
Why
Recently, I'm very interested in compilers. Why should I learn the compilation principle? For me, it's because I need to write a DSL and an interpreter recently. For most programmers, learning compilers may have the following three aspects:
(1) Learning compiler design can help you better understand the program and how the computer runs. At the same time, writing a compiler or interpreter requires a lot of computer skills, which is also an improvement to the technology.
(2) Interview needs, the so-called "work screw, interview makes rocket". Learning compiler design helps to strengthen basic computer skills, improve coding literacy and better deal with the interview. After all, you don't know whether your interviewer is also interested in this.
(3) Work needs. Sometimes you may need to create some domain specific languages or invent a new language (this need is not too much). At this time, you need to write a compiler or interpreter to meet your needs.
Compiler and interpreter
The compiler takes the program written in a certain language as the input and produces an equivalent program as the output. Usually, the input language may be C + + or C + +. The equivalent target program is usually the instruction set of a certain processor, and then the target program can be run directly. The difference between interpreter and compiler is that it directly executes the code written by programming language or script, does not precompile the source code into instruction set, and it will return the results in real time. As shown in the figure below
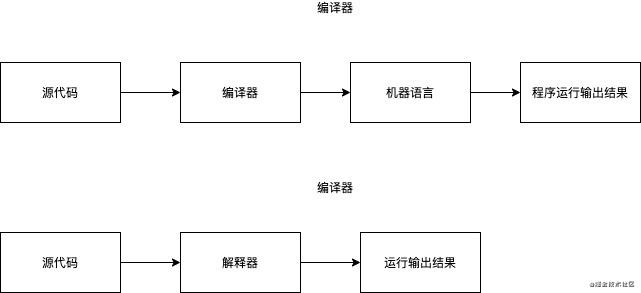
There is also a compiler that translates one high-level language into another, such as converting php to C + +. This compiler is generally called source to source converter.
target
The goal of this blog series is actually very small. It is to use Kotlin to realize a small interpreter to carry out four operations of positive numbers. Because I am also in the learning stage, I can only get such a small function first, and then open a new one when the technology is improved. This series will only involve the concepts related to the front end of the compiler, such as lexical analysis, syntax analysis and abstract syntax tree, but not the code optimization and code generation related to the back end of the compiler.
lexical analysis
The task of lexical analysis is to change the character flow into the word flow of the input language. Each word must be classified into a grammatical category, also known as part of speech. Lexical analyzer is the only one-time processing in the compiler that touches every character in the program. Here are some concepts to explain. For example, parts of speech. Liebi's usual language, we will say that "walking" is a verb, "running" is also a verb, "beautiful" is an adjective, "beautiful" is also an adjective. Here, verbs and adjectives are parts of speech, representing the classification of words. Another is morpheme, which is "walking" and "running", "Beautiful "Wait" is actually morpheme, that is, the specific word content, the actual text. The function of lexical analysis is to read the files in the source code according to the characters, and recognize the words according to the read characters to form a lexical unit. Each lexical unit is composed of the name of the lexical unit and the morpheme, such as < adjective: beautiful >, in which the adjective is the name of the lexical unit, which can be regarded as and part of speech Similarly, beauty is morpheme, and for the calculator we want to implement, it may be < plus, + >, < number, 9 >.
code
Defining lexical units
As mentioned earlier, lexical unit is composed of lexical unit name and morpheme, so we define a Token class to represent lexical unit, and TokenType enumeration class to represent lexical unit name
data class Token(val tokenType: TokenType, val value: String) {
override fun toString(): String {
return "Token(tokenType=${this.tokenType.value}, value= ${this.value})"
}
}
enum class TokenType(val value: String) {
NUMBER("NUMBEER"), PLUS("+"), MIN("-"), MUL("*"), DIV("/"), LBRACKETS("("), RBRACKETS(")"), EOF("EOF")
}
You can see that I have 8 tokentypes. 8 tokentypes represent 8 lexical unit names, that is, 8 parts of speech. EOF represents END OF FILE and the end of source file scanning.
Define lexical analyzer
import java.lang.RuntimeException
class Lexer(private val text: String) {
private var nextPos = 0
private val tokenMap = mutableMapOf<String, TokenType>()
private var nextChar: Char? = null
init {
TokenType.values().forEach {
if(it!=TokenType.NUMBER) {
tokenMap[it.value] = it
}
}
nextChar = text.getOrNull(nextPos)
}
fun getNextToken(): Token {
loop@ while (nextChar != null) {
when (nextChar) {
in '0'..'9' -> {
return Token(TokenType.NUMBER, getNumber())
}
' ' -> {
skipWhiteSpace()
continue@loop
}
}
if (tokenMap.containsKey(nextChar.toString())) {
val tokenType = tokenMap[nextChar.toString()]
if (tokenType != null) {
val token = Token(tokenType, tokenType.value)
advance()
return token
}
}
throw RuntimeException("Error parsing input")
}
return Token(TokenType.EOF, TokenType.EOF.value)
}
private fun getNumber(): String {
var item = ""
while (nextChar != null && nextChar!! in '0'..'9') {
item += nextChar
advance()
if ('.' == nextChar) {
item += nextChar
advance()
while (nextChar != null && nextChar!! in '0'..'9') {
item += nextChar
advance()
}
}
}
return item
}
private fun skipWhiteSpace() {
var nextChar = text.getOrNull(nextPos)
while (nextChar != null && ' ' == nextChar) {
advance()
nextChar = text.getOrNull(nextPos)
}
}
private fun advance() {
nextPos++
nextChar = if (nextPos > text.length - 1) {
null
} else {
text.getOrNull(nextPos)
}
}
}
Let's first look at the member variables, where text represents the content of the source file, nextPos represents the position of the next character in the source code, nextChar represents the next character in the source code, tokenMap represents morpheme and lexical unit, which are the only corresponding Map, where key represents morpheme and TokenType represents lexical unit. We can see that in our definition, except TokenType NUMBER and others have unique correspondence, because for numbers, 9 corresponds to the lexical unit NUMBER, and 10 corresponds to the lexical unit NUMBER. There is no unique correspondence, so we need to identify it separately.
The construction method is very simple. Calculate the assignment for tokenMap and nextChar
Look at the rest of the methods. In fact, only the getNextToken method exposed by the lexical parser is used to return the Token. Other methods are private to assist in returning the Token. In the getNextToken method, there is a while loop to judge whether the nextChar is null. If NULL, it means that the source file has been processed and returns the Token(TokenType.EOF, TokenType.EOF.value), Otherwise, judge whether the current character is a number. If it is a number, return Token(TokenType.NUMBER, getNumber()), where the getNumber method is used to obtain the digital content until nextChar is no longer a number. If nextChar is a space, skip the space skipWhiteSpce, and then continue the current cycle. If it is neither a number nor a space, get the corresponding TokenType according to tokenMap to see if it is an operation symbol or bracket. If it does not exist, it indicates that there are non number, four operation symbols and bracket characters in the input, and throw the error "Error parsing input".
test
import java.util.*
fun main() {
while(true) {
val scanner = Scanner(System.`in`)
val text = scanner.nextLine()
val lexer = Lexer(text)
var nextToken = lexer.getNextToken()
while (TokenType.EOF != nextToken.tokenType) {
println(nextToken.toString())
nextToken = lexer.getNextToken()
}
}
}
Write the test code, print the corresponding token, run the code, enter the data in the code and press enter to view the results

So far, the lexical analyzer has been basically completed. In fact, the lexical analyzer still has many concepts, such as regular expression, and then the regular expression generates NFA. NFA uses the least subset method to generate DFA, and then the DFA generates the minimum DFA. There are many concepts, but I think too many concepts will confuse people. It's better to start with simple examples and gradually deepen understanding, Familiar with concepts
The code has been uploaded to github and will be updated in the future CompilerDemo
Welcome to my official account: "old arsenic on skateboards".