Common terms of Kafka
Broker: Kafka's server is an instance of Kafka. The Kafka cluster consists of one or more Brokers, which are responsible for receiving and processing client requests.
Topic: Topic, a logical container for messages in Kafka. Each message published to Kafka has a corresponding logical container, which is often used to differentiate business.
Partition: Partition is a physical concept that represents an orderly and invariant sequence of messages, each Topic consisting of one or more Parties
Replica: Replica. The same message in Kafka is copied to multiple places for data redundancy. These places are replicas. The replicas are divided into Leader and Follower. Different roles play different roles. Replicas are for Partition. Each partition can configure multiple replicas to achieve high availability.
Record: Messages, objects processed by Kafka
Offset: Message displacement, the location information of each message in a partition, is a monotonically increasing and unchanged value
Producer: Producer, an application that sends new messages to a topic
Consumer: Consumer, an application that subscribes to new messages from a topic
Consumer Offset: Consumer displacement, recording consumer progress, each consumer has its own consumer displacement
Consumer Group: Consumer group, where multiple consumers form a consumer group and consume multiple partitions at the same time to achieve high availability (the number of consumers in the group should not be more than the number of partitions to avoid wasting resources)
Reblance: Rebalancing, the process of automatically redistributing subscription subject partitions for other consumer instances after the number of consumer instances in the consumer group changes
Here's a picture to show some of the concepts mentioned above. (Painting with PPT is too arduous. It's been a long time. Useful drawing tools are welcome to recommend.)
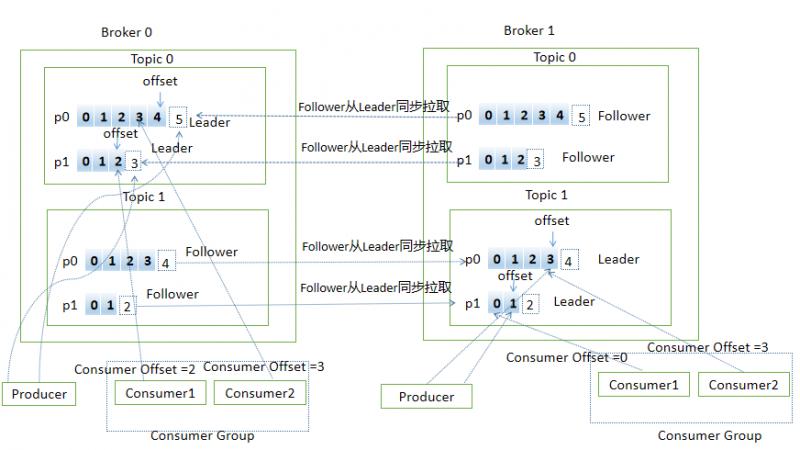
Message Production Process
Let's start with a small demo of Kafka Producer
public static void main(String[] args) throws ExecutionException, InterruptedException { if (args.length != 2) { throw new IllegalArgumentException("usage: com.ding.KafkaProducerDemo bootstrap-servers topic-name"); } Properties props = new Properties(); // kafka server ip and port, multiple split by commas props.put("bootstrap.servers", args[0]); // Confirmation signal configuration // ack=0 means that the producer side does not need to wait for the confirmation signal and has the lowest availability. // ack=1 waits for at least one leader to write the message to the log successfully, which does not guarantee that the follower will write successfully if the leader goes down and the follower does not write the data successfully. // Message loss // ack=all leader needs to wait for all follower s to backup successfully, with the highest availability props.put("ack", "all"); // retry count props.put("retries", 0); // Batch message size, batch processing can increase throughput props.put("batch.size", 16384); // Delayed time to send messages props.put("linger.ms", 1); // Memory size used to swap out data props.put("buffer.memory", 33554432); // key serialization props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value serialization props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Create the KafkaProducer object and start the Sender thread when created Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 100; i++) { // Write a message to RecordAccumulator Future<RecordMetadata> result = producer.send(new ProducerRecord<>(args[1], Integer.toString(i), Integer.toString(i))); RecordMetadata rm = result.get(); System.out.println("topic: " + rm.topic() + ", partition: " + rm.partition() + ", offset: " + rm.offset()); } producer.close(); }
instantiation
The construction method of Kafka Producer is mainly based on the configuration file for some instantiation operations.
1. Resolve clientId, if not configured, by producer-incremental numbers
2. Parsing and instantiating partitioner can realize its own partitioner. For example, according to key partitioning, it can ensure that the same key is divided into the same partition, which is very useful for ensuring the order. If no partition rule is specified, the default rule (message has key, hash the key, and then model the available partition; if there is no key, use random number to model the available partition. [When there is no key, random number is inaccurate to model the available partition, and the initial counter value is random, but it is incremental later, so it can be used. To roundrobin)
3. Analyzing and instantiating the serialization of key and value
4. Analyzing and instantiating interceptors
5. Parse and instantiate Record Accumulator, which is mainly used to store messages (Kafka Producer main thread writes messages to Record Accumulator, Sender thread reads messages from Record Accumulator and sends them to Kafka)
6. Resolving Broker Address
7. Create a Sender thread and start it
... this.sender = newSender(logContext, kafkaClient, this.metadata); this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start(); ...
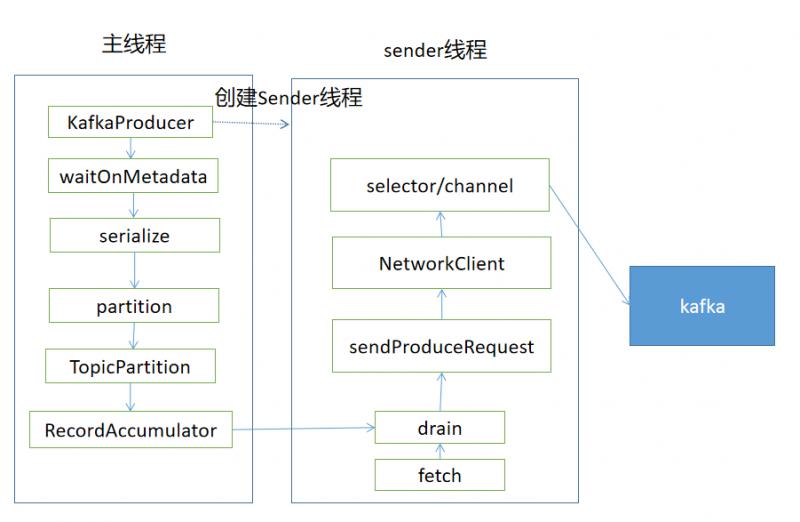
Message sending process
The sending entry of the message is the KafkaProducer.send method. The main process is as follows.
KafkaProducer.send KafkaProducer.doSend // Getting Cluster Information KafkaProducer.waitOnMetadata // key/value serialization key\value serialize // partition KafkaProducer.partion // Create TopciPartion objects, record the topic and partion information of messages TopicPartition // Write message RecordAccumulator.applend // Wake up Sender thread Sender.wakeup
RecordAccumulator
RecordAccumulator is a message queue for caching messages, grouping messages according to TopicPartition
Focus on the flow of additional messages for RecordAccumulator.applend
// Record the number of threads for applend appendsInProgress.incrementAndGet();
// Get or create a new Deque double-ended queue based on TopicPartition Deque<ProducerBatch> dq = getOrCreateDeque(tp); ... private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) { Deque<ProducerBatch> d = this.batches.get(tp); if (d != null) return d; d = new ArrayDeque<>(); Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d); if (previous == null) return d; else return previous; }
// Attempt to add messages to the buffer // Locking ensures that the same TopicPartition is written in an orderly manner synchronized (dq) { if (closed) throw new KafkaException("Producer closed while send in progress"); // Attempt to write RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq); if (appendResult != null) return appendResult; }
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, Deque<ProducerBatch> deque) { // Remove Producer Batch from the tail of the double-ended queue ProducerBatch last = deque.peekLast(); if (last != null) { // Get it, and try to add a message FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()); // Not enough space, return null if (future == null) last.closeForRecordAppends(); else return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false); } // Unfetched return null return null; }
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) { // Not enough space, return null if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) { return null; } else { // Really add messages Long checksum = this.recordsBuilder.append(timestamp, key, value, headers); ... FutureRecordMetadata future = ... // future is associated with callback thunks.add(new Thunk(callback, future)); ... return future; } }
// If you fail to try applend (return null), you will come here. If tryApplend returns directly // Request memory space from BufferPool to create a new ProducerBatch buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) { // Notice here that the previous attempt to add failed and memory has been allocated. Why try to add? // Because other threads may have created ProducerBatch or the previous ProducerBatch has been freed up by the Sender thread, try adding it once. If successful, the application space will be released later in final. RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq); if (appendResult != null) { return appendResult; } // Attempt to add failed, new Producer Batch MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic); ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds()); FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds())); dq.addLast(batch); incomplete.add(batch); // Set buffer to null to avoid releasing space in final summary buffer = null; return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true); }
finally { // Finally, if the addition is successful again, the memory previously requested will be released (for the purpose of creating a new Producer Batch) if (buffer != null) free.deallocate(buffer); appendsInProgress.decrementAndGet(); }
// Write messages to buffers RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs); if (result.batchIsFull || result.newBatchCreated) { // Buffer full or newly created Proucer Batch, evokes Sender threads this.sender.wakeup(); } return result.future;
Sender Sender Sender Message Thread
The main processes are as follows.
Sender.run Sender.runOnce Sender.sendProducerData // Getting Cluster Information Metadata.fetch // Get the partition where messages can be sent and the node of the leader partition has been obtained RecordAccumulator.ready // Get the Producer Batch information from the Deque queue corresponding to topicPartion in the buffer according to the prepared node information RecordAccumulator.drain // Transfer messages to the production request queue for each node Sender.sendProduceRequests // Create a production request queue for messages Sender.sendProducerRequest KafkaClient.newClientRequest // Here's the message KafkaClient.sent NetWorkClient.doSent Selector.send // Actually, it's not really I/O, it's just written into Kafka Channel. // poll really performs I/O KafkaClient.poll
The main flow of Sender thread through source code analysis
The construction method of KafkaProducer starts a KafkaThread thread to execute Sender at instantiation time
// Kafka Producer construction method starts Sender String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId; this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start();
// Sender->run()->runOnce() long currentTimeMs = time.milliseconds(); // Send production messages long pollTimeout = sendProducerData(currentTimeMs); // Really perform I/O operations client.poll(pollTimeout, currentTimeMs);
// Getting Cluster Information Cluster cluster = metadata.fetch();
// Get the nodes that are ready to send messages and have been fetched to the leader partition RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now); // ReadyCheckResult contains the set of nodes that can send messages and get to the leader partition, and the top set that does not get to the leader partition node. public final Set<Node> Node; public final long nextReadyCheckDelayMs; public final Set<String> unknownLeaderTopics;
The read method mainly traverses the container of adding messages to Record Accumulator, Map < Topic Partition, Deque < Producer Batch> from the cluster information to get the node where the leader partition is located according to Topic Partition, and can not find the corresponding leader node, but the topic of the message to be sent is added to unknownLeader Topics. At the same time, the nodes that can get the leader partition according to TopicPartition and satisfy the condition of sending messages are added to the nodes.
// Traversing batches for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) { TopicPartition part = entry.getKey(); Deque<ProducerBatch> deque = entry.getValue(); // Get the node of leader partition from cluster information according to TopicPartition Node leader = cluster.leaderFor(part); synchronized (deque) { if (leader == null && !deque.isEmpty()) { // Add a topic that does not find the node where the corresponding leader partition is located but has messages to send unknownLeaderTopics.add(part.topic()); } else if (!readyNodes.contains(leader) && !isMuted(part, nowMs)) { .... if (sendable && !backingOff) { // Add ready nodes readyNodes.add(leader); } else { ... }
Then traverse the returned unknownLeaderTopics, add topic to the metadata information, and call the metadata.requestUpdate method to request the update of metadata information.
for (String topic : result.unknownLeaderTopics) this.metadata.add(topic); result.unknownLeaderTopics); this.metadata.requestUpdate();
Final checking of ready nodes, removing those nodes that are not ready to connect, is mainly based on KafkaClient. read method.
Iterator<Node> iter = result.readyNodes.iterator(); long notReadyTimeout = Long.MAX_VALUE; while (iter.hasNext()) { Node node = iter.next(); // Call the KafkaClient. read method to verify that the node connection is ready if (!this.client.ready(node, now)) { // Remove Unready Nodes iter.remove(); notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now)); } }
Let's start creating a request for a production message
// Remove the Deque double-ended queue corresponding to TopicPartition from RecordAccumulator, and then remove the Producer Batch from the head of the double-ended queue as the message to be sent. Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
Encapsulate messages as ClientRequest
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);
Calling KafkaClient to send a message (not really performing I/O) involves Kafka Channel. Kafka's communication adopts NIO mode
// NetworkClient.doSent Method String destination = clientRequest.destination(); RequestHeader header = clientRequest.makeHeader(request.version()); ... Send send = request.toSend(destination, header); InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now); this.inFlightRequests.add(inFlightRequest); selector.send(send); ... // Selector.send method String connectionId = send.destination(); KafkaChannel channel = openOrClosingChannelOrFail(connectionId); if (closingChannels.containsKey(connectionId)) { this.failedSends.add(connectionId); } else { try { channel.setSend(send); ...
At this point, the job of sending messages is almost ready. Call the KafkaClient.poll method to really perform I/O operations.
client.poll(pollTimeout, currentTimeMs);
Summarize the Sender thread process with a diagram
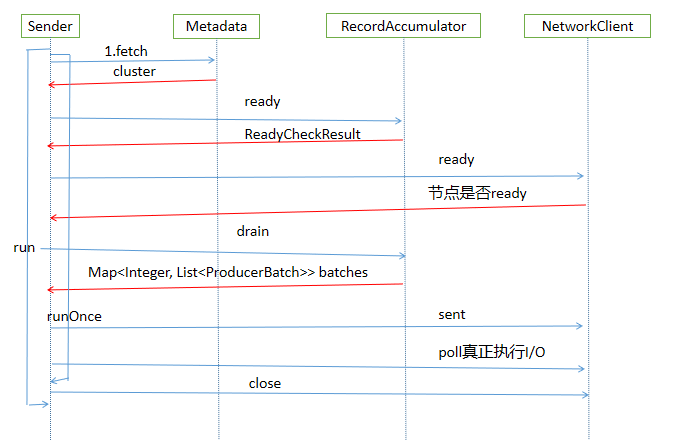
Through the above introduction, we have sorted out the main process of Kafka production message, which involves the main thread writing messages to RecordAccumulator, while the background Sender thread gets messages from RecordAccumulator, sends messages to Kafka by NIO, and summarizes them with a graph.
Epilogue
This is the first time that this public number has tried to write a source-related article. To tell the truth, I really don't know how to write it. The feeling of code screenshot and pasting the whole code has been denied by me. Finally, this way is adopted to introduce the main process, omit the irrelevant code and cooperate with the flow chart.
Last week, I attended the Huawei Cloud Kafka Practical Course. I simply looked at the production and consumption codes of kafka. I wanted to sort them out. Then I started reading the source code and sorting out the process at 8.17 on Sunday noon. I wrote it till 12:00 p.m. There was still a little unfinished. I finished this article early Monday morning. Of course, this article ignores a lot of more details, and will continue to go deeper, dare to try, keep improving, refueling!
Reference material
Huawei Cloud Actual Warfare
Geek Time kafka Column