Kubernetes Advanced Node Auto Expansion/Scaling
Catalog: 1. Cluster AutoScaler cloud vendor expansion/scaling 2. Ansible one-click auto-expanding Node
1,Cluster AutoScaler
Extension: Cluster AutoScaler periodically detects whether there are sufficient resources to schedule the newly created Pod and calls Cloud Provider to create a new Node when resources are low.
Workflow: Periodically check if there are enough resources in the cluster, if the cluster resource is not enough pod will appear pending state, will wait for the resources to be ready, if no new resources are released, it will wait all the time, deployed services will not provide services, autoscaler will detect the utilization of a resource, is there capitalA shortage of sources, if present, calls cloud provider to create a new node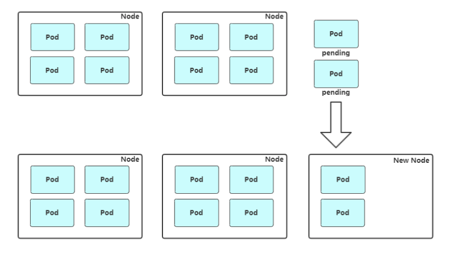
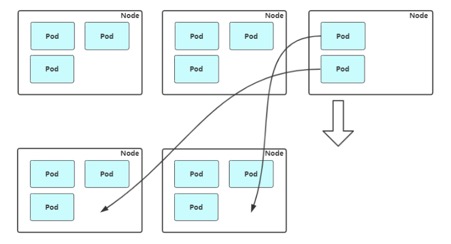
Compact: Cluster AutoScaler also regularly monitors Node's resource usage. When a Node has a low long-term resource utilization (less than 50%), resources with low long-term resource utilization go offline to make judgments and automatically remove their virtual machines from the cloud service provider.In this case, the pod above will be expelled and dispatched to other nodes to provide services.
Supported cloud providers:
If you use their cloud vendors, you can use their components to solve problems, and generally they are docked.
* Ali Yun: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
• AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
• Azure: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
Summary:
The main problem that elastic scaling solves is the contradiction between capacity planning and actual load. That is, in my batch of machines, the load is too high, so can the batch of servers expand quickly? This is mainly to solve such a problem, the test is fast expansion and scaling.
It's the traditional flexibility that scales into k8s, so think carefully about two problems you'll encounter
1. Inconsistent machine specifications cause fragmentation of machine utilization percentage
In k8s cluster, not all machines are the same, and we do not need to be the same. In fact, k8s has helped us manage resources well. These CPUs and memory will be placed in the resource pool as a whole to schedule. For scaling and expansion cases, especially when scaling, machine specifications are not uniform, and some machines with small specifications may be scaled when scaling, so it is very good.Maybe you do not have much effect after scaling. Maybe your big machine has not been scaled yet, so your effect is not very obvious. If a large machine scales, it may make you compete for resources. Maybe your resources are not very redundant.
2. Machine utilization is not solely dependent on host computing
When you plan for a server's resources before you make a container, memory and CPU applications are complete. It's also easier to do some scaling and expansion in that case. For example, expand your server to see if its resources reach 80%, 90%, and then apply for a new machine. The same is true for scaling. Check that the overall resource utilization of the idle resources is low.It is still easy to reduce a few, but in the k8s scenario, in fact, some of the applications we deployed above do not need to pay much attention to the resources at the bottom of the server, do not care about the configuration utilization rate of my machine, it is concerned about the resources I requested, can you give me enough applications I deployed, capacity planning in k8s is based on request and limit valuesRequest is actually a quota in k8s. You deploy an application and the requested resources are defined by request. So there is an extra dimension in k8s, request and host resource utilization. So you should take this into account when scaling out, that is, you can't allocate according to your current node, because you are applying to deploy this requestQuota It can't be said to be removed even if it's not used, so consider the overall resource utilization of the overall request and maintain some redundancy over that resource utilization.
2.2 Ansible Expansion Node
The third is our manual intervention to expand the capacity, which is a common means of self-building.
1. Trigger the addition of Node, knowing whether to add a node or not. 2. Call the Ansible script to deploy components, how to prepare this node, whether the new machine is ready, whether these components are deployed. 3. Check that the service is available and that newly added components are normal 4. Call the API to join the new Node to the cluster or enable Node auto-join 5. Observe the status of the new Node, monitor it, view the new node, run the log, resource status. 6. Complete Node expansion and receive new Pod s
Analog expanded node, unable to allocate due to too many resources, appears pending
[root@k8s-master1 ~]# kubectl run web --image=nginx --replicas=6 --requests="cpu=1,memory=256Mi" [root@k8s-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE web-944cddf48-6qhcl 1/1 Running 0 15m web-944cddf48-7ldsv 1/1 Running 0 15m web-944cddf48-7nv9p 0/1 Pending 0 2s web-944cddf48-b299n 1/1 Running 0 15m web-944cddf48-nsxgg 0/1 Pending 0 15m web-944cddf48-pl4zt 1/1 Running 0 15m web-944cddf48-t8fqt 1/1 Running 0 15m
The current state is that pod cannot allocate resources to the current node due to insufficient pools, so now we need to expand our node
[newnode] 10.4.7.22 node_name=k8s-node3 [root@ansible ansible-install-k8s-master]# ansible-playbook -i hosts add-node.yml -uroot -k
View that a request to join the node has been received and run through
[root@k8s-master1 ~]# kubectl get csr NAME AGE REQUESTOR CONDITION node-csr-0i7BzFaf8NyG_cdx_hqDmWg8nd4FHQOqIxKa45x3BJU 45m kubelet-bootstrap Approved,Issued
View node status
[root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready <none> 7d v1.16.0 k8s-node1 Ready <none> 7d v1.16.0 k8s-node2 Ready <none> 7d v1.16.0 k8s-node3 Ready <none> 2m52s v1.16.0
View the overall utilization rate of resource status assignments
[root@k8s-master1 ~]# kubectl describe node k8s-node1
Shrink Node
In a condensed form, the expulsion of pod s on this node may have some impact on both business and cluster
If you want to remove a node from the kubernetes cluster, the correct process 1. Get a list of nodes Kubectl get node 2. Set non-dispatchable Kubectl cordon $node_name 3. Expulsion node top pod Kubectl drain $node_name –I gnore-daemonsets 4. Remove Nodes There are no more resources on this node, so you can remove it directly: Kubectl delete node $node_node In this way, we smoothly remove a k8s node
First of all, we need to know which node of the whole cluster is to be deleted. If this manual intervention is to determine which node is worth retracting, it must be the node with the lowest resource utilization and the most priority retracting.
Then set it to be non-dispatchable, because there is always the possibility that a new pod will be dispatched to prevent a new pod from dispatching, which has a kubectl-help related command
cordon sign node by unschedulable [root@k8s-master1 ~]# kubectl cordon k8s-node3 node/k8s-node3 cordoned
Mark the non-dispatchable node here
[root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready <none> 7d1h v1.16.0 k8s-node1 Ready <none> 7d1h v1.16.0 k8s-node2 Ready <none> 7d1h v1.16.0 k8s-node3 Ready,SchedulingDisabled <none> 45m v1.16.0
Now this stage will have no effect on the pod of the existing stage
Now expel pod s that already exist on the node, so now set a maintenance period for this node and this command
drain Drain node in preparation for maintenance
If this state is set, it will expel the pod on this node and give you a hint that this node is no longer in a dispatchable state. Now the expulsion is in progress. There is a wrong daemonset pod reported here, because we deployed flanneld to start with daemonset, so this happens, this can be ignored directly
[root@k8s-master1 ~]# kubectl drain k8s-node3 node/k8s-node3 already cordoned error: unable to drain node "k8s-node3", aborting command... There are pending nodes to be drained: k8s-node3 error: cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): ingress-nginx/nginx-ingress-controller-qxhj7, kube-system/kube-flannel-ds-amd64-j9w5l
This followed command
[root@k8s-master1 ~]# kubectl drain k8s-node3 --ignore-daemonsets node/k8s-node3 already cordoned WARNING: ignoring DaemonSet-managed Pods: ingress-nginx/nginx-ingress-controller-qxhj7, kube-system/kube-flannel-ds-amd64-j9w5l evicting pod "web-944cddf48-nsxgg" evicting pod "web-944cddf48-7nv9p" pod/web-944cddf48-nsxgg evicted pod/web-944cddf48-7nv9p evicted node/k8s-node3 evicted [root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready <none> 7d1h v1.16.0 k8s-node1 Ready <none> 7d1h v1.16.0 k8s-node2 Ready <none> 7d1h v1.16.0 k8s-node3 Ready,SchedulingDisabled <none> 53m v1.16.0 [root@k8s-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE web-944cddf48-6qhcl 1/1 Running 0 127m web-944cddf48-7ldsv 1/1 Running 0 127m web-944cddf48-b299n 1/1 Running 0 127m web-944cddf48-cc6n5 0/1 Pending 0 38s web-944cddf48-pl4zt 1/1 Running 0 127m web-944cddf48-t8fqt 1/1 Running 0 127m web-944cddf48-vl5hg 0/1 Pending 0 38s [root@k8s-master1 ~]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-944cddf48-6qhcl 1/1 Running 0 127m 10.244.0.6 k8s-node2 <none> <none> web-944cddf48-7ldsv 1/1 Running 0 127m 10.244.0.5 k8s-node2 <none> <none> web-944cddf48-b299n 1/1 Running 0 127m 10.244.0.7 k8s-node2 <none> <none> web-944cddf48-cc6n5 0/1 Pending 0 43s <none> <none> <none> <none> web-944cddf48-pl4zt 1/1 Running 0 127m 10.244.2.2 k8s-master1 <none> <none> web-944cddf48-t8fqt 1/1 Running 0 127m 10.244.1.2 k8s-node1 <none> <none> web-944cddf48-vl5hg 0/1 Pending 0 43s <none> <none> <none> <none>
Now the scaling is complete, because my resources are tight, there is a pending state, so this is the scaling. After scaling, or the controller to ensure the number of copies of the pod, this is the current you want to ensure the redundancy of one other node, so that the scaling is meaningful, otherwise the pending state will certainly not work.
Then delete the k8s-node3 node
[root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready <none> 7d2h v1.16.0 k8s-node1 Ready <none> 7d2h v1.16.0 k8s-node2 Ready <none> 7d2h v1.16.0 k8s-node3 Ready,SchedulingDisabled <none> 71m v1.16.0
Removing nodes, when the deportation is completed, also ensure that other nodes have expected copies, and do a good job of certain strategies, can not do pod scheduling during the offline period.
Or shut down node3. First of all, make sure that the resources of other nodes are redundant. Even in other situations, k8s has a mechanism to float the pod on the failed node node to other normal node nodes within 5 minutes. Like microservices, when we go to expulsion, our business will also receive some impact, after all, weNodes on this node need to be expelled and moved to other nodes, so try to do this during peak business hours.
[root@k8s-master1 ~]# kubectl delete node k8s-node3 node "k8s-node3" deleted [root@k8s-master1 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready <none> 7d2h v1.16.0 k8s-node1 Ready <none> 7d2h v1.16.0 k8s-node2 Ready <none> 7d2h v1.16.0