Last time I talked about the example of two classification, today I will explore the problem of multi classification
actual combat
Introduction to iris data set
Iris data set is a commonly used experimental data set of classification, which is collected by Fisher, 1936. Iris, also known as iris flower data set, is a kind of multi variable analysis data set. The data set consists of 150 data sets, which are divided into three categories, each of which contains 50 data and each of which contains 4 attributes. According to the four attributes of calyx length, calyx width, petal length and petal width, we can predict which kind of iris belongs to (Setosa, versicolor, Virginia).
Here is an iris.csv file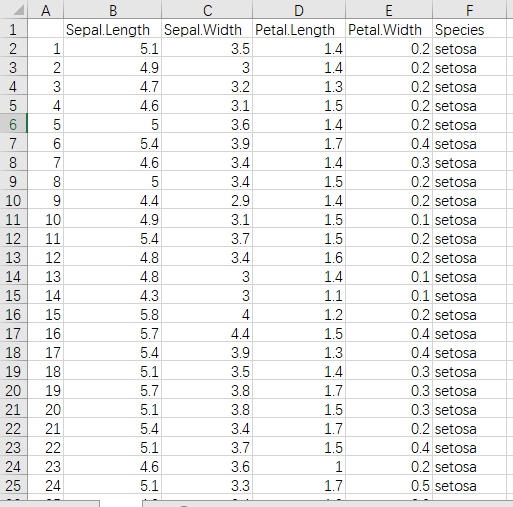
read file
import keras
from keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('../dataset/iris.csv')
data.head()
data.info()
OUT:
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
0 1 5.1 3.5 1.4 0.2 setosa
1 2 4.9 3.0 1.4 0.2 setosa
2 3 4.7 3.2 1.3 0.2 setosa
3 4 4.6 3.1 1.5 0.2 setosa
4 5 5.0 3.6 1.4 0.2 setosa
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
Unnamed: 0 150 non-null int64
Sepal.Length 150 non-null float64
Sepal.Width 150 non-null float64
Petal.Length 150 non-null float64
Petal.Width 150 non-null float64
Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.1+ KB
Data preprocessing
There is no missing value for the data, but the type is to be processed because it is text data
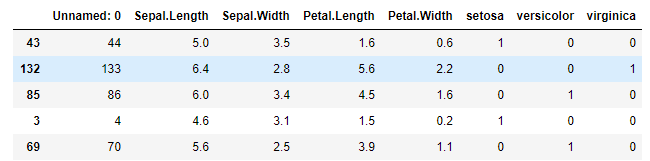
data.Species.unique() OUT: array(['setosa', 'versicolor', 'virginica'], dtype=object) ----- # Last time, it was very complicated. This time, it used advanced methods data = data.join(pd.get_dummies(data.Species)) # Get Dummies will directly create three columns ['setosa ',' versioncolor ',' virginica '] data.drop(['Species'],axis=1,inplace=True) print(data.head())
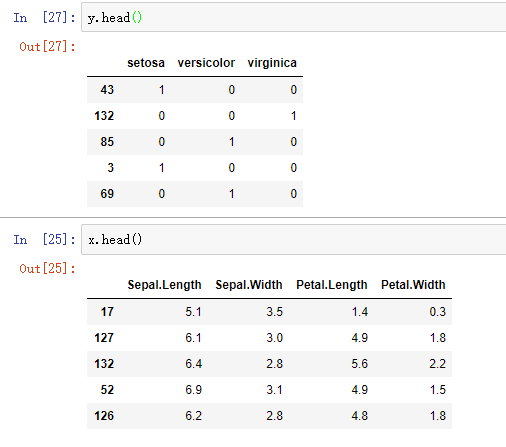
Assignment of x and y
x = data.iloc[:,1:-3] y = data.iloc[:,-3:]
It's messing up the order
index = np.random.permutation(len(data)) data = data.iloc[index]
Training model
model = keras.Sequential() model.add(layers.Dense(3, input_dim=4, activation='softmax'))
Here's the episode:
TypeError: softmax() got an unexpected keyword argument 'axis' solution:
Change axis=axis to dim=axis in line 3149 of tensorflow_backend.py to solve the problem. Reason: the installed keras library may not be compatible with TensorFlow library. You can also rollback the version of keras pip install keras==2.1
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
# The target data is thermal coded, and the cross entropy of softmax is calculated by means of the categorical cross entropy
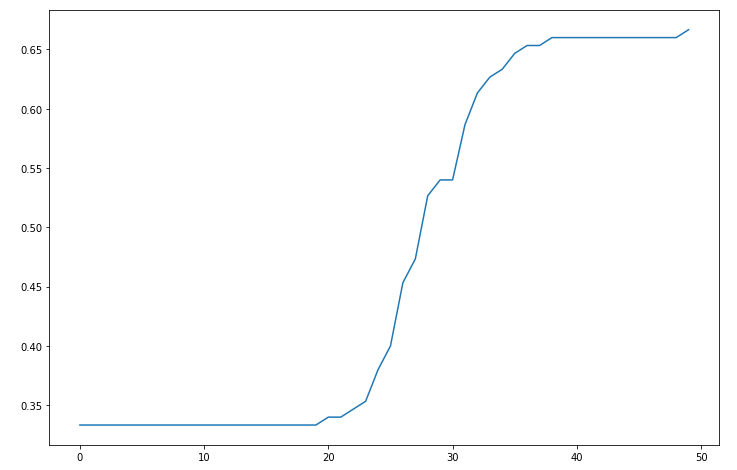
history = model.fit(x, y, epochs=50)
plt.plot(range(50), history.history.get('loss'))
plt.plot(range(50), history.history.get('acc'))
loss
acc