@[TOC] (Kafka (component building springboot integration practice))
Kafka (component building springboot integration practice)
1. Application scenario
1.1 kafka scenario
Kafka was originally developed by LinkedIn in Scala and based on ZooKeeper. Now it has been donated to the Apache foundation. At present, Kafka has been positioned as a distributed stream processing platform. It is widely used because of its high throughput, persistence, horizontal scalability, support for stream processing and other characteristics.
Apache Kafka can support the data transmission of massive data. Kafka is widely used in offline and real-time message processing business systems.
(1) log collection: collect logs of various services and open them to various consumer s through kafka in the form of unified interface services, such as Hadoop, Hbase, Solr, etc;
(2) Message system: decoupling producers and consumers, caching messages, etc;
(3) User activity tracking: Kafka is often used to record various activities of web users or app users, such as web browsing, search, click and other activities. These activity information is published by various servers to Kafka topics, and then subscribers subscribe to these topics for real-time monitoring and analysis, or load them into Hadoop and data warehouse for offline analysis and mining;
(4) Operational indicators: Kafka is also often used to record operational monitoring data. Including collecting data of various distributed applications and producing centralized feedback of various operations, such as alarm and report;
(5) Streaming processing: such as spark streaming and storm;
1.2 kafka characteristics
kafka is famous for its high throughput and has the following characteristics:
(1) High throughput and low latency: kafka can process hundreds of thousands of messages per second, and its latency is only a few milliseconds;
(2) Scalability: kafka cluster supports hot expansion;
(3) Persistence and reliability: messages are persisted to local disks, and data backup is supported to prevent data loss;
(4) Fault tolerance: nodes in the cluster are allowed to fail (if the number of replicas is n, n-1 nodes are allowed to fail);
(5) High concurrency: support thousands of clients to read and write at the same time;
1.3 message comparison
- If ordinary business messages are decoupled and message transmission, rabbitMq is the first choice. It is simple enough, easy to manage and usable.
- If kafka is recommended in the above high throughput and real-time scenarios such as logs, message collection and access records, it is based on distributed and easy to expand
- For heavy business, to achieve high reliability, consider rocketMq, but it is too heavy. You need to know enough
1.4 large plant application
JD builds a data platform through kafka to analyze users' buying, browsing and other behaviors. Successfully resist the flow peak of 6.18
Ali introduced its own rocketmq based on kafka's concept. In the design, we refer to kafka's architecture
2. Basic components
2.1 roles
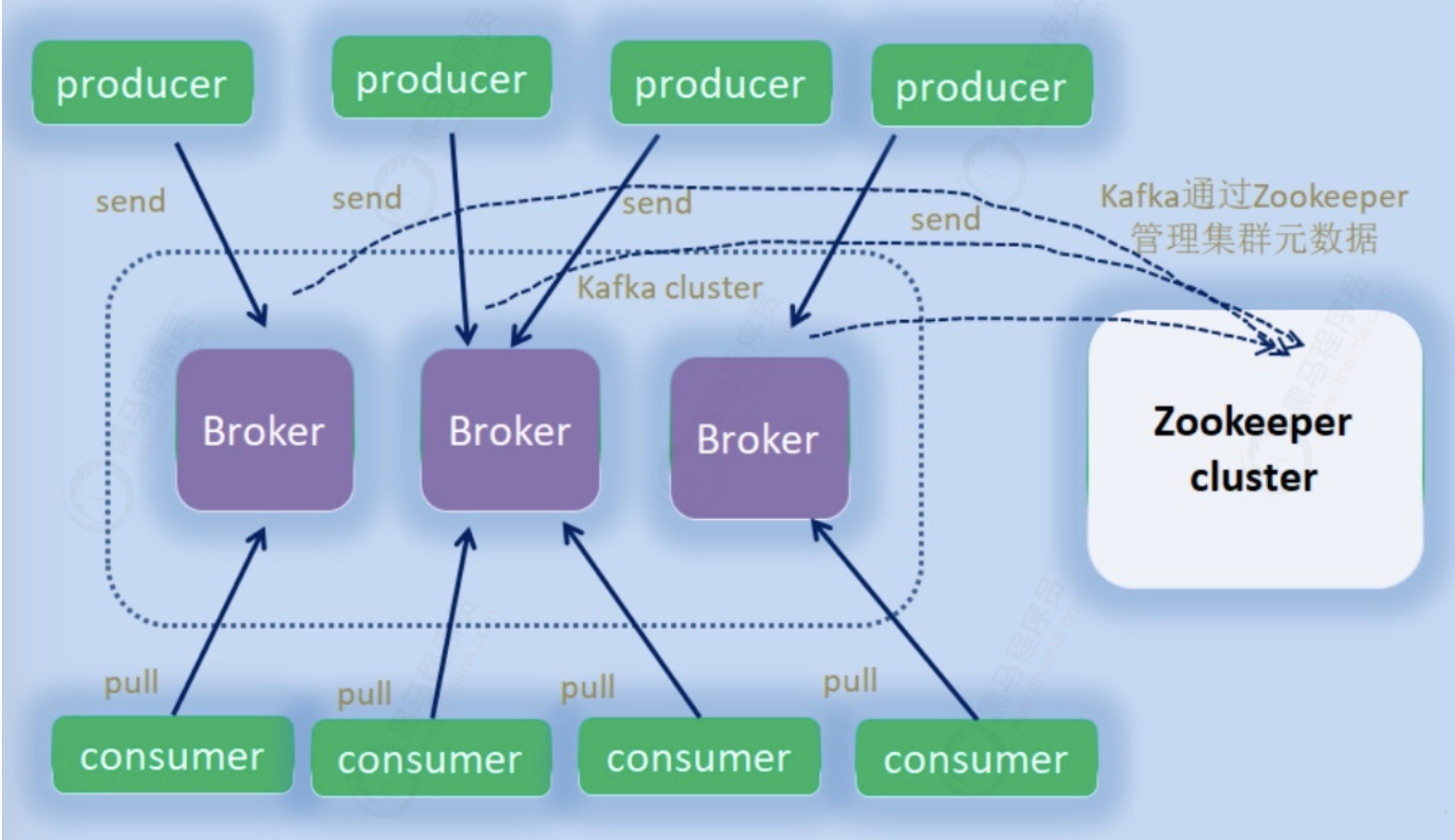
- broker: node is the machine you see
- provider: the producer who sends messages
- Consumer: consumer who reads messages
- zookeeper: Information Center, where kafka's various information is recorded
- controller: one of the broker s is responsible for managing the whole cluster as a leader. If you hang up, choose the master again with the help of zk
2.2 logic components

- Topic: topic is a message channel. You always know where to send and receive messages
- Partition: partition. Each topic can have multiple partitions to share data transmission. Multiple paths are parallel and the throughput is large
- Replicas: replicas. Multiple replicas can be set for each partition, and the data between replicas is consistent. Equivalent to backup, more reliable with spare tire
- Leader & follower: master and slave. One of the above replicas is identified as leader and the others as follower. The leader handles all read and write requests for the partition
2.3 replica set
- AR (assigned replicas): a general term for all replicas, AR=ISR+OSR
- ISR (in sync replicas): the replica in synchronization can participate in leader selection. Once it lags too much (the two dimensions of quantity lag and time lag), it will be kicked to OSR.
- OSR (out sync replicas): kick out the synchronized replica, keep chasing the leader, and enter the ISR after catching up
2.4 message marking

Offset: offset. Which message is consumed? Each consumer has its own offset

HW: (high watermark): the high watermark value of the replica, which is the location that the client can consume at most. The HW value is 8, which means that all 9 messages with offset [0,8] can be consumed. They are visible to the consumer, while the 4 messages [9,12] are not visible to the consumer because they are not submitted.
LEO: (log end offset): log end offset, which represents the offset of the next message to be written in the log file. There is no message on this offset. Both the leader copy and the follower copy have this value.
So what is the relationship between the three?
For example, when the number of copies is equal to 3, the value of LEO will be updated after the message is sent to Leader A, and Follower B and Follower C will also pull the message in Leader A to update themselves in real time. HW represents the log displacement reached by A, B and C at the same time, that is, the smallest value of LEO among A, B and C. Due to the delay between B and C pulling A messages, HW is generally less than LEO, that is, LEO > = HW.
LEO>=HW>=OFFSET
3. Architecture exploration
3.1 development process
http://kafka.apache.org/downloads

3.1.1 version naming
Kafka's naming rule before version 1.0.0 is 4 digits, for example, 0.8.2.1, 0.8 is the large version number, 2 is the small version number, and 1 indicates that a patch has been applied
The current version number naming rule is 3 digits, and the format is "large version number" + "small version number" + "number of revised patches", such as 2.5.0. The front 2 represents the large version number, the middle 5 represents the small version number, and 0 represents no patch
The download package we see is the version of the scala compiler in front and the real kafka version in the back.
3.1.2 evolution history
Version 0.7 only provides the most basic message queuing function.
Version 0.8 introduces the replica mechanism. So far, Kafka has become a truly complete distributed and highly reliable message queue solution.
In version 0.9, permissions and authentication are added, and Java is used to rewrite the new consumer API and Kafka Connect function; Consumer API is not recommended;
In version 0.10, Kafka Streams was introduced to officially upgrade the component distributed stream processing platform; Recommended version 0.10.2.2; A new version of the consumer API is recommended
Version 0.11 producer API idempotent, transaction API, message format reconstruction; Recommended version 0.11.0.3; Be cautious about message format changes
1.0 and 2.0 Kafka Streams improvements; Recommended version 2.0;
3.2 cluster construction
1) Native boot
zookeeper is required for kafka startup. The first step is to start zk:
docker run --name zookeeper-1 -d -p 2181 zookeeper:3.4.13
Native installation: after downloading, unzip and start http://kafka.apache.org/downloads
bin/kafka-server-start.sh config/server.properties
#server.properties configuration description #Represents the number of brokers. If there are multiple brokers in the cluster, the number of each broker needs to be set differently broker.id=0 #The service entry address provided by brocder is 9092 by default listeners=PLAINTEXT://:9092 #Set the address where the message log file is stored log.dirs=/tmp/kafka/log #This is the key to the Zookeeper cluster address required by Kafka! Kafka joining the same zk is the same cluster zookeeper.connect=zookeeper:2181
2) It is recommended to start docker compose with one click
#docker-compose.yml
#Pay attention to the problem of hostname. The ip address is 52.82.98.209. Replace it with your own server
#Docker compose up - d start
version: '3'
services:
zookeeper:
image: zookeeper:3.6.3
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka
ports:
- 10903:9092
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 192.168.31.236
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#The external accessible ip and port must be set for docker deployment, otherwise the address registered in zk will not be reachable, resulting in external connection failure
KAFKA_ADVERTISED_HOST_NAME: 192.168.31.236
KAFKA_ADVERTISED_PORT: 10903
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka
ports:
- 10904:9092
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 192.168.31.236
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.31.236
KAFKA_ADVERTISED_PORT: 10904
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
3.3 component exploration
The command line tool is the most direct tool for managing kafka clusters. The official comes with it, and no additional installation is required.
3.2.1 topic creation
#Enter container docker exec -it kafka-1 sh #Enter the bin directory cd /opt/kafka/bin #establish kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test --partitions 2 --replication-factor 1
3.2.2 viewing topics
kafka-topics.sh --zookeeper zookeeper:2181 --list
3.2.3 subject details
kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test #Analysis output: #Note the format: Partition: (partition number, starting from 0), Leader, Replicas, Isr: (machine number, that is, the broker_id configured at startup) Topic: test PartitionCount: 2 ReplicationFactor: 1 Configs: Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2 Topic: test Partition: 1 Leader: 1 Replicas: 1 Isr: 1
3.2.4 messaging
#Use docker to connect to a container in any cluster docker exec -it kafka-1 sh #Enter the directory in kafka's container cd /opt/kafka/bin #Client listening ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test #Start another terminal and verify the transmission ./kafka-console-producer.sh --broker-list localhost:9092 --topic test
If both clients listen, it is found that it is broadcast
3.2.5 group consumption
#When two consumer s are started, if the group information is not specified, the message is broadcast #Specify the same group to allow multiple consumers to consume separately (drawing: Group principle) ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- group aaa #Results: at the sender, 1-4 or 4 messages are sent continuously. Two consumer s in the same group consume alternately and execute concurrently
be careful!!!
This is when the number of consumers and partitions are equal (both 2). If (number of consumers > number of partitions) in the same group, some consumers will be idle.
Verification method:
You can start a few more consumers to try, and you will find that when more than two, some will never consume messages. Stop what can be consumed, then the idle will be activated and enter the working state
3.2.6 designated zoning
#Specify the partition through the parameter -- partition. Note! You need to remove the group above #The meaning of specifying partitions is to ensure the sequence of message transmission (drawing: kafka sequence principle) ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- partition 0 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- partition 1 #Result: 1-4 messages are sent and appear alternately. The description message is evenly distributed to each partition for delivery #By default, no key is specified for sending #To specify partition sending, you need to define a key. Then the same key is routed to the same partition ./kafka-console-producer.sh --broker-list kafka-1:9092 --topic test --property parse.key=true #Carry the key and then send it. Note that the key and value are separated by tab >1 1111 >1 2222 >2 3333 >2 4444
3.2.7 offset
#The offset determines where the message is consumed. It supports: the beginning or the end # Earlist: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, consumption starts from scratch # latest: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, the newly generated data under the partition is consumed # none:topic when there are committed offsets in each partition, consumption starts after offset; As long as there is no committed offset in one partition, an exception is thrown #--Offset [early | latest (default)], or -- from beginning #Start a new terminal and specify the offset position ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- partition 0 --offset earliest ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- partition 0 --from-beginning #Results: the messages sent before were consumed again from the beginning! # Be careful!!! If there is a submission offset, it is still mainly submitted. Even if earlist is used, those earlier than the submission point will not be extracted # The following instructions, under the group=aa group, will start from the beginning only for the first time # Even if you specify starting later, you will not start at the earliest, because there is an offset after the first consumption, so it takes precedence! ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -- group begining-group --from-beginning
3.4 zk exploring Secrets
As mentioned earlier, zk stores the relevant information of kafka cluster. This section explores the internal secrets.
The information of kafka is recorded in zk. Enter zk container to view relevant nodes and information
docker exec -it kafka_zookeeper_1 sh >./bin/zkCli.sh >ls / #Result: the following configuration information is obtained [admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]

3.4.1 broker information
[zk: localhost:2181(CONNECTED) 2] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 3] ls /brokers/ids
[1, 2, 3]
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/1
{"features":{},"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://192.168.31.236:10903"],"jmx_port":-1,"port":10903,"host":"192.168.31.236","version":5,"timestamp":"1625978230130"}
cZxid = 0x27
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x27
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x27
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 196
numChildren = 0
3.4.2 theme and zoning
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics
[__consumer_offsets, test]
[zk: localhost:2181(CONNECTED) 9] ls /brokers/topics/test
[partitions]
[zk: localhost:2181(CONNECTED) 10] ls /brokers/topics/test/partitions
[0, 1]
[zk: localhost:2181(CONNECTED) 11] ls /brokers/topics/test/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 12] get /brokers/topics/test/partitions/0/state
{"controller_epoch":2,"leader":1,"version":1,"leader_epoch":2,"isr":[1]}
[zk: localhost:2181(CONNECTED) 13]
cZxid = 0xb0
ctime = Tue Jan 05 05:56:06 GMT 2021
mZxid = 0xb0
mtime = Tue Jan 05 05:56:06 GMT 2021
pZxid = 0xb0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
3.4.3 consumers and offsets
[zk: localhost:2181(CONNECTED) 15] ls /consumers [] #Empty??? #So, where are consumers and their offsets???
There are two ways to record the consumption offset of kafka consumer group:
1) kafka self maintenance (New)
2) zookpeer maintenance (old), has been gradually abandoned
View by:
The above consumption uses the console tool, which uses - bootstrap server. Without zk, it will not be recorded under / consumers.
The offset of its consumers will be updated to the topic [_consumer_offsets] of kafka
#Start a consumer and specify group ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group aaa #Use the console tool to view the consumer and offset ./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --list KMOffsetCache-44acff134cad aaa #View offset details ./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --describe --group aaa
At present, it is consistent with LEO, which means that the messages have been consumed completely

After stopping the consumer, send several more records to the provider, and the offset starts to lag:

Restart the consumer, consume the latest message, and then return to see the offset. The message is synchronized

3.4.4 controller
#Who is the master node in the current cluster
[zk: localhost:2181(CONNECTED) 17] get /controller
{"version":1,"brokerid":1,"timestamp":"1609825245694"}
cZxid = 0x2a
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x2a
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x2a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 54
numChildren = 0
3.5.1 startup
kafka manager is the most popular kafka cluster management tool. It was first opened source by Yahoo. Provides visual kafka cluster operations
Official website: https://github.com/yahoo/kafka-manager/releases
Pay attention to its version. The scene version of docker community lags behind kafka. Let's mirror it ourselves
#Dockerfile FROM daocloud.io/library/java:openjdk-8u40-jdk ADD kafka-manager-2.0.0.2/ /opt/km2002/ CMD ["/opt/km2002/bin/kafka-manager","- Dconfig.file=/opt/km2002/conf/application.conf"] #Package and put kafka-manager-2.0.0.2 in the same directory docker build -t km:2002 .
#Start: add a paragraph under the services node in the yml above #Reference: km yml #Execution: docker compose - f km yml up -d km: image: km:2002 ports: - 10906:9000 depends_on: - zookeeper
3.5.2 use
Using km, you can easily view the following information:
- Cluster: create a cluster, fill in zk address, and select jmx, consumer information and other options
- brokers: list, machine information
- Topic: topic information, partition information within a topic. Create new themes and add partitions
- cosumers: consumer information, offset, etc
4. Deep application
4.1 springboot-kafka
1) Configuration file
kafka:
bootstrap-servers: 52.82.98.209:10903,52.82.98.209:10904
producer: # Producer producer
retries: 0 # retry count
acks: 1 # Response level: how many partition replicas send ack confirmation to the producer when the backup is completed (optional: 0, 1, all/-1)
batch-size: 16384 # Batch size
buffer-memory: 33554432 # Production side buffer size
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# value-serializer: com.itheima.demo.config.MySerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # Consumer consumer
group-id: javagroup # Default consumer group ID
enable-auto-commit: true # Automatically submit offset
auto-commit-interval: 100 # Submit offset delay (how long to submit offset after receiving the message)
# Earlist: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, consumption starts from scratch
# latest: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, the newly generated data under the partition is consumed
# none:topic when there are committed offsets in each partition, consumption starts after offset; As long as there is no committed offset in one partition, an exception is thrown
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# value-deserializer: com.itheima.demo.config.MyDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
pom.xml
<name>kafka</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!--swagger2 Enhanced, official ui too low , Access address: /doc.html -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>swagger-bootstrap-ui</artifactId>
<version>1.9.6</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
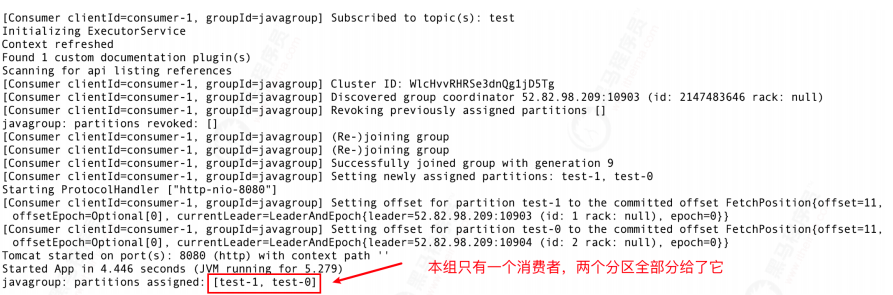
2) Startup information
4.2 message sending
4.2.1 sending type
When KafkaTemplate calls send, asynchronous sending is adopted by default. If you need to get the sending results synchronously, call the get method
Detailed code reference: asyncproducer java
@RestController
public class AsyncProducer {
private final static Logger logger = LoggerFactory.getLogger(AsyncProducer.class);
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
//Synchronous transmission
@GetMapping("/kafka/sync/{msg}")
public void sync(@PathVariable("msg") String msg) throws Exception {
Message message = new Message();
message.setMessage(msg);
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("test", JSON.toJSONString(message));
SendResult<String, Object> result = future.get(3,TimeUnit.SECONDS);
logger.info("send result:{}",result.getProducerRecord().value());
}
}
Consumer use: kafkaconsumer java
//Default consumption group consumption
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//If no group is specified, the group configured in yml will be used by default
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("message:{}", msg);
}
}
}
1) Synchronous transmission
ListenableFuture<SendResult<String, Object>> future =
kafkaTemplate.send("test", JSON.toJSONString(message));
//Note that you can set the waiting time. After it is exceeded, you will no longer wait for the result
SendResult<String, Object> result = future.get(3,TimeUnit.SECONDS);
logger.info("send result:{}",result.getProducerRecord().value());
Send through swagger, and the console can print send result normally
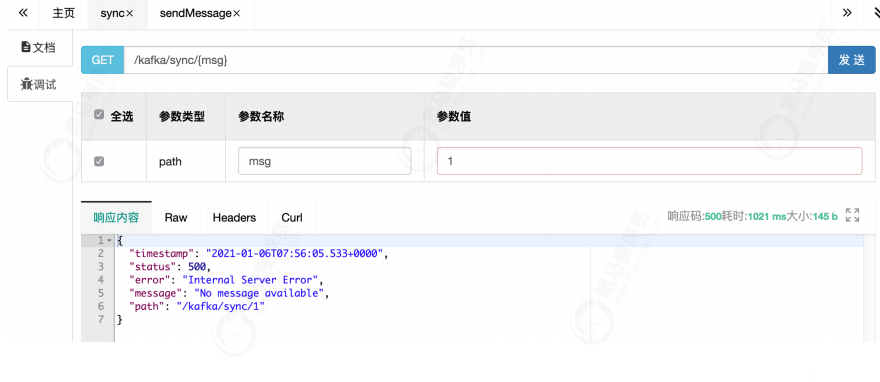
2) Block
On the server, the kafka service will be suspended
Send message in swagger
Synchronous sending: the request is blocked, waiting all the time, and an error is returned after timeout
For asynchronous sending (the default sending interface), the request is returned immediately.
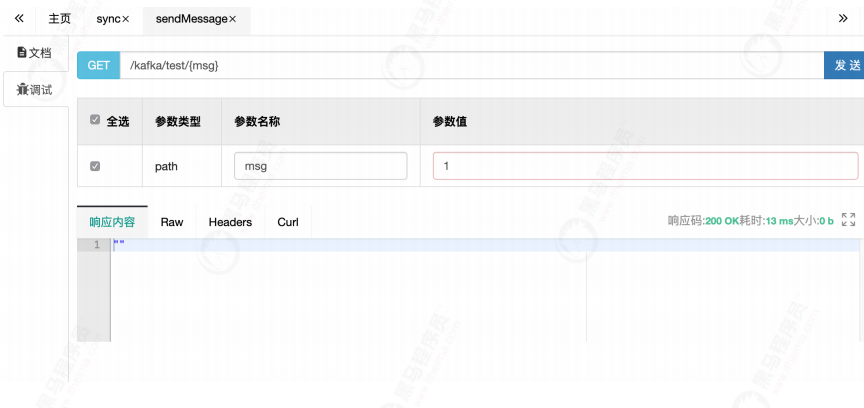
Then, how to confirm the sending of asynchronous messages??? Look down!
3) Register listening
Code reference: kafkalistener java
You can set a Listener for kafkaTemplate to listen to message sending and implement internal corresponding methods
//@Configuration
public class KafkaListener {
private final static Logger logger = LoggerFactory.getLogger(KafkaListener.class);
@Autowired
KafkaTemplate kafkaTemplate;
//Configure listening
@PostConstruct
private void listener(){
kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {
@Override
public void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) {
logger.info("ok,message={}",producerRecord.value());
}
@Override
public void onError(ProducerRecord<String, Object> producerRecord, Exception exception) {
logger.error("error!message={}",producerRecord.value());
}
});
}
}
Check the console. After waiting for a period of time, the message of asynchronous sending failure will be recalled to the registered listener
com.itheima.demo.config.KafkaListener:error!message= {"message":"1","sendTime":1609920296374}
Start kafka
docker-compose unpause kafka-1 kafka-2
When sending a message again, both synchronous and asynchronous messages can be sent and received normally, and listening enters the success callback
com.itheima.demo.config.KafkaListener$1:ok,message=
{"message":"1","sendTime":1610089315395}
com.itheima.demo.controller.PartitionConsumer:patition=1,message:
[{"message":"1","sendTime":1610089315395}]
You can see that in the internal class KafkaListener , that is, the message of the registered Listener
4.2.2 serialization
Consumer use: kafkaconsumer java
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//If no group is specified, the group configured in yml will be used by default
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("message:{}", msg);
}
}
}
1) Serialization details
- The previous use is Kafka's own string serializer
(org.apache.kafka.common.serialization.StringSerializer) - In addition, there are: ByteArray, ByteBuffer, Bytes, Double, Integer, Long, etc
- These serializers implement interfaces (org.apache.kafka.common.serialization.Serializer)
- Basically, it can meet most scenarios
2) Custom serialization
You can implement the corresponding interface by yourself. There are the following methods:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
}
//In theory, only this can work normally
byte[] serialize(String var1, T var2);
//Default to the above method
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}
Case, reference: myserializer java
public class MySerializer implements Serializer {
@Override
public byte[] serialize(String s, Object o) {
String json = JSON.toJSONString(o);
return json.getBytes();
}
}
Configure your own encoder in yaml
value-serializer: com.itheima.demo.config.MySerializer
After resending, it is found that the encoding callback at the sending end of the message is normal. But the content of the consumer message is wrong!
com.itheima.demo.controller.KafkaListener$1:ok,message=
{"message":"1","sendTime":1609923570477}
com.itheima.demo.controller.KafkaConsumer:message:"
{\"message\":\"1\",\"sendTime\":1609923570477}"
What should I do?
3) Decode
If the sender has a code and we define the code ourselves, the receiver should be equipped with the corresponding decoding strategy
Code reference: mydeserializer Java, the implementation method is almost the same as the encoder!
Configure your own decoder in yaml
value-deserializer: com.itheima.demo.config.MyDeserializer
public class MyDeserializer implements Deserializer {
private final static Logger logger = LoggerFactory.getLogger(MyDeserializer.class);
@Override
public Object deserialize(String s, byte[] bytes) {
try {
String json = new String(bytes,"utf-8");
return JSON.parse(json);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
}
Send and receive again, and the message is normal
com.itheima.demo.controller.AsyncProducer$1:ok,message=
{"message":"1","sendTime":1609924855896}
com.itheima.demo.controller.KafkaConsumer:message:
{"message":"1","sendTime":1609924855896}
4.2.3 zoning strategy
The partition policy determines the partition to which messages are delivered according to the key, and it is also the cornerstone of sequential consumption guarantee.
- Given the partition number, send the data directly to the specified partition
- If the partition code is not given and the key value of the data is given, get the hashCode through the key to partition
- Neither the partition code nor the key value is given, and the partition is carried out by rotation directly
- Customize the partition. Do whatever you want
1) Validate default partition rules
Sender code reference: partitionproducer java
@RestController
public class PartitionProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
// Specify partition send
// No matter what your key is, go to the same partition
@GetMapping("/kafka/partitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
kafkaTemplate.send("test", 0,key,"key="+key+",msg=Specify partition 0");
}
// Specify the key to send without specifying the partition
// hash according to the key, and the same key to the same partition
@GetMapping("/kafka/keysend/{key}")
public void setKey(@PathVariable("key") String key) {
kafkaTemplate.send("test", key,"key="+key+",msg=No partition specified");
}
}
Consumer code usage: partitionconsumer java
//@Component
public class PartitionConsumer {
private final Logger logger = LoggerFactory.getLogger(PartitionConsumer.class);
//Regional consumption
@KafkaListener(topics = {"test"},topicPattern = "0")
public void onMessage(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=0,message:[{}]", msg);
}
}
@KafkaListener(topics = {"test"},topicPattern = "1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=1,message:[{}]", msg);
}
}
}
Access setKey through swagger:
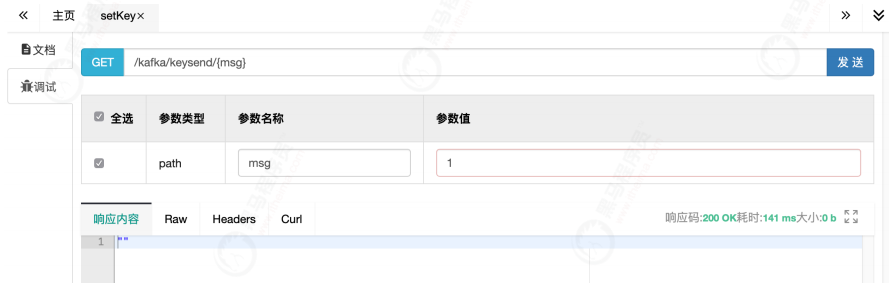
Look at the console:

Then access setPartition to set the partition number 0 to send
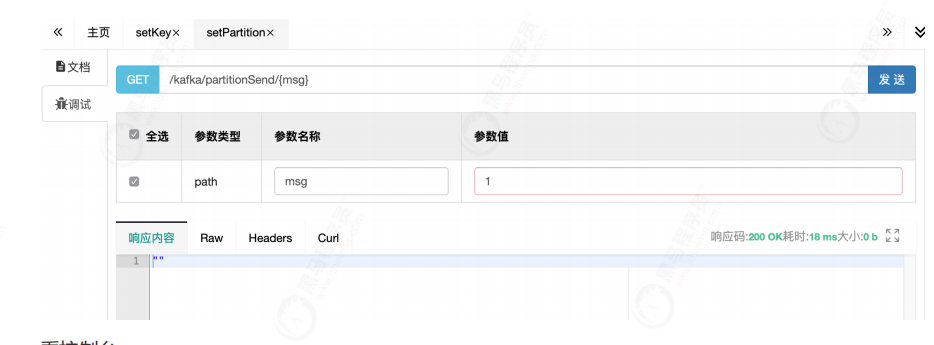
Look at the console:

2) Custom partition
Do you want to define your own rules and put messages into the corresponding partition according to my requirements? sure!
Reference code: mypartitioner java
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// Define your own partition policy
// If the key starts with 0, send it to partition 0
// Throw the rest to Division 1
String keyStr = key+"";
if (keyStr.startsWith("0")){
return 0;
}else {
return 1;
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
MyPartitionTemplate.java ,
@Configuration
public class MyPartitionTemplate {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
KafkaTemplate kafkaTemplate;
@PostConstruct
public void setKafkaTemplate() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//Note that the partition is here!!!
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);
this.kafkaTemplate = new KafkaTemplate<String, String>(new DefaultKafkaProducerFactory<>(props));
}
public KafkaTemplate getKafkaTemplate(){
return kafkaTemplate;
}
}
Send using: mypartitionproducer java
@RestController
public class MyPartitionProducer {
@Autowired
MyPartitionTemplate template;
// Send a message using a key starting with 0 and any other letter
// Look at the console output. Which partition is it in?
@GetMapping("/kafka/myPartitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
template.getKafkaTemplate().send("test", key,"key="+key+",msg=Custom partition policy");
}
}
Use swagger to send two types of key s beginning with 0 and not beginning with 0. Try it!
remarks:
It's troublesome to define the config parameter yourself. You need to break the default KafkaTemplate setting
Kafkaconfiguration can be The getTemplate in Java is annotated with @ bean to override the system default bean
Here, @ Autowire injection is used to avoid confusion
4.3 message consumption
4.3.1 message group
Sender: kafkaproducer java
@RestController
public class KafkaProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/test/{msg}")
public void sendMessage(@PathVariable("msg") String msg) {
Message message = new Message();
message.setMessage(msg);
kafkaTemplate.send("test", JSON.toJSONString(message));
}
}
1) Code reference: groupconsumer Three copies of Java and Listener are given to two groups respectively to verify the group consumption:
@Component
public class GroupConsumer {
private final Logger logger = LoggerFactory.getLogger(GroupConsumer.class);
//Group 1, consumer 1
@KafkaListener(topics = {"test"},groupId = "group1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group1-1 , message:{}", msg);
}
}
//Group 1, consumer 2
@KafkaListener(topics = {"test"},groupId = "group1")
public void onMessage2(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group1-2 , message:{}", msg);
}
}
//Group 2, only one consumer
@KafkaListener(topics = {"test"},groupId = "group2")
public void onMessage3(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group2 , message:{}", msg);
}
}
}
2) Start

3) Send 2 messages through swagger

Two consumers in the same group share messages equally in group1
There is only one consumer in group2 and they get all the information
4) Consumer idle
Pay attention to the matching between the number of partitions and the number of consumers. If (number of consumers > number of partitions), consumers will be idle and waste resources!
Verification method:
Stop the project, delete the test theme, and create a new one. This time, only one partition is assigned to it.
Resend two messages and try

Resolution:
group2 can consume 1 and 2 messages
There are two consumers under group1, but they are only allocated to - 1 and - 2. This process is idle
4.3.2 displacement submission
1) Auto submit
In the previous case, if we set the following two options, kafka will automatically submit according to the delay setting
enable-auto-commit: true # Automatically submit offset auto-commit-interval: 100 # Submit offset delay (how long to submit offset after receiving the message)
2) Manual submission
Sometimes, we need to manually control the submission timing of offset, such as ensuring that messages are submitted after strict consumption, so as to prevent loss or duplication.
Let's define the configuration ourselves and override the above parameters
@Configuration
public class MyOffsetConfig {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaListenerContainerFactory<?> manualKafkaListenerContainerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// Pay attention here!!! Set manual submission
configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));
// ack mode:
// AckMode for enable_ AUTO_ COMMIT_ It takes effect when config = false. There are the following types:
//
// RECORD
// Once for each commit
//
// Batch (default)
// Each poll is submitted in batches, and the frequency depends on the call frequency of each poll
//
// TIME
// Commit at the interval of ackTime each time (what's the difference between auto commit interval and auto commit interval?)
//
// COUNT
// Accumulated ack counts to commit
//
// COUNT_TIME
// If the ackTime or ackCount condition is satisfied first, commit
//
// MANUAL
// listener is responsible for ack, but behind it is also batch up
//
// MANUAL_IMMEDIATE
// listner is responsible for ack. Every time it is called, it commit s immediately
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
}
There are several ways to submit the offset through the Consumer on the Consumer side:
//@Component
public class MyOffsetConsumer {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics = "test",groupId = "myoffset-group-1",containerFactory = "manualKafkaListenerContainerFactory")
public void manualCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("Manually submit offset , partition={}, msg={}", partition, message);
// Synchronous submission
consumer.commitSync();
//Asynchronous commit
//consumer.commitAsync();
// ACK submission is also OK. It will follow the set ack policy (refer to the ACK mode in MyOffsetConfig.java)
// ack.acknowledge();
}
@KafkaListener(topics = "test",groupId = "myoffset-group-2",containerFactory = "manualKafkaListenerContainerFactory")
public void noCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("Forget to submit offset, partition={}, msg={}", partition, message);
// No commit!
}
/**
* Reality:
* commitSync Combined with commitAsync
*
* Manually submit asynchronous consumer commitAsync();
* Submit the consumer manually commitSync()
*
* commitSync()Method submits the last offset. Before successfully submitting or encountering an error without recovery,
* commitSync()Will keep trying, but commitAsync() won't.
*
* In general, for the occasional submission failure, there will be no big problem without retrying
* Because if the submission failure is caused by temporary problems, subsequent submissions will always succeed.
* However, if this is the last submission before closing consumers or rebalancing, ensure that the submission is successful. Otherwise, it will cause repeated consumption
* Therefore, commitAsync() and commitSync() are usually used together before the consumer closes.
*/
// @KafkaListener(topics = "test", groupId = "myoffset-group-3",containerFactory = "manualKafkaListenerContainerFactory")
public void manualOffset(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
try {
logger.info("Synchronous asynchronous collocation , partition={}, msg={}", partition, message);
//Asynchronous commit first
consumer.commitAsync();
//Keep doing something else
} catch (Exception e) {
System.out.println("commit failed");
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
/**
* You can even submit manually, specifying an offset anywhere
* Not recommended for daily use!!!
*/
// @KafkaListener(topics = "test", groupId = "myoffset-group-4",containerFactory = "manualKafkaListenerContainerFactory")
public void offset(ConsumerRecord record, Consumer consumer) {
logger.info("Manually specify any offset, partition={}, msg={}",record.partition(),record);
Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
currentOffset.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
consumer.commitSync(currentOffset);
}
}
Synchronous submission and asynchronous submission: manualCommit(), the difference between synchronous and asynchronous, which will be discussed in detail below.
Specify offset commit: offset()
3) Repeated consumption problem
If manual submission mode is turned on, be sure not to forget to submit the offset. Otherwise, it will cause repeated consumption!
Code reference and comparison: manualcommit(), nocommit()
Verification process:
Delete the test topic with km and create an empty test topic. It is convenient to observe the message offset, comment out the Component annotation of other consumers, and only keep the current myoffsetconsumer Start the project with Java, send several consecutive messages using Kafka producer of swagger, pay attention to the console, and you can consume them. No problem:

But! Try restarting:

No matter how many times you restart, the consumption group that does not submit the offset will consume again!!!
Try to query the offset through the command line:
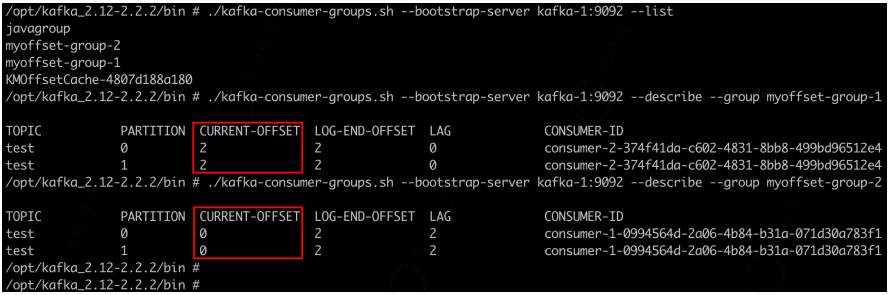
4) Experience and summary
commitSync()Method, synchronous commit, commits the last offset. Before successfully submitting or encountering an error without recovery, commitSync()Will keep trying, but commitAsync()can't. This creates a trap: If you commit asynchronously, it will not be a big problem if you do not retry the occasional submission failure, because if the submission failure is due to a temporary problem If so, subsequent submissions will always succeed. Once successful, the offset will be submitted. But! If this is the last submission when the consumer is closed, ensure that the submission is successful. If the submission is not finished, stop the entry Cheng. It will cause repeated consumption! Therefore, it is generally used in combination before consumers close commitAsync()and commitSync(). Detailed code reference: MyOffsetConsumer.manualOffset()