I've learned about message queuing before, but I haven't used it. If I encounter kafka in today's project, there will be an application scenario
1. Kafka
Kafka is A distributed, partitioned and multi replica zookeeper based message queue. Using message queue means that application A sends the information to be processed to the message queue, and then continues the following tasks. Application B that needs the information obtains the information from the message queue and then processes it. This seems to be superfluous. Isn't it OK for application A to send information directly to application B? If it exists, it is reasonable to use message queue. Its functions are as follows:
- Asynchronous processing: after registering, users can send e-mail, SMS and verification code asynchronously, so that the registration process can be returned immediately after being written to the database
- Traffic peak elimination: requests with second kill activity exceeding the threshold are discarded and turned to the error page, and then business processing is carried out according to the messages in the message queue
- Log processing: the log of error can be persisted to the message queue separately
- Application decoupling: for the order placing operation of shopping, a message queue is added between the order system and the inventory system to decouple them. If the latter fails, the message will not be lost
I also wrote RabbitMQ's notes before, Portal
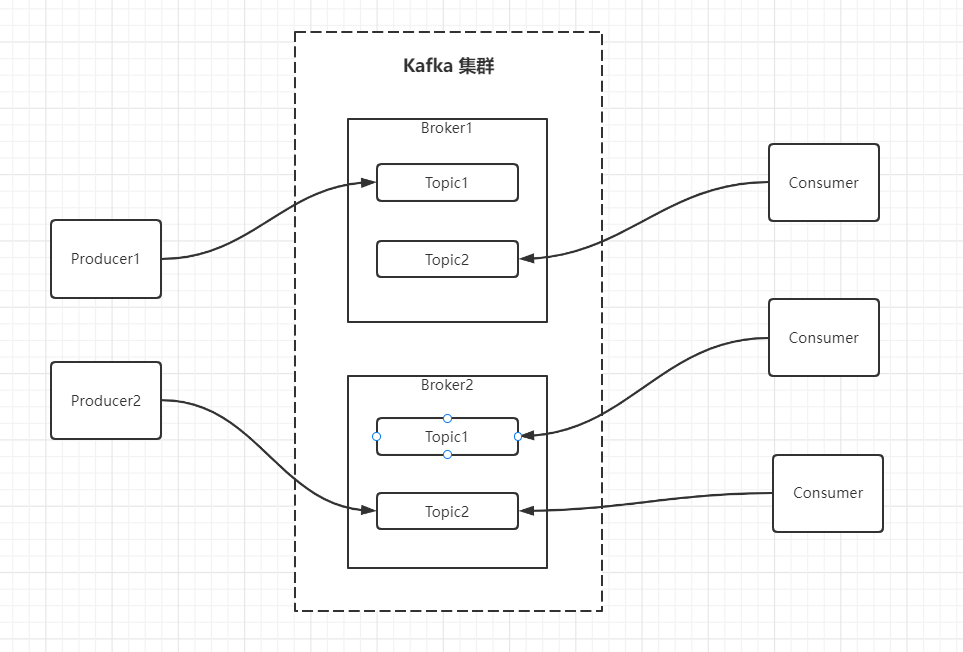
2. Production and consumption model
It will be easier to understand kafka's model by combining the following nouns
| name | explain |
|---|---|
| Broker | An instance of kafka. Deploying multiple Kafkas means that there are multiple broker s |
| Topic | The topic of message subscription is the classification of these messages, which is similar to the channel of message subscription |
| Producer | The producer is responsible for sending messages to kafka |
| Consumer | Consumers, read messages from kafka to consume |
3. Installation and deployment
kafka and the dependent zookeeper are tools written in java, which require jdk8 and above. The author uses Docker to install here. He is lazy and wants to be convenient and fast
# Images made using wurstmeister docker pull wurstmeister/zookeeper docker pull wurstmeister/kafka # Start zookeeper docker run -d --name zookeeper -p 2181:2181 wurstmeister/zookeeper # Stand alone startup kafka docker run -d --name kafka -p 9092:9092 \ -e KAFKA_BROKER_ID=0 \ -e KAFKA_ZOOKEEPER_CONNECT=xxx.xxx.xxx.xxx:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://xxx.xxx.xxx.xxx:9092 \ -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka
4. Quickstart
The kafka official website also has a good introduction, quickstart
# Enter kafka container docker exec -it kafka /bin/sh # Enter the bin directory cd /opt/kafka_2.13-2.8.1/bin # Partitions partitions # Replication replication factor # Create a topic (if you don't understand the parameters, you can fill them in directly, which will be explained later) ./kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic quickstart-events --bootstrap-server localhost:9092 # see ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092 # Write topic (enter indicates a message, and ctrl + c ends the input) # Messages are stored for 7 days by default, and the next consumption can be verified ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 This is my first event This is my second event # Read topic (messages can be read after running multiple times because they are stored for 7 days by default) ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092 ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
5. SpringBoot integration
SpringBoot integrates kafka. After adding dependencies, you can use the built-in KafkaTemplate template method to operate kafka message queue
5.1 adding dependencies
<!-- sprinboot In version management kafka Version number is not required -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
5.2 configuration files
server:
port: 8080
spring:
# Message queue
kafka:
producer:
# The broker address, the number of retries, the number of acknowledgments received, and the encoding and decoding method of the message
bootstrap-servers: 101.200.197.22:9092
retries: 3
acks: 1
key-serializer: org.springframework.kafka.support.serializer.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.StringSerializer
consumer:
# broker address, auto submit, partition offset setting
bootstrap-servers: 101.200.197.22:9092
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
5.3 producers
@RestController
@RequestMapping("/kafka")
public class Producer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/producer1")
public String sendMessage1(@RequestParam(value = "message", defaultValue = "123") String message) throws ExecutionException, InterruptedException {
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("topic1", message);
SendResult<String, Object> sendResult = future.get();
return sendResult.toString();
}
@GetMapping("/producer2")
public String sendMessage2(@RequestParam(value = "message", defaultValue = "123") String message) throws ExecutionException, InterruptedException {
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("topic1", message);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println("faile");
}
@Override
public void onSuccess(SendResult<String, Object> result) {
System.out.println("success");
}
});
return "";
}
}
5.4 consumers
@Component
public class Consumer {
@KafkaListener(topics = {"topic1"})
public void onMessage(ConsumerRecord<?, ?> record) {
System.out.println(record.value());
}
}
6. Storage directory structure
kafka
|____kafka-logs
|____topic1
| |____00000000000000000000.log(Store received messages)
| |____consumer_offsets-01(Consumer offset)
| |____consumer_offsets-02
|____topic2
|____00000000000000000000.log
|____consumer_offsets-01
|____consumer_offsets-02
After receiving the message, each broker instance stores it in 00000 Log is saved by first in first out. Messages will not be deleted after consumption. Instead, you can set the message retention time of topic. The important thing is that Kafka's performance is actually constant in terms of data size, so there is no problem storing data for a long time
Consumers will submit their consumption offset offset to topic_ consumer_offsets is saved, and then the location of the message is determined by the offset. By default, it starts from the last consumption location. Adding the parameter -- from beginning will start consumption from the beginning, and all previously stored messages can be obtained. kafka will also periodically clear internal messages until the latest one is saved (messages saved in files are saved for 7 days by default)
7. Consumer group
This problem was found when the author configured consumers. The startup times mistakenly said that there was no designated consumer group
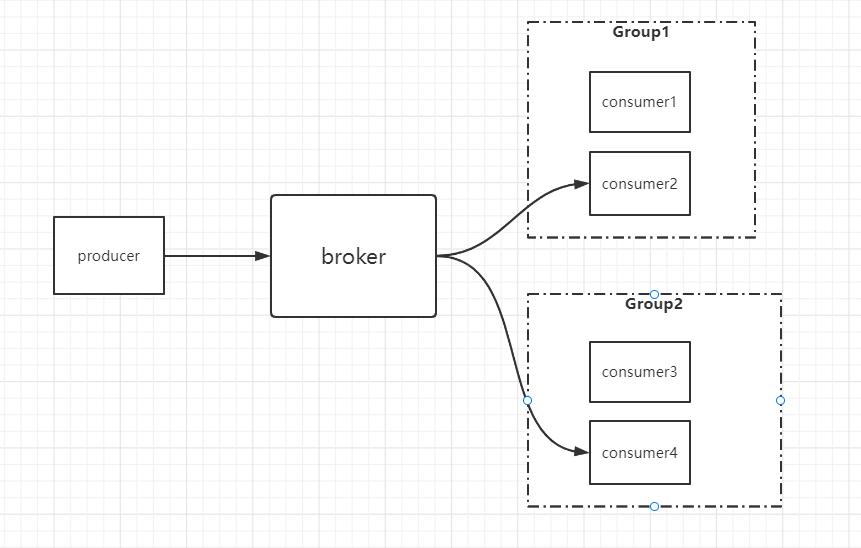
- Each partition message can only be consumed by one consumer in the same group. consumer1 and consumer2 are in the same group, so only one of them can consume the same message
- Each partition message can be consumed by a single consumer in different groups. consumer2 and consumer4 are different groups, so they can consume the same message
- The above two rules are established at the same time
- Its function is to ensure the consumption order. Messages in the same partition will be consumed by the same consumer in order
8. Partitions and replicas
topic message saved file 0000 Log can be physically partitioned. This is the concept of partition, which is similar to database and table partitioning. The advantage of this is that a single saved file will not be too large, which will affect the performance. The most important thing is that after partitioning, not a single file is executed serially, but multiple zones and multiple files can be executed in parallel, which improves the concurrency
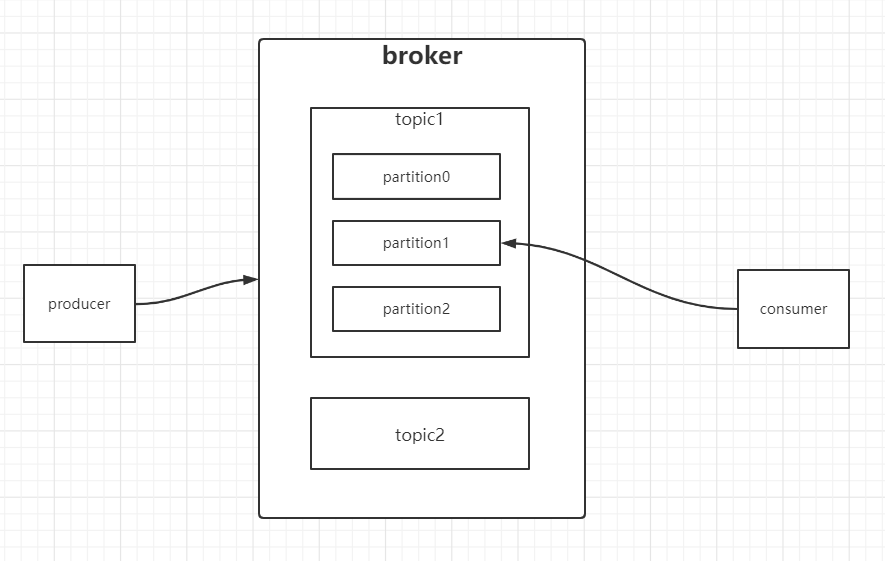
Partition: consumers will consume different partitions of the same topic, so they will save the offset of different partitions in the format of GroupId + topic + partition number
Replica: replica is a backup of partitions. Different partitions in the cluster are on different brokers, but replicas will be backed up to a specified number of brokers. These replicas are different from leader s and follower s. Leaders are responsible for reading and writing, hanging up and re electing. Replicas are used to maintain data consistency
9. Frequently asked questions
9.1 producer synchronous and asynchronous messages
The producer sends a message to the broker, and then the broker will respond to the ack to the producer. The producer waits for 3 seconds to receive the ACK signal, and retries 3 times if it times out
Producer ack confirmation configuration:
- ack = 0: no synchronization message is required
- ack = 1: the leader receives the message and saves it to the local log before responding to the ack message
- ack is configured as 2 by default
9.2 automatic submission and manual submission by consumers
- Automatic submission: the consumer submits its offset to the broker immediately after pull ing the message. This process is automatic
- Manual submission: the consumer submits the offset to the broker in the code on or after the pull message
- Difference between the two: prevent the consumer from hanging up after pull ing the message, and submit the offset before the message is consumed
9.3 message loss and repeated consumption
- Message loss
- Producer: configure ack, and the configuration copy and partition values are consistent
- Consumer: setting up manual submission
- Repeated consumption
- Set a unique primary key. If the Mysql primary key is unique, the insertion fails
- Distributed lock
9.4 sequential consumption scheme
- Producer: turn off retry, use synchronous sending, and send the next one after success
- Consumer: messages are sent to a partition, and only consumers of one consumer group can receive messages