp != nil {
// on a restart of the controller manager, it's possible a new pod shows up in a state that
// is already pending deletion. Prevent the pod from being a creation observation.
rsc.deletePod(pod)
return
}
// If it has a ControllerRef, that's all that matters.
if controllerRef := metav1.GetControllerOf(pod); controllerRef != nil {
rs := rsc.resolveControllerRef(pod.Namespace, controllerRef)
if rs == nil {
return
}
rsKey, err := controller.KeyFunc(rs)
if err != nil {
return
}
klog.V(4).Infof("Pod %s created: %#v.", pod.Name, pod)
rsc.expectations.CreationObserved(rsKey)
rsc.queue.Add(rsKey)
return
}
// Otherwise, it's an orphan. Get a list of all matching ReplicaSets and sync
// them to see if anyone wants to adopt it.
// DO NOT observe creation because no controller should be waiting for an
// orphan.
rss := rsc.getPodReplicaSets(pod)
if len(rss) == 0 {
return
}
klog.V(4).Infof("Orphan Pod %s created: %#v.", pod.Name, pod)
for _, rs := range rss {
rsc.enqueueRS(rs)
}
}
5 rsc.updatePod
This method is called when a pod object is found to have changed.
Main logic:
(1) Judge the ResourceVersion of the old and new pod s. If it is consistent, it means there is no change and returns directly;
(2) If the deleteiontimestamp of the pod is not empty, call rsc.deletePod (analyze later) and return;
(3)...
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) updatePod(old, cur interface{}) {
curPod := cur.(*v1.Pod)
oldPod := old.(*v1.Pod)
if curPod.ResourceVersion == oldPod.ResourceVersion {
// Periodic resync will send update events for all known pods.
// Two different versions of the same pod will always have different RVs.
return
}
labelChanged := !reflect.DeepEqual(curPod.Labels, oldPod.Labels)
if curPod.DeletionTimestamp != nil {
// when a pod is deleted gracefully it's deletion timestamp is first modified to reflect a grace period,
// and after such time has passed, the kubelet actually deletes it from the store. We receive an update
// for modification of the deletion timestamp and expect an rs to create more replicas asap, not wait
// until the kubelet actually deletes the pod. This is different from the Phase of a pod changing, because
// an rs never initiates a phase change, and so is never asleep waiting for the same.
rsc.deletePod(curPod)
if labelChanged {
// we don't need to check the oldPod.DeletionTimestamp because DeletionTimestamp cannot be unset.
rsc.deletePod(oldPod)
}
return
}
curControllerRef := metav1.GetControllerOf(curPod)
oldControllerRef := metav1.GetControllerOf(oldPod)
controllerRefChanged := !reflect.DeepEqual(curControllerRef, oldControllerRef)
if controllerRefChanged && oldControllerRef != nil {
// The ControllerRef was changed. Sync the old controller, if any.
if rs := rsc.resolveControllerRef(oldPod.Namespace, oldControllerRef); rs != nil {
rsc.enqueueRS(rs)
}
}
// If it has a ControllerRef, that's all that matters.
if curControllerRef != nil {
rs := rsc.resolveControllerRef(curPod.Namespace, curControllerRef)
if rs == nil {
return
}
klog.V(4).Infof("Pod %s updated, objectMeta %+v -> %+v.", curPod.Name, oldPod.ObjectMeta, curPod.ObjectMeta)
rsc.enqueueRS(rs)
// TODO: MinReadySeconds in the Pod will generate an Available condition to be added in
// the Pod status which in turn will trigger a requeue of the owning replica set thus
// having its status updated with the newly available replica. For now, we can fake the
// update by resyncing the controller MinReadySeconds after the it is requeued because
// a Pod transitioned to Ready.
// Note that this still suffers from #29229, we are just moving the problem one level
// "closer" to kubelet (from the deployment to the replica set controller).
if !podutil.IsPodReady(oldPod) && podutil.IsPodReady(curPod) && rs.Spec.MinReadySeconds > 0 {
klog.V(2).Infof("%v %q will be enqueued after %ds for availability check", rsc.Kind, rs.Name, rs.Spec.MinReadySeconds)
// Add a second to avoid milliseconds skew in AddAfter.
// See https://github.com/kubernetes/kubernetes/issues/39785#issuecomment-279959133 for more info.
rsc.enqueueRSAfter(rs, (time.Duration(rs.Spec.MinReadySeconds)*time.Second)+time.Second)
}
return
}
// Otherwise, it's an orphan. If anything changed, sync matching controllers
// to see if anyone wants to adopt it now.
if labelChanged || controllerRefChanged {
rss := rsc.getPodReplicaSets(curPod)
if len(rss) == 0 {
return
}
klog.V(4).Infof("Orphan Pod %s updated, objectMeta %+v -> %+v.", curPod.Name, oldPod.ObjectMeta, curPod.ObjectMeta)
for _, rs := range rss {
rsc.enqueueRS(rs)
}
}
}
6 rsc.deletePod
This method is called when a pod object is found to be deleted.
Main logic:
(1) Call metav1.GetControllerOf to obtain the OwnerReference of the pod object and judge whether it is a controller. If yes, call rsc.resolveControllerRef to query whether the replica set of the pod belongs to exists. If it does not exist, it will be returned directly;
(2) Call the rsc.expectations.DeletionObserved method to reduce the expected number of deleted pod s of the rs by 1 (the expectations mechanism will be analyzed separately later, and an impression here is OK);
(3) Assemble the key and put it into the queue.
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) deletePod(obj interface{}) {
pod, ok := obj.(*v1.Pod)
// When a delete is dropped, the relist will notice a pod in the store not
// in the list, leading to the insertion of a tombstone object which contains
// the deleted key/value. Note that this value might be stale. If the pod
// changed labels the new ReplicaSet will not be woken up till the periodic resync.
if !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("couldn't get object from tombstone %+v", obj))
return
}
pod, ok = tombstone.Obj.(*v1.Pod)
if !ok {
utilruntime.HandleError(fmt.Errorf("tombstone contained object that is not a pod %#v", obj))
return
}
}
controllerRef := metav1.GetControllerOf(pod)
if controllerRef == nil {
// No controller should care about orphans being deleted.
return
}
rs := rsc.resolveControllerRef(pod.Namespace, controllerRef)
if rs == nil {
return
}
rsKey, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for object %#v: %v", rs, err))
return
}
klog.V(4).Infof("Pod %s/%s deleted through %v, timestamp %+v: %#v.", pod.Namespace, pod.Name, utilruntime.GetCaller(), pod.DeletionTimestamp, pod)
rsc.expectations.DeletionObserved(rsKey, controller.PodKey(pod))
rsc.queue.Add(rsKey)
}
Start analysis
Analysis entry Run
Start the corresponding number of goroutine s according to the value of workers, call rsc.worker circularly, and take a key from the queue to tune the replicaset resource object.
// pkg/controller/replicaset/replica_set.go
// Run begins watching and syncing.
func (rsc *ReplicaSetController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer rsc.queue.ShutDown()
controllerName := strings.ToLower(rsc.Kind)
glog.Infof("Starting %v controller", controllerName)
defer glog.Infof("Shutting down %v controller", controllerName)
if !controller.WaitForCacheSync(rsc.Kind, stopCh, rsc.podListerSynced, rsc.rsListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(rsc.worker, time.Second, stopCh)
}
<-stopCh
}
The workers parameter here is passed in from the startReplicaSetController method. The value is ctx.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs. Its value is actually determined by the concurrent replicaset syncs startup parameter of the Kube controller manager component. When not configured, the default value is set to 5, The representative will play five goroutine s to process and tune the replicaset objects in the queue in parallel.
Let's take a look at the concurrent replicaset syncs startup parameters related to the replicaset controller in the Kube controller manager component.
ReplicaSetControllerOptions
// cmd/kube-controller-manager/app/options/replicasetcontroller.go
// ReplicaSetControllerOptions holds the ReplicaSetController options.
type ReplicaSetControllerOptions struct {
*replicasetconfig.ReplicaSetControllerConfiguration
}
// AddFlags adds flags related to ReplicaSetController for controller manager to the specified FlagSet.
func (o *ReplicaSetControllerOptions) AddFlags(fs *pflag.FlagSet) {
if o == nil {
return
}
fs.Int32Var(&o.ConcurrentRSSyncs, "concurrent-replicaset-syncs", o.ConcurrentRSSyncs, "The number of replica sets that are allowed to sync concurrently. Larger number = more responsive replica management, but more CPU (and network) load")
}
// ApplyTo fills up ReplicaSetController config with options.
func (o *ReplicaSetControllerOptions) ApplyTo(cfg *replicasetconfig.ReplicaSetControllerConfiguration) error {
if o == nil {
return nil
}
cfg.ConcurrentRSSyncs = o.ConcurrentRSSyncs
return nil
}
Default settings
The default value of the concurrent replica set syncs parameter is configured as 5.
// pkg/controller/apis/config/v1alpha1/register.go
func init() {
// We only register manually written functions here. The registration of the
// generated functions takes place in the generated files. The separation
// makes the code compile even when the generated files are missing.
localSchemeBuilder.Register(addDefaultingFuncs)
}
// pkg/controller/apis/config/v1alpha1/defaults.go
func addDefaultingFuncs(scheme *kruntime.Scheme) error {
return RegisterDefaults(scheme)
}
// pkg/controller/apis/config/v1alpha1/zz_generated.defaults.go
func RegisterDefaults(scheme *runtime.Scheme) error {
scheme.AddTypeDefaultingFunc(&v1alpha1.KubeControllerManagerConfiguration{}, func(obj interface{}) {
SetObjectDefaults_KubeControllerManagerConfiguration(obj.(*v1alpha1.KubeControllerManagerConfiguration))
})
return nil
}
func SetObjectDefaults_KubeControllerManagerConfiguration(in *v1alpha1.KubeControllerManagerConfiguration) {
SetDefaults_KubeControllerManagerConfiguration(in)
SetDefaults_KubeCloudSharedConfiguration(&in.KubeCloudShared)
}
// pkg/controller/apis/config/v1alpha1/defaults.go
func SetDefaults_KubeControllerManagerConfiguration(obj *kubectrlmgrconfigv1alpha1.KubeControllerManagerConfiguration) {
...
// Use the default RecommendedDefaultReplicaSetControllerConfiguration options
replicasetconfigv1alpha1.RecommendedDefaultReplicaSetControllerConfiguration(&obj.ReplicaSetController)
...
}
// pkg/controller/replicaset/config/v1alpha1/defaults.go
func RecommendedDefaultReplicaSetControllerConfiguration(obj *kubectrlmgrconfigv1alpha1.ReplicaSetControllerConfiguration) {
if obj.ConcurrentRSSyncs == 0 {
obj.ConcurrentRSSyncs = 5
}
}
After analyzing the boot parameters of replicaset controller, look at the core processing method after the startup.
1 rsc.worker
As mentioned earlier, in the Run method of replicaset controller, the corresponding number of goroutine s will be started according to the value of workers, rsc.worker will be called circularly, and a key will be taken from the queue to tune the replicaset resource object.
Main logic of rsc.worker:
(1) Get a key from the queue;
(2) Call rsc.syncHandler to further process the key;
(3) Remove the key from the queue.
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (rsc *ReplicaSetController) worker() {
for rsc.processNextWorkItem() {
}
}
func (rsc *ReplicaSetController) processNextWorkItem() bool {
key, quit := rsc.queue.Get()
if quit {
return false
}
defer rsc.queue.Done(key)
err := rsc.syncHandler(key.(string))
if err == nil {
rsc.queue.Forget(key)
return true
}
utilruntime.HandleError(fmt.Errorf("Sync %q failed with %v", key, err))
rsc.queue.AddRateLimited(key)
return true
}
1.1 rsc.syncHandler
Calling rsc.syncHandler is actually calling the rsc.syncReplicaSet method. rsc.syncHandler is assigned as rsc.syncReplicaSet in NewBaseController. Later, when analyzing the core processing logic, analyze rsc.syncHandler in detail. No in-depth analysis is made here.
// NewBaseController is the implementation of NewReplicaSetController with additional injected
// parameters so that it can also serve as the implementation of NewReplicationController.
func NewBaseController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int,
gvk schema.GroupVersionKind, metricOwnerName, queueName string, podControl controller.PodControlInterface) *ReplicaSetController {
...
rsc.syncHandler = rsc.syncReplicaSet
return rsc
}
summary
Replicaset controller is one of many controllers in Kube controller manager component. It is the controller of replicaset resource object. It monitors replicaset and pod resources. When these two resources change, it will trigger the replicaset controller to tune the corresponding replicaset object, so as to complete the tuning of the expected number of replicas of replicaset, Create a pod when the actual number of pods does not meet the expectation, and delete a pod when the actual number of pods exceeds the expectation.
This blog analyzes the initialization and startup of replicaset controller, including the code analysis of the pod registered by replicaset controller and the event handler of replicaet object, as well as how to start replicaset controller and what methods are registered as the core processing logic methods.
replicaset controller architecture diagram
The general composition and processing flow of the replicaset controller are shown in the following figure. The replicaset controller registers an event handler for pod and replicaset objects. When there is an event, it will watch, and then put the corresponding replicaset object into the queue. Then, the syncReplicaSet method tunes the core processing logic of the replicaset object for the replicaset controller, Take out the replicaset object from the queue for tuning.
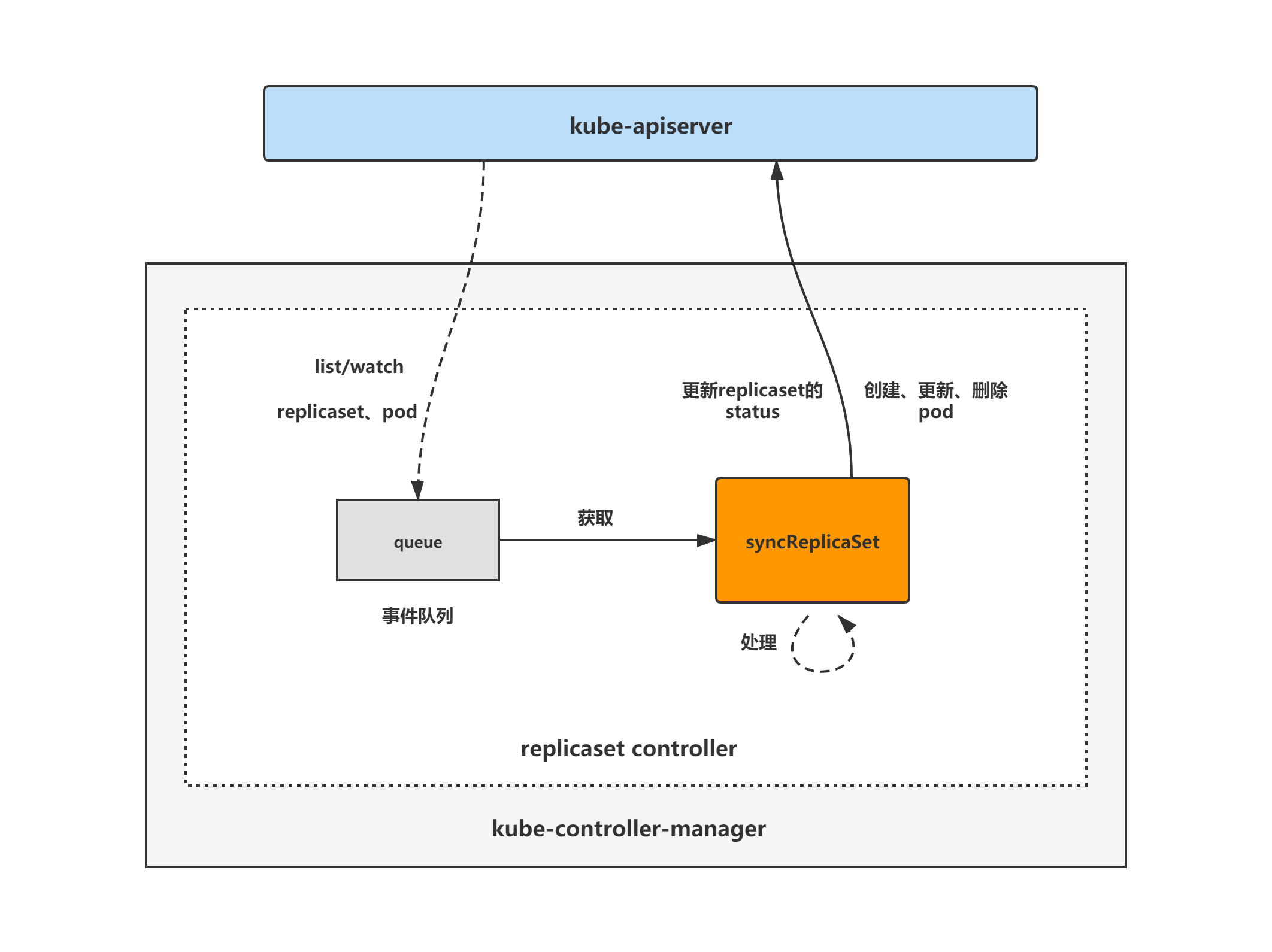
The next two blogs will analyze the core processing logic and expectations mechanism of replicaset controller in turn. Please look forward to it.