6. Detailed explanation of pod controller
6.1 introduction to pod controller
Pod is the smallest management unit of kubernetes. In kubernetes, it can be divided into two categories according to the creation method of Pod:
- Autonomous Pod: a pod directly created by kubernetes. This kind of pod will not exist and will not be rebuilt after deletion
- Pod created by the controller: the pod created by kubernetes through the controller. After this pod is deleted, it will be rebuilt automatically
What is a Pod controller
The pod controller is the middle layer for managing pods. After using the pod controller, you only need to tell the pod controller how many and what kind of pods you want. It will create qualified pods and ensure that each pod resource is in the desired target state. If the pod resource fails during operation, it rearranges the pod based on the specified policy.
In kubernetes, there are many types of pod controllers, each of which has its own suitable scenario. The common ones are as follows:
- ReplicationController: compared with the original pod controller, it has been abandoned and replaced by ReplicaSet
- ReplicaSet: ensure that the number of replicas is always maintained at the expected value, and support the expansion and contraction of pod number and image version upgrade
- Deployment: controls Pod by controlling ReplicaSet, and supports rolling upgrade and rollback version
- Horizontal Pod Autoscaler: the number of pods can be automatically adjusted according to the cluster load level to realize peak shaving and valley filling
- Daemon set: runs on the specified Node in the cluster and only runs one copy. It is generally used for the tasks of the daemon class
- Job: the created pod will exit as soon as the task is completed. It does not need to restart or rebuild. It is used to perform one-time tasks
- Cronjob: the Pod it creates is responsible for periodic task control and does not need to run continuously in the background
- Stateful set: manage stateful applications
6.2 ReplicaSet(RS)
The main function of ReplicaSet is to ensure the normal operation of a certain number of pods. It will continuously monitor the operation status of these pods. Once the pod fails, it will restart or rebuild. At the same time, it also supports the expansion and contraction of the number of pods and the upgrading and upgrading of the image version.
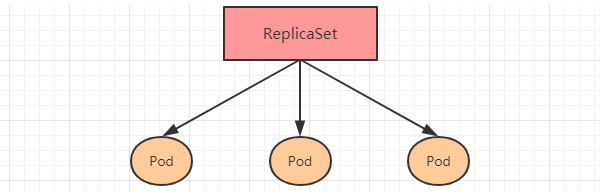
Resource manifest file for ReplicaSet:
apiVersion: apps/v1 # Version number
kind: ReplicaSet # type
metadata: # metadata
name: # rs name
namespace: # Namespace
labels: #label
controller: rs
spec: # Detailed description
replicas: 3 # Number of copies
selector: # Selector, which specifies which pod s the controller manages
matchLabels: # Labels matching rule
app: nginx-pod
matchExpressions: # Expressions matching rule
- {key: app, operator: In, values: [nginx-pod]}
template: # Template. When the number of copies is insufficient, a pod copy will be created according to the following template
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
Here, the configuration items that need to be newly understood are the following options of spec:
-
Replicas: Specifies the number of replicas, which is actually the number of pod s created by the current rs. the default value is 1
-
Selector: selector, which is used to establish the association relationship between pod controller and pod, and adopts the Label Selector mechanism
Define a label on the pod template and a selector on the controller to indicate which pods the current controller can manage
-
Template: template is the template used by the current controller to create a pod. In fact, it is the definition of pod learned in the previous chapter
Create ReplicaSet
Create a pc-replicaset.yaml file as follows:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: pc-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# Create rs [root@k8s-master01 ~]# kubectl create -f pc-replicaset.yaml replicaset.apps/pc-replicaset created # View rs # Specified: expected number of replicas # CURRENT: CURRENT copy quantity # READY: number of copies READY for service [root@k8s-master01 ~]# kubectl get rs pc-replicaset -n dev -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR pc-replicaset 3 3 3 22s nginx nginx:1.17.1 app=nginx-pod # View the pod created by the current controller # It is found that the name of the pod created by the controller is spliced with - xxxxx random code after the controller name [root@k8s-master01 ~]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-replicaset-6vmvt 1/1 Running 0 54s pc-replicaset-fmb8f 1/1 Running 0 54s pc-replicaset-snrk2 1/1 Running 0 54s
Expansion and contraction capacity
# Edit the number of copies of rs and modify spec:replicas: 6 [root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev replicaset.apps/pc-replicaset edited # View pod [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-replicaset-6vmvt 1/1 Running 0 114m pc-replicaset-cftnp 1/1 Running 0 10s pc-replicaset-fjlm6 1/1 Running 0 10s pc-replicaset-fmb8f 1/1 Running 0 114m pc-replicaset-s2whj 1/1 Running 0 10s pc-replicaset-snrk2 1/1 Running 0 114m # Of course, you can also use commands directly # Use the scale command to expand or shrink the capacity, and then -- replicas=n directly specify the target quantity [root@k8s-master01 ~]# kubectl scale rs pc-replicaset --replicas=2 -n dev replicaset.apps/pc-replicaset scaled # After the command is run, check it immediately and find that there are 4 ready to exit [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-replicaset-6vmvt 0/1 Terminating 0 118m pc-replicaset-cftnp 0/1 Terminating 0 4m17s pc-replicaset-fjlm6 0/1 Terminating 0 4m17s pc-replicaset-fmb8f 1/1 Running 0 118m pc-replicaset-s2whj 0/1 Terminating 0 4m17s pc-replicaset-snrk2 1/1 Running 0 118m #Wait a moment, there are only two left [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-replicaset-fmb8f 1/1 Running 0 119m pc-replicaset-snrk2 1/1 Running 0 119m
Image upgrade
# Edit container image of rs - image: nginx:1.17.2 [root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev replicaset.apps/pc-replicaset edited # Check again and find that the image version has changed [root@k8s-master01 ~]# kubectl get rs -n dev -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ... pc-replicaset 2 2 2 140m nginx nginx:1.17.2 ... # In the same way, you can use commands to do this # Kubectl set image RS name container = mirror version - n namespace [root@k8s-master01 ~]# kubectl set image rs pc-replicaset nginx=nginx:1.17.1 -n dev replicaset.apps/pc-replicaset image updated # Check again and find that the image version has changed [root@k8s-master01 ~]# kubectl get rs -n dev -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ... pc-replicaset 2 2 2 145m nginx nginx:1.17.1 ...
Delete ReplicaSet
# Using the kubectl delete command deletes this RS and the Pod it manages # Before kubernetes deletes RS, the replicasclear of RS will be adjusted to 0. After all pods are deleted, delete RS objects [root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev replicaset.apps "pc-replicaset" deleted [root@k8s-master01 ~]# kubectl get pod -n dev -o wide No resources found in dev namespace. # If you want to delete only RS objects (keep Pod), you can add -- cascade=false option when using kubectl delete command (not recommended). [root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev --cascade=false replicaset.apps "pc-replicaset" deleted [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-replicaset-cl82j 1/1 Running 0 75s pc-replicaset-dslhb 1/1 Running 0 75s # You can also use yaml to delete directly (recommended) [root@k8s-master01 ~]# kubectl delete -f pc-replicaset.yaml replicaset.apps "pc-replicaset" deleted
6.3 Deployment(Deploy)
In order to better solve the problem of service orchestration, kubernetes introduced the Deployment controller in V1.2. It is worth mentioning that this controller does not directly manage pod, but introduces the management of pod by managing ReplicaSet, that is, Deployment manages ReplicaSet and ReplicaSet manages pod. Therefore, Deployment is more powerful than ReplicaSet.
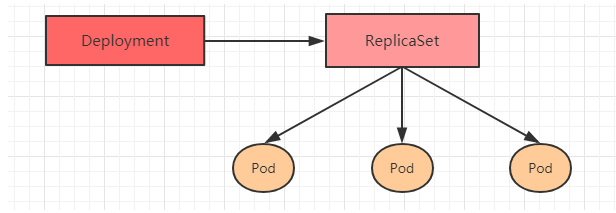
The main functions of Deployment are as follows:
- All features of ReplicaSet are supported
- Support the stop and continue of publishing
- Support rolling upgrade and rollback version
Resource manifest file for Deployment:
apiVersion: apps/v1 # Version number
kind: Deployment # type
metadata: # metadata
name: # rs name
namespace: # Namespace
labels: #label
controller: deploy
spec: # Detailed description
replicas: 3 # Number of copies
revisionHistoryLimit: 3 # Keep historical version
paused: false # Pause deployment. The default value is false
progressDeadlineSeconds: 600 # Deployment timeout (s). The default is 600
strategy: # strategy
type: RollingUpdate # Rolling update strategy
rollingUpdate: # Rolling update
maxSurge: 30% # The maximum number of copies that can exist, either as a percentage or as an integer
maxUnavailable: 30% # The maximum value of the Pod in the maximum unavailable state, which can be either a percentage or an integer
selector: # Selector, which specifies which pod s the controller manages
matchLabels: # Labels matching rule
app: nginx-pod
matchExpressions: # Expressions matching rule
- {key: app, operator: In, values: [nginx-pod]}
template: # Template. When the number of copies is insufficient, a pod copy will be created according to the following template
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
6.3.1 create deployment
Create pc-deployment.yaml as follows:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# Create deployment [root@k8s-master01 ~]# kubectl create -f pc-deployment.yaml --record=true deployment.apps/pc-deployment created # View deployment # UP-TO-DATE number of pod s of the latest version # AVAILABLE the number of currently AVAILABLE pod s [root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev NAME READY UP-TO-DATE AVAILABLE AGE pc-deployment 3/3 3 3 15s # View rs # It is found that the name of rs is a 10 digit random string added after the name of the original deployment [root@k8s-master01 ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-6696798b78 3 3 3 23s # View pod [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-deployment-6696798b78-d2c8n 1/1 Running 0 107s pc-deployment-6696798b78-smpvp 1/1 Running 0 107s pc-deployment-6696798b78-wvjd8 1/1 Running 0 107s
6.3.2 expansion and contraction capacity
# The number of changed copies is 5 [root@k8s-master01 ~]# kubectl scale deploy pc-deployment --replicas=5 -n dev deployment.apps/pc-deployment scaled # View deployment [root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev NAME READY UP-TO-DATE AVAILABLE AGE pc-deployment 5/5 5 5 2m # View pod [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-deployment-6696798b78-d2c8n 1/1 Running 0 4m19s pc-deployment-6696798b78-jxmdq 1/1 Running 0 94s pc-deployment-6696798b78-mktqv 1/1 Running 0 93s pc-deployment-6696798b78-smpvp 1/1 Running 0 4m19s pc-deployment-6696798b78-wvjd8 1/1 Running 0 4m19s # Edit the number of copies of deployment and modify spec:replicas: 4 [root@k8s-master01 ~]# kubectl edit deploy pc-deployment -n dev deployment.apps/pc-deployment edited # View pod [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-deployment-6696798b78-d2c8n 1/1 Running 0 5m23s pc-deployment-6696798b78-jxmdq 1/1 Running 0 2m38s pc-deployment-6696798b78-smpvp 1/1 Running 0 5m23s pc-deployment-6696798b78-wvjd8 1/1 Running 0 5m23s
Mirror update
deployment supports two update strategies: rebuild update and rolling update. You can specify the policy type through strategy and support two attributes:
strategy: Specify a new Pod Replace old Pod The policy supports two properties:
type: Specify the policy type and support two policies
Recreate: Create a new Pod We'll kill all the existing before Pod
RollingUpdate: Rolling update is to kill a part and start a part. During the update process, there are two versions Pod
rollingUpdate: When type by RollingUpdate Effective when used for RollingUpdate Setting parameters supports two properties:
maxUnavailable: Used to specify not available during upgrade Pod The maximum quantity of is 25 by default%.
maxSurge: Used to specify that you can exceed expectations during the upgrade process Pod The maximum quantity of is 25 by default%.
Rebuild update
- Edit pc-deployment.yaml and add an update policy under the spec node
spec:
strategy: # strategy
type: Recreate # Rebuild update
- Create deploy for validation
# Change image [root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.2 -n dev deployment.apps/pc-deployment image updated # Observe the upgrade process [root@k8s-master01 ~]# kubectl get pods -n dev -w NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-65qcw 1/1 Running 0 31s pc-deployment-5d89bdfbf9-w5nzv 1/1 Running 0 31s pc-deployment-5d89bdfbf9-xpt7w 1/1 Running 0 31s pc-deployment-5d89bdfbf9-xpt7w 1/1 Terminating 0 41s pc-deployment-5d89bdfbf9-65qcw 1/1 Terminating 0 41s pc-deployment-5d89bdfbf9-w5nzv 1/1 Terminating 0 41s pc-deployment-675d469f8b-grn8z 0/1 Pending 0 0s pc-deployment-675d469f8b-hbl4v 0/1 Pending 0 0s pc-deployment-675d469f8b-67nz2 0/1 Pending 0 0s pc-deployment-675d469f8b-grn8z 0/1 ContainerCreating 0 0s pc-deployment-675d469f8b-hbl4v 0/1 ContainerCreating 0 0s pc-deployment-675d469f8b-67nz2 0/1 ContainerCreating 0 0s pc-deployment-675d469f8b-grn8z 1/1 Running 0 1s pc-deployment-675d469f8b-67nz2 1/1 Running 0 1s pc-deployment-675d469f8b-hbl4v 1/1 Running 0 2s
Rolling update
- Edit pc-deployment.yaml and add an update policy under the spec node
spec:
strategy: # strategy
type: RollingUpdate # Rolling update strategy
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
- Create deploy for validation
# Change image [root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.3 -n dev deployment.apps/pc-deployment image updated # Observe the upgrade process [root@k8s-master01 ~]# kubectl get pods -n dev -w NAME READY STATUS RESTARTS AGE pc-deployment-c848d767-8rbzt 1/1 Running 0 31m pc-deployment-c848d767-h4p68 1/1 Running 0 31m pc-deployment-c848d767-hlmz4 1/1 Running 0 31m pc-deployment-c848d767-rrqcn 1/1 Running 0 31m pc-deployment-966bf7f44-226rx 0/1 Pending 0 0s pc-deployment-966bf7f44-226rx 0/1 ContainerCreating 0 0s pc-deployment-966bf7f44-226rx 1/1 Running 0 1s pc-deployment-c848d767-h4p68 0/1 Terminating 0 34m pc-deployment-966bf7f44-cnd44 0/1 Pending 0 0s pc-deployment-966bf7f44-cnd44 0/1 ContainerCreating 0 0s pc-deployment-966bf7f44-cnd44 1/1 Running 0 2s pc-deployment-c848d767-hlmz4 0/1 Terminating 0 34m pc-deployment-966bf7f44-px48p 0/1 Pending 0 0s pc-deployment-966bf7f44-px48p 0/1 ContainerCreating 0 0s pc-deployment-966bf7f44-px48p 1/1 Running 0 0s pc-deployment-c848d767-8rbzt 0/1 Terminating 0 34m pc-deployment-966bf7f44-dkmqp 0/1 Pending 0 0s pc-deployment-966bf7f44-dkmqp 0/1 ContainerCreating 0 0s pc-deployment-966bf7f44-dkmqp 1/1 Running 0 2s pc-deployment-c848d767-rrqcn 0/1 Terminating 0 34m # At this point, the new version of pod is created and the version of pod is destroyed # The intermediate process is rolling, that is, creating while destroying
Rolling update process:
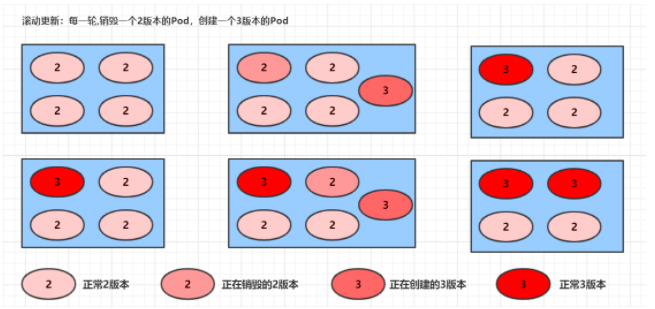
Changes of rs in mirror update
# Looking at rs, it is found that the original rs still exists, but the number of pods becomes 0, and then a new rs is generated, and the number of pods is 4 # In fact, this is the secret of version fallback in deployment, which will be explained in detail later [root@k8s-master01 ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-6696798b78 0 0 0 7m37s pc-deployment-6696798b11 0 0 0 5m37s pc-deployment-c848d76789 4 4 4 72s
6.3.3 version fallback
deployment supports many functions such as pause, resume and version fallback during version upgrade, as shown below
kubectl rollout: functions related to version upgrade. The following options are supported:
- Status displays the current upgrade status
- History displays the upgrade history
- Pause pause the version upgrade process
- resume resumes the suspended version upgrade process
- Restart restart the version upgrade process
- undo rollback to the previous version (you can use – to revision to rollback to the specified version)
# View the status of the current upgraded version [root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev deployment "pc-deployment" successfully rolled out # View upgrade history [root@k8s-master01 ~]# kubectl rollout history deploy pc-deployment -n dev deployment.apps/pc-deployment REVISION CHANGE-CAUSE 1 kubectl create --filename=pc-deployment.yaml --record=true 2 kubectl create --filename=pc-deployment.yaml --record=true 3 kubectl create --filename=pc-deployment.yaml --record=true # It can be found that there are three version records, indicating that two upgrades have been completed # Version rollback # Here, you can directly use -- to revision = 1 to roll back to version 1. If you omit this option, you will roll back to the previous version, which is version 2 [root@k8s-master01 ~]# kubectl rollout undo deployment pc-deployment --to-revision=1 -n dev deployment.apps/pc-deployment rolled back # The first version can be found through the nginx image version [root@k8s-master01 ~]# kubectl get deploy -n dev -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES pc-deployment 4/4 4 4 74m nginx nginx:1.17.1 # Looking at the rs, it is found that four pods in the first rs are running, and the pods in the later two versions of rs are running # In fact, the reason why deployment can roll back the version is to record the history rs, # Once you want to rollback to which version, you only need to reduce the number of pods of the current version to 0, and then increase the number of pods of the rollback version to the target number [root@k8s-master01 ~]# kubectl get rs -n dev NAME DESIRED CURRENT READY AGE pc-deployment-6696798b78 4 4 4 78m pc-deployment-966bf7f44 0 0 0 37m pc-deployment-c848d767 0 0 0 71m
6.3.4 Canary release
The Deployment controller supports control during the update process, such as "pause" or "resume" update operations.
For example, when a batch of new Pod resources are created, the update process is suspended immediately. At this time, there are only some new versions of applications, and the main part is still the old version. Then, filter a small number of user requests to route to the new version of Pod application, and continue to observe whether it can run stably in the desired way. After confirming that there is no problem, continue to complete the rolling update of the remaining Pod resources, otherwise roll back the update operation immediately. This is the so-called Canary release.
# Update the version of deployment and configure to suspend deployment [root@k8s-master01 ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment pc-deployment -n dev deployment.apps/pc-deployment image updated deployment.apps/pc-deployment paused #Observe update status [root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev Waiting for deployment "pc-deployment" rollout to finish: 2 out of 4 new replicas have been updated... # Monitoring the update process, we can see that a new resource has been added, but an old resource has not been deleted according to the expected state, because the pause command is used [root@k8s-master01 ~]# kubectl get rs -n dev -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES pc-deployment-5d89bdfbf9 3 3 3 19m nginx nginx:1.17.1 pc-deployment-675d469f8b 0 0 0 14m nginx nginx:1.17.2 pc-deployment-6c9f56fcfb 2 2 2 3m16s nginx nginx:1.17.4 [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-deployment-5d89bdfbf9-rj8sq 1/1 Running 0 7m33s pc-deployment-5d89bdfbf9-ttwgg 1/1 Running 0 7m35s pc-deployment-5d89bdfbf9-v4wvc 1/1 Running 0 7m34s pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 3m31s pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 3m31s # Make sure that the updated pod is OK and continue to update [root@k8s-master01 ~]# kubectl rollout resume deploy pc-deployment -n dev deployment.apps/pc-deployment resumed # View the last update [root@k8s-master01 ~]# kubectl get rs -n dev -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES pc-deployment-5d89bdfbf9 0 0 0 21m nginx nginx:1.17.1 pc-deployment-675d469f8b 0 0 0 16m nginx nginx:1.17.2 pc-deployment-6c9f56fcfb 4 4 4 5m11s nginx nginx:1.17.4 [root@k8s-master01 ~]# kubectl get pods -n dev NAME READY STATUS RESTARTS AGE pc-deployment-6c9f56fcfb-7bfwh 1/1 Running 0 37s pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 5m27s pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 5m27s pc-deployment-6c9f56fcfb-rf84v 1/1 Running 0 37s
Delete Deployment
# When the deployment is deleted, the rs and pod under it will also be deleted [root@k8s-master01 ~]# kubectl delete -f pc-deployment.yaml deployment.apps "pc-deployment" deleted
6.4 Horizontal Pod Autoscaler(HPA)
In the previous course, we can manually execute kubectl scale command to realize pod capacity expansion or reduction, but this obviously does not meet the positioning goal of kubernetes - automation and intelligence. Kubernetes expects to realize the automatic adjustment of the number of pods by monitoring the use of pods, so a controller such as Horizontal Pod Autoscaler (HPA) is produced.
HPA can obtain the utilization rate of each Pod, then compare it with the indicators defined in HPA, calculate the specific value to be scaled, and finally adjust the number of pods. In fact, like the previous Deployment, HPA also belongs to a Kubernetes resource object. It tracks and analyzes the load changes of all target pods controlled by RC to determine whether it is necessary to adjust the number of copies of the target Pod. This is the implementation principle of HPA.
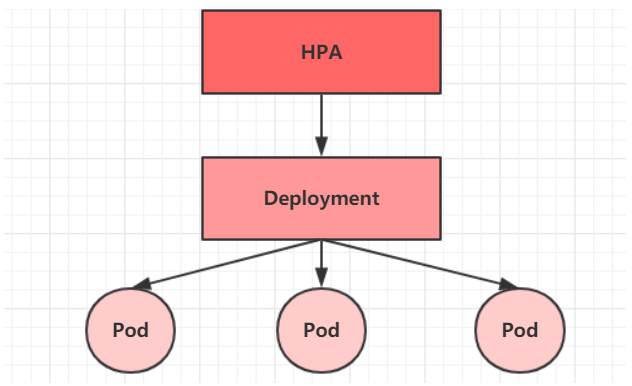
Next, let's do an experiment
6.4.1 installing metrics server
Metrics server can be used to collect resource usage in a cluster
# Install git [root@k8s-master01 ~]# yum install git -y # Get the metrics server and pay attention to the version used [root@k8s-master01 ~]# git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server # When modifying the deployment, note that the image and initialization parameters are modified [root@k8s-master01 ~]# cd /root/metrics-server/deploy/1.8+/ [root@k8s-master01 1.8+]# vim metrics-server-deployment.yaml Add the following options as shown hostNetwork: true image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6 args: - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
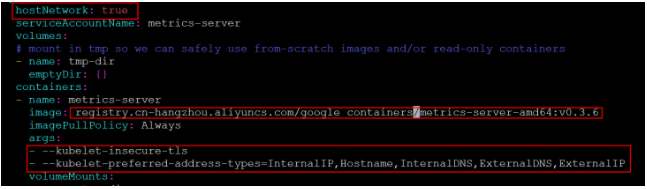
# Installing metrics server [root@k8s-master01 1.8+]# kubectl apply -f ./ # Check the operation of pod [root@k8s-master01 1.8+]# kubectl get pod -n kube-system metrics-server-6b976979db-2xwbj 1/1 Running 0 90s # Use kubectl top node to view resource usage [root@k8s-master01 1.8+]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 289m 14% 1582Mi 54% k8s-node01 81m 4% 1195Mi 40% k8s-node02 72m 3% 1211Mi 41% [root@k8s-master01 1.8+]# kubectl top pod -n kube-system NAME CPU(cores) MEMORY(bytes) coredns-6955765f44-7ptsb 3m 9Mi coredns-6955765f44-vcwr5 3m 8Mi etcd-master 14m 145Mi ... # At this point, the metrics server installation is complete
6.4.2 preparing deployment and servie
Create a pc-hpa-pod.yaml file as follows:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
strategy: # strategy
type: RollingUpdate # Rolling update strategy
replicas: 1
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # Resource quota
limits: # Limit resources (upper limit)
cpu: "1" # CPU limit, in core s
requests: # Requested resources (lower limit)
cpu: "100m" # CPU limit, in core s
# Create deployment [root@k8s-master01 1.8+]# kubectl run nginx --image=nginx:1.17.1 --requests=cpu=100m -n dev # Create service [root@k8s-master01 1.8+]# kubectl expose deployment nginx --type=NodePort --port=80 -n dev
# see [root@k8s-master01 1.8+]# kubectl get deployment,pod,svc -n dev NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 1/1 1 1 47s NAME READY STATUS RESTARTS AGE pod/nginx-7df9756ccc-bh8dr 1/1 Running 0 47s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/nginx NodePort 10.101.18.29 <none> 80:31830/TCP 35s
6.4.3 deploy HPA
Create a pc-hpa.yaml file as follows:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pc-hpa
namespace: dev
spec:
minReplicas: 1 #Minimum pod quantity
maxReplicas: 10 #Maximum number of pod s
targetCPUUtilizationPercentage: 3 # CPU utilization index
scaleTargetRef: # Specify the nginx information to control
apiVersion: /v1
kind: Deployment
name: nginx
# Create hpa
[root@k8s-master01 1.8+]# kubectl create -f pc-hpa.yaml
horizontalpodautoscaler.autoscaling/pc-hpa created
# View hpa
[root@k8s-master01 1.8+]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 62s
6.4.4 testing
Use the pressure measurement tool to measure the service address 192.168.5.4:31830, and then check the changes of hpa and pod through the console
hpa change
[root@k8s-master01 ~]# kubectl get hpa -n dev -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE pc-hpa Deployment/nginx 0%/3% 1 10 1 4m11s pc-hpa Deployment/nginx 0%/3% 1 10 1 5m19s pc-hpa Deployment/nginx 22%/3% 1 10 1 6m50s pc-hpa Deployment/nginx 22%/3% 1 10 4 7m5s pc-hpa Deployment/nginx 22%/3% 1 10 8 7m21s pc-hpa Deployment/nginx 6%/3% 1 10 8 7m51s pc-hpa Deployment/nginx 0%/3% 1 10 8 9m6s pc-hpa Deployment/nginx 0%/3% 1 10 8 13m pc-hpa Deployment/nginx 0%/3% 1 10 1 14m
deployment change
[root@k8s-master01 ~]# kubectl get deployment -n dev -w NAME READY UP-TO-DATE AVAILABLE AGE nginx 1/1 1 1 11m nginx 1/4 1 1 13m nginx 1/4 1 1 13m nginx 1/4 1 1 13m nginx 1/4 4 1 13m nginx 1/8 4 1 14m nginx 1/8 4 1 14m nginx 1/8 4 1 14m nginx 1/8 8 1 14m nginx 2/8 8 2 14m nginx 3/8 8 3 14m nginx 4/8 8 4 14m nginx 5/8 8 5 14m nginx 6/8 8 6 14m nginx 7/8 8 7 14m nginx 8/8 8 8 15m nginx 8/1 8 8 20m nginx 8/1 8 8 20m nginx 1/1 1 1 20m
pod change
[root@k8s-master01 ~]# kubectl get pods -n dev -w NAME READY STATUS RESTARTS AGE nginx-7df9756ccc-bh8dr 1/1 Running 0 11m nginx-7df9756ccc-cpgrv 0/1 Pending 0 0s nginx-7df9756ccc-8zhwk 0/1 Pending 0 0s nginx-7df9756ccc-rr9bn 0/1 Pending 0 0s nginx-7df9756ccc-cpgrv 0/1 ContainerCreating 0 0s nginx-7df9756ccc-8zhwk 0/1 ContainerCreating 0 0s nginx-7df9756ccc-rr9bn 0/1 ContainerCreating 0 0s nginx-7df9756ccc-m9gsj 0/1 Pending 0 0s nginx-7df9756ccc-g56qb 0/1 Pending 0 0s nginx-7df9756ccc-sl9c6 0/1 Pending 0 0s nginx-7df9756ccc-fgst7 0/1 Pending 0 0s nginx-7df9756ccc-g56qb 0/1 ContainerCreating 0 0s nginx-7df9756ccc-m9gsj 0/1 ContainerCreating 0 0s nginx-7df9756ccc-sl9c6 0/1 ContainerCreating 0 0s nginx-7df9756ccc-fgst7 0/1 ContainerCreating 0 0s nginx-7df9756ccc-8zhwk 1/1 Running 0 19s nginx-7df9756ccc-rr9bn 1/1 Running 0 30s nginx-7df9756ccc-m9gsj 1/1 Running 0 21s nginx-7df9756ccc-cpgrv 1/1 Running 0 47s nginx-7df9756ccc-sl9c6 1/1 Running 0 33s nginx-7df9756ccc-g56qb 1/1 Running 0 48s nginx-7df9756ccc-fgst7 1/1 Running 0 66s nginx-7df9756ccc-fgst7 1/1 Terminating 0 6m50s nginx-7df9756ccc-8zhwk 1/1 Terminating 0 7m5s nginx-7df9756ccc-cpgrv 1/1 Terminating 0 7m5s nginx-7df9756ccc-g56qb 1/1 Terminating 0 6m50s nginx-7df9756ccc-rr9bn 1/1 Terminating 0 7m5s nginx-7df9756ccc-m9gsj 1/1 Terminating 0 6m50s nginx-7df9756ccc-sl9c6 1/1 Terminating 0 6m50s
6.5 DaemonSet(DS)
A DaemonSet type controller can ensure that a replica runs on each (or specified) node in the cluster. It is generally applicable to log collection, node monitoring and other scenarios. That is to say, if the functions provided by a Pod are node level (each node requires and only needs one), then this kind of Pod is suitable for creating with a controller of type DaemonSet.
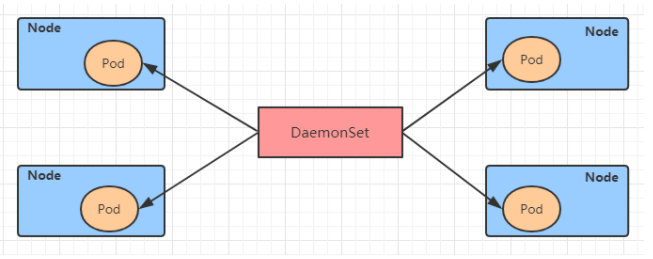
Features of DaemonSet controller:
- Whenever a node is added to the cluster, the specified Pod copy is also added to the node
- When a node is removed from the cluster, the Pod is garbage collected
Let's take a look at the resource manifest file of DaemonSet
apiVersion: apps/v1 # Version number
kind: DaemonSet # type
metadata: # metadata
name: # rs name
namespace: # Namespace
labels: #label
controller: daemonset
spec: # Detailed description
revisionHistoryLimit: 3 # Keep historical version
updateStrategy: # Update strategy
type: RollingUpdate # Rolling update strategy
rollingUpdate: # Rolling update
maxUnavailable: 1 # The maximum value of the Pod in the maximum unavailable state, which can be either a percentage or an integer
selector: # Selector, which specifies which pod s the controller manages
matchLabels: # Labels matching rule
app: nginx-pod
matchExpressions: # Expressions matching rule
- {key: app, operator: In, values: [nginx-pod]}
template: # Template. When the number of copies is insufficient, a pod copy will be created according to the following template
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
Create pc-daemon.yaml as follows:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: pc-daemonset
namespace: dev
spec:
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# Create daemonset [root@k8s-master01 ~]# kubectl create -f pc-daemonset.yaml daemonset.apps/pc-daemonset created # View daemonset [root@k8s-master01 ~]# kubectl get ds -n dev -o wide NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES pc-daemonset 2 2 2 2 2 24s nginx nginx:1.17.1 # Check the pod and find that a pod is running on each Node [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE pc-daemonset-9bck8 1/1 Running 0 37s 10.244.1.43 node1 pc-daemonset-k224w 1/1 Running 0 37s 10.244.2.74 node2 # Delete daemonset [root@k8s-master01 ~]# kubectl delete -f pc-daemonset.yaml daemonset.apps "pc-daemonset" deleted
6.6 Job
Job, which is mainly used for * * batch processing (processing a specified number of tasks at a time) short one-time (each task ends after running only once) * * tasks. Job features are as follows:
- When the execution of the pod created by the Job is completed successfully, the Job will record the number of successfully completed pods
- When the number of successfully completed pod s reaches the specified number, the Job will complete execution
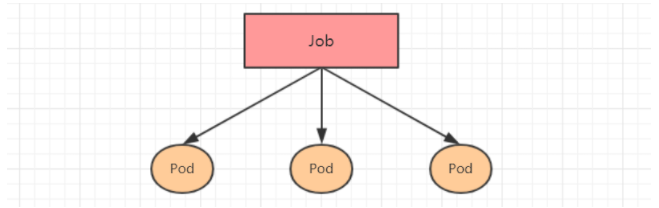
Job resource manifest file:
apiVersion: batch/v1 # Version number
kind: Job # type
metadata: # metadata
name: # rs name
namespace: # Namespace
labels: #label
controller: job
spec: # Detailed description
completions: 1 # Specifies the number of times a job needs to run Pods successfully. Default: 1
parallelism: 1 # Specifies the number of Pods that a job should run concurrently at any one time. Default: 1
activeDeadlineSeconds: 30 # Specify the time period within which the job can run. If it is not over, the system will try to terminate it.
backoffLimit: 6 # Specifies the number of retries after a job fails. The default is 6
manualSelector: true # Can I use the selector to select pod? The default is false
selector: # Selector, which specifies which pod s the controller manages
matchLabels: # Labels matching rule
app: counter-pod
matchExpressions: # Expressions matching rule
- {key: app, operator: In, values: [counter-pod]}
template: # Template. When the number of copies is insufficient, a pod copy will be created according to the following template
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # The restart policy can only be set to Never or OnFailure
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2;done"]
Description of restart policy settings:
If specified as OnFailure,be job Will be pod Restart the container on failure instead of creating pod,failed Times unchanged
If specified as Never,be job Will be pod Create a new on failure pod,And fault pod It won't disappear or restart, failed Times plus 1
If specified as Always If so, it means always restarting, which means job The task will be executed repeatedly. Of course, it is wrong, so it cannot be set to Always
Create pc-job.yaml as follows:
apiVersion: batch/v1
kind: Job
metadata:
name: pc-job
namespace: dev
spec:
manualSelector: true
selector:
matchLabels:
app: counter-pod
template:
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 3;done"]
# Create job [root@k8s-master01 ~]# kubectl create -f pc-job.yaml job.batch/pc-job created # View job [root@k8s-master01 ~]# kubectl get job -n dev -o wide -w NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR pc-job 0/1 21s 21s counter busybox:1.30 app=counter-pod pc-job 1/1 31s 79s counter busybox:1.30 app=counter-pod # By observing the status of the pod, you can see that the pod will change to the Completed status after running the task [root@k8s-master01 ~]# kubectl get pods -n dev -w NAME READY STATUS RESTARTS AGE pc-job-rxg96 1/1 Running 0 29s pc-job-rxg96 0/1 Completed 0 33s # Next, adjust the total number and parallel number of pod runs, that is, set the following two options under spec # completions: 6 # The number of times that the specified job needs to run Pods successfully is 6 # parallelism: 3 # Specify that the number of job s running Pods concurrently is 3 # Then re run the job and observe the effect. At this time, it will be found that the job will run 3 pods at a time, and a total of 6 pods have been executed [root@k8s-master01 ~]# kubectl get pods -n dev -w NAME READY STATUS RESTARTS AGE pc-job-684ft 1/1 Running 0 5s pc-job-jhj49 1/1 Running 0 5s pc-job-pfcvh 1/1 Running 0 5s pc-job-684ft 0/1 Completed 0 11s pc-job-v7rhr 0/1 Pending 0 0s pc-job-v7rhr 0/1 Pending 0 0s pc-job-v7rhr 0/1 ContainerCreating 0 0s pc-job-jhj49 0/1 Completed 0 11s pc-job-fhwf7 0/1 Pending 0 0s pc-job-fhwf7 0/1 Pending 0 0s pc-job-pfcvh 0/1 Completed 0 11s pc-job-5vg2j 0/1 Pending 0 0s pc-job-fhwf7 0/1 ContainerCreating 0 0s pc-job-5vg2j 0/1 Pending 0 0s pc-job-5vg2j 0/1 ContainerCreating 0 0s pc-job-fhwf7 1/1 Running 0 2s pc-job-v7rhr 1/1 Running 0 2s pc-job-5vg2j 1/1 Running 0 3s pc-job-fhwf7 0/1 Completed 0 12s pc-job-v7rhr 0/1 Completed 0 12s pc-job-5vg2j 0/1 Completed 0 12s # Delete job [root@k8s-master01 ~]# kubectl delete -f pc-job.yaml job.batch "pc-job" deleted
6.7 CronJob(CJ)
The CronJob controller takes the Job controller resource as its control object and uses it to manage the pod resource object. The Job tasks defined by the Job controller will be executed immediately after its controller resource is created, but CronJob can control its running time point and repeated running mode in a way similar to the periodic task Job plan of the Linux operating system. That is, CronJob can run Job tasks at a specific point in time (repeatedly).
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-Z2O6Zqjl-1638097980073)(Kubenetes.assets/image-20200618213149531.png)]
Resource manifest file for CronJob:
apiVersion: batch/v1beta1 # Version number
kind: CronJob # type
metadata: # metadata
name: # rs name
namespace: # Namespace
labels: #label
controller: cronjob
spec: # Detailed description
schedule: # cron format job scheduling run time point, which is used to control when tasks are executed
concurrencyPolicy: # Concurrent execution policy is used to define whether and how to run the next job when the previous job run has not been completed
failedJobHistoryLimit: # The number of history records reserved for failed task execution. The default is 1
successfulJobHistoryLimit: # The number of history records reserved for successful task execution. The default is 3
startingDeadlineSeconds: # Timeout length of start job error
jobTemplate: # The job controller template is used to generate a job object for the cronjob controller; The following is actually the definition of job
metadata:
spec:
completions: 1
parallelism: 1
activeDeadlineSeconds: 30
backoffLimit: 6
manualSelector: true
selector:
matchLabels:
app: counter-pod
matchExpressions: rule
- {key: app, operator: In, values: [counter-pod]}
template:
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 20;done"]
Several key options to explain:
schedule: cron Expression that specifies the execution time of the task
*/1 * * * *
<minute> <hour> <day> <month> <week>
Minute values range from 0 to 59.
Hour values range from 0 to 23.
Daily values range from 1 to 31.
Monthly values range from 1 to 12.
Week values range from 0 to 6, 0 On behalf of Sunday
Multiple times can be separated by commas; The range can be given with hyphens;*Can be used as wildcards; /Represents each...
concurrencyPolicy:
Allow: allow Jobs Concurrent operation(default)
Forbid: Concurrent running is prohibited. If the previous run has not been completed, the next run will be skipped
Replace: Replace, cancel the currently running job and replace it with a new job
Create pc-cronjob.yaml as follows:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: pc-cronjob
namespace: dev
labels:
controller: cronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
metadata:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 3;done"]
# Create cronjob [root@k8s-master01 ~]# kubectl create -f pc-cronjob.yaml cronjob.batch/pc-cronjob created # View cronjob [root@k8s-master01 ~]# kubectl get cronjobs -n dev NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE pc-cronjob */1 * * * * False 0 <none> 6s # View job [root@k8s-master01 ~]# kubectl get jobs -n dev NAME COMPLETIONS DURATION AGE pc-cronjob-1592587800 1/1 28s 3m26s pc-cronjob-1592587860 1/1 28s 2m26s pc-cronjob-1592587920 1/1 28s 86s # View pod [root@k8s-master01 ~]# kubectl get pods -n dev pc-cronjob-1592587800-x4tsm 0/1 Completed 0 2m24s pc-cronjob-1592587860-r5gv4 0/1 Completed 0 84s pc-cronjob-1592587920-9dxxq 1/1 Running 0 24s # Delete cronjob [root@k8s-master01 ~]# kubectl delete -f pc-cronjob.yaml cronjob.batch "pc-cronjob" deleted