First, environmental preparation
* K8S version 15.1
* Docker version supports up to 18.06.1
Second, Docker Environment Construction and Replacement
1. Clear the original Docker environment, the original version is the latest version
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
rm -rf /etc/systemd/system/docker.service.d
rm -rf /var/lib/docker
rm -rf /var/run/docker
2. If the package collision error remains after clearance
file /usr/share/man/man1/docker-manifest-annotate.1.gz from install of docker-ce-18.06.1.ce-3.el7.x86_64 conflicts with file from package docker-ce-cli-1:18.09.6-3.el7.x86_64
Manual removal of conflict packages via the yum command
yum erase docker-common-2:1.12.6-68.gitec8512b.el7.centos.x86_64
3. Install 18.06.1 version of Docker
yum install -y docker-ce-18.06.1.ce-3.el7
4. Blogs before other Docker installation references Docker: Environment Building
Third, Kubernetes Cluster Environment Construction
1. Basic environmental preparation
a. Machine node preparation, virtual machine building, insufficient memory, host name only supports [-.] two special symbols
| Node Host | Node IP | Node role | operating system | Node Configuration |
|---|---|---|---|---|
| master | 192.168.91.136 | master | CentOS07 | 2C2G |
| node1 | 192.168.91.137 | node | CentOS07 | 2C2G |
| node2 | 192.168.91.138 | node | CentOS07 | 2C2G |
b, / etc/hosts file settings
* Add commands
cat >> /etc/hosts << EOF 192.168.91.136 master 192.168.91.137 node1 192.168.91.138 node2 EOF
* The hosts file is configured as follows

(c) Configure time synchronization, use chrony synchronization time, configure master node and network NTP server synchronization time, all node and master node synchronization time
* Configuring Master Nodes
// Install chrony: yum install -y chrony // Annotate the default ntp server sed -i 's/^server/#&/' /etc/chrony.conf // Specify upstream public ntp server and allow other nodes to synchronize time cat >> /etc/chrony.conf << EOF server 0.asia.pool.ntp.org iburst server 1.asia.pool.ntp.org iburst server 2.asia.pool.ntp.org iburst server 3.asia.pool.ntp.org iburst allow all EOF // Restart the chronyd service and set it to boot: systemctl enable chronyd && systemctl restart chronyd // Open Network Time Synchronization Function timedatectl set-ntp true
* Configuring Node Nodes
// Install chrony: yum install -y chrony // Annotation Default Server sed -i 's/^server/#&/' /etc/chrony.conf // Specify the intranet master node as the upstream NTP server echo server 192.168.91.128 iburst >> /etc/chrony.conf // Restart the service and set it to boot up: systemctl enable chronyd && systemctl restart chronyd
* All nodes execute the chronyc sources command to see the existence of lines starting with ^* indicating that they are synchronized with the server time


d. Some users who set up bridge packages over iptalbes RHEL/CentOS 7 reported that traffic routing was incorrect due to iptables being bypassed. Create the / etc/sysctl.d/k8s.conf file and add the following
// Add File Content cat <<EOF > /etc/sysctl.d/k8s.conf vm.swappiness = 0 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF // Make configuration effective modprobe br_netfilter sysctl -p /etc/sysctl.d/k8s.conf
e. The prerequisite for kube-proxy to open ipvs. Since IPVS have been added to the backbone of the kernel, the prerequisite for opening IPVS for kube-proxy requires loading the following kernel modules: execute the following scripts on all Kubernetes nodes
// Adding content cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF // Execution script chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
f. The above script creates the file / etc/sysconfig/modules/ipvs.modules to ensure that the required modules can be loaded automatically after the node restarts. Use the lsmod | grep-e ip_vs-e nf_conntrack_ipv4 command to see if the required kernel modules have been loaded correctly. Next, you need to make sure that the ipset package is installed on each node. In order to view the proxy rules of ipvs, it is better to install the management tool ipvsadm.
yum install ipset ipvsadm -y
g. Install kubeadm, kubelet, kubectl
// To configure the source of kubernetes.repo, because the official source can not be accessed in China, the source of Ali yum is used here. cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF // Install the specified versions of kubelet, kubeadm, and kubectl on all nodes // Download version 1.15.1 directly here yum install -y kubelet kubeadm kubectl // Start the kubelet service systemctl enable kubelet && systemctl start kubelet
2. Master Environment Construction
(a) Reset the node after the installation is scrapped
kubeadm reset
b. Initialize the Master node, pay attention to changes to address and version, version is the same as kubeadm and other versions.
kubeadm init \
--apiserver-advertise-address=192.168.91.136 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.15.1 \
--pod-network-cidr=10.244.0.0/16* apiserver-advertise-address: specifies which interface of Master communicates with other nodes of Cluster. If Master has multiple interfaces, it is recommended to specify explicitly. If not, kubeadm automatically selects interfaces with default gateways.
* pod-network-cidr: Specifies the scope of the Pod network. Kubernetes supports a variety of network schemes, and different network schemes have their own requirements for pod-network-cidr, which is set to 10.244.0.0/16 because we will use flannel network scheme and must be set to this CIDR.
* image-repository: Kubenets default Registries address is k8s.gcr.io It can't be visited at home. gcr.io In version 1.15, we can add the image-repository parameter with the default value of ___________. k8s.gcr.io To designate it as the Ali Cloud Mirror Address: registry.aliyuncs.com/google_containers.
* kubernetes-version=v1.15.1: Turn off version detection because its default value is stable-1, which results in the following https://dl.k8s.io/release/stable-1.txt downloads the latest version number, which we can designate as a fixed version (latest version: v1.13.1) to skip network requests.
c. Initialization process and description
[root@master ~]# kubeadm init --apiserver-advertise-address=192.168.91.136 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.15.1 --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.15.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [master localhost] and IPs [192.168.91.136 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [master localhost] and IPs [192.168.91.136 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.91.136]
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 25.517374 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.15" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: qozff5.j2weqyh2uhcz4l7f
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.91.136:6443 --token qozff5.j2weqyh2uhcz4l7f \
--discovery-token-ca-cert-hash sha256:f427679e26a28dec67138e2806c4ec2c03827665dd1233b11e7f60cb3c260b60 * [preflight] kubeadm performs pre-initialization checks
* [kubelet-start] generates the configuration file for kubelet"/ var/lib/kubelet/config.yaml"
* [certificates] generate various token s and certificates
* [certificates] generate various token s and certificates
* [kubeconfig] generates a KubeConfig file that kubelet needs to communicate with Master
* [control-plane] Installs the Master component and downloads the Docker image of the component from the specified Registry.
* [bootstraptoken] generates token records, which are then used when adding nodes to the cluster using kubeadm join
* [addons] install additional components kube-proxy and kube-dns.
* Kubernetes Master initialization was successful, prompting how to configure regular users to access the cluster using kubectl.
* Tips on how to install the Pod network.
* Tips on how to register other nodes to Cluster.
* The join command must remember that you need to add node nodes using the token corresponding to the join later.
d. Configuring kubectl: kubectl is a command-line tool for managing Kubernetes Cluster. We have installed kubectl on all the nodes before. When Master initialization is complete, some configuration work is needed, and then kubectl can be used. The reason for these configuration commands is that the Kubernetes cluster by default requires encrypted access. Therefore, these commands are to save the newly deployed security configuration file of the Kubernetes cluster to the. kube directory of the current user. By default, kubectl will access the Kubernetes cluster using the authorization information in this directory. If we don't, we need to tell kubectl the location of the security profile every time through the export KUBECONFIG environment variable. Once the configuration is complete, centos users can use the kubectl command to manage the cluster. (This demo runs directly on the root account)
// Add sudo permissions and configure sudo confidentiality sed -i '/^root/a\centos ALL=(ALL) NOPASSWD:ALL' /etc/sudoers // Save the cluster security profile to the current user. kube directory mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config // Enable automatic completion of the kubectl command (logout and re-entry takes effect) echo "source <(kubectl completion bash)" >> ~/.bashrc
e. After configuring the Master node, look at the cluster state and make sure that each component is in a health state
kubectl get cs

f. Check the node status after confirming that the components are in health state
kubectl get nodes

g. There is only one Master node and the node is in the NotReady state. Use the kubectl description command to view the details, status, and events of the Node object
kubectl describe node master

h. From the output of the kubectl description instruction, we can see that the reason for NodeNotReady is that we have not deployed any network plug-ins yet, and components such as kube-proxy are still in starting state. In addition, we can also check the status of each system Pod on this node through kubectl, where kube-system is the system Pod workspace reserved by Kubernetes project (Namepsace, note that it is not Linux Namespace, it is only the unit of Kubernetes dividing different workspaces). As you can see, CoreDN S-dependent network Pods are in Pending state, i.e. scheduling failure. This certainly fits expectations: because the Master node's network is not yet ready
kubectl get pod -n kube-system -o wide

i. Deployment of network plug-ins. To make Kubernetes Cluster work, you must install a Pod network, otherwise Pod cannot communicate with each other. Kubernetes supports a variety of network solutions. Here we use flannel to execute the following commands to deploy flannel: kubectl apply-f kube-flannel.yml
* Upload the kube-flannel.yml file as follows
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-amd64
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: amd64
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.10.0-amd64
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-arm64
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: arm64
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.10.0-arm64
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-arm64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-arm
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: arm
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.10.0-arm
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-arm
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-ppc64le
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: ppc64le
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.10.0-ppc64le
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-ppc64le
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-s390x
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: s390x
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.10.0-s390x
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-s390x
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
* Executive Document
kubectl apply -f kube-flannel.yml
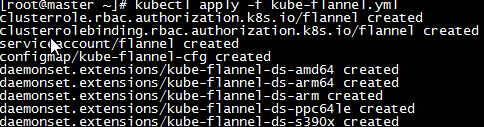
j. After installing the flannel network plug-in successfully, review the POD status again. The circled part may have a transient init state, just wait a minute.

* If the Pod state is Pending, Container Creating, ImagePullBackOff, all indicate that the Pod is not ready, Running is ready. If the Pod state is abnormal, you can pull the abnormal information by command.
// kube-flannel-ds-amd64-d2r8p denotes the name of pod kubectl describe pod kube-flannel-ds-amd64-d2r8p --namespace=kube-system
k. Revisit the status of the node. The status of the node is changed from notReady to ready. The Master node is deployed. By default, the Master node of Kubernetes cannot run user Pod.

3. Construction of Worker Environment
a, the join statement prompted when init is executed, showing the following information indicating that the addition was successful
kubeadm join 192.168.91.136:6443 --token qozff5.j2weqyh2uhcz4l7f \
--discovery-token-ca-cert-hash sha256:f427679e26a28dec67138e2806c4ec2c03827665dd1233b11e7f60cb3c260b60 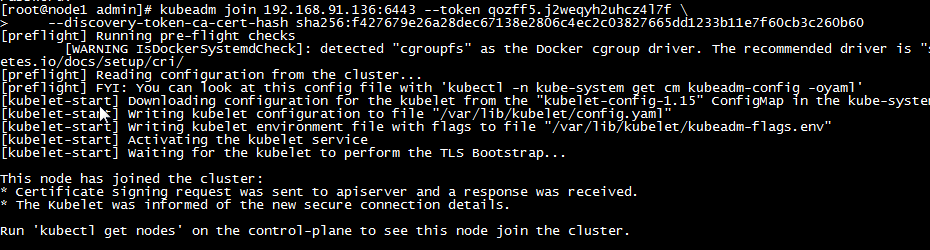
b. If you forget to remember the join information, you can regenerate it by statement
kubeadm token create --print-join-command
c. Repeat the previous step to add the node 2 node. After adding the node, view the node and pod in the master node. If there is a NotReady node, you can wait a moment, wait until all pods are started, or check the status of pods, for a specific analysis of pods that are not Running status! (Pod status Pending, Container Creating, ImagePullBackOff all indicate that Pod is not ready)
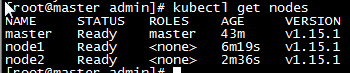

d. So far, the cluster has been completed.