Automatic Submission from Consumer
stay Above The use of the Producer API is described. Now that we know how to send messages through the API to Kafka, the producer/consumer model is one less consumer.Therefore, this article will introduce the use of the Consumer API, which consumes messages from Kafka to make an app a consumer role.
As always, first we have to create a Consumer instance and specify the associated configuration items so that we can do anything else with this instance object.Code example:
/**
* Create Consumer Instance
*/
public static Consumer<String, String> createConsumer() {
Properties props = new Properties();
// Specify the ip address and port of the Kafka service
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127. 0.0.1:9092");
// AppointGroup.id, consumers in Kafka need to be in the consumer group
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test");
// Whether to turn on autocommit
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// Autocommit interval in milliseconds
props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// Serializer for message key
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// Serializer for message value
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<>(props);
}In the code above, you can see the settingsGroup.idThis configuration item, which is required for Consumer, is because in Kafka, Consumer needs to be in a Consumer Group.As shown in the following figure: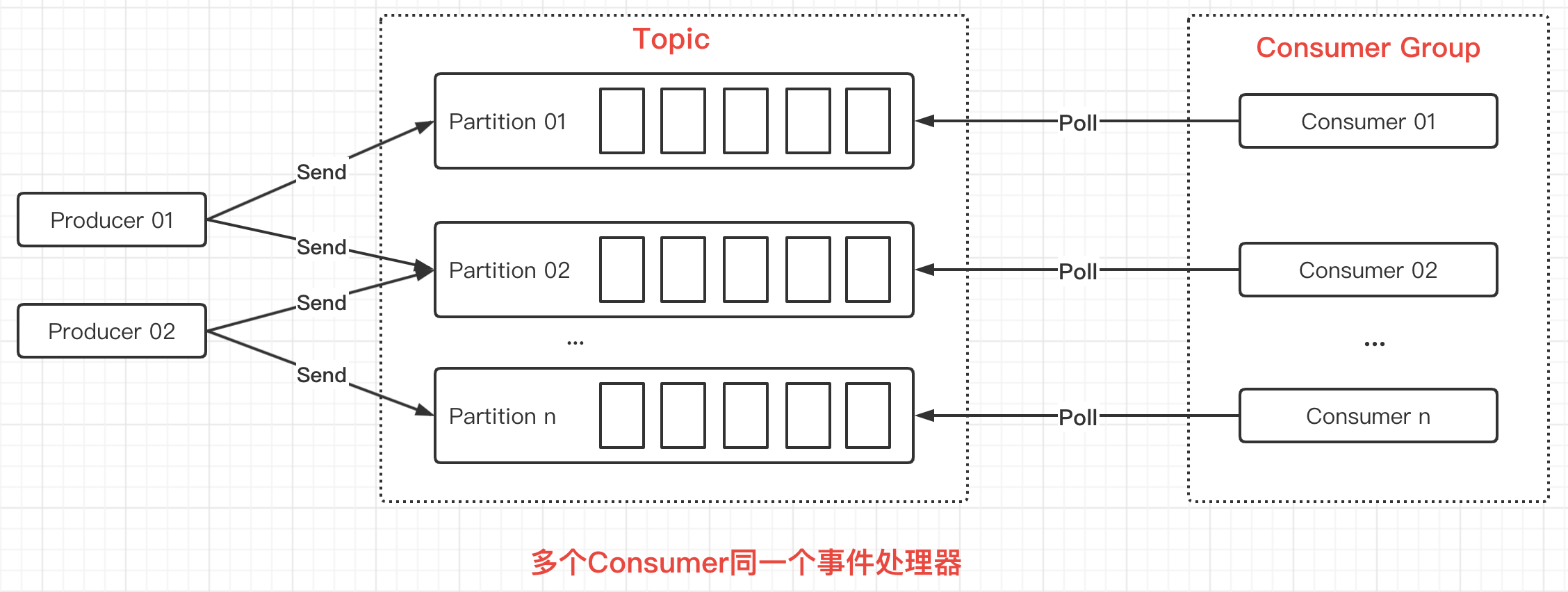
In the figure above, a Consumer consumes a Partition, which is a one-to-one relationship.However, there can be only one Consumer in the Consumer Group, where the Consumer can consume multiple Partitions, which is a one-to-many relationship.As shown in the following figure: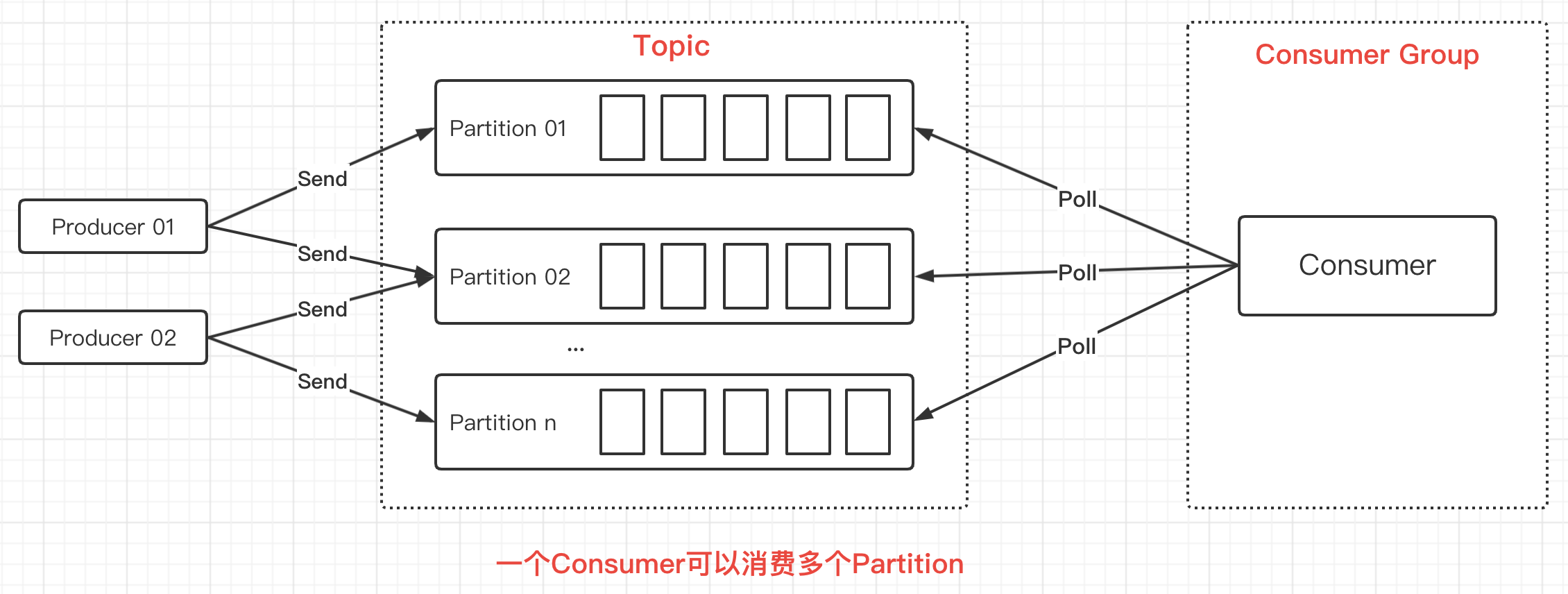
A Consumer can consume one or more Partitions, but it is important to note that multiple consumers cannot consume the same Partition: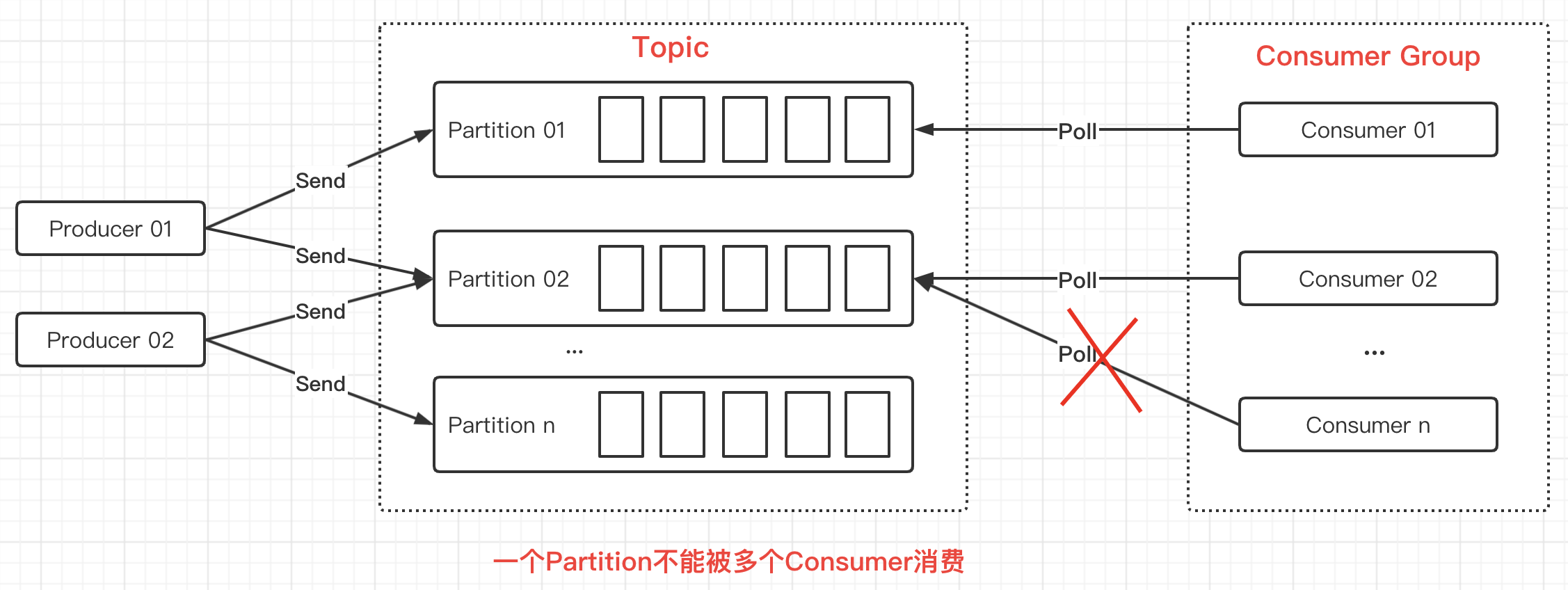
Summarize the Consumer's considerations:
- Messages from a single Partition can only be consumed by a Consumer in the Consumer Group
- Consumer consume messages from the Partition are sequential and start from scratch by default
- If there is only one Consumer in the Consumer Group, the Consumer consumes messages from all Partition s
In Kafka, when consumers consume data, offsets that submit data are required to tell the service what data was consumed successfully.Then the server will move the offset of the data, and the next time it consumes, it will start from the offset location.
This guarantees to some extent that the data is consumed successfully, and because the data will not be deleted, it will only move the offset of the data, which also guarantees that the data is not easy to lose.If the consumer fails to process the data, he or she can re-consume the next time he or she does not submit the offset.
Like database transactions, Kafka consumers submit offset s in two ways, automatic and manual.This example demonstrates automatic submission, which is also the simplest way to consume data.Code example:
/**
* Demo Autosubmit offset
*/
public static void autoCommitOffset() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// Subscribe to one or more Topic s
consumer.subscribe(topics);
while (true) {
// Pull data from Topic, once every 1000 milliseconds
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// Each pull may be a set of data that needs to be traversed
for (ConsumerRecord<String, String> record : records) {
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
}Consumer's Manual Submission
The automatic submission method is the simplest, but it is not recommended to be used in actual production because of its low controllability.So most of the time we use manual submission, but if you want to use manual submission, you need to turn off automatic submission first, modify the configuration items as follows:
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
Once autocommit is turned off, you have to call commit-related methods in your code to commit offset s, mainly commitAsync and commitSync, which are known by the method name as asynchronous commit and synchronous commit.
Here, commitAsync is taken as an example. The main idea is not to call the commitAsync method when an exception occurs, but to call the commitAsync method after normal execution.Code example:
/**
* Demo manual submission offset
*/
public static void manualCommitOffset() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// Subscribe to one or more Topic s
consumer.subscribe(topics);
while (true) {
// Pull data from Topic, once every 1000 milliseconds
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// Each pull may be a set of data that needs to be traversed
for (ConsumerRecord<String, String> record : records) {
try {
// Simulate writing data to the database
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// Do not call commit if the write fails, which acts as a rollback.
// Next consumption starts from previous offset s
e.printStackTrace();
return;
}
}
// Write success calls commit related method to submit offset manually
consumer.commitAsync();
}
}##Submit offset for Partition
As mentioned in the previous article, a Consumer Group can have only one Consumer, which can consume multiple Partitions.In this scenario, we might turn on Multithreading in Consumer to process data from multiple Partitions to improve performance.
To prevent data consumption in some Partitions from succeeding, while data consumption in some Partitions fails, offsets are submitted together.We need to submit offsets for a single Partition, that is, to control the submission granularity of offsets at the Partition level.
Here's a quick demonstration of how to submit offset s for a single Partition, code example:
/**
* Demonstrate offset for manually submitting a single Partition
*/
public static void manualCommitOffsetWithPartition() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// Subscribe to one or more Topic s
consumer.subscribe(topics);
while (true) {
// Pull data from Topic, once every 1000 milliseconds
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// Processing data in each Partition individually
for (TopicPartition partition : records.partitions()) {
System.out.println("======partition: " + partition + " start======");
// Remove data from Partition
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
try {
// Simulate writing data to the database
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// End directly with exception and do not submit offset
e.printStackTrace();
return;
}
}
// Execution success removes offset s currently consumed
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// Since the next time you start spending is the last offset+1, here you want to+1
OffsetAndMetadata metadata = new OffsetAndMetadata(lastOffset + 1);
// Submit offset for Partition
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(partition, metadata);
// Synchronous commit offset
consumer.commitSync(offsets);
System.out.println("======partition: " + partition + " end======");
}
}
}Consumer subscribes to one or more Partition s
In the previous example, we all subscribed to and consumed data for Topic, but we could actually subscribe to Partition s with a finer granularity, which is often used in a Consumer multi-threaded consumption scenario.Code example:
/**
* Demonstrates controlling subscription granularity to the Partition level
* Subscribe to a single or multiple Partition
*/
public static void manualCommitOffsetWithPartition2() {
Consumer<String, String> consumer = createConsumer();
// There are two Partition s in this Topic
TopicPartition p0 = new TopicPartition("MyTopic", 0);
TopicPartition p1 = new TopicPartition("MyTopic", 1);
// Subscribe to a Partition under the Topic
consumer.assign(List.of(p0));
// You can also subscribe to multiple Partition s under this Topic
// consumer.assign(List.of(p0, p1));
while (true) {
...Consistent with the code in the previous section, omitted...
}
}Consumer multithreaded concurrent processing
The first two subsections are basically paved for the multithreaded concurrent processing of messages described in this subsection, because in order to improve the processing efficiency of applications for messages, we usually use multithreads to consume messages in parallel, thus speeding up the processing of messages.
There are two main ways to process messages with multiple threads. One is to create threads in the number of Partitions, then create a Consumer in each thread, and multiple Consumers consume multiple Partitions.This is the same as the previous illustration given when introducing Consumer Group: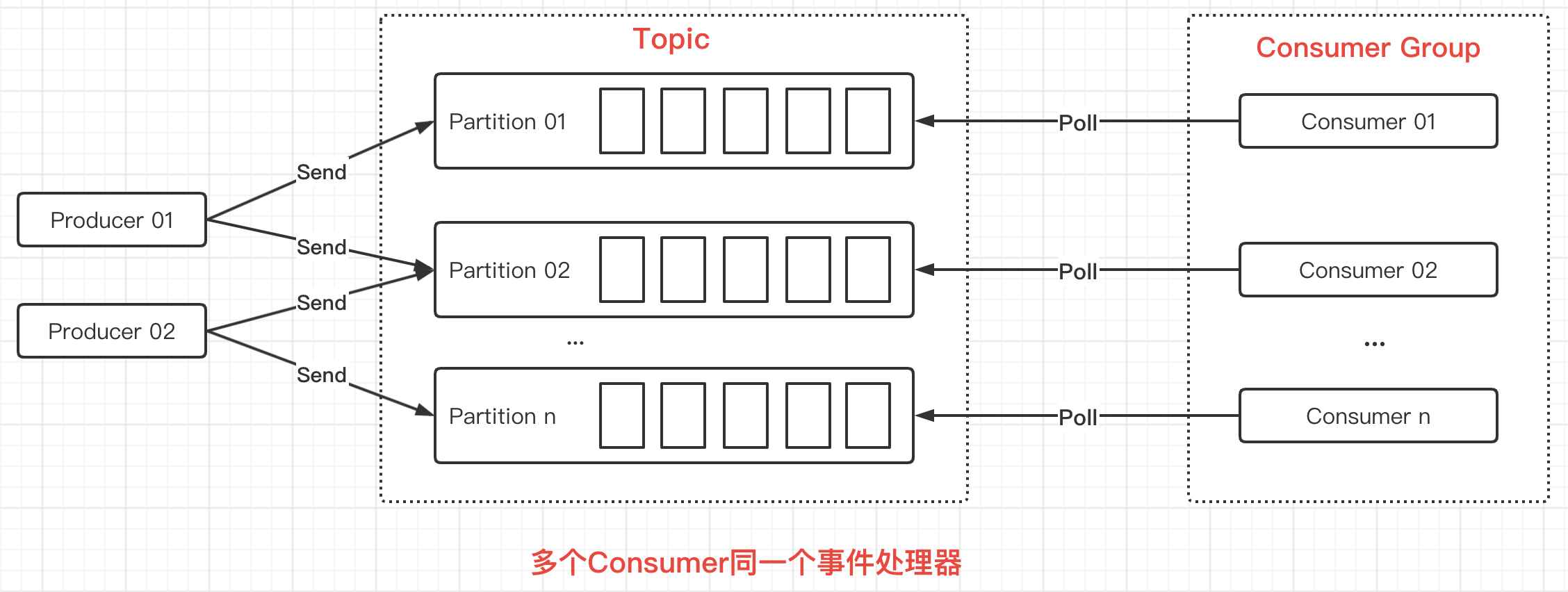
This is a classical pattern and is relatively simple to implement, suitable for scenarios where the order of messages and offset control are required.Code example:
package com.zj.study.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.WakeupException;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
/**
* Classic mode
*
* @author 01
* @date 2020-05-21
**/
public class ConsumerThreadSample {
private final static String TOPIC_NAME = "MyTopic";
/**
* This type is classic, with each thread creating a separate KafkaConsumer for thread safety
*/
public static void main(String[] args) throws InterruptedException {
KafkaConsumerRunner r1 = new KafkaConsumerRunner();
Thread t1 = new Thread(r1);
t1.start();
Thread.sleep(15000);
r1.shutdown();
}
public static class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer<String, String> consumer;
public KafkaConsumerRunner() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.220.128:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
TopicPartition p1 = new TopicPartition(TOPIC_NAME, 1);
consumer.assign(List.of(p0, p1));
}
@Override
public void run() {
try {
while (!closed.get()) {
//Processing messages
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
// Processing messages for each partition
for (ConsumerRecord<String, String> record : pRecord) {
System.out.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
// Go back and tell kafka about the new offset
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
// Note Plus 1
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} catch (WakeupException e) {
if (!closed.get()) {
throw e;
}
} finally {
consumer.close();
}
}
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
}Another multithreaded consumption method is to create only one Consumer instance in a thread pool, pull data through the Consumer, and leave it to the threads in the thread pool to process.As shown in the following figure: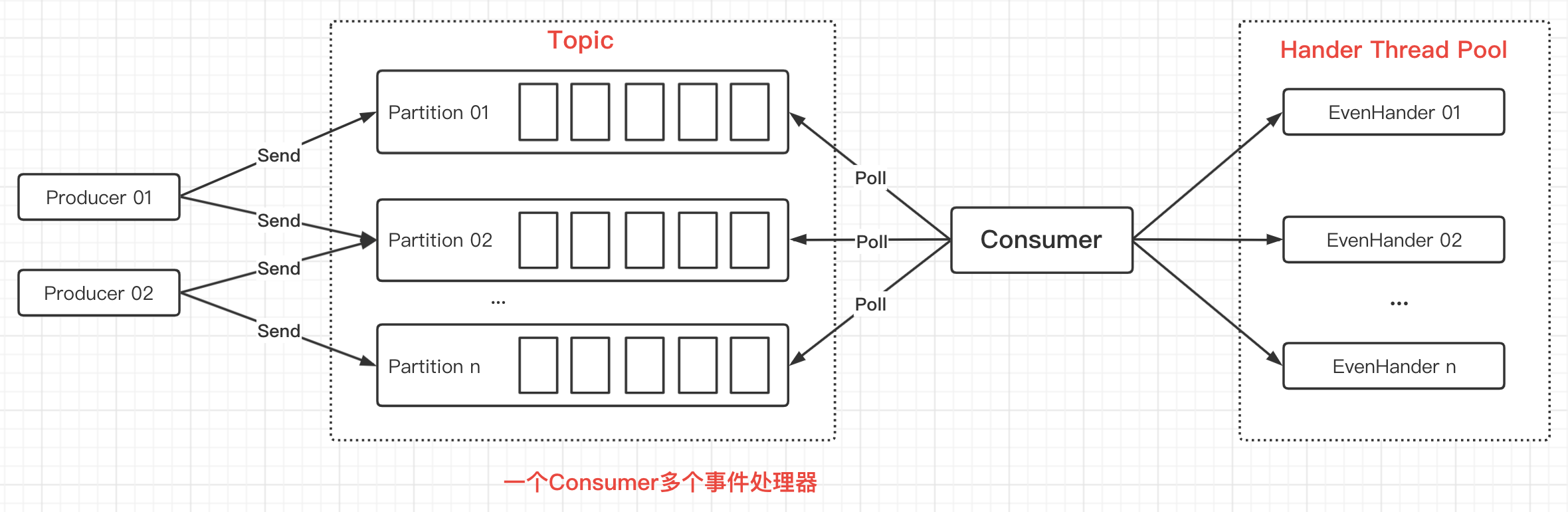
However, it is important to note that in this mode we cannot control the offset of the data manually, nor can we guarantee the sequentiality of the data, so it is often used in stream processing scenarios, which do not require the order and accuracy of the data.
From the previous example, we know that each pull returns a ConsumerRecords with multiple pieces of data in it.Then we iterate over ConsumerRecords, and we can put multiple pieces of data in parallel to multiple threads in the thread pool.Code example:
package com.zj.study.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* One Consumer, multiple hander modes
*
* @author 01
* @date 2020-05-21
**/
public class ConsumerRecordThreadSample {
private final static String TOPIC_NAME = "MyTopic";
public static void main(String[] args) throws InterruptedException {
String brokerList = "192.168.220.128:9092";
String groupId = "test";
int workerNum = 5;
ConsumerExecutor consumers = new ConsumerExecutor(brokerList, groupId, TOPIC_NAME);
consumers.execute(workerNum);
Thread.sleep(1000000);
consumers.shutdown();
}
/**
* Consumer Handle
*/
public static class ConsumerExecutor {
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
public ConsumerExecutor(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of(topic));
}
public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (final ConsumerRecord<String, String> record : records) {
executors.submit(new ConsumerRecordWorker(record));
}
}
}
public void shutdown() {
if (consumer != null) {
consumer.close();
}
if (executors != null) {
executors.shutdown();
}
try {
if (executors != null && !executors.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout.... Ignore for this case");
}
} catch (InterruptedException ignored) {
System.out.println("Other thread interrupted this shutdown, ignore for this case.");
Thread.currentThread().interrupt();
}
}
}
/**
* Record Processing
*/
public static class ConsumerRecordWorker implements Runnable {
private ConsumerRecord<String, String> record;
public ConsumerRecordWorker(ConsumerRecord<String, String> record) {
this.record = record;
}
@Override
public void run() {
// Suppose data entry
System.out.println("Thread - " + Thread.currentThread().getName());
System.err.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
}Consumer controls offset start location
The second multithreaded messaging model described in the previous section cannot control offset by pulling data through Consumer and leaving it to multithreaded processing. If errors or other unexpected events in the program result in messages not being consumed correctly, we need to control the starting location of offset artificially and re-consume them.
By calling the seek method, you can specify from which Partition and which offset location to consume, code example:
/**
* Manually control the starting position of offset
*/
public static void manualCommitOffsetWithPartition2() {
Consumer<String, String> consumer = createConsumer();
TopicPartition p0 = new TopicPartition("MyTopic", 0);
consumer.assign(List.of(p0));
// Specify the starting location of offset
consumer.seek(p0, 1);
while (true) {
...Consistent with the code in the previous section, omitted...
}
}Design ideas in practical applications:
- Consume for the first time from the start of an offset
- If 100 pieces of data are consumed this time, offset is set to 101 and stored in a cached database such as Redis
- Before each subsequent poll, get the offset value from Redis and consume it from where the offset started
- After consumption, store the new offset value in Redis again, week after week
Consumer Limit
To avoid a situation where excessive traffic in Kafka is hitting the Consumer side and crushing the consumer supply, we need to limit the flow to the consumer.For example, pause consumption when the amount of data processed reaches a certain threshold and resume consumption when it falls below that threshold, which allows consumers to maintain a certain rate of data consumption and thus avoid crushing consumers when traffic surges.The general idea is as follows:
- After poll ing the data, go to the token bucket to pick up the token
- Continue business processing if a token is obtained
- If a token is not available, call the pause method to pause Consumer and wait for the token
- When there are enough tokens in the token bucket, the resume method is called to restore Consumer consumption
Next, write a specific code case to briefly demonstrate this flow-limiting idea. The Token Bucket algorithm uses the built-in Guava, so you need to add a dependency on Guava to your project.The following dependencies were added:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>Then we can use Guava's current limiter to limit Constumer, code example:
public class ConsumerCurrentLimiting {
/*** Rate of token generation in seconds */
public static final int permitsPerSecond = 1;
/*** Current Limiter */
private static final RateLimiter LIMITER = RateLimiter.create(permitsPerSecond);
/**
* Create Consumer Instance
*/
public static Consumer<String, String> createConsumer() {
... Similar to the code in the previous section, omit ...
}
/**
* Demonstration of Constumer Current Limiting
*/
public static void currentLimiting() {
Consumer<String, String> consumer = createConsumer();
TopicPartition p0 = new TopicPartition("MyTopic", 0);
TopicPartition p1 = new TopicPartition("MyTopic", 1);
consumer.assign(List.of(p0, p1));
while (true) {
// Pull data from Topic, once every 100 milliseconds
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1));
if (records.isEmpty()) {
continue;
}
// Current Limiting
if (!LIMITER.tryAcquire()) {
System.out.println("Unable to get token, suspend consumption");
consumer.pause(List.of(p0, p1));
} else {
System.out.println("Get a token, restore consumption");
consumer.resume(List.of(p0, p1));
}
// Processing data in each Partition individually
for (TopicPartition partition : records.partitions()) {
System.out.println("======partition: " + partition + " start======");
// Remove data from Partition
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
try {
// Simulate writing data to the database
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// End directly with exception and do not submit offset
e.printStackTrace();
return;
}
}
// Execution success removes offset s currently consumed
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// Since the next time you start spending is the last offset+1, here you want to+1
OffsetAndMetadata metadata = new OffsetAndMetadata(lastOffset + 1);
// Submit offset for Partition
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(partition, metadata);
// Synchronous commit offset
consumer.commitSync(offsets);
System.out.println("======partition: " + partition + " end======");
}
}
}
public static void main(String[] args) {
currentLimiting();
}
}Consumer Rebalance Resolution
Consumer has a Rebalance feature, that is, reload balancing, which is implemented by a coordinator.Rebalance is triggered whenever a Consumer exits or a new Consumer joins the Consumer Group.
The reason for the reload balancing is to redistribute the data processed by the exiting Customer to other Consumers within the group for processing.Or when you have a newly joined Cusumer, redistribute the load pressure from the other Consumers in the group evenly, rather than saying that a newly joined Consumer is idle there.
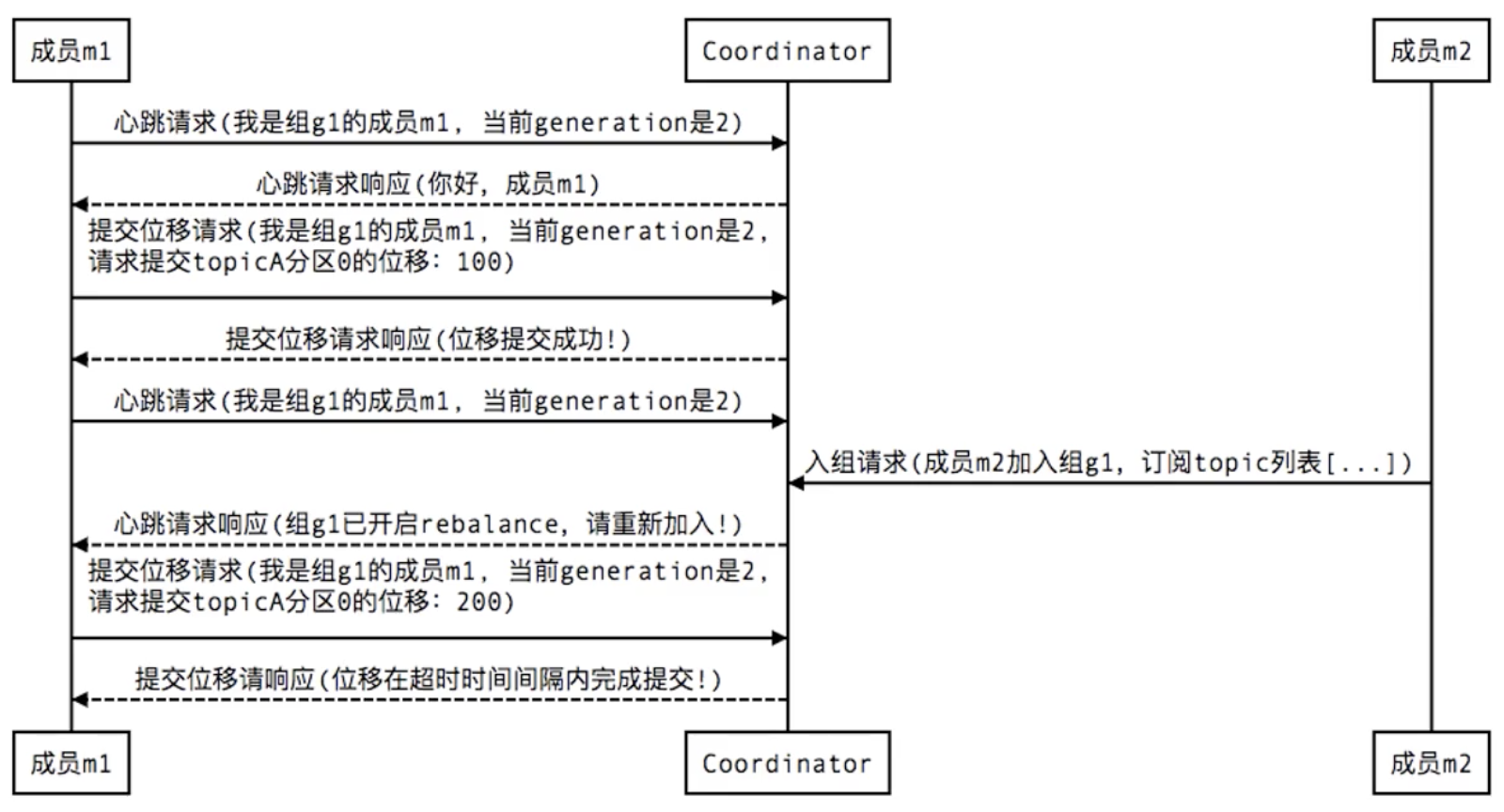
Here are a few diagrams that briefly describe how members of a group interact with the coordinator when a Rebalance is triggered in various situations.
1. New members join groups: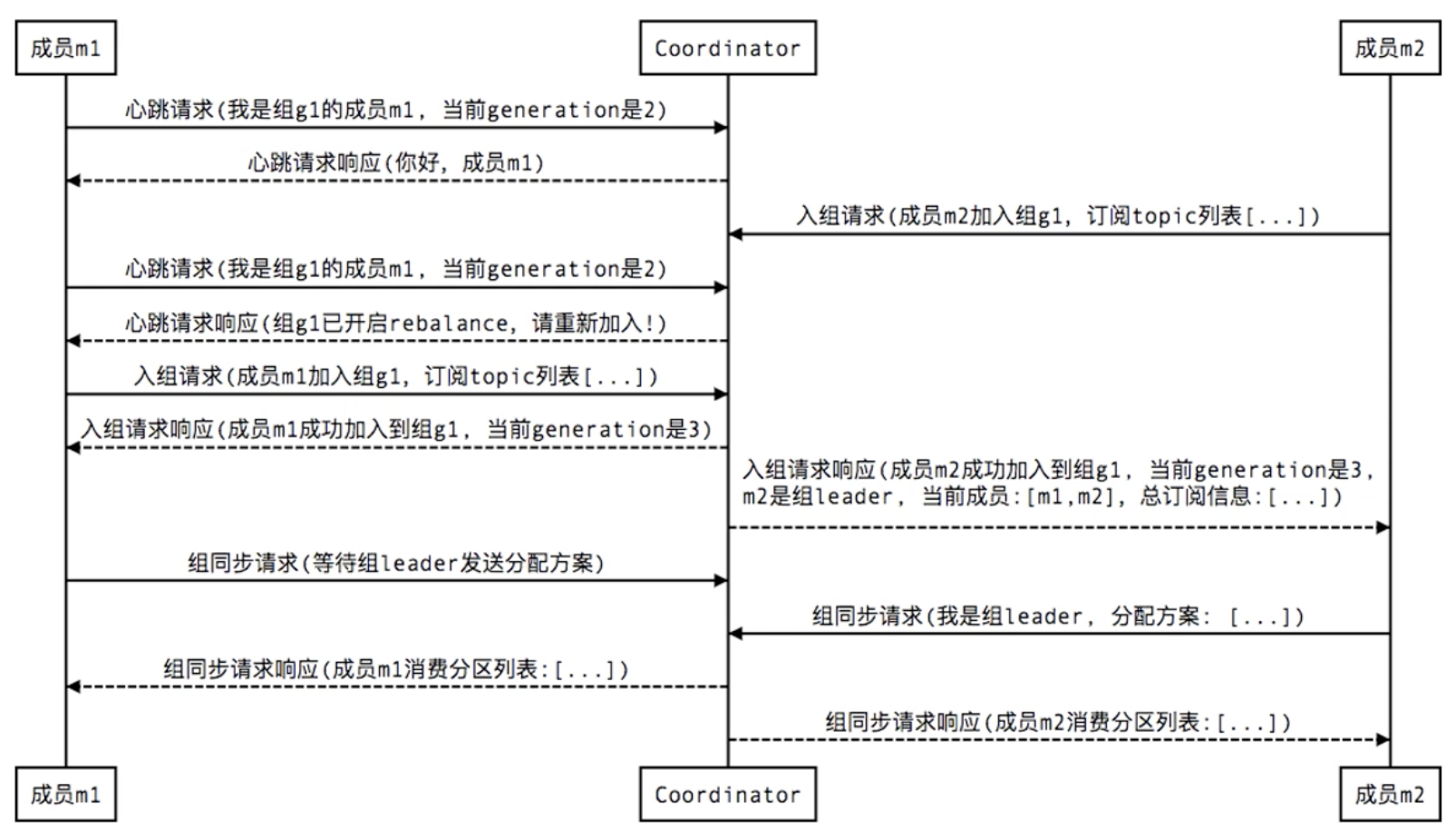
- Tips: The Coordinator in the diagram is the coordinator, while the generation is similar to the version number in the optimistic lock, which updates whenever a member enters the group successfully and acts as a concurrency control.
2. member failure:
3. Group members leave group voluntarily: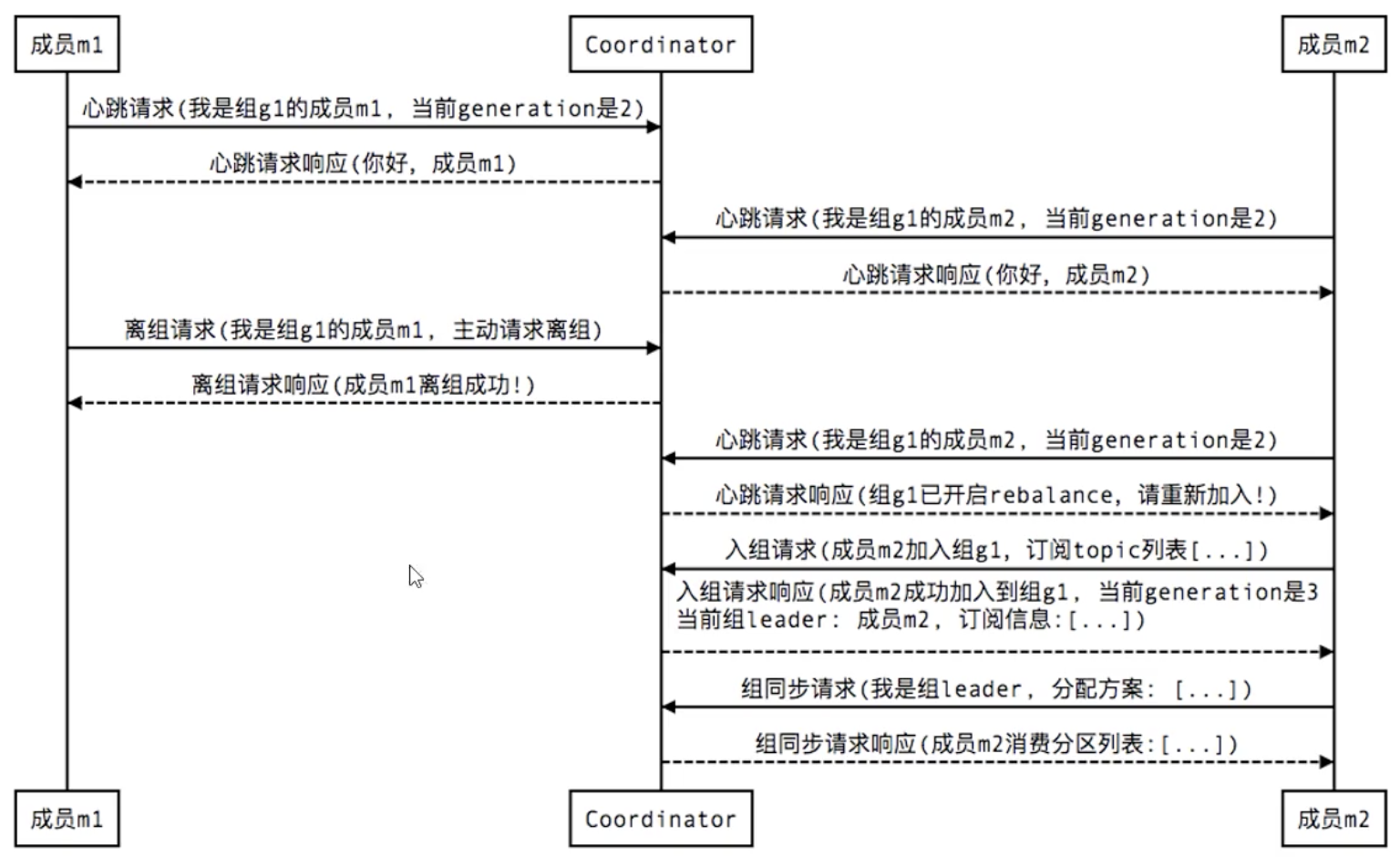
4. When the Consumer submits a member commit offset, a similar interaction occurs: