Kafka Study Notes
install
ellipsis
The installation under linux is simply NIMA outrageous
zooker. Change it
Just open kafka's port
Methodology of Kafka operation
First, understand what message queuing is.
There must be sender and receiver for the transmission of information
If the sender and receiver receive messages synchronously, it will bring a lot of inconvenience. For example, the sender and receiver may not be free at the same time. If there is an intermediate person who saves in this person, and the person who goes out also goes out, it will be much more convenient. Message oriented middleware came into being.
Message queuing has many patterns
Point to point mode
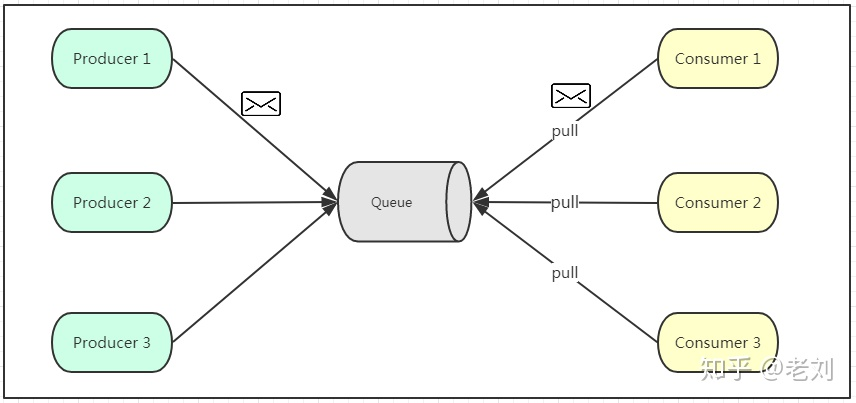
Point to point features:
- Messages generated by a producer are consumed by only one consumer
- The consumer cannot sense whether there is a message in the Queue (so additional threads need to be added)
Publish subscribe mode
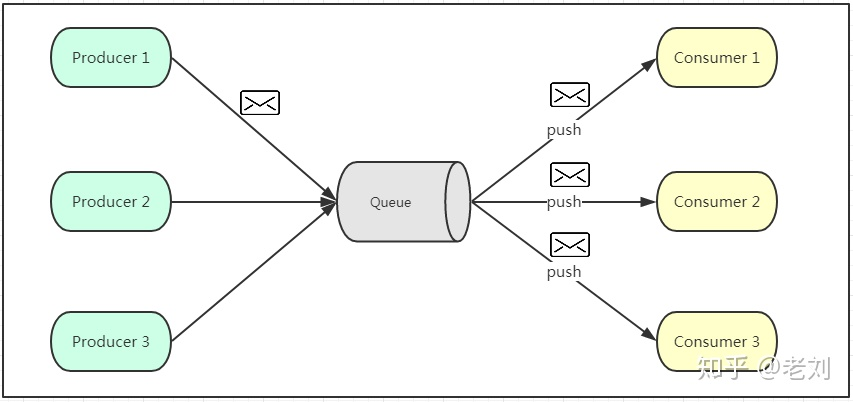
3. The subscriber of a producer can accept the message of the producer
4. However, the speed of message delivery is uncertain, because different machines have different speed and ability to process messages
Kafka model architecture
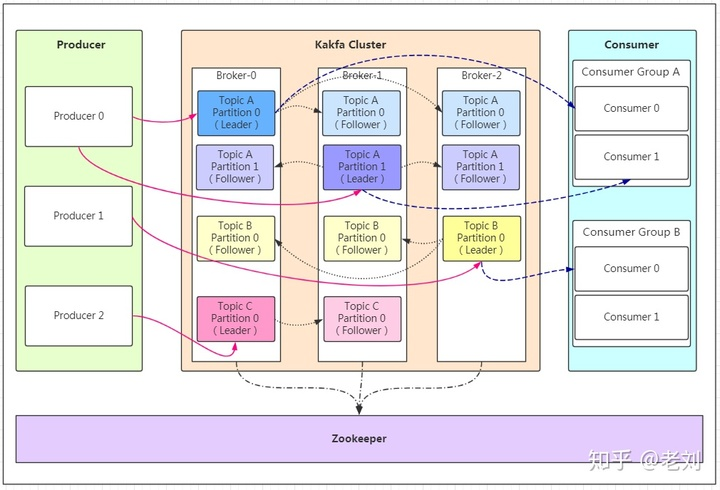
- Producer: the producer of the message
- kafka cluster
- Broker: a broker is an instance of Kafka. There are one or more Kafka instances on each server. Let's think that one broker corresponds to one server. Every broker in a Kafka cluster has a unique number.
- Topic: Message topic, which can be understood as message classification. Kafka's data is saved in topic, and each broker can create multiple topics
- Partition: the partition of a topic. Each topic can have multiple partitions. The partition is used to load and improve Kafka's throughput. Different partition data in the same topic are different. It can be understood as a time database table.
- Replication: each partition has one or more replicas. The role of the replica is to have the machine on top when the primary partition fails. Based on this analysis, the relationship between folder and leader is obvious.
The correspondence is
kafka cluster contains multiple brokers, brokers contain multiple topics, and topics contain multiple partitions Among them, each partition has multiple replications and is stored in different machines to achieve high availability. The number of replicas must not be greater than the number of brokers, that is, there cannot be two replications with the same content in a broker - Message: every message sent
- Consumer: the consumer is the sender of the message. It is used to consume information and is the outlet of the message.
- Consumer Group: multiple consumers can form a Consumer Group. Consumers in the same Consumer Group can consume information from different partitions of the same topic.
Kafka workflow
Producer sends message to Kafka Cluster
- The producer obtains the information of the leader in the cluster
- The producer sends information to the Leader
- The leader writes information locally
- The leader sends information to the follower
- After the follower is written, send an ack to the leader
- The leader receives ack s from all follower s and sends messages to the producer
The purpose of using partitions is to facilitate expansion and improve concurrency. Different partitions store different contents. How does the server distribute different requests to different partitions?
7. Manually make partition
8. If the data has a key, use hash to get a partition
9. Poll a partition.
You know, in the message queue, it is very important to ensure that data is not lost. It is guaranteed by a parameter called ack.
0 means that the producer does not need to wait for the cluster to return when sending data to the cluster.
1 means the leader level stop and wait protocol, which ensures that the leader can send the next message after receiving the response message.
All means that all leader follower s can send the next data only after receiving the message.
How does Kafka save data
For example, Kafka requires high concurrency components. It will separately open up a continuous disk space and write data sequentially.
Partition structure
A Partition contains multiple segements
A Segment contains
- xx.index index file
- xx. Load information storage file
- xx.timeindex index file
Storage strategy
Kafka saves all information whether it is consumed or not. - 7-day deletion based on time
Consumption data
After the message is stored in the log file, the consumer can consume it. First of all, Kafka adopts a peer-to-peer model (? I remember not publishing and subscribing, this will be considered). Second, consumers also take the initiative to find leader s in Kafka cluster to pull information. Each consumer has a group id, and the same consumer group can consume data from different partitions under the same topic. To put it simply, if a and B belong to the same consumer group, you can't read all the assignments under the Topic test, but only one.
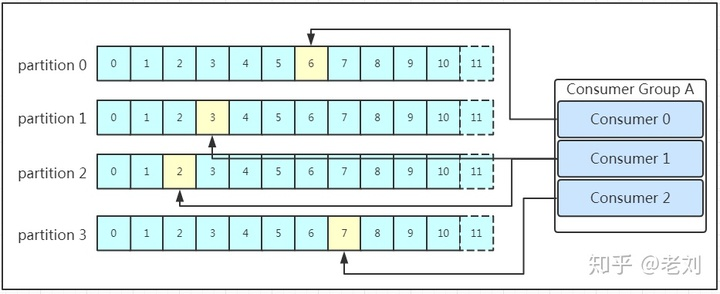
Therefore, a certain consumer will consume multiple partitions. Generally, the number of consumers in the consumer group corresponds to the number of partitions one by one. Otherwise, a consumer may not be more efficient in dealing with two partitions. Multiple consumers cannot consume the same partition for two consumers anyway
Kafka practice
- Briefly introduce server properties
- broker.id is the unique representation of each broker in the cluster. It is required to be a positive number. When broker If the ID does not change, the message status of consumers will not be affected.
- log.dirs kafka data storage address
- Service port of port broker server
- message.max.byte, the maximum size of the message body, in bytes
- num.network.threads, the maximum number of threads that the broker can process messages, generally the number of cpu cores
- num.io.threads brokers the number of threads that process disk IO
- Hostname the host address of the broker. If set, it will be bound to this low IQ. If not, it will be bound to all interfaces and send one of them to
- zookeeper. The address of the connect zookeeper cluster can be multiple
- zookeeper.session.timeout.ms zookeeper maximum timeout
- zookeeper.connection.timeouout.ms
- listener: listening port
Kafka's functions for many nodes are completed through zookeeper
- Practical command
- Server startup
zkServer.sh start
create themes
[root@k8s-master1 kafka_2.13-3.0.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic heima --partitions 2 --replication-factor 1
kafka-topics.sh in this category
Replace -- zookeeper localhost:2081 with – bootstrap server localhost: 9092
– creae is a defined action
– topic is followed by some information
name
Partition: sets the number of partitions
Replication factor, which defines the number of replicas
- Start the server
bin/kafka-server-start.sh config/server.properties
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ice
Start the client and bind the theme
This is the producer, production information
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ice
Take a simple Java example to explain kafka
First, configure in Maven
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
Take a consumer example
public class ProducerFastStart {
private static final String brokerList = "192.168.236.137:9092";
private static final String topic = "ice";
public static void main(String[] args) {
Properties properties = new Properties();
// properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.RETRIES_CONFIG,10);
//Set value serializer
// properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//Set cluster address
// properties.put("bootstrap.servers",brokerList);
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
//record encapsulates the object
ProducerRecord<String,String> record = new ProducerRecord<>(topic,"kafka-demo","123");
try {
Future<RecordMetadata> send = producer.send(record);
RecordMetadata recordMetadata = send.get();
System.out.println("topic = "+recordMetadata.topic());
System.out.println("partition = "+recordMetadata.partition());
System.out.println("offset = " + recordMetadata.offset());
}catch (Exception e){
e.printStackTrace();
}
producer.close();
}
}
First, specify the ip and port of the broker list. You should tell the producer where to put messages. Specify a topic to tell which topic to send information.
In Java, the whole Message exists in the form of Message, which is configured with properties as the configuration tool.
properties.put(ProducerConfig.RETRIES_CONFIG,10);
Configure how many retransmissions will be made if the transmission fails
When using java to transfer information in kafka, you should generally keep up with key and value.
Moreover, both key and value need to be serialized.
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
Here, some information in properties is bound to implement a configuration of Kafka
ProducerRecord<String,String> record = new ProducerRecord<>(topic,"kafka-demo","123");
The information is set here and generated in the form of key value pairs.
java implementation of consumer
private static final String brokerList = "192.168.236.135:9092";
private static final String topic = "ice";
private static final String groupId = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
// properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
properties.put("bootstrap.servers",brokerList);
properties.put("group.id",groupId);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton(topic));
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(5000));
for (ConsumerRecord<String,String> record:records){
System.out.println(record.value());
}
}
}
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Here, the previous producer needs to be serialized, so we need to deserialize the extracted information in order to obtain the information.
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
Here, value also needs to be deserialized
properties.put("bootstrap.servers",brokerList);
properties.put("group.id",groupId);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
The difference is that you need to set the group of consumers.
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton(topic));
Then you need to ask the consumer to subscribe to the topic topic topic
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(5000));
for (ConsumerRecord<String,String> record:records){
System.out.println(record.value());
}
}
Set the listening time and analyze the information obtained by listening.
Briefly analyze the writing process of producer
- Client writer. Connect to the broker through the KafkaProducer class, and specify the address of the broker through properties, as well as the serialization type, topic, partition and other information of kv.
- Encapsulate the message to be sent through producer record.
- KafkaProducer loads the ProducerRecord and sends it through the send() function. At this time, a serializer will enter a partition.
- Serializer, serialized information, partition, to determine which partition this information is placed in the partition.
Note that both the partitioner and serializer can be rewritten by ourselves. 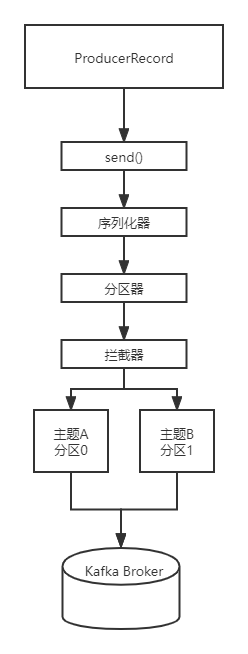
Finally, there is an interceptor. The function of the interceptor is the same as that of AOP, which is equivalent to an enhanced function.
Briefly analyze the reading process of consumer
First, let's explain the concept of displacement. First, he and the displacement in the partition are not for a while, although their English is Offset. Consumption displacement refers to the displacement of the next message to be consumed by the Consumer. It is the displacement of the next message, not the displacement of the latest consumption message.
For example, there are 10 pieces of information in a partition, and the displacements are 0-9 If a Consumer application has consumed 5 pieces of information, it means that the Consumer has consumed 5 messages with a displacement of 0-4. At this time, the displacement of the Consumer is 5, pointing to the displacement of the next message.
In addition, the Consumer needs to report its displacement data to Kafka. This reporting process is called submitting offsets. Because the Consumer can consume the data of Acura partition, the submission of displacement is based on the granularity of partition. The Consumer needs to allocate each partition to it and submit the displacement.
This displacement exists to ensure that you will not consume the data you have consumed before. Moreover, Kafka has strong tolerance for displacement submission, which can be divided into automatic submission and manual submission. Automatic submission means that Kafka silently submits displacement for you. As a user, you don't have to worry about these things at all. Manual submission means that you submit displacement yourself, and Kafka Consumer doesn't care.
The automatically submitted Kafka automatically submits the displacement once in about 5s.
However, automatic submission will lead to a problem of repeated consumption. The core problem is
Turn on auto submit
props.put("enable.auto.commit","true");
props.put(""auto.commit.interval.ms,"2000")
Generally speaking, it is still very simple
Automatic submission, Kafka will ensure that all messages returned by the last poll will be submitted when calling the poll method. In order, the logic of the poll method is to submit the displacement of the previous batch of messages before processing the next batch of messages. But if rebalancing happens, it will become different. How will it be different? We'll talk about it later.
Manual submission is flexible, but when commitSync() is called, the Consumer will be in a blocking state. This state will not end until the remote Broker returns the submission result. It is the system blocking caused by non resource reasons that reduces the efficiency.
Here comes asynchronous commit.
But in my project, synchronous submission is used to accept the transmitted data, cut and preprocess it, and then use it.
Asynchronous processing will lead to information loss, because it is meaningless to retry at this time. When you retry, the valid information bit does not know where to go.
The best way is actually two superposition