kafka installation record:
Official website: http://kafka.apache.org/downloads.html
1. Download
yum install -y wget
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
2. Decompression:
tar -zxvf kafka_2.12-2.6.0.tgz -C /opt/
3. Change of name
mv kafka_2.12-2.6.0 kafka
4. Create files
cd kafka
Create under kafka Directory:
mkdir logs mkdir data
5. Modify the configuration file:
cd config/ vi server.properties


#The globally unique number of the broker, which cannot be repeated
broker.id=0
#Delete topic function enable
delete.topic.enable=true
#Number of threads processing network requests
num.network.threads=3
#Off the shelf quantity used to process disk IO
num.io.threads=8
#Buffer size of send socket
socket.send.buffer.bytes=102400
#Buffer size of receive socket
socket.receive.buffer.bytes=102400
#Buffer size of the requested socket
socket.request.max.bytes=104857600
#kafka running log storage path
log.dirs=/opt/kafka/data
#Number of partitions of topic on the current broker
num.partitions=1
#Number of threads used to recover and clean up data under data
num.recovery.threads.per.data.dir=1
#The maximum time the segment file is retained. If the timeout expires, it will be deleted
log.retention.hours=168
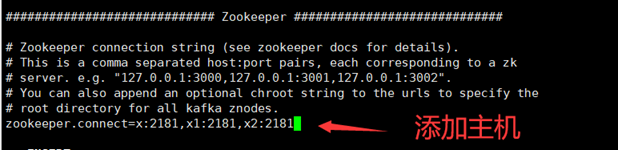
#Configure Zookeeper cluster address
zookeeper.connect=x:2181,x1:2181,x2:2181
Modify the configuration file on the other two hosts respectively
/opt/kafka/config/server. Broker in properties id=1,broker.id=2
Note: broker ID cannot be repeated
6. Configure environment variables
vi ~/.bash_profile
add to:
#KAFKA_HOME
export KAFKA_HOME=/opt/kafka
export PATH= P A T H : PATH: PATH:KAFKA_HOME/bin
Profile validation:
source ~/.bash_profile
7. Start the cluster,
(you must start zookeeper first) (write a startup script later)
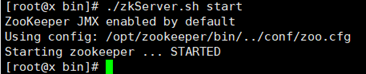
cd /opt/zookeeper/bin/
./zkServer.sh start
7.1 start kafka on the master, server1 and server2 nodes in turn
cd /opt/kafka/bin/
./kafka-server-start.sh /opt/kafka/config/server.properties
(after startup, it is a blocking process, and the operation needs to reopen a window, but it is convenient to view the output log)

./kafka-server-start.sh -daemon /opt/kafka/config/server.properties
(background startup, recommended.)

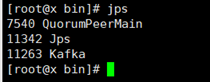
Check whether Kafka starts successfully jps
8. Create cluster script
echo $PATH

In order to find the script we created; It can be created in any of the above bin directories; Take / usr/bin as an example
cd /usr/bin vi kk.sh
8.1 change kafka stop script
kafka server stop. In the config directory of kafka SH has some problems. You need to modify the stop script provided by the official first. Every machine in the cluster should be changed (note that k in kafka is lowercase)
PIDS=$(ps ax | grep -i 'kafka\.Kafka' | grep java | grep -v grep | awk '{print $1}')
Change to
PIDS=$(ps ax | grep -i 'kafka' | grep java | grep -v grep | awk '{print $1}')
Cluster startup script:
#!/bin/bash
case $i in
"start"){
for i in x x1 x2
do
echo --------$i start-up kafka---------
ssh $i " source /etc/profile;/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties"
done
};;
"stop"){
for i in x x1 x2
do
echo --------$i stop it kafka---------
ssh $i " source /etc/profile;/opt/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
8.2 authorization:
chmod 777 kk.sh
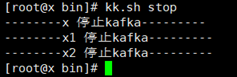
8.3 script usage:
Stop: KK sh stop
Operation: KK sh start
Solve the problem that script files created by Windows cannot be uploaded to Linux:
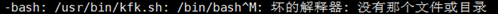
sed -i 's/\r$//' kk.sh
9. Create theme:

[root@x kafka]#
bin/kafka-topics.sh --create --zookeeper x:2181 --topic first --partitions 2 --replication-factor 2 --create

Resolution:
bin/kafka-topics.sh added theme create to create zookeeper x:2181
Storage data topic first topic name partitions number of partitions replication factor 2 copies
9.1 viewing topic:
[root@x kafka]# bin/kafka-topics.sh --list --zookeeper x:2181

Help us classify data
9.2 delete subject:
bin/kafka-topics.sh --delete --zookeeper x:2181 --topic first
Server is required Set delete in properties topic. Enable = true, otherwise it is only marked for deletion.
9.3 modify the number of partitions
bin/kafka-topics.sh --zookeeper x:2181 --alter --topic first --partitions 3
The number of general partitions shall not exceed the number of hosts
9.4 details:
bin/kafka-topics.sh --describe --topic first --zookeeper x:2181

10. Production:
bin/kafka-console-producer.sh --topic first --broker-list x:9092

10.1 turn on another machine:
[root@x1 kafka]# bin/kafka-console-consumer.sh --bootstrap-server x:9092,x1:9092,x2:9092 --topic first
x producers send messages, x1 consumers receive messages,
x2 consumers can't spend more than 7 days after receiving messages from the beginning
bin/kafka-console-consumer.sh --bootstrap-server x:9092,x1:9092,x2:9092 --topic first --from-beginning

In case of the following warnings, a node is disconnected. Check the status of three nodes. If it is disconnected, it can be solved after the node is restarted

11 some error aggregation records
zookeeper, kafka error
1.ERROR Exiting Kafka due to fatal exception (kafka.Kafka$)
Cause: not found properties File or configuration file path specified incorrectly Method: specify the configuration file path
2.Configured broker.id 130 doesn't match stored broker.id 0 in meta.properties
Reason: single machine used Method: delete the data file and restart
3.zookeeper is not a recognized option
Reason: old version used--zookeeper This option has been removed from the new version Method: 0.9 Later versions start with --bootstrap-server
4.Replication factor: 2 larger than available brokers: 1
Reason: the number of copies exceeded broker Number of servers Method: less than broker Just count
5. Error reporting:
WARN Error while fetching metadata with correlation id 479 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
WARN Error while fetching metadata with correlation id 480 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
Method: modify server.properties add to host.name=