Knative provides a flexible implementation mechanism for auto-scaling. This paper gives you an in-depth understanding of the implementation mechanism of KPA auto-scaling from the dimension of "three horizontal and two vertical".Allows you to easily control Knative AutoZoom.
Note: This article is based on code interpretation of the latest Knative v0.11.0 version
KPA Implementation Flowchart
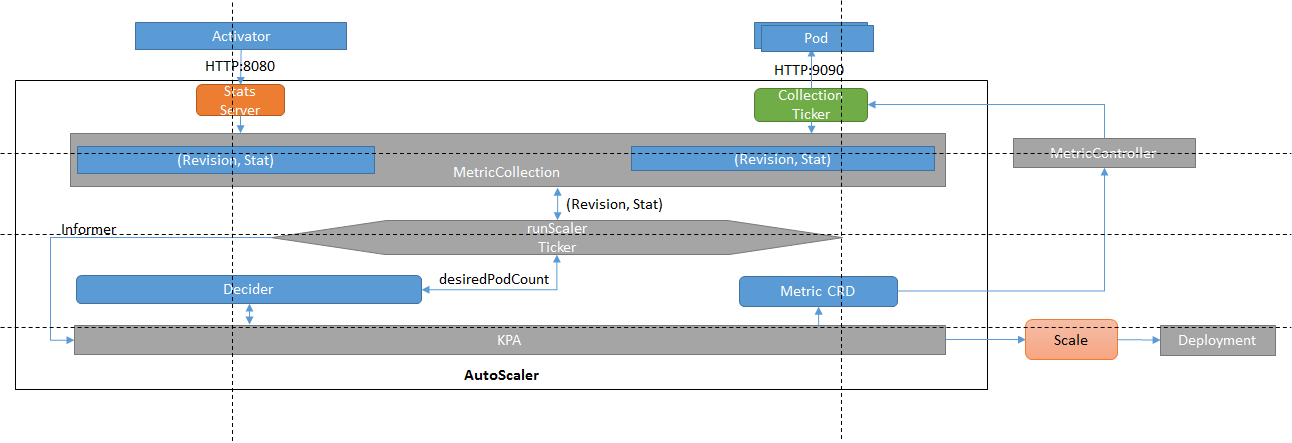
In Knative, creating a Revision creates the PodAutoScaler resource accordingly.Scale POD s in the current Revision by manipulating PodAutoScaler resources in KPA.
For the above process implementation, we analyze its implementation mechanism from the three-dimensional, two-dimensional.
Three Horizontal
- KPA Controller
- Calculate POD Number Based on Indicator Timing
- Indicator Collection
KPA Controller
Create PodAutoScaler through Revision, which consists of two resources (Decider and Metric) and one operation (Scale) in the KPA controller.The main code is as follows
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error { ...... decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName) if err != nil { return fmt.Errorf("error reconciling Decider: %w", err) } if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil { return fmt.Errorf("error reconciling Metric: %w", err) } // Metrics services are no longer needed as we use the private services now. if err := c.DeleteMetricsServices(ctx, pa); err != nil { return err } // Get the appropriate current scale from the metric, and right size // the scaleTargetRef based on it. want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale) if err != nil { return fmt.Errorf("error scaling target: %w", err) } ...... }
Here are two resources:
- Decider: The resource for scaling decision. Use Decider to get the number of scaled POD s: DesiredScale.
- Metric: Collect the resources for the indicator, and use Metric to collect the POD indicator under the current Revision.
Take another look at the Scale operation. In the Scale method, the number of POD instances that need to be expanded is determined based on the number of expanded PODs, the minimum number of instances, and the maximum number of instances. Then, the deployment's Relicas value is modified to achieve POD expansion. The code is as follows:
// Scale attempts to scale the given PA's target reference to the desired scale. func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) { ...... min, max := pa.ScaleBounds() if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale { logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale) desiredScale = newScale } desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale) if !shouldApplyScale { return desiredScale, nil } ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory) if err != nil { return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err) } currentScale := int32(1) if ps.Spec.Replicas != nil { currentScale = *ps.Spec.Replicas } if desiredScale == currentScale { return desiredScale, nil } logger.Infof("Scaling from %d to %d", currentScale, desiredScale) return ks.applyScale(ctx, pa, desiredScale, ps) }
Calculate POD Number Based on Indicator Timing
This is a story about Decider.A timer is created at the same time after the Decider is created, and the Scale method is called by default every 2 seconds (configurable through the TickInterval parameter), which is implemented as follows:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) { ...... metricName := spec.ScalingMetric var observedStableValue, observedPanicValue float64 switch spec.ScalingMetric { case autoscaling.RPS: observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now) a.reporter.ReportStableRPS(observedStableValue) a.reporter.ReportPanicRPS(observedPanicValue) a.reporter.ReportTargetRPS(spec.TargetValue) default: metricName = autoscaling.Concurrency // concurrency is used by default observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now) a.reporter.ReportStableRequestConcurrency(observedStableValue) a.reporter.ReportPanicRequestConcurrency(observedPanicValue) a.reporter.ReportTargetRequestConcurrency(spec.TargetValue) } // Put the scaling metric to logs. logger = logger.With(zap.String("metric", metricName)) if err != nil { if err == ErrNoData { logger.Debug("No data to scale on yet") } else { logger.Errorw("Failed to obtain metrics", zap.Error(err)) } return 0, 0, false } // Make sure we don't get stuck with the same number of pods, if the scale up rate // is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single // pod if we need to scale up. // E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need // 3 pods. See the unit test for this scenario in action. maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount) // Same logic, opposite math applies here. maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate) dspc := math.Ceil(observedStableValue / spec.TargetValue) dppc := math.Ceil(observedPanicValue / spec.TargetValue) logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f", dspc, dppc, maxScaleUp, maxScaleDown) // We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range. desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp)) desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp)) ...... return desiredPodCount, excessBC, true }
This method mainly obtains index information from MetricCollector and calculates the POD number that needs to be expanded based on the index information.Then set it in Decider.In addition, when the POD expected value in Decider changes, the PodAutoscaler reconciliation will be triggered, the key code is as follows:
...... if runner.updateLatestScale(desiredScale, excessBC) { m.Inform(metricKey) } ......
Set the reconcile Watch operation in the KPA controller:
...... // Have the Deciders enqueue the PAs whose decisions have changed. deciders.Watch(impl.EnqueueKey) ......
Indicator Collection
POD indicators are collected in two ways:
- PUSH Collection Indicators: External services, such as Activitor s, can call this interface to push metric s information through the Exposure Indicators interface
- PULL collection metrics: Gather metrics by calling the Queue Proxy service interface.
PUSH collection metrics are easy to implement, expose services in main.go, and push metrics received into MetricCollector:
// Set up a statserver. statsServer := statserver.New(statsServerAddr, statsCh, logger) .... go func() { for sm := range statsCh { collector.Record(sm.Key, sm.Stat) multiScaler.Poke(sm.Key, sm.Stat) } }()
How are PULL collection metrics collected?Remember the Metric resource mentioned above. Receiving the Metric resource here creates a timer that accesses the queue-proxy 9090 port every second to collect metrics.The key codes are as follows:
// newCollection creates a new collection, which uses the given scraper to // collect stats every scrapeTickInterval. func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection { c := &collection{ metric: metric, concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize), rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize), scraper: scraper, stopCh: make(chan struct{}), } logger = logger.Named("collector").With( zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name))) c.grp.Add(1) go func() { defer c.grp.Done() scrapeTicker := time.NewTicker(scrapeTickInterval) for { select { case <-c.stopCh: scrapeTicker.Stop() return case <-scrapeTicker.C: stat, err := c.getScraper().Scrape() if err != nil { copy := metric.DeepCopy() switch { case err == ErrFailedGetEndpoints: copy.Status.MarkMetricNotReady("NoEndpoints", ErrFailedGetEndpoints.Error()) case err == ErrDidNotReceiveStat: copy.Status.MarkMetricFailed("DidNotReceiveStat", ErrDidNotReceiveStat.Error()) default: copy.Status.MarkMetricNotReady("CreateOrUpdateFailed", "Collector has failed.") } logger.Errorw("Failed to scrape metrics", zap.Error(err)) c.updateMetric(copy) } if stat != emptyStat { c.record(stat) } } } }() return c }
Two Verticals
- 0-1 expansion
- 1-N expansion
The above analysis is from three horizontal angles of KPA implementation. KPA achieves 0-1 expansion and 1-N expansion. Below we further analyze from these two vertical angles.
We know that in Knative, traffic flows through two modes to POD:Serve and Proxy.
Proxy mode: Switch to Proxy mode when the POD number is 0 (in addition, scenarios for burst traffic will switch to Proxy mode, which is not explained in detail here).
Serve mode: Switch to Serve mode when the number of POD s is not zero.
So when do you switch modes?The code in KPA is implemented as follows:
mode := nv1alpha1.SKSOperationModeServe // We put activator in the serving path in the following cases: // 1. The revision is scaled to 0: // a. want == 0 // b. want == -1 && PA is inactive (Autoscaler has no previous knowledge of // this revision, e.g. after a restart) but PA status is inactive (it was // already scaled to 0). // 2. The excess burst capacity is negative. if want == 0 || decider.Status.ExcessBurstCapacity < 0 || want == -1 && pa.Status.IsInactive() { logger.Infof("SKS should be in proxy mode: want = %d, ebc = %d, PA Inactive? = %v", want, decider.Status.ExcessBurstCapacity, pa.Status.IsInactive()) mode = nv1alpha1.SKSOperationModeProxy }
0-1 expansion
Step 1: Indicator Collection
When the number of POD s is 0, the traffic request mode is Proxy mode.Traffic is taken over by the activity at this time. In the activity, the indicator information is sent to the MetricCollector in the KPA by calling the indicator interface provided in the KPA through WebSockt based on the indicator information of the number of requests.
In the main function in the Activitor, the access KPA service code is implemented as follows
// Open a WebSocket connection to the autoscaler. autoscalerEndpoint := fmt.Sprintf("ws://%s.%s.svc.%s%s", "autoscaler", system.Namespace(), pkgnet.GetClusterDomainName(), autoscalerPort) logger.Info("Connecting to Autoscaler at ", autoscalerEndpoint) statSink := websocket.NewDurableSendingConnection(autoscalerEndpoint, logger) go statReporter(statSink, ctx.Done(), statCh, logger)
Send request indicator code through WebSockt:
func statReporter(statSink *websocket.ManagedConnection, stopCh <-chan struct{}, statChan <-chan []autoscaler.StatMessage, logger *zap.SugaredLogger) { for { select { case sm := <-statChan: go func() { for _, msg := range sm { if err := statSink.Send(msg); err != nil { logger.Errorw("Error while sending stat", zap.Error(err)) } } }() case <-stopCh: // It's a sending connection, so no drainage required. statSink.Shutdown() return } } }
Step 2: Calculate POD number according to index
In the Scale method, the expected number of PODs is calculated based on the index information obtained by PUSH.Modify Decider's expected POD value to trigger PodAutoScaler reconciliation.
Step 3: Expansion
In the KPA controller, re-execute the reconcile method and perform scaler extensions to the current Revision.Then switch traffic mode to Server mode.Finally, 0-1 expansion operation is achieved.
1-N expansion
Step 1: Indicator Collection
When the number of PODs is not zero, the traffic request mode is Server mode.At this time, all POD queue proxy 9090 ports in the current revision will be accessed by PULL, pulling business metrics information, and accessing service URL code as follows:
... func urlFromTarget(t, ns string) string { return fmt.Sprintf( "http://%s.%s:%d/metrics", t, ns, networking.AutoscalingQueueMetricsPort) }
Step 2: Calculate POD number according to index
In the Scale method, the expected number of PODs is calculated based on the index information obtained by PULL.Modify Decider's expected POD value to trigger PodAutoScaler reconciliation.
Step 3: Scaling
In the KPA controller, re-execute the reconcile method and perform scaler scaling to the current Revision.If the scale is 0 or a burst traffic scenario is triggered, the traffic mode is switched to Proxy mode.The 1-N scaling operation is finally implemented.
summary
I believe that through the above introduction, a better understanding of the implementation of Knative KPA will help us not only to troubleshoot related problems, but also to implement custom scaling components based on such scaling mechanism, which is the soul of Knative auto-scaling scalability.
This article is the content of Aliyun and cannot be reproduced without permission.