Kotlin collaboration series article navigation:
Kotlin process I - Coroutine
Kotlin collaboration process 2 - Channel
Kotlin collaboration process III - data Flow
Kotlin collaboration process IV -- Application of Flow and Channel
Kotlin collaboration 5 - using kotlin collaboration in Android
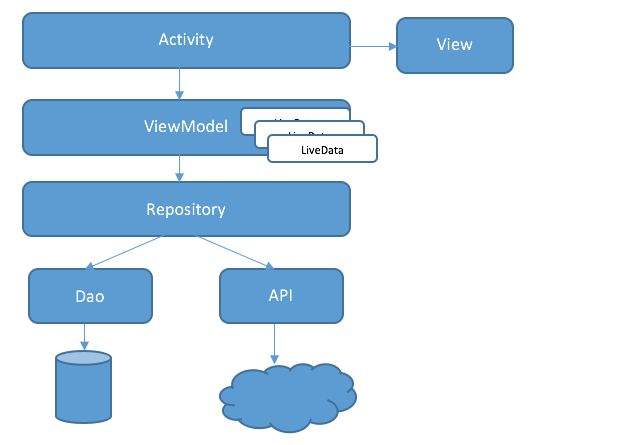
1, Android MVVM architecture
Architecture diagram officially provided by Android
2, Add dependency
To use a coroutine in an Android project, add the following dependencies to the application's build In the gradle file:
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.9")
}
3, Execute in background thread
3.1 what problems are solved by the collaborative process
In Android, Xie Cheng has solved two problems:
- Time consuming task, running too long, blocking the main thread
- The main thread is safe, allowing you to call any suspend (suspend) function in the main thread.
Getting Web pages and interacting with API s all involve network requests. Similarly, reading data from the database and loading pictures from the hard disk involve file reading. These are what we call time-consuming tasks.
To avoid making network requests in the main thread, a common pattern is to use callback, which can callback into your code at some time in the future.
class ViewModel: ViewModel() {
fun getDataAndShow() {
getApi() { result ->
show(result)
}
}
}
Although the getApi() method is called in the main thread, it makes a network request in another thread. Once the result of the network request is available, the callback is called in the main thread. This is a good way to deal with time-consuming tasks.
Using a coroutine to handle time-consuming tasks can simplify code. Taking the fetchDocs() method above as an example, we use a coroutine to rewrite the previous callback logic.
// Dispatchers.Main
suspend fun getDataAndShow() {
// Dispatchers.IO
val result = getApi()
// Dispatchers.Main
show(result)
}
// look at this in the next section
suspend fun getApi() = withContext(Dispatchers.IO){/*...*/}
As mentioned in the collaboration, the execution of withContext will be suspended and resumed after execution.
- Suspend -- suspend the execution of the current coroutine and save all local variables
- resume -- continue execution from the place where the suspended collaboration is suspended
The suspension and recovery of the coroutine work together to replace the callback. This enables us to write asynchronous code in a synchronous way.
3.2 ensure the safety of main thread
Using suspend does not mean telling Kotlin to run the function in the background thread. To prevent a function from slowing down the main thread, we can tell the Kotlin coroutine to use Default or IO scheduler.
- Room automatically provides main thread safety when you use suspended functions, RxJava and LiveData.
- Network frameworks such as Retrofit and Volley generally manage thread scheduling by themselves. When you use Kotlin collaboration, you don't need to explicitly ensure the safety of the main thread.
Through coprocessing, you can fine-grained control thread scheduling, because withContext allows you to control the thread on which any line of code runs without introducing a callback to obtain the results. It can be applied to very small functions, such as database operations and network requests. Therefore, it is better to use withContext to ensure that each function is safe to execute on any scheduler, including Main, so that the caller does not need to consider what thread to run on when calling the function.
It should be safe for a well written suspend function to be called by any thread.
3.3 performance of withcontext
If a function will make 10 calls to the database, you can tell Kotlin to call a handover in the external withContext. Although the database will repeatedly call withcontext, it will find the fastest path under the same scheduler. In addition, dispatchers Default and dispatchers The co process switching between IOS has been optimized to avoid thread switching as much as possible.
4, Structured concurrency
4.1 tracking coordination process
It's really difficult to track a thousand collaborations manually using code. You can try to track them and manually ensure that they will be completed or cancelled in the end, but such code is redundant and error prone. If your code is not perfect, you will lose track of a collaborative process, which I call task leakage.
The leaked process will waste memory, CPU, disk, and even send an unnecessary network request.
In order to avoid revealing the cooperation process, Kotlin introduces structured concurrency. Structured and combined with language features and best practices, following this principle will help you track all tasks in the collaboration.
In Android, we can do three things using structured Concurrency:
- Cancel tasks that are no longer needed
- Track all ongoing tasks
- Error signal when collaboration fails
4.2 cancel task by scope
In Kotlin, the coroutine must run in CoroutineScope. CoroutineScope will track your collaboration, even if it has been suspended. In order to ensure that all collaborations are tracked, Kotlin does not allow you to start new collaborations without CoroutineScope. You can think of CoroutineScope as a lightweight ExecutorServicce with special capabilities. It gives you the ability to create new processes that have the hang and recover capabilities we discussed in the previous article. CoroutineScope will track all the collaborations, and it can also cancel all the collaborations opened by it. This is very suitable for Android developers. When users leave the current page, they can ensure that all opened things are cleaned up.
CoroutineScope will track all the collaborations, and it can also cancel all the collaborations opened by it.
It should be noted that the scope that has been cancelled cannot start a new process. If you just want to cancel a process within the scope, you need to cancel it with the Job of the process.
4.2.1 start a new process
There are two methods to start a collaborative process, and they have different usages:
- Use the launch collaboration builder to start a new collaboration, which has no return value
- It allows you to use the awync function to get the result of a new aiync, which allows you to start a new aiync.
In most cases, the answer to how to start a coroutine from an ordinary function is to use launch, because an ordinary function cannot call await. To be exact, ordinary functions cannot call suspended functions.
fun foo(scope: CoroutineScope) {
scope.launch {
test() // allow
}
val task = scope.async { }
task.await() // not allow
test() // not allow
}
Launch connects the world of code and coroutines in ordinary functions. Inside the launch, you can call the suspend function. Because launch started a collaborative process.
It is well understood that the suspend function can only be called directly or indirectly in the coroutine.
Launch is a bridge to bring ordinary functions into the world of coprocessing.
Tip: one big difference between launch and async is exception handling. Async expects you to get the result (or exception) by calling await, so it won't throw an exception by default. This means that when async is used to start a new procedure, it will quietly discard the exception.
Suppose we write a suspend method and an exception occurs
val unrelatedScope = MainScope()
// example of a lost error
suspend fun lostError() {
// async without structured concurrency
unrelatedScope.async {
throw InAsyncNoOneCanHearYou("except")
}
}
Note that the above code declares an unassociated scope of the collaboration and does not start a new collaboration through structured concurrency.
In this case, you will throw an error in the call to async, because the above exception will be thrown again. But if you don't call await, this error will be saved forever and wait quietly for it to be found.
If we use structured concurrency to write the above code, the exception will be correctly thrown to the caller.
suspend fun foundError() {
coroutineScope {
async {
throw StructuredConcurrencyWill("throw")
}
}
}
Because coroutineScope will wait for all child processes to complete, it will also know when the child process fails. When an exception is thrown by the coroutine scope started coroutine scope, coroutine scope will throw the exception to the caller. If you use coroutineScope instead of supervisor scope, all child processes will be stopped immediately when an exception is thrown.
Structured concurrency ensures that when an error occurs in a collaboration, its caller or scope can find it.
4.2.2 start in ViewModel
If a CoroutineScope tracks all the collaborations started in it and launch creates a new one, where should you call launch and place it in the scope of the collaboration? Also, when should you cancel all the collaborations started in the scope?
In Android, coroutine scope is usually associated with the user interface. This will help you avoid collaboration leakage and make the activities or fragments that users no longer need no additional work. When the user leaves the current page, the CoroutineScope associated with the page cancels all work.
Structured concurrency guarantees that when the scope of a collaboration is cancelled, all the collaborations in it will be cancelled.
When integrating the collaboration process through Android Architecture Components, the collaboration process is generally started in ViewModel. This is where many important tasks begin to work, and you don't have to worry that rotating the screen will kill the process.
Start the process through viewModelScope. When viewModelScope is cleared (that is, onCleared() is called), it will automatically cancel all the processes started by it.
Use viewModelScope to switch from a normal function to a coroutine when you need the lifecycle of the coroutine to be consistent with that of the ViewModel. Then, because viewModelScope will automatically cancel the collaboration, it can ensure that any work, even an endless loop, can be cancelled when it is no longer needed.
4.3 using structured concurrency
Using an unassociated CoroutineScope (note the capital letter C), or using a global scope GlobalScope, can lead to unstructured concurrency. Unstructured concurrency is considered only in a few cases where you need the life cycle of the collaboration to be longer than the scope of the caller. In general, you should use structured concurrency to track concurrency, handle exceptions, and have a good cancellation mechanism.
Structured concurrency helps us solve three problems:
- Cancel tasks that are no longer needed
- Track all ongoing tasks
- Error signal when collaboration fails
Structured concurrency gives us the following guarantees:
- When the scope is cancelled, the collaboration will also be cancelled
- When the suspend function returns, all of its tasks have been completed
- When an error occurs in the process, its caller will be notified
Together, these make our code more secure and concise, and help us avoid task disclosure.
5, Some best practices for using synergy in Android
5.1 injection scheduler
When creating a new collaboration or calling withContext, do not hard code Dispatchers.
// DO inject Dispatchers
class NewsRepository(
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend fun loadNews() = withContext(defaultDispatcher) { /* ... */ }
}
// DO NOT hardcode Dispatchers
class NewsRepository {
// DO NOT use Dispatchers.Default directly, inject it instead
suspend fun loadNews() = withContext(Dispatchers.Default) { /* ... */ }
}
This dependency injection mode can reduce the difficulty of testing, because you can use test coroutine dispatcher to replace these schedulers in unit tests and plug-in tests to improve the certainty of testing.
5.2 the suspend function should ensure thread safety
That is, as mentioned in 3.2, the suspended function should be safe for any thread, and the caller of the suspended function should not switch threads.
class NewsRepository(private val ioDispatcher: CoroutineDispatcher) {
// As this operation is manually retrieving the news from the server
// using a blocking HttpURLConnection, it needs to move the execution
// to an IO dispatcher to make it main-safe
suspend fun fetchLatestNews(): List<Article> {
withContext(ioDispatcher) { /* ... implementation ... */ }
}
}
// This use case fetches the latest news and the associated author.
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository
) {
// This method doesn't need to worry about moving the execution of the
// coroutine to a different thread as newsRepository is main-safe.
// The work done in the coroutine is lightweight as it only creates
// a list and add elements to it
suspend operator fun invoke(): List<ArticleWithAuthor> {
val news = newsRepository.fetchLatestNews()
val response: List<ArticleWithAuthor> = mutableEmptyList()
for (article in news) {
val author = authorsRepository.getAuthor(article.author)
response.add(ArticleWithAuthor(article, author))
}
return Result.Success(response)
}
}
This pattern can improve the scalability of the application, because the class calling the suspended function does not have to worry about which Dispatcher to use to handle which type of work. This responsibility will be borne by the class performing the relevant work.
5.3 the ViewModel shall create a collaboration
The ViewModel class should prefer to create a coroutine rather than expose a suspended function to execute business logic. The suspend function in ViewModel is useful if you only need to issue a value instead of exposing the state using a data flow.
// DO create coroutines in the ViewModel
class LatestNewsViewModel(
private val getLatestNewsWithAuthors: GetLatestNewsWithAuthorsUseCase
) : ViewModel() {
private val _uiState = MutableStateFlow<LatestNewsUiState>(LatestNewsUiState.Loading)
val uiState: StateFlow<LatestNewsUiState> = _uiState
fun loadNews() {
viewModelScope.launch {
val latestNewsWithAuthors = getLatestNewsWithAuthors()
_uiState.value = LatestNewsUiState.Success(latestNewsWithAuthors)
}
}
}
// Prefer observable state rather than suspend functions from the ViewModel
class LatestNewsViewModel(
private val getLatestNewsWithAuthors: GetLatestNewsWithAuthorsUseCase
) : ViewModel() {
// DO NOT do this. News would probably need to be refreshed as well.
// Instead of exposing a single value with a suspend function, news should
// be exposed using a stream of data as in the code snippet above.
suspend fun loadNews() = getLatestNewsWithAuthors()
}
The view should not directly trigger any collaboration to execute business logic, but should delegate this work to the ViewModel. In this way, the business logic becomes easier to test because you can unit test the ViewModel object without using the plug-in tests necessary for the test view.
In addition, if the work is started in viewModelScope, your collaboration will be automatically retained after configuration changes. If you use lifecycleScope to create a collaboration, you must handle the operation manually. If the lifetime of a collaboration needs to be longer than the scope of the ViewModel, see the section "creating a collaboration in the business and data layers".
The white point is that business logic should be understood. Collaborative processing should be started in the ViewModel, not in the View.
Note: the view should start the process with the logic related to the interface. For example, extract an image from the Internet or format a string.
5.4 do not expose variable types
It is best to expose immutable types to other classes. In this way, all changes to mutable types are concentrated in one class for debugging in case of problems.
// DO expose immutable types
class LatestNewsViewModel : ViewModel() {
private val _uiState = MutableStateFlow(LatestNewsUiState.Loading)
val uiState: StateFlow<LatestNewsUiState> = _uiState
/* ... */
}
class LatestNewsViewModel : ViewModel() {
// DO NOT expose mutable types
val uiState = MutableStateFlow(LatestNewsUiState.Loading)
/* ... */
}
5.5 the data layer and business layer shall disclose the suspended function and data flow
Classes in the data layer and business layer usually expose functions to perform one-time calls or receive notifications of data changes over time. Classes in these layers should expose suspended functions for one-time calls and expose the data flow to receive notifications of data changes.
// Classes in the data and business layer expose
// either suspend functions or Flows
class ExampleRepository {
suspend fun makeNetworkRequest() { /* ... */ }
fun getExamples(): Flow<Example> { /* ... */ }
}
After adopting this best practice, the caller (usually the presentation layer) can control the execution and lifecycle of the work in these layers, and cancel the corresponding work when necessary.
Create a process in the business layer and data layer
For classes in the data layer or business layer that need to create a collaboration for different reasons, they can choose different options.
If the work to be done in these collaborations is relevant only when the user views the current screen, the caller's life cycle should be followed. In most cases, the caller will be ViewModel. In this case, coroutineScope or supervisorScope should be used.
class GetAllBooksAndAuthorsUseCase(
private val booksRepository: BooksRepository,
private val authorsRepository: AuthorsRepository,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend fun getBookAndAuthors(): BookAndAuthors {
// In parallel, fetch books and authors and return when both requests
// complete and the data is ready
return coroutineScope {
val books = async(defaultDispatcher) {
booksRepository.getAllBooks()
}
val authors = async(defaultDispatcher) {
authorsRepository.getAllAuthors()
}
BookAndAuthors(books.await(), authors.await())
}
}
}
If the work to be completed is relevant as long as the application is open, and the work is not limited to a specific screen, the life cycle of the work should be longer than that of the caller. In this case, you should use an external CoroutineScope.
class ArticlesRepository(
private val articlesDataSource: ArticlesDataSource,
private val externalScope: CoroutineScope,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
// As we want to complete bookmarking the article even if the user moves
// away from the screen, the work is done creating a new coroutine
// from an external scope
suspend fun bookmarkArticle(article: Article) {
externalScope.launch(defaultDispatcher) {
articlesDataSource.bookmarkArticle(article)
}
.join() // Wait for the coroutine to complete
}
}
externalScope should be created and managed by classes that exist longer than the current screen, and can be managed by the Application class or ViewModel whose scope is limited to the navigation map.
5.6 inject TestCoroutineDispatcher into the test
An instance of TestCoroutineDispatcher should be injected into a class within the test. The tester controls the timing of your tasks and enables you to execute them immediately.
Use the runblocking test of TestCoroutineDispatcher in the test body to wait for all the collaborations using the corresponding scheduler to complete.
class ArticlesRepositoryTest {
private val testDispatcher = TestCoroutineDispatcher()
@Test
fun testBookmarkArticle() {
// Execute all coroutines that use this Dispatcher immediately
testDispatcher.runBlockingTest {
val articlesDataSource = FakeArticlesDataSource()
val repository = ArticlesRepository(
articlesDataSource,
// Make the CoroutineScope use the same dispatcher
// that we use for runBlockingTest
CoroutineScope(testDispatcher),
testDispatcher
)
val article = Article()
repository.bookmarkArticle(article)
assertThat(articlesDataSource.isBookmarked(article)).isTrue()
}
// make sure nothing else is scheduled to be executed
testDispatcher.cleanupTestCoroutines()
}
}
Because all the collaborations created by the tested class use the same TestCoroutineDispatcher, and the test body will use runblocking test to wait for the execution of the collaborations, your test will become deterministic and will not be affected by race conditions.
Note: if other Dispatchers are not used in the tested code, the above situation will occur. Therefore, we do not recommend hard coding Dispatchers in classes. If you need to inject multiple Dispatchers, you can pass the same instance of TestCoroutineDispatcher.
5.7 avoid GlobalScope
This is similar to the injection scheduler best practice. By using GlobalScope, you will hard code the CoroutineScope used by the class, which will cause some problems:
- Increase hard coded values. If you hard code GlobalScope, you may also hard code Dispatchers.
- This makes testing very difficult because your code is executed in an uncontrolled scope and you will not be able to control its execution.
- You cannot set a common CoroutineContext to execute all the coroutines built into the scope itself.
You can consider injecting a coroutine scope for work that needs to exist longer than the current scope. To learn more about this topic, see the section "creating collaborations in the business and data layers".
5.8 set the coordination process as cancelable
Cancellation of a collaboration process belongs to a collaboration operation, that is, after the Job of the collaboration process is cancelled, the corresponding collaboration process will not be cancelled before suspending or checking whether there is a cancellation operation. If you perform blocking operations in a collaboration, make sure that the corresponding collaboration is cancelable.
For example, if you want to read multiple files from disk, check whether the collaboration has been cancelled before starting reading each file. One way to check for cancellations is to call the ensureActive function.
someScope.launch {
for(file in files) {
ensureActive() // Check for cancellation
readFile(file)
}
}
kotlinx. All pending functions in coroutines, such as withContext and delay, are cancelable. If your coroutine calls these functions, you don't need to do anything else.
5.8 pay attention to abnormalities
Improper handling of exceptions thrown in the process may cause your application to crash. If an exception may occur, catch the corresponding exception in any collaboration content created using viewModelScope or lifecycleScope.
class LoginViewModel(
private val loginRepository: LoginRepository
) : ViewModel() {
fun login(username: String, token: String) {
viewModelScope.launch {
try {
loginRepository.login(username, token)
// Notify view user logged in successfully
} catch (error: Throwable) {
// Notify view login attempt failed
}
}
}
}