I CGAN and ACGAN
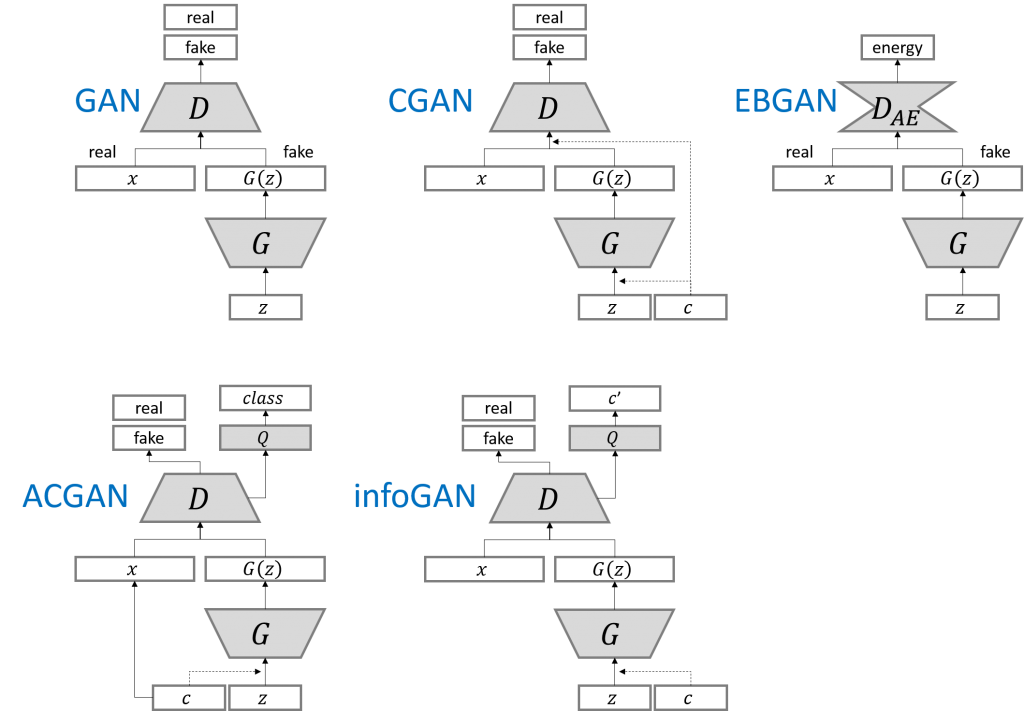
1. CGAN
- The input of ordinary GAN is an N-dimensional normal distribution along with machine number \color{red} random number Random number, and CGAN will along with machine number add upper mark sign \color{red} label random numbers Labeling random numbers;
- CGAN uses the Embedding layer to convert positive integers (index values) to solid set ruler inch of Thick dense towards amount \color{red} dense vector of fixed size A dense vector of fixed size, and the dense vector is connected with the N-dimensional normally distributed random number mutually ride \Multiply color{red} Multiply to get a have mark sign of along with machine number \color{red} labeled random number Labeled random number.
2. ACGAN
- ACGAN will deep degree volume product network Collaterals \color{red} depth convolution network Depth convolution network Save stay mark sign of G A N \color{red} GAN with label In GAN with tags, higher quality pictures can be generated.
- ACGAN equivalent D C G A N ( deep degree volume product living become yes resist network Collaterals ) and C G A N ( strip piece living become yes resist network Collaterals ) of junction close \Color {red} combination of dcgan (deep convolution generation countermeasure network) and cgan (conditional generation countermeasure network) The combination of DCGAN (deep convolution generation countermeasure network) and cgan (conditional generation countermeasure network) will deep degree volume product network Collaterals and mark sign belt enter reach G A N \color{red} depth convolution network and label are brought into GAN Deep convolution networks and labels are brought into GAN.
II Construction of ACGAN neural network
2.1 generator
-
transport
enter
\color{red} input
The input is a random number with a label.
The specific operation methods are:
- Generate an N-dimensional normally distributed random number, and then use the Embedding layer to convert the positive integer (index value) into an N-dimensional dense vector;
- Multiply this dense vector by an N-dimensional normally distributed random number.
- model type junction structure \color{red} model structure Model structure: reshape the input number, and then generate an image of corresponding size by using a series of up sampling and convolution
- transport enter \color{red} input After reshape the input number, the image is generated by up sampling and convolution.
-
Enter data code:
noise = Input(shape=(self.latent_dim,)) # (none,100) label = Input(shape=(1,), dtype='int32') # (none,1) # Converts a positive integer (index value) to a dense vector of fixed size. label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label)) model_input = multiply([noise, label_embedding]) # Desired number * randomly generated noise img = model(model_input)
-
Generator code
def build_generator(self): model = Sequential(name='generator') # All connected to 64 * 7 * 7 tensor, why is the input late_ dim? model.add(Dense(32 * 7 * 7, activation="relu", input_dim=self.latent_dim)) # reshape into feature layer style model.add(Reshape((7, 7, 32))) # The output is 7 * 7 * 64 model.add(Conv2D(filters=64, kernel_size=3, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) # Up sampling # 7*7*64->14*14*128 model.add(UpSampling2D()) model.add(Conv2D(filters=128, kernel_size=3, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) # 14*14*64->28*28*64 model.add(UpSampling2D()) model.add(Conv2D(filters=64, kernel_size=3, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) # 28*28*64->28*28*1 model.add(Conv2D(self.channels, kernel_size=3, padding="same")) model.add(Activation("tanh")) model.summary() noise = Input(shape=(self.latent_dim,)) # (none,100) label = Input(shape=(1,), dtype='int32') # (none,1) # Converts a positive integer (index value) to a dense vector of fixed size. label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label)) model_input = multiply([noise, label_embedding]) # Desired number * randomly generated noise img = model(model_input) return Model([noise, label], img)
2.2 discrimination model
The discriminant network of ACGAN is composed of convolution. Compared with the discriminant model of ordinary GAN, its purpose is no only want sentence break Out really false , still want sentence break Out species class \color{red} not only to judge the authenticity, but also to judge the type Not only to judge the authenticity, but also to judge the type (the purpose of the ordinary GAN discrimination model is to judge the authenticity according to the input picture).
- model type transport enter \color{red} model input Model input: a picture, which can be real or false
- model type junction structure \color{red} model structure Model structure: reshape the input number, and then use a series of downsampling and convolution to obtain the characteristic graph
-
model
type
of
transport
Out
\Output of color{red} model
Model output: the result of judging the authenticity and type.
transport
Out
have
two
individual
\color{red} output has two
There are two outputs:
- One is a number between 0 and 1. 1 means to judge whether the picture is true and 0 means to judge whether the picture is false;
- The other is a vector, which is used to judge what kind of picture this picture belongs to.
- Discriminant model code
def build_discriminator(self): model = Sequential(name='discriminator') # 28*28*1->14*14*16 model.add(Conv2D(filters=16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same")) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) # 14*14*16->8*8*32 model.add(Conv2D(filters=32, kernel_size=3, strides=2, padding="same")) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(BatchNormalization(momentum=0.8)) # 8*8*32->4*4*64 model.add(ZeroPadding2D(padding=((0, 1), (0, 1)))) # ? model.add(Conv2D(filters=64, kernel_size=3, strides=2, padding="same")) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(BatchNormalization(momentum=0.8)) # 4*4*64->4*4*128 model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same")) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(GlobalAveragePooling2D()) # import picture img = Input(shape=self.img_shape) # (none,28,28,1)) features = model(img) # (none,128) validity = Dense(1, activation="sigmoid")(features) # (none,1) label = Dense(self.num_classes, activation="softmax")(features) # (none,10) return Model(img, [validity, label])
2.3 model training
It is roughly the same as the traditional GAN training idea, but the output of classification is added on this basis.
The training idea of ACGAN is divided into the following steps:
- Randomly select batch_size a real picture and its label.
- Randomly generated batch_size N-dimensional vectors and their corresponding label labels are combined using the Embedding layer and passed into the Generator to generate batch_ This is a fake picture.
- The loss function of Discriminator consists of two parts: one is the comparison between the judgment result of authenticity and the real situation, and the other is the comparison between the judgment result of the label to which the picture belongs and the real situation.
- The loss function of the Generator is also composed of two parts: one is whether the generated picture is judged as 1 by the Discriminator, and the other is whether the generated picture is divided into correct classes.
def train(self, epochs, batch_size=128, sample_interval=50):
# Load data
(X_train, y_train), (_, _) = mnist.load_data()
# Data preprocessing and normalization
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
Y_train = y_train.reshape(-1, 1)
valid = np.ones((batch_size, 1)) # (256,1)
fake = np.zeros((batch_size, 1)) # (256,1)
for epoch in range(epochs):
# Random selection of real pictures
idx = np.random.randint(0, X_train.shape[0], batch_size)
img, labels = X_train[idx], Y_train[idx]
# Generate model to generate imitation image
noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # [256,100]
sampled_label = np.random.randint(0, 10, (batch_size, 1)) # [256,1] label
gen_imgs = self.generator.predict([noise, sampled_label]) # [256,28,28,1] generated picture
d_loss_real = self.discriminator.train_on_batch(img, [valid, labels]) # list 5,5 float numbers, 1 loss, 4 metrics
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, sampled_label]) # list 5,5 float numbers
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Training generation model
g_loss = self.combined.train_on_batch([noise, sampled_label], [valid, sampled_label])
# list 3,3 float numbers, 1 loss, 2 metrics
print("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (
epoch, d_loss[0], 100 * d_loss[3], 100 * d_loss[4], g_loss[0]))
2.4 model call
Load the weight of the generation model. Given the random number and specific label, the generation model can be called to generate (32,32,3) pictures to achieve the purpose of data amplification.
if __name__ == '__main__':
acgan = ACGAN()
weight_path = "./weights/gen_epoch20000.h5"
acgan.test(Label =np.array([[3]]),weight_path = weight_path)
3, Complete code
from __future__ import print_function, division
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, multiply, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D, GlobalAveragePooling2D,MaxPooling2D
from tensorflow.keras.layers import LeakyReLU, UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import os
import numpy as np
class ACGAN():
def __init__(self):
# Enter the size of the picture
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# Since there are ten numbers, they are divided into ten categories
self.num_classes = 10
# What does this mean?
self.latent_dim = 100
# adam optimizer
# optimizer = Adam(learning_rate=0.0002, beta_1=0.5)
optimizer = Adam(0.0002, 0.5)
# Discriminant model
losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=losses,
optimizer=optimizer,
metrics=['accuracy'])
# Generation model
self.generator = self.build_generator()
# Combine is a combination of generative model and discriminant model
# When training the generation model, the trainable of the discrimination model is False
# Model for training generation
# Generate a noise picture
noise = Input(shape=(self.latent_dim,)) # [none,100]
label = Input(shape=(1,)) # [none, 1]
img = self.generator([noise, label]) # [28, 28, 1]
self.discriminator.trainable = False
valid, target_labels = self.discriminator(img) # valid[none,1];target_labels[none,10]
self.combined = Model([noise, label], [valid, target_labels]) # ?
self.combined.compile(loss=losses,
optimizer=optimizer) # ?
def build_generator(self):
model = Sequential(name='generator')
# All connected to 64 * 7 * 7 tensor, why is the input late_ dim?
model.add(Dense(32 * 7 * 7, activation="relu", input_dim=self.latent_dim))
# reshape into feature layer style
model.add(Reshape((7, 7, 32)))
# The output is 7 * 7 * 64
model.add(Conv2D(filters=64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# Up sampling
# 7*7*64->14*14*128
model.add(UpSampling2D())
model.add(Conv2D(filters=128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 14*14*64->28*28*64
model.add(UpSampling2D())
model.add(Conv2D(filters=64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 28*28*64->28*28*1
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,)) # (none,100)
label = Input(shape=(1,), dtype='int32') # (none,1)
# Converts a positive integer (index value) to a dense vector of fixed size.
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding]) # Desired number * randomly generated noise
img = model(model_input)
return Model([noise, label], img)
def build_discriminator(self):
model = Sequential(name='discriminator')
# 28*28*1->14*14*16
model.add(Conv2D(filters=16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 14*14*16->8*8*32
model.add(Conv2D(filters=32, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 8*8*32->4*4*64
model.add(ZeroPadding2D(padding=((0, 1), (0, 1)))) # ?
model.add(Conv2D(filters=64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 4*4*64->4*4*128
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
# import picture
img = Input(shape=self.img_shape) # (none,28,28,1))
features = model(img) # (none,128)
validity = Dense(1, activation="sigmoid")(features) # (none,1)
label = Dense(self.num_classes, activation="softmax")(features) # (none,10)
return Model(img, [validity, label])
def train(self, epochs, batch_size=128, sample_interval=50):
# Load data
(X_train, y_train), (_, _) = mnist.load_data()
# Data preprocessing and normalization
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
Y_train = y_train.reshape(-1, 1)
valid = np.ones((batch_size, 1)) # (256,1)
fake = np.zeros((batch_size, 1)) # (256,1)
for epoch in range(epochs):
# Random selection of real pictures
idx = np.random.randint(0, X_train.shape[0], batch_size)
img, labels = X_train[idx], Y_train[idx]
# Generate model to generate imitation image
noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # [256,100]
sampled_label = np.random.randint(0, 10, (batch_size, 1)) # [256,1] label
gen_imgs = self.generator.predict([noise, sampled_label]) # [256,28,28,1] generated picture
d_loss_real = self.discriminator.train_on_batch(img, [valid, labels]) # list 5,5 float numbers, 1 loss, 4 metrics
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, sampled_label]) # list 5,5 float numbers
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Training generation model
g_loss = self.combined.train_on_batch([noise, sampled_label], [valid, sampled_label])
# list 3,3 float numbers, 1 loss, 2 metrics
print("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (
epoch, d_loss[0], 100 * d_loss[3], 100 * d_loss[4], g_loss[0]))
if epoch % sample_interval == 0:
self.sampel_image(epoch)
def sampel_image(self, epoch):
r, c = 2, 5
noise = np.random.normal(0, 1, (r * c, 100)) # ?
sampled_labels = np.arange(0, 10).reshape(-1, 1)
gen_imgs = self.generator.predict([noise, sampled_labels])
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].set_title("Digit: %d" % sampled_labels[cnt])
axs[i, j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weight": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weight'])
save(self.generator, "generator")
save(self.discriminator, "discriminator")
if __name__ == '__main__':
if not os.path.exists("./images"):
os.makedirs("./images")
acgan = ACGAN()
acgan.train(epochs=30000, batch_size=256, sample_interval=50)