
1. General
Reprint: Idempotent real of Kafka transactional property
Starting from 0.11.0, Apache Kafka supports a very large feature, that is, transactional support. In Kafka, transactional has three meanings: one is idempotent support; Second, transactional support; The third is the implementation of exactly once of Kafka Streams. In the articles on Kafka transactional series, we only focus on the first two levels of transactional, and the contents related to Kafka Streams will not be discussed for the time being. The community began to discuss transactional issues for nearly half a year. There are more than 60 pages of relevant design documents (for reference) Exactly Once Delivery and Transactional Messaging in Kafka ). The implementation of transactional part is also very complex. The previous code implementation of Producer side is actually very simple. After adding transactional logic, the complexity of this part of the code has increased a lot. This and subsequent articles on transactional will take the code implementation of version 2.0.0 as an example to analyze this part. The plan is divided into five articles:
- Part I: implementation of Kafka idempotency;
- Part II: Kafka transactional implementation;
- Part III: how to process Kafka transaction related processing requests on the Server side and its implementation details;
- Chapter 4: Some Thoughts on the implementation of Kafka transactional. I will also briefly introduce the implementation of RocketMQ transactional and make a comparison;
- Chapter 5: how Flink + Kafka realizes Exactly Once;
This is the first article in Kafka transactional series. It mainly describes the overall process of idempotent implementation. Compared with transactional implementation, idempotent implementation is much simpler and the basis of transactional implementation.
2.Producer idempotency
The idempotency of Producer means that when the same message is sent, the data will only be persisted once on the Server side, and the data will not be lost or heavy. However, the idempotency here is conditional:
- It can only ensure that the Producer does not lose or lose weight in a single session. If the Producer hangs up unexpectedly, it cannot be restarted (in the case of idempotency, the previous state information cannot be obtained, so it is impossible to achieve cross session level non loss and non weight);
- Idempotency cannot span multiple topic partitions, but can only ensure idempotency within a single partition. When multiple topic partitions are involved, the intermediate states are not synchronized.
If you need to cross sessions and multiple topic partitions, you need to use Kafka's transactional.
3. Idempotent example
The example of Producer using idempotency is very simple. Compared with the normal use of Producer, it does not change much. You only need to enable the configuration of Producer Set the identotence to true, as shown below:
Properties props = new Properties();
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
props.put("acks", "all"); // When enable Idempotent is true, and the default here is all
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
producer.send(new ProducerRecord(topic, "test");
The interface reserved by prodcouer idempotency is very simple. Its bottom implementation encapsulates the upper application well. The application layer does not need to care about the specific implementation details and is very user-friendly.
4. Problems to be solved by idempotency
Before looking at how Producer implements idempotency, first consider a question: what problem does idempotency solve? Before 0.11.0, Kafka could ensure that data was not lost through the relevant configurations of Producer and Server, that is, at least once. However, in some cases, data duplication may occur, such as retry operations caused by network request delay, When sending a request for retry, the Server does not know whether the request has been processed (no previous status information is recorded), so it may lead to repeated sending of data requests, which is caused by Kafka's own mechanism (request retry mechanism in case of exception).
For most applications, data assurance can meet their needs, but for some other application scenarios (such as payment data, etc.), they require accurate counting. At this time, if the upstream data is repeated, the downstream applications can only perform corresponding de duplication operations when consuming data. When de duplication is applied, The most common method is to check the duplicate according to the unique id key.
In this scenario, the problem of data duplication caused by upstream production will cause all downstream applications with accurate counting requirements to do this complex and repeated de reprocessing. Just imagine: if the system can ensure exactly once when sending, how much relief it will be for the downstream. This is the problem to be solved by idempotency, mainly to solve the problem of data duplication. As mentioned earlier, the general solution to the problem of data duplication is to add a unique id, and then judge whether the data is repeated according to the id. the idempotency of Producer is also realized in this way. In this section, let's see how Kafka's Producer ensures that the data is exactly once.
5. Implementation principle of idempotency
Before describing the idempotency processing process, let's take a look at how Producer ensures idempotency. As mentioned earlier, the problem to be solved by idempotency is that when Producer sets at least once, the exception triggers the retry mechanism, resulting in data duplication. The purpose of idempotency is to solve the problem of data duplication. In short:
at least once + idempotent = exactly once
We can achieve exactly once by adding idempotency to al least once. Of course, there are restrictions on exactly once at this level. For example, it requires intra session validity or cross session transactional validity. Here we first analyze the simplest case, that is, how to achieve idempotency in a single session, so as to ensure exactly once.
To achieve idempotency, the following problems should be solved:
-
The system needs to be able to identify whether a piece of data is duplicate data? The common method is to judge by the unique key / unique id. at this time, the system generally needs to cache the processed unique key records, so as to judge whether a piece of data is repeated more efficiently;
-
What granularity should the unique key choose? For distributed storage systems, the global unique key cannot be used (the global key is for the cluster level). The core solution is still divide and conquer. In order to realize distribution, data intensive systems have the concept of partition, and there is corresponding isolation between partitions. For Kafka, the solution here is to do it in the dimension of partition, The leader of the partition is allowed to judge and process the duplicate data. The premise is that the unique key value needs to be told to the leader in the production request;
-
Is there any other problem with Partition granularity to realize the only key? The problem to be considered here is that when a Partition is written from multiple clients, it is difficult for these clients to use the same unique key (one is that it is difficult to realize the real-time perception of the unique key between them, and the other is whether such implementation is necessary). If the system achieves the granularity of client + partition during implementation, the advantage of this implementation is that each client is completely independent (there is no need for any connection between them, which is a great advantage). It is only necessary to distinguish different clients on the Server side, Of course, the same client can use the same PID when dealing with multiple topic partitions.
With the above analysis (all personal opinions, welcome advice if there is any error), it is not difficult to understand the implementation principle of Producer idempotency. Kafka Producer has the following two important mechanisms in its implementation:
-
PID (Producer ID), used to identify each producer client;
-
sequence numbers: each message sent by the client will carry a corresponding sequence number. The Server side will judge whether the data is repeated according to this value.
The two implementation mechanisms are described in detail below.
5.1 PID
Each Producer will be assigned a unique PID during initialization. This PID is transparent to the application and is not exposed to the user at all. For a given PID, the sequence number will increase automatically from 0, and each topic partition will have an independent sequence number. When the Producer sends data, it will identify each msg with a sequence number, which is used by the Server to verify whether the data is repeated. The PID here is globally unique. A new PID will be assigned after the restart of the Producer after failure, which is also one reason why idempotency cannot achieve cross session.
5.1.1 Producer PID application
Here's how PID is allocated on the Server side? The Client obtains the PID by sending an InitProducerIdRequest request to the Server (when idempotent, select a Broker with the least number of connections to send the request). Here is how the Server handles the request? The implementation of handleInitProducerIdRequest() method in KafkaApis is as follows:
def handleInitProducerIdRequest(request: RequestChannel.Request): Unit = {
val initProducerIdRequest = request.body[InitProducerIdRequest]
val transactionalId = initProducerIdRequest.transactionalId
if (transactionalId != null) { //note: set TxN ID, verify for TxN Permission of ID
if (!authorize(request.session, Write, Resource(TransactionalId, transactionalId, LITERAL))) {
sendErrorResponseMaybeThrottle(request, Errors.TRANSACTIONAL_ID_AUTHORIZATION_FAILED.exception)
return
}
} else if (!authorize(request.session, IdempotentWrite, Resource.ClusterResource)) { //note: TxN is not set ID, verify whether you have idempotent permissions on the cluster
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
def sendResponseCallback(result: InitProducerIdResult): Unit = {
def createResponse(requestThrottleMs: Int): AbstractResponse = {
val responseBody = new InitProducerIdResponse(requestThrottleMs, result.error, result.producerId, result.producerEpoch)
trace(s"Completed $transactionalId's InitProducerIdRequest with result $result from client ${request.header.clientId}.")
responseBody
}
sendResponseMaybeThrottle(request, createResponse)
}
//note: the corresponding pid is generated and returned to producer
txnCoordinator.handleInitProducerId(transactionalId, initProducerIdRequest.transactionTimeoutMs, sendResponseCallback)
}
In fact, the handleInitProducerId() method of the TransactionCoordinator (the Broker will initialize this instance when starting the server service) is called to do the corresponding processing. The implementation is as follows (only the idempotence processing is concerned here):
def handleInitProducerId(transactionalId: String,
transactionTimeoutMs: Int,
responseCallback: InitProducerIdCallback): Unit = {
if (transactionalId == null) { //note: when only idempotency is set, pid is directly allocated and returned
// if the transactional id is null, then always blindly accept the request
// and return a new producerId from the producerId manager
val producerId = producerIdManager.generateProducerId()
responseCallback(InitProducerIdResult(producerId, producerEpoch = 0, Errors.NONE))
}
...
}
When the Server initializes a PID for a client, it actually generates a PID through the generateProducerId() method of the ProducerIdManager.
5.1.2 Server PID management
As mentioned earlier, in the case of idempotency, a PID is generated directly through the generateProducerId() method of the ProducerIdManager. The ProducerIdManager is initialized when the TransactionCoordinator object is initialized. This object is mainly used to manage PID information:
-
When the local PID end is used up or in the new state, apply for PID segments (by default, apply for 1000 PIDs each time);
-
The TransactionCoordinator object obtains the next available PID through the generateProducerId() method;
PID side application is to apply to ZooKeeper, and there is a / latest in zk_ producer_ id_ Block node. After applying for a PID segment from zk, each Broker will write the PID segment information applied by itself to this node. In this way, when other brokers apply for a PID segment again, they will first read and write the information of this node, and then according to the block_end select a PID segment, and finally write the information to this node of zk. The information format of this node is as follows:
{"version":1,"broker":35,"block_start":"4000","block_end":"4999"}
The method of ProducerIdManager applying for PID segment from zk is as follows:
private def getNewProducerIdBlock(): Unit = {
var zkWriteComplete = false
while (!zkWriteComplete) { //note: until the allocated PID segment is taken from zk
// refresh current producerId block from zookeeper again
val (dataOpt, zkVersion) = zkClient.getDataAndVersion(ProducerIdBlockZNode.path)
// generate the new producerId block
currentProducerIdBlock = dataOpt match {
case Some(data) =>
//note: get the latest pid information from zk. If the subsequent update fails, you will get it again from zk
val currProducerIdBlock = ProducerIdManager.parseProducerIdBlockData(data)
debug(s"Read current producerId block $currProducerIdBlock, Zk path version $zkVersion")
if (currProducerIdBlock.blockEndId > Long.MaxValue - ProducerIdManager.PidBlockSize) {//note: not enough to allocate 1000 PID s
// we have exhausted all producerIds (wow!), treat it as a fatal error
//note: when the PID allocation exceeds the limit, it will directly report an error (allocate one per second, which is enough for 20 billion years)
fatal(s"Exhausted all producerIds as the next block's end producerId is will has exceeded long type limit (current block end producerId is ${currProducerIdBlock.blockEndId})")
throw new KafkaException("Have exhausted all producerIds.")
}
ProducerIdBlock(brokerId, currProducerIdBlock.blockEndId + 1L, currProducerIdBlock.blockEndId + ProducerIdManager.PidBlockSize)
case None => //note: the node does not exist yet. It is initialized for the first time
debug(s"There is no producerId block yet (Zk path version $zkVersion), creating the first block")
ProducerIdBlock(brokerId, 0L, ProducerIdManager.PidBlockSize - 1)
}
val newProducerIdBlockData = ProducerIdManager.generateProducerIdBlockJson(currentProducerIdBlock)
// try to write the new producerId block into zookeeper
//note: write the new pid information to zk. If the writing fails (the zkVersion will be compared before writing. If this changes, it proves that there are other brokers operating during this period, then the writing fails), re apply
val (succeeded, version) = zkClient.conditionalUpdatePath(ProducerIdBlockZNode.path,
newProducerIdBlockData, zkVersion, Some(checkProducerIdBlockZkData))
zkWriteComplete = succeeded
if (zkWriteComplete)
info(s"Acquired new producerId block $currentProducerIdBlock by writing to Zk with path version $version")
}
}
The process of applying for PID segment by ProducerIdManager is as follows:
-
Start with / latest of zk_ producer_ id_ The block node reads the latest allocated PID segment information;
-
If the node does not exist, allocate directly from 0 and select a PID segment of 0 ~ 1000 (the PidBlockSize of producer idmanager defaults to 1000, that is, the PID segment size of each application);
-
If the node exists, read the data in it according to the block_end select this PID segment (if the PID segment exceeds the maximum value of Long type, an exception will be returned directly here);
-
After selecting the corresponding PID segment, write the PID segment information back to the node of zk. If the writing is successful, the PID segment proves that the application is successful, If the write fails (it will be judged whether the zkVersion of the current node is the same as the zkVersion obtained in step 1 when writing. If it is the same, it can be written successfully, otherwise the write will fail, which proves that the node has been modified), it proves that other brokers may have updated the node at this time (the current PID segment may have been applied by other brokers), Then restart from step 1 until the writing is successful.
After understanding how the ProducerIdManager applies for the PID segment, it is much simpler to look at the method generateProducerId(). This method will update the nextProducerId value every time it is called (the PID value can be used next time), as shown below
def generateProducerId(): Long = {
this synchronized {
// grab a new block of producerIds if this block has been exhausted
if (nextProducerId > currentProducerIdBlock.blockEndId) {
//note: if the allocated pid runs out, re apply to zk for another batch
getNewProducerIdBlock()
nextProducerId = currentProducerIdBlock.blockStartId + 1
} else {
nextProducerId += 1
}
nextProducerId - 1 //note: returns the currently allocated pid
}
}
Here is how to apply for Producer PID (the application of PID in transactional cases will be more complex, which will be described in the next article) and how to manage PID on the Server side.
5.2 sequence numbers
After having the pid, add a sequence numbers information on the pid + topic partition level to realize the idempotency of the Producer. ProducerBatch also provides a setProducerState() method, which can add some meta information (pid, baseSequence, isTransactional) to a batch. These information will be sent to the Server side along with the ProduceRequest, and the Server side will make corresponding judgments through these meta information, as shown below:
// ProducerBatch
public void setProducerState(ProducerIdAndEpoch producerIdAndEpoch, int baseSequence, boolean isTransactional) {
recordsBuilder.setProducerState(producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, baseSequence, isTransactional);
}
// MemoryRecordsBuilder
public void setProducerState(long producerId, short producerEpoch, int baseSequence, boolean isTransactional) {
if (isClosed()) {
// Sequence numbers are assigned when the batch is closed while the accumulator is being drained.
// If the resulting ProduceRequest to the partition leader failed for a retriable error, the batch will
// be re queued. In this case, we should not attempt to set the state again, since changing the producerId and sequence
// once a batch has been sent to the broker risks introducing duplicates.
throw new IllegalStateException("Trying to set producer state of an already closed batch. This indicates a bug on the client.");
}
this.producerId = producerId;
this.producerEpoch = producerEpoch;
this.baseSequence = baseSequence;
this.isTransactional = isTransactional;
}
5.3 overall process of idempotency realization
After the two implementation mechanisms of Kafka idempotency (PID+sequence numbers) are described above, here we will describe in detail the overall processing flow of idempotency, mainly about the contents related to idempotency, Other parts will be briefly introduced (you can refer to the previous [Kafka source code analysis series articles] to understand the Producer side processing process and the Server side processing process of the ProduceRequest request request). The process is shown in the following figure:
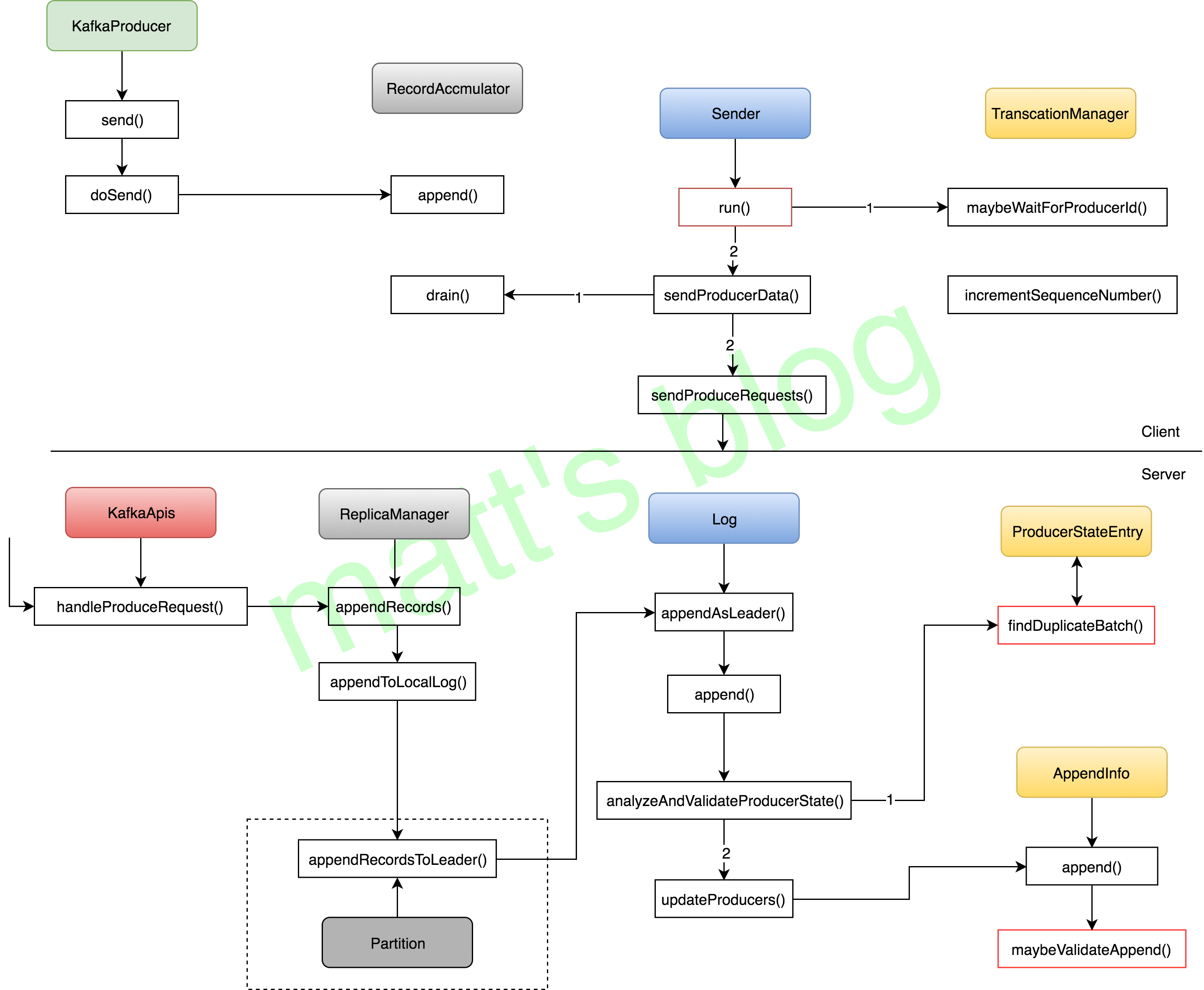
This figure only shows the general process of Producer in the case of idempotency. Many parts have been analyzed in the previous article, which will not be described in this paper. Here, we focus on the content related to idempotency (the implementation of transactional is more complex, which will be described in the later article). First, KafkaProducer will initialize a TransactionManager instance during initialization, Its functions include the following parts:
- Record the local transaction status (required when transactional);
- Record some status information to ensure idempotency, such as the next sequence numbers corresponding to each topic partition and the maximum sequence number of the last acked batch (the latest confirmed batch);
- Record the ProducerIdAndEpoch information (PID information).
5.4 sending process when client is idempotent
As shown in the previous figure, when idempotent, the sending process of Producer is as follows:
-
The application adds data to the RecordAccumulator through KafkaProducer's send() method. When adding, it will judge whether it is necessary to create a new producebatch. At this time, the producebatch still has no PID and sequence number information;
-
The Producer background sending thread Sender, in the run() method, will first judge whether the current PID needs to be reset according to the shouldrestproducerstateafterresolvingsequences() method of the TransactionManager. The reason for the reset is: if there are batch retries of topic partition that fail for many times and are finally removed due to timeout, At this time, the sequence number cannot be continuous because some of the sequence number has been allocated. At this time, the system cannot continue relying on its own mechanism (because idempotency is to ensure no loss and no duplication). It is equivalent to that the program encounters a fatal exception, and the PID will be reset, The cache information related to the TransactionManager is cleared (the Producer will not restart), but the TransactionManager that saves the status information has done the clear+new operation. In case of this problem, it cannot be guaranteed to be exactly once (some data has failed to be sent, and the number of retries has exceeded);
-
The Sender thread judges whether to apply for PID through the maybeWaitForProducerId() method. If necessary, it will block here until the corresponding PID information is obtained;
-
The Sender thread sends data through the sendProducerData() method. The overall process is similar to the previous Producer process. The difference is that in the drain() method of RecordAccumulator, after adding idempotency, the drain() method has the following additional steps to judge:
- Conventional judgment: judge whether the topic partition can continue to be sent (if the situation in the previous 2 is not allowed to be sent), judge whether the PID is valid, and judge whether there are batches that have not been sent before the batch if the batch is a retry batch. If so, the sending of the topic partition will be skipped first, Until the previous batch is sent, the in flight request of this topic partition will be reduced to 1 in the worst case (this involves a setting on the server side, which will be analyzed in detail below);
- If the ProducerBatch does not have the corresponding PID and sequence number information, it will be set here;
-
Finally, the Sender thread calls the sendProduceRequests() method to send a ProduceRequest request, and the subsequent process is consistent with the previous normal process.
Let's look at the implementation of the following key methods. The first is the method maybeWaitForProducerId() used by the Sender thread to obtain PID information, which is implemented as follows:
//note: wait until the Producer obtains the corresponding PID and epoch information
private void maybeWaitForProducerId() {
while (!transactionManager.hasProducerId() && !transactionManager.hasError()) {
try {
Node node = awaitLeastLoadedNodeReady(requestTimeoutMs); //note: select node (the node with the least number of local connections)
if (node != null) {
ClientResponse response = sendAndAwaitInitProducerIdRequest(node); //note: send InitPidRequest
InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response.responseBody();
Errors error = initProducerIdResponse.error();
if (error == Errors.NONE) { //note: update PID and epoch information of Producer
ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(
initProducerIdResponse.producerId(), initProducerIdResponse.epoch());
transactionManager.setProducerIdAndEpoch(producerIdAndEpoch);
return;
} else if (error.exception() instanceof RetriableException) {
log.debug("Retriable error from InitProducerId response", error.message());
} else {
transactionManager.transitionToFatalError(error.exception());
break;
}
} else {
log.debug("Could not find an available broker to send InitProducerIdRequest to. " +
"We will back off and try again.");
}
} catch (UnsupportedVersionException e) {
transactionManager.transitionToFatalError(e);
break;
} catch (IOException e) {
log.debug("Broker {} disconnected while awaiting InitProducerId response", e);
}
log.trace("Retry InitProducerIdRequest in {}ms.", retryBackoffMs);
time.sleep(retryBackoffMs);
metadata.requestUpdate();
}
}
Let's take another look at the drain() method of RecordAccumulator. The focus should be on the processing of idempotency and transactional correlation, as shown below. The judgment of transactional correlation has been described in the above process.
/**
* Drain all the data for the given nodes and collate them into a list of batches that will fit within the specified
* size on a per-node basis. This method attempts to avoid choosing the same topic-node over and over.
*
* @param cluster The current cluster metadata
* @param nodes The list of node to drain
* @param maxSize The maximum number of bytes to drain
* @param now The current unix time in milliseconds
* @return A list of {@link ProducerBatch} for each node specified with total size less than the requested maxSize.
*/
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster,
Set<Node> nodes,
int maxSize,
long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
Map<Integer, List<ProducerBatch>> batches = new HashMap<>();
for (Node node : nodes) {
int size = 0;
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
List<ProducerBatch> ready = new ArrayList<>();
/* to make starvation less likely this loop doesn't start at 0 */
int start = drainIndex = drainIndex % parts.size();
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
// Only proceed if the partition has no in-flight batches.
if (!isMuted(tp, now)) {
Deque<ProducerBatch> deque = getDeque(tp);
if (deque != null) {
synchronized (deque) { //note: first judge whether there is data, and then lock it later when it is actually processed
ProducerBatch first = deque.peekFirst();
if (first != null) {
boolean backoff = first.attempts() > 0 && first.waitedTimeMs(now) < retryBackoffMs;
// Only drain the batch if it is not during backoff period.
if (!backoff) {
if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) {
// there is a rare case that a single batch size is larger than the request size due
// to compression; in this case we will still eventually send this batch in a single
// request
break;
} else {
ProducerIdAndEpoch producerIdAndEpoch = null;
boolean isTransactional = false;
if (transactionManager != null) { //note: when idempotent or transactional, make some checks and judgments
if (!transactionManager.isSendToPartitionAllowed(tp))
break;
producerIdAndEpoch = transactionManager.producerIdAndEpoch();
if (!producerIdAndEpoch.isValid()) //Note: is PID valid
// we cannot send the batch until we have refreshed the producer id
break;
isTransactional = transactionManager.isTransactional();
if (!first.hasSequence() && transactionManager.hasUnresolvedSequence(first.topicPartition))
//note: the current topic partition data has timed out and cannot be sent. If it is new batch data, skip it directly (there is no SEQ number information)
// Don't drain any new batches while the state of previous sequence numbers
// is unknown. The previous batches would be unknown if they were aborted
// on the client after being sent to the broker at least once.
break;
int firstInFlightSequence = transactionManager.firstInFlightSequence(first.topicPartition);
if (firstInFlightSequence != RecordBatch.NO_SEQUENCE && first.hasSequence()
&& first.baseSequence() != firstInFlightSequence)
//note: retry the operation (seq number is not 0), if the baseSequence of this batch is different from in flight
//Note: if the baseSequence of the first request batch in the queue is different (it proves that there are unsuccessful requests in front of it),
//note: it will wait for the next cycle before judging. In the worst case, it will cause the in flight request to be 1 (only this partition is affected)
//note: in this case, it is meaningless to continue sending this, because the order is guaranteed in idempotency. Only if the previous ones are successful, the subsequent resending is meaningful
//note: here is a break, which is equivalent to directly skipping the sending of this topic partition in this sending
// If the queued batch already has an assigned sequence, then it is being
// retried. In this case, we wait until the next immediate batch is ready
// and drain that. We only move on when the next in line batch is complete (either successfully
// or due to a fatal broker error). This effectively reduces our
// in flight request count to 1.
break;
}
ProducerBatch batch = deque.pollFirst();
if (producerIdAndEpoch != null && !batch.hasSequence()) {//note: batch related information (seq id) is set here
//note: this batch has no seq number information
// If the batch already has an assigned sequence, then we should not change the producer id and
// sequence number, since this may introduce duplicates. In particular,
// the previous attempt may actually have been accepted, and if we change
// the producer id and sequence here, this attempt will also be accepted,
// causing a duplicate.
//
// Additionally, we update the next sequence number bound for the partition,
// and also have the transaction manager track the batch so as to ensure
// that sequence ordering is maintained even if we receive out of order
// responses.
//note: set the corresponding pid, seq id and other information for this batch
batch.setProducerState(producerIdAndEpoch, transactionManager.sequenceNumber(batch.topicPartition), isTransactional);
transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount); //note: add the next seq id value corresponding to the partition
log.debug("Assigned producerId {} and producerEpoch {} to batch with base sequence " +
"{} being sent to partition {}", producerIdAndEpoch.producerId,
producerIdAndEpoch.epoch, batch.baseSequence(), tp);
transactionManager.addInFlightBatch(batch);
}
batch.close();
size += batch.records().sizeInBytes();
ready.add(batch);
batch.drained(now);
}
}
}
}
}
}
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
batches.put(node.id(), ready);
}
return batches;
}
5.5 how does the Server handle the ProduceRequest request when idempotent
As shown in the previous en route, after the Broker receives the ProduceRequest request, it will handle it through handleProduceRequest(). The processing flow is as follows (here is only about idempotency):
-
If the request is a transaction request, check whether it is valid for TxN ID has Write permission. If not, transaction will be returned_ ID_ AUTHORIZATION_ FAILED;
-
If idempotency is set in the request, check whether you have IdempotentWrite permission for ClusterResource. If not, return CLUSTER_AUTHORIZATION_FAILED;
-
Verify whether you have Write permission on topic and whether topic exists. Otherwise, return to TOPIC_AUTHORIZATION_FAILED or UNKNOWN_TOPIC_OR_PARTITION exception;
-
Check whether there is PID information. If not, follow the normal writing process;
-
The LOG object will first check whether the batch is repeated according to the sequence number information of the batch in the analyzeAndValidateProducerState() method (the server side will cache the information of the last five batches of the PID corresponding to the topic partition). If there is a repetition, Here, it is returned as successful writing (the corresponding status information in the LOG object is not updated, such as the end offset of the replica);
-
When the PID information is available and the batch is not repeated, the following checks will be performed when updating the producer information:
- Check whether the PID exists in the cache (mainly in the ProducerStateManager object);
- If it does not exist, judge whether the sequence number starts from 0. If so, record the meta (PID, epoch, sequence number) of PID in the cache and execute the write operation, Otherwise, it returns UnknownProducerIdException (the PID has expired on the server side or the data written by the PID has expired, but the Client is still sending data after the last sequence number);
- If the PID exists, first check whether the PID epoch is the same as that recorded on the server side;
- If it is different and the sequence number does not start from 0, an OutOfOrderSequenceException exception is returned;
- If it is different and the sequence number starts from 0, it is written normally;
- If it is the same, check whether it is continuous according to the latest sequence number (currentLastSeq) recorded in the cache (0, Int.MaxValue, etc.), and return OutOfOrderSequenceException exception in case of discontinuity.
-
The following is the same as normal writing.
During idempotency, the Broker has more verification operations when processing the ProduceRequest request. Here, we will focus on some important implementations. First, we will look at the implementation of the analyzeAndValidateProducerState() method, as shown below:
private def analyzeAndValidateProducerState(records: MemoryRecords, isFromClient: Boolean): (mutable.Map[Long, ProducerAppendInfo], List[CompletedTxn], Option[BatchMetadata]) = {
val updatedProducers = mutable.Map.empty[Long, ProducerAppendInfo]
val completedTxns = ListBuffer.empty[CompletedTxn]
for (batch <- records.batches.asScala if batch.hasProducerId) { //note: the corresponding judgment will be made only when there is pid
val maybeLastEntry = producerStateManager.lastEntry(batch.producerId)
// if this is a client produce request, there will be up to 5 batches which could have been duplicated.
// If we find a duplicate, we return the metadata of the appended batch to the client.
if (isFromClient) {
maybeLastEntry.flatMap(_.findDuplicateBatch(batch)).foreach { duplicate =>
return (updatedProducers, completedTxns.toList, Some(duplicate)) //note: if this batch has been received, it will be returned directly here
}
}
val maybeCompletedTxn = updateProducers(batch, updatedProducers, isFromClient = isFromClient) //note: here
maybeCompletedTxn.foreach(completedTxns += _)
}
(updatedProducers, completedTxns.toList, None)
}
If the batch has PID information, it will first check whether the batch is duplicate batch data. Its implementation is as follows. batchMetadata will cache the data of the latest five batches (if more than five, it will be deleted when adding. This is also the reason why the idempotency requirement MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION is less than or equal to 5, which is related to the setting of this value), Judge whether this batch is duplicate data according to the batch data cached by batchMetadata.
def findDuplicateBatch(batch: RecordBatch): Option[BatchMetadata] = {
if (batch.producerEpoch != producerEpoch)
None
else
batchWithSequenceRange(batch.baseSequence, batch.lastSequence)
}
// Return the batch metadata of the cached batch having the exact sequence range, if any.
def batchWithSequenceRange(firstSeq: Int, lastSeq: Int): Option[BatchMetadata] = {
val duplicate = batchMetadata.filter { metadata =>
firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq
}
duplicate.headOption
}
private def addBatchMetadata(batch: BatchMetadata): Unit = {
if (batchMetadata.size == ProducerStateEntry.NumBatchesToRetain)
batchMetadata.dequeue() //note: only the records of the last five batch es will be kept
batchMetadata.enqueue(batch) //note: add it to the record in batchMetadata to facilitate subsequent judgment of whether it is repeated according to seq id
}
If the batch is not duplicate data, analyzeAndValidateProducerState() will update the corresponding records of the producer through updateProducers(). In the process of updating, one-step verification will be performed. The verification method is as follows:
//note: check seq number
private def checkSequence(producerEpoch: Short, appendFirstSeq: Int): Unit = {
if (producerEpoch != updatedEntry.producerEpoch) { //note: epoch is different
if (appendFirstSeq != 0) { //note: at this time, it is required that the seq number must start from 0 (if not, the PID may be newly created or the PID has expired on the Server side)
//Note: the pid has expired (updatedentry.produceepoch is not - 1, the original pid expired at the time of certification)
if (updatedEntry.producerEpoch != RecordBatch.NO_PRODUCER_EPOCH) {
throw new OutOfOrderSequenceException(s"Invalid sequence number for new epoch: $producerEpoch " +
s"(request epoch), $appendFirstSeq (seq. number)")
} else { //Note: the PID has expired (updatedentry.produceepoch is - 1, which proves that the server side meta is newly created, the PID has expired on the server side, and the client is still sending data after the last seq)
throw new UnknownProducerIdException(s"Found no record of producerId=$producerId on the broker. It is possible " +
s"that the last message with t()he producerId=$producerId has been removed due to hitting the retention limit.")
}
}
} else {
val currentLastSeq = if (!updatedEntry.isEmpty)
updatedEntry.lastSeq
else if (producerEpoch == currentEntry.producerEpoch)
currentEntry.lastSeq
else
RecordBatch.NO_SEQUENCE
if (currentLastSeq == RecordBatch.NO_SEQUENCE && appendFirstSeq != 0) {
//note: at this time, the expected seq number starts from 0, because currentLastSeq is - 1, which means that the pid has not written data
// the epoch was bumped by a control record, so we expect the sequence number to be reset
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: found $appendFirstSeq " +
s"(incoming seq. number), but expected 0")
} else if (!inSequence(currentLastSeq, appendFirstSeq)) {
//note: judge whether it is continuous
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: $appendFirstSeq " +
s"(incoming seq. number), $currentLastSeq (current end sequence number)")
}
}
}
The verification logic is described in the previous process.
6. Small thoughts
Here we mainly think about two questions:
-
Why does Producer require Max when setting idempotency_ IN_ FLIGHT_ REQUESTS_ PER_ If the connection is less than or equal to 5, what consequences will it bring if it is set to be greater than 5 (regardless of the error of Producer side parameter verification)?
-
When Producer sets idempotency, if we set max_ IN_ FLIGHT_ REQUESTS_ PER_ If connection is greater than 1, can order be guaranteed? If so, how?
Let's talk about the conclusion first. In fact, the setting requirements of question 1 have been described in the above analysis, which is mainly related to the mechanism that the server side will only cache the last five batch es; Question 2, even Max_ IN_ FLIGHT_ REQUESTS_ PER_ If connection is greater than 1, order can still be achieved when idempotent. Let's analyze these two problems in detail.
Why MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION less than or equal to 5
In fact, here, Max is required_ IN_ FLIGHT_ REQUESTS_ PER_ The main reason why connection is less than or equal to 5 is that the ProducerStateManager instance on the Server side will cache the last five batch data sent by each PID on each topic partition (this 5 is written dead, and the reason why it is 5 may be related to experience. When idempotency is not set, the performance is relatively high when it is set to 5. The community has a relevant test document and has forgotten where it is). If it exceeds 5, the producer statemanager will clear the oldest batch data.
Suppose the application will be MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION is set to 6. Suppose the order of requests sent is 1, 2, 3, 4, 5 and 6. At this time, the server can only cache the batch data corresponding to requests 2, 3, 4, 5 and 6. At this time, suppose that request 1 fails to be sent and needs to be retried. When the retried request is sent, first check whether it is a duplicate batch, and then check whether the check result is correct, After that, it will start checking its sequence number value. At this time, only one OutOfOrderSequenceException exception will be returned. After receiving this exception, the client will retry again until the maximum number of retries or timeout is exceeded. This will not only affect the performance of the Producer, but also put pressure on the server (equivalent to the client sending out error requests).
Is there a better plan? I think there is. For OutOfOrderSequenceException exception, subdivide it to distinguish whether the sequence number is greater than nextSeq (the expected next sequence number value) or less than nextSeq. If it is less than, it must be duplicate data.
When Max_ IN_ FLIGHT_ REQUESTS_ PER_ When the connection configuration is greater than 1, is order guaranteed
Let's analyze first. Under what circumstances will Producer be out of order? When there is no idempotency, the disorder occurs during retry. For example, the client still sends six requests 1, 2, 3, 4, 5 and 6 (they correspond to a batch respectively). Only 2-6 of the six requests succeed in ack and 1 fails. At this time, it needs to retry. When retrying, the data of batch 1 will be added to the data queue to be sent), Then, the data of batch 1 will be sent the next time. At this time, the data has been out of order, because the data of batch 1 is later than batch 2-6.
When Max_ IN_ FLIGHT_ REQUESTS_ PER_ When connection is set to 1, this problem can be solved because only one request is allowed to be sent at the same time. The next request can be sent only after the current request is sent (after successful ack). Similar to the single thread processing mode, each request will wait for the last completion, which is very inefficient, However, it can solve the problem of out of order (of course, order here is only for the case of single client, and concurrent writing of multiple clients cannot be achieved).
The solution that the system can provide is basically to choose between order and performance, which cannot be compatible. In fact, the probability of requesting retry in the system is very small (usually triggered by network problems), and it may not even take 0.1% of the time. However, for this reason, the application needs to sacrifice the performance problem to solve it. In the big data scenario, We hope to have a more friendly way to solve this problem. In short, when retries occur, Max in flight request can be dynamically reduced to 1. Under normal circumstances, it is still treated as 5 (5 is an example), which is a bit similar to the consideration of P in the distributed system CAP theory. When problems occur, the performance can be tolerated to deteriorate, but in other cases, we want to have the original performance, Not one size fits all. Fortunately, in Kafka version 2.0.0, if Producer starts idempotency, Kafka can do this. If idempotency is not turned on, it cannot do so, because its implementation depends on sequence number.
When the request is retried, the batch will be added to the queue again. At this time, it is added to the appropriate position of the queue according to the sequence number (if some batches do not have a sequence number, their relative position will remain unchanged), that is, the sequence number of the batch in front of the batch in the queue is smaller than the sequence number of the batch, The implementation is as follows. This method ensures that the batch will be placed in the appropriate position when retrying:
/**
* Re-enqueue the given record batch in the accumulator to retry
*/
public void reenqueue(ProducerBatch batch, long now) {
batch.reenqueued(now); //note: retry and update the corresponding meta
Deque<ProducerBatch> deque = getOrCreateDeque(batch.topicPartition);
synchronized (deque) {
if (transactionManager != null)
insertInSequenceOrder(deque, batch); //note: add batch to the appropriate location of the queue (according to seq num information)
else
deque.addFirst(batch);
}
}
In addition, when sending a request, the Sender will first obtain the data it sends through the drain() method of RecordAccumulator. When traversing the batch in the queue corresponding to topic partition, if it is found that the batch already has a sequence number, it will prove that this batch is a retry batch, because the sequence number of the batch that has not been retried has not been set, At this time, a judgment will be made, and the data of this topic partition can be sent again only after the request in flight requests is sent. The judgment is realized as follows:
//note: get the basesequence of the first batch in infightbatches. If infightbatches is null, recordbatch will be returned NO_ SEQUENCE
int firstInFlightSequence = transactionManager.firstInFlightSequence(first.topicPartition);
if (firstInFlightSequence != RecordBatch.NO_SEQUENCE && first.hasSequence()
&& first.baseSequence() != firstInFlightSequence)
//note: retry the operation (seq number is not 0), if the baseSequence of this batch is different from in flight
//Note: if the baseSequence of the first request batch in the queue is different (it proves that there are unsuccessful requests in front of it),
//note: it will wait for the next cycle before judging. In the worst case, it will cause the in flight request to be 1 (only this partition is affected)
//note: in this case, it is meaningless to continue sending this, because the order is guaranteed in idempotency. Only if the previous ones are successful, the subsequent resending is meaningful
//note: here is a break, which is equivalent to directly skipping the sending of this topic partition in this sending
// If the queued batch already has an assigned sequence, then it is being
// retried. In this case, we wait until the next immediate batch is ready
// and drain that. We only move on when the next in line batch is complete (either successfully
// or due to a fatal broker error). This effectively reduces our
// in flight request count to 1.
break;
}
The two mechanisms on the Client side are not enough. When processing the ProduceRequest request, the Server side will also check the sequence number value of batch, which requires that this value must be continuous. If it is not continuous, an exception will be returned, and the Client will retry accordingly, For example, suppose the order of requests sent by the Client is 1, 2, 3, 4 and 5 (corresponding to a batch respectively). If an exception occurs to request 2 in the middle, it will cause 3, 4 and 5 to return an exception and retry (because the sequence number is discontinuous), that is, at this time, 2, 3, 4 and 5 will retry and add it to the corresponding queue.
The inflightBatchesBySequence member variable of the transactionmanager instance of Producer will maintain the corresponding relationship between this topic partition and the batch currently being sent (add batch records through the addInFlightBatch() method). Only after this batch is ack ed successfully, This batch will be removed from the inflightBatchesBySequence through the removeInFlightBatch() method. Following the previous example, there are batches 2, 3, 4 and 5 in the inflight batchesbysequence (in order, 2 is in the front), According to the draw () method of the previous RecordAccumulator, you can only send the batch to be sent next time by this topic partition when it is batch 2 (judged by obtaining the baseSequence of the first batch in infightbatches with the firstInFlightSequence() method of the transactionmanager). Otherwise, it will break directly, Skip the data sending of this topic partition. This is equivalent to a wait. Wait for batch 2 to rejoin the queue before sending. You can't skip batch 2 and retry batch 3, 4 and 5 directly. This is not allowed.
In short, its implementation mechanism can be summarized as follows:
-
The Server side verifies the sequence number value of batch. If it is discontinuous, an exception will be returned directly;
-
When the Client side requests retry, batch will be placed in the appropriate position according to the sequence number value in the request queue (one of the order guarantees);
-
When the Sender thread sends, when traversing the batch in the queue, it will check whether this batch is a retry batch. If so, it is allowed to send only if this batch is the oldest batch that needs to be retried. Otherwise, this transmission skips the transmission of this topic partition data and waits for the next transmission.