Fundamentals of knowledge map (Zhihu series blog posts)
Starting from an example, this paper expounds the source and structure of the knowledge map. It is worth learning. Reference link:
https://zhuanlan.zhihu.com/p/31726910
https://zhuanlan.zhihu.com/p/31864048
https://zhuanlan.zhihu.com/p/32122644
What is the knowledge map
Knowledge Graph is a semantic network that maps the real world to the data world. It is composed of nodes and edges. Nodes represent entities or concepts in the physical world, and edges represent the attributes of entities or between them.
Application examples of knowledge map
Take an application example of knowledge map in search engine as an example:
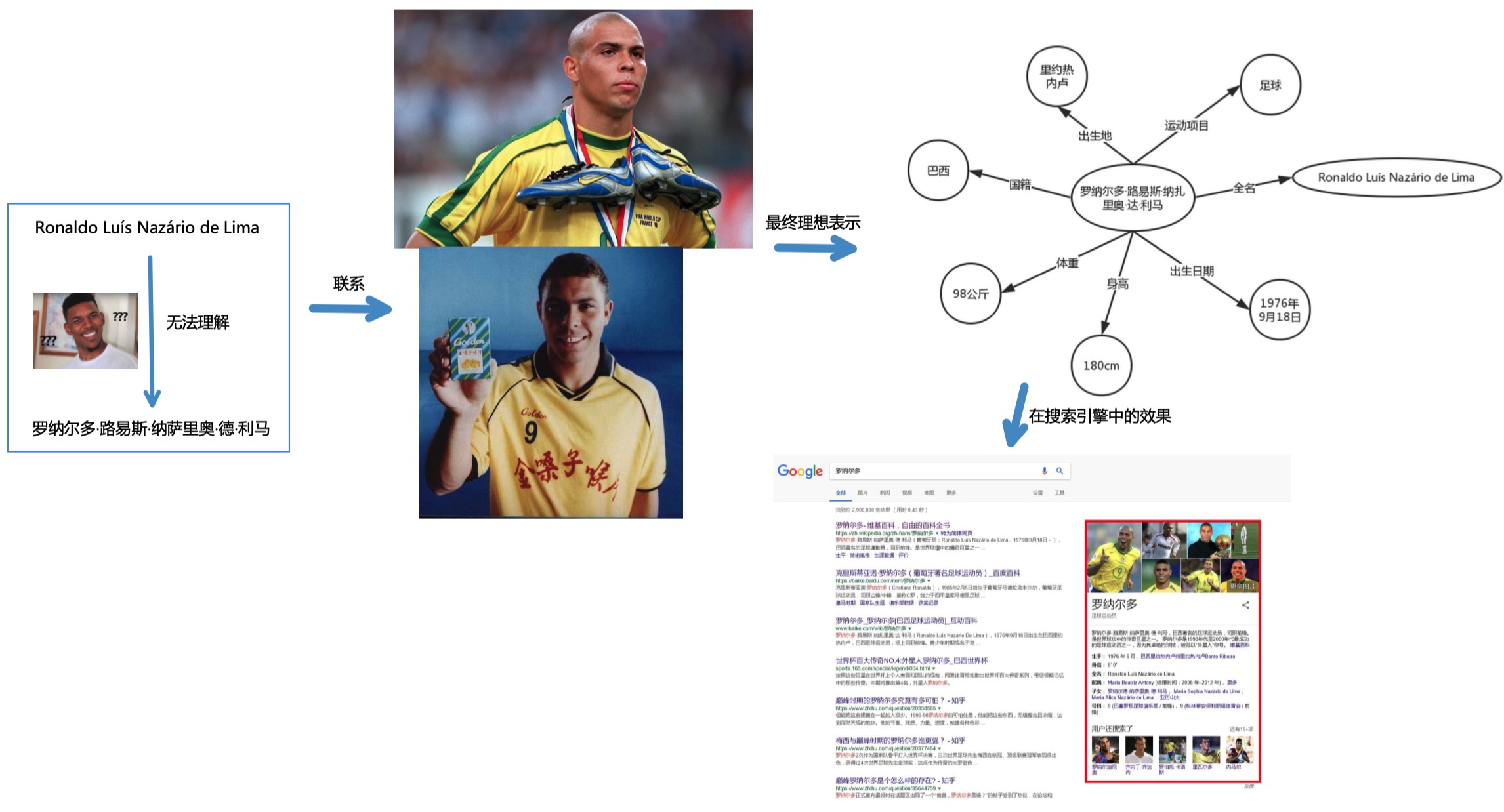
The reason for taking such an example is that computers have been facing such a dilemma - they can't obtain the semantic information of network text.
Although artificial intelligence has made great progress in recent years and has made achievements beyond human beings in some tasks, it is still a long way from the goal that a machine has the intelligence of a two or three-year-old child. A large part of the reason behind this distance is the lack of knowledge of machines.
As in the above example, the machine's response to the text is the same as our response to Ronaldo's Portuguese original name. In order for the machine to understand the meaning behind the text, we need to model the describable thing (entity), fill its attributes, and expand its connection with other things, that is, build the prior knowledge of the machine. Take Ronaldo as an example to illustrate that when we expand around this entity, we can get the knowledge map in the upper right corner.
Advantages of constructing knowledge map
By constructing the knowledge map, the computer can find the potential correlation in a large number of complex knowledge, which is difficult to achieve due to the limited brain capacity of human beings.
Structure of knowledge map
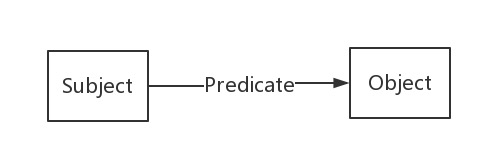
SPO
Knowledge map is composed of pieces of knowledge, and each piece of knowledge is represented as a SPO triple (subject predicate object).
RDF
In the knowledge map, we can use RDF to represent this ternary relationship. RDF is formally expressed as SPO triples, sometimes called a statement. In the knowledge map, we also call it a knowledge
RDF (Resource Description Framework) is a standard data model for describing entities / relationships. There are three types of RDF: International Resource Identifiers(IRIs),blank nodes and literals.
- IRI is similar to the URL (Uniform Resource Identifier) in the knowledge map, which uniquely defines an entity / resource in the whole knowledge map.
- blank node simply means that there are no IRI and literal resources, similar to empty nodes or anonymous resources.
- Literal, literal can be regarded as plain text with data type. For example, the original name of Ronaldo mentioned in the first part can be expressed as "Ronaldo Lu í s Naz á rio de Lima"^^xsd:string.
Type constraints for each part of SPO in RDF:
- Subject can be IRI or blank node.
- Predicate is IRI.
- All three types of Object are OK.
RDF instance
Then the triples in the above example are expressed in RDF:
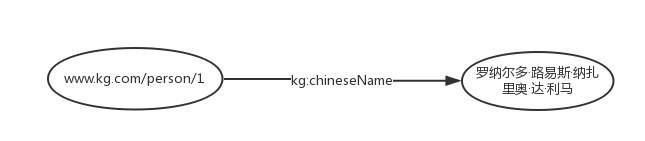
- www.kg.com/person/1 is an IRI, which is used to uniquely represent the entity "Ronaldo".
- kg:chineseName is also an IRI, which is used to represent the attribute of Chinese name.
- Kg: is the prefix defined in the RDF file, i.e. @ prefix kg:< http://www.kg.com/ontology/ >, kg:chineseName is actually http://www.kg.com/ontology/chineseName Abbreviation for.
Draw the above knowledge map in a more formal form:
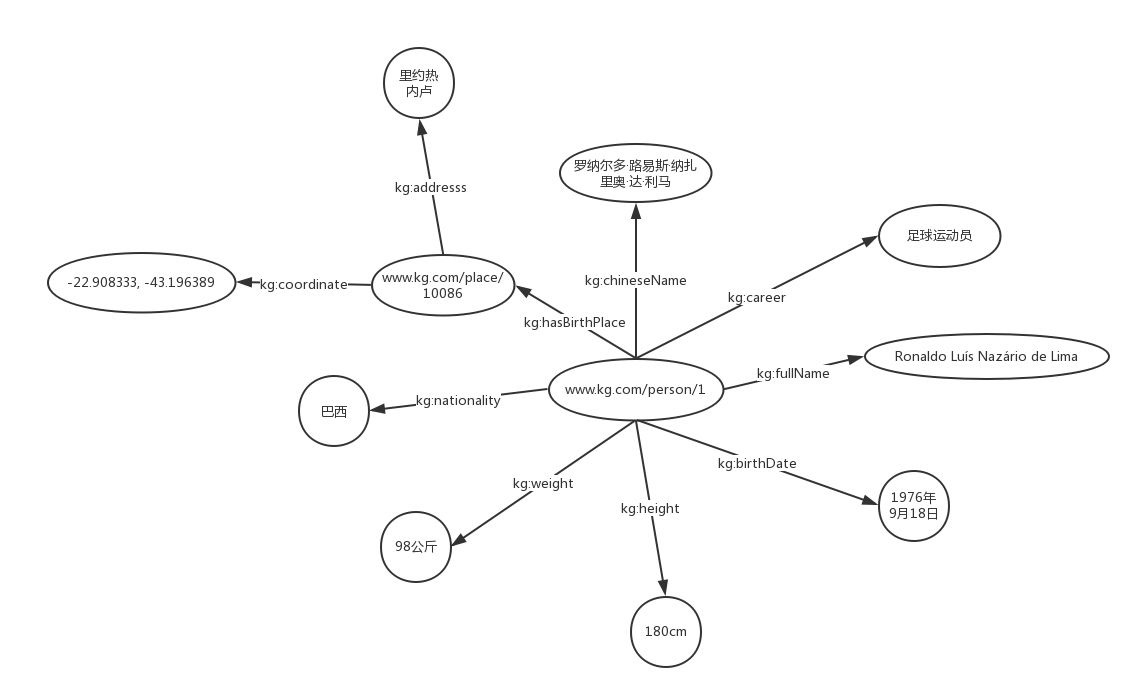
In fact, it can be considered that the knowledge map includes two node types: resources and literal quantity. The literal quantity is similar to the leaf node in the tree structure. The outgoing degree is 0 and can only be pointed to.
The relationship between knowledge atlas and semantic network
Semantic Web uses interconnected nodes and edges to represent knowledge. Nodes represent objects and concepts, and edges represent the relationship between nodes. We can easily understand semantics and semantic relations. Its expression is simple and straightforward, in line with nature. However, due to the lack of standards, it is difficult to apply in practice.
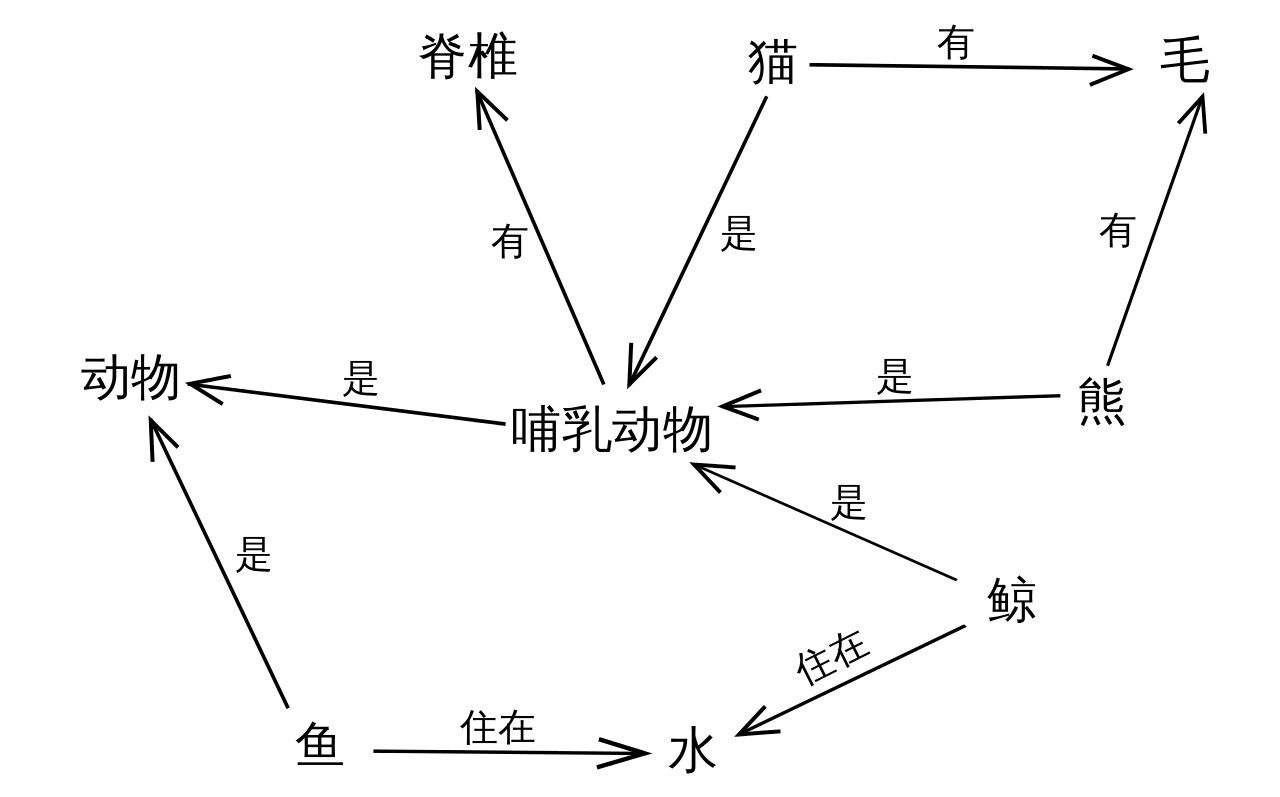
Knowledge map comes from semantic network , which solves the shortcoming of semantic network lacking standard
⭐ Ontology
In a more formal way, knowledge atlas is a structured data set with Ontology as the Schema layer and compatible with RDF data model.
Tom Gruber defines ontology as the formal description of concepts and relationships, which refers to the class level and relationship level of entities respectively. Let's continue with the example above. The nodes uniquely marked with IRI are an instance of a class, and each edge represents a relationship. Ronaldo is a person and Rio de Janeiro is a place. We use RDF to mean:
www.kg.com/person/1 kg:hasBirthPlace www.kg.com/place/10086 www.kg.com/person/1 kg:fullName "Ronaldo Luís Nazário de Lima"^^xsd:string
Here, kg:Person, kg:Place, kg:hasBirthPlace, kg:fullName are the classes and relationships defined in Ontology.
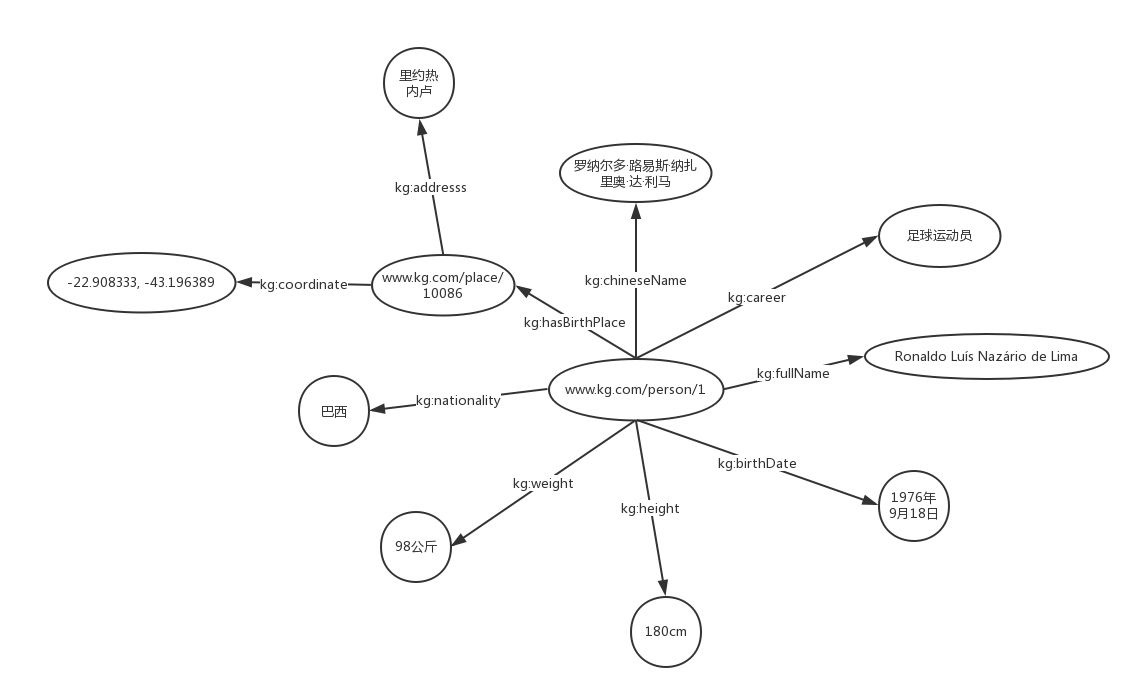
RDF serialization method
RDF can be said to be the cornerstone of the knowledge map. It is the SPO triples represented by RDF that constitute the whole knowledge map.
RDF Representation and type Already introduced. How to create an RDF dataset and serialize it? Serialization refers to how RDF data is stored and transmitted. At present, RDF serialization methods mainly include: RDF/XML, N-Triples, Turtle, RDFa, JSON-LD, etc.
- RDF/XML, as its name suggests, is to represent RDF data in XML format. This method is proposed because XML technology is relatively mature, and there are many ready-made tools to store and parse XML. However, for RDF, the format of XML is too verbose and not easy to read, and we usually don't use this way to process RDF data.
- N-Triples, that is, using multiple triples to represent RDF data sets, is the most intuitive representation. In the file, each line represents a triple, which is convenient for machine parsing and processing. Open domain knowledge map DBpedia This format is usually used to publish data.
- Turtle should be the most widely used RDF serialization method. It is more compact than RDF/XML and better readable than N-Triples.
- RDFa (The Resource Description Framework in Attributes) is an extension of HTML5. Without changing any display effect, it allows website builders to mark entities in the page, such as people, places, times, comments, etc. In other words, by embedding RDF data into web pages, search engines can better analyze unstructured pages and obtain some useful structured information. Readers can go to this page Feel RDFa, which intuitively shows the pages seen by ordinary users, the pages seen by browsers and the structured information parsed by search engines.
- JSON-LD, namely "JSON for Linking Data", stores RDF data in the form of key value pairs. Interested readers can refer to this website.
Still combined The above example , the specific expressions of N-Triples and Turtle are given:
# Example1 N-Triples: <http://www.kg. com/person/1> < http://www.kg.com/ontology/chineseName >"Ronaldo Luis nazario de Lima" ^ ^ string <http://www.kg. com/person/1> < http://www.kg.com/ontology/career >"Football player" ^ ^ string <http://www.kg.com/person/1> <http://www.kg.com/ontology/fullName> "Ronaldo Luís Nazário de Lima"^^string. <http://www.kg.com/person/1> <http://www.kg.com/ontology/birthDate> "1976-09-18"^^date. <http://www.kg.com/person/1> <http://www.kg.com/ontology/height> "180"^^int. <http://www.kg.com/person/1> <http://www.kg.com/ontology/weight> "98"^^int. <http://www.kg. com/person/1> < http://www.kg.com/ontology/nationality >"Brazil" ^ ^ string <http://www.kg.com/person/1> <http://www.kg.com/ontology/hasBirthPlace> <http://www.kg.com/place/10086>. <http://www.kg. com/place/10086> < http://www.kg.com/ontology/address >"Rio de Janeiro" ^ ^ string <http://www.kg.com/place/10086> <http://www.kg.com/ontology/coordinate> "-22.908333, -43.196389"^^string.
When represented by Turtle, we will add Prefix to abbreviate the IRI of RDF.
# Example2 Turtle: @prefix person: <http://www.kg.com/person/> . @prefix place: <http://www.kg.com/place/> . @prefix : <http://www.kg.com/ontology/> . person:1 :chineseName "Ronaldo·Louis·Nasario·virtue·Lima"^^string. person:1 :career "Football player"^^string. person:1 :fullName "Ronaldo Luís Nazário de Lima"^^string. person:1 :birthDate "1976-09-18"^^date. person:1 :height "180"^^int. person:1 :weight "98"^^int. person:1 :nationality "Brazil"^^string. person:1 :hasBirthPlace place:10086. place:10086 :address "Rio de Janeiro"^^string. place:10086 :coordinate "-22.908333, -43.196389"^^string.
The same entity has multiple attributes (data attributes) or relationships (object attributes), which can be represented by only one subject to make it more compact. We can change the Turtle above to:
# Example3 Turtle:
@prefix person: <http://www.kg.com/person/> .
@prefix place: <http://www.kg.com/place/> .
@prefix : <http://www.kg.com/ontology/> .
person:1 :chineseName "Ronaldo·Louis·Nasario·virtue·Lima"^^string;
:career "Football player"^^string;
:fullName "Ronaldo Luís Nazário de Lima"^^string;
:birthDate "1976-09-18"^^date;
:height "180"^^int;
:weight "98"^^int;
:nationality "Brazil"^^string;
:hasBirthPlace place:10086.
place:10086 :address "Rio de Janeiro"^^string;
:coordinate "-22.908333, -43.196389"^^string.
That is, an entity is represented by a sentence (the sentence here refers to an English period, not multiple sentences), and the attributes are used between them; separate.
Disadvantages of RDF: limited expression ability
The disadvantage of RDF is that it has limited expression ability, can not distinguish between classification and objects, and can not define and describe the relationship / attribute of classes. If we want to define Ronaldo as a person and Rio de Janeiro as a place, and what attributes do people have, what attributes do places have, and what relationships exist between people and places, RDF is powerless at this time.
But this ability to generalize abstraction is actually quite important, RDFSandOWL These two technologies, or schema/ontology language, solve the disadvantage of limited expression ability of RDF.
RDFS/OWL
RDFS/OWL is a collection of predefined attributes used to describe RDF / Owl.
The difference between schema language and relational database
The database of relational database is also called Schema (schema) , this schema is similar to RDF's schema language. We can think that every table in the database is a Class, every row in the table is an instance or object of this Class, and every column in the table is the attribute contained in this Class.
For example, if we represent the two categories of people and places in the database, we can create a table for them respectively; Then use another table to show the relationship between people and places.
RDFS/OWL and RDF serialization methods
The RDFS/OWL serialization mode is consistent with that of the RDF serializer. The commonly used methods are RDF/XML and Turtle. Some conventional rules are as follows:
- Attributes are usually represented by words or phrases beginning with lowercase, and classes beginning with uppercase.
- data property (the relationship between entities and literal) is usually composed of nouns, while object property (the relationship between entities) is usually composed of verbs (has, is and so on) plus nouns.
- Hump nomenclature is used by default.
RDFS: lightweight schema language
RDFS (Resource Description Framework Schema), the most basic schema language.
Taking Ronaldo knowledge map as an example, we define RDF data at the conceptual and abstract levels. The following RDFS defines two classes: people and places, and the attributes contained in each class.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <http://www.kg.com/ontology/> .
### Here, we use the word rdfs:Class to define the two classes of "person" and "place".
:Person rdf:type [rdfs:Class](https://www.wolai.com/n5WCiaoc8bTHey7nWVeMuR#2e27EtKcXVzcex2D3GMRQs).
:Place rdf:type rdfs:Class.
### rdfs does not distinguish between data attributes and object attributes. The vocabulary rdf:Property defines attributes, that is, the "edge" of RDF.
:chineseName rdf:type rdf:Property;
[rdfs:domain](https://www.wolai.com/n5WCiaoc8bTHey7nWVeMuR#4C5Bw9d2nsD9QCpxsK8DWk) :Person;
[rdfs:range](https://www.wolai.com/n5WCiaoc8bTHey7nWVeMuR#uMGQQqjW3VaZiaC4hbn2aK) xsd:string .
:career rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:fullName rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:birthDate rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:date .
:height rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:int .
:weight rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:int .
:nationality rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:hasBirthPlace rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range :Place .
:address rdf:type rdf:Property;
rdfs:domain :Place;
rdfs:range xsd:string .
:coordinate rdf:type rdf:Property;
rdfs:domain :Place;
rdfs:range xsd:string .
- rdfs:Class is used to define classes.
- rdfs:domain is used to indicate which category the attribute belongs to.
- rdfs:range is used to describe the value type of this attribute.
- RDFS: subcalassof is used to describe the parent class of this class.
For example, we can define an athlete class and declare that this class is a subclass of human. - rdfs:subProperty is used to describe the parent property of this property.
For example, we can define a name attribute and declare that Chinese name and full name are subclasses of name.
rdf:Property and rdf:type are also terms of RDFS, because RDFS is essentially an extension of RDF terms. Please refer to other terms of RDFS and their usage W3C official documents.
Hierarchy of RDFS in knowledge map
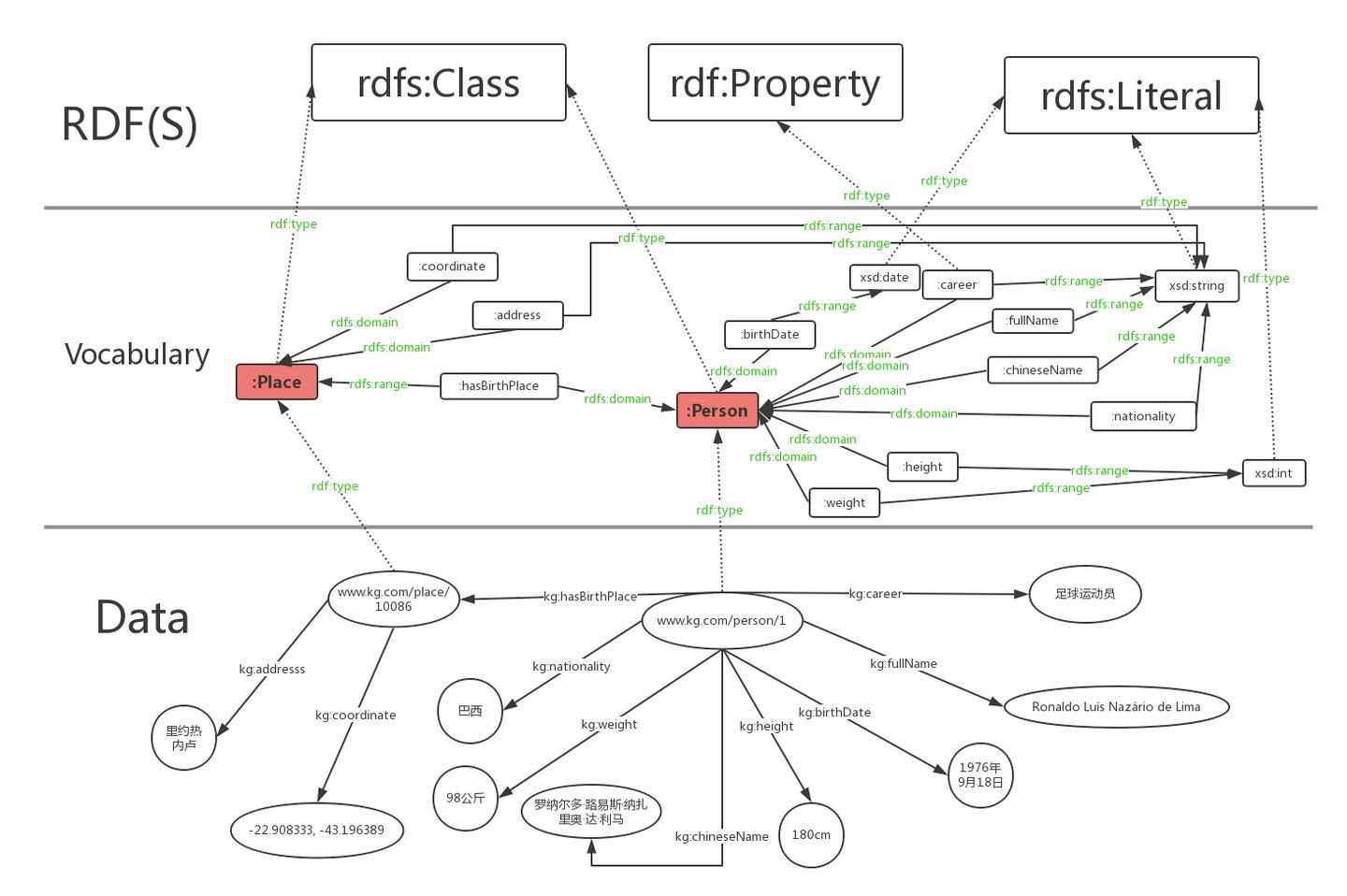
The data layer below is the specific description of Ronaldo's knowledge map with RDF. Vocabulary can be understood as schema layer (ontology), which is some words (categories and attributes) defined by ourselves, and RDF(S) is a predefined word. From bottom to top is a process from concrete to abstract.
In the figure, we use red rounded rectangle to represent the class, green font to represent three predefined words: rdf:type, rdfs:domain and rdfs:range, and dotted line to represent the ownership relationship of rdf:type. In addition, in order to reduce the crossing of lines in the figure, we only retain the rdf:type belonging relationship of the attribute "career", and omit this relationship of other attributes.
OWL: extension of RDFS
The expressive ability of RDFS is still quite limited, so OWL (Ontology Web Language) is proposed. OWL can also be regarded as an extension of RDFS, which adds additional predefined words. As one of the cores of OWL semantic web technology stack, it has two main functions:
- Provide fast and flexible data modeling capability.
- Efficient automatic reasoning.
Let's first look at how to use OWL for data modeling, and still use OWL to describe Ronaldo's knowledge map at the semantic level:
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <http://www.kg.com/ontology/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
### Here we use the word owl:Class to define the two classes of "person" and "place".
:Person rdf:type owl:Class.
:Place rdf:type owl:Class.
### Owl distinguishes between data attributes and object attributes (object attributes represent the relationship between entities). The vocabulary owl:DatatypeProperty defines data properties, and owl:ObjectProperty defines object properties.
:chineseName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:career rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:fullName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:birthDate rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:date .
:height rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:int .
:weight rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:int .
:nationality rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:hasBirthPlace rdf:type owl:ObjectProperty;
rdfs:domain :Person;
rdfs:range :Place .
:address rdf:type owl:DatatypeProperty;
rdfs:domain :Place;
rdfs:range xsd:string .
:coordinate rdf:type owl:DatatypeProperty;
rdfs:domain :Place;
rdfs:range xsd:string .
The hierarchy of OWL in knowledge map
After the description language of schema layer is changed to OWL, the hierarchy diagram is represented as:
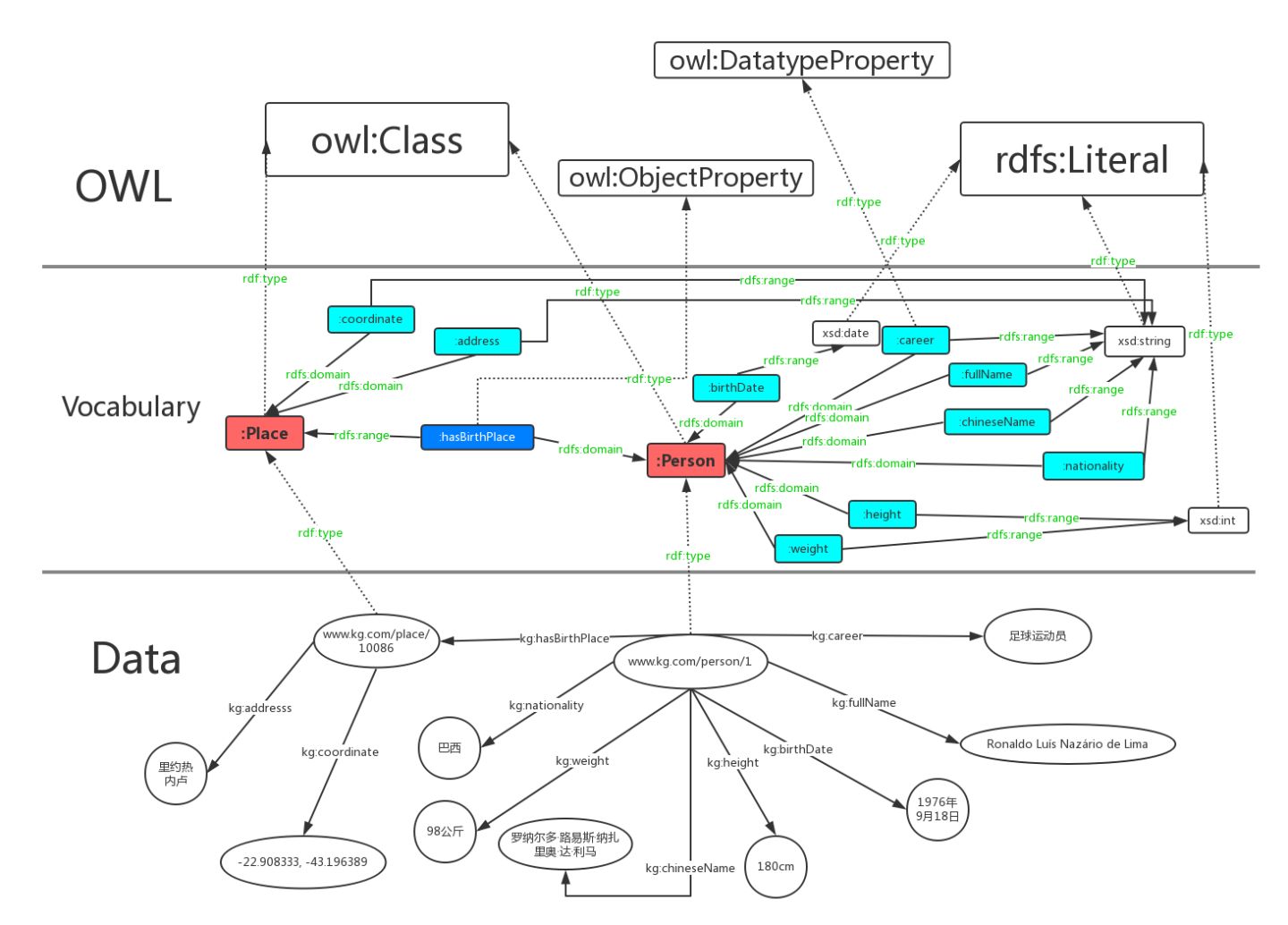
Data attributes are represented in cyan and object attributes are represented in blue.