1. Introduction to kudu
1.1 what is kudu?
Background:
Before Kudu, big data was mainly stored in two ways;
- Static data:
- Taking HDFS engine as the storage engine, it is suitable for high-throughput offline big data analysis scenarios.
- The limitation of this kind of storage is that the data cannot be read and written randomly.
- Dynamic data:
- HBase and Cassandra are used as storage engines, which are suitable for big data random reading and writing scenarios.
- The limitation of this kind of storage is that the batch read throughput is far lower than that of HDFS, which is not suitable for the scenario of batch data analysis.
It can be seen from the above analysis that these two kinds of data are completely different in storage methods, resulting in completely different use scenarios. However, in the real scene, the boundary may not be so clear. How to choose in the face of big data scenarios that require both random reading and writing and batch analysis? In this scenario, a single storage engine cannot meet the business needs, and we need to meet this need through a combination of multiple big data tools.
===>Therefore:
To put it simply: dudu is a columnar storage distributed database similar to hbase.
The official positioning of kudu is to achieve faster data analysis on the basis of more timely updates
1.2 why do you need kudu?
1.2.1 disadvantages of hdfs and hbase data storage
At present, with HDFS and hbase for data storage, why do you need an extra kudu?
HDFS: it uses the columnar storage format Apache Parquet and Apache ORC, which is suitable for offline analysis. It does not support the update operation at the level of a single record, and the random reading and writing performance is poor
HBASE: it can carry out efficient random reading and writing, but it is not suitable for the direction of data analysis based on SQL. The performance of mass data acquisition is poor.
Because HDFS and HBase have the above disadvantages, KUDU can better solve these disadvantages of HDFS and HBase. It is not as fast as HDFS batch processing and not as strong as HBase random reading and writing ability, but on the contrary, it is faster than HBase batch processing (applicable to OLAP analysis scenarios) and better than HDFS random reading and writing ability (applicable to real-time writing or update scenarios), This is the problem it can solve.
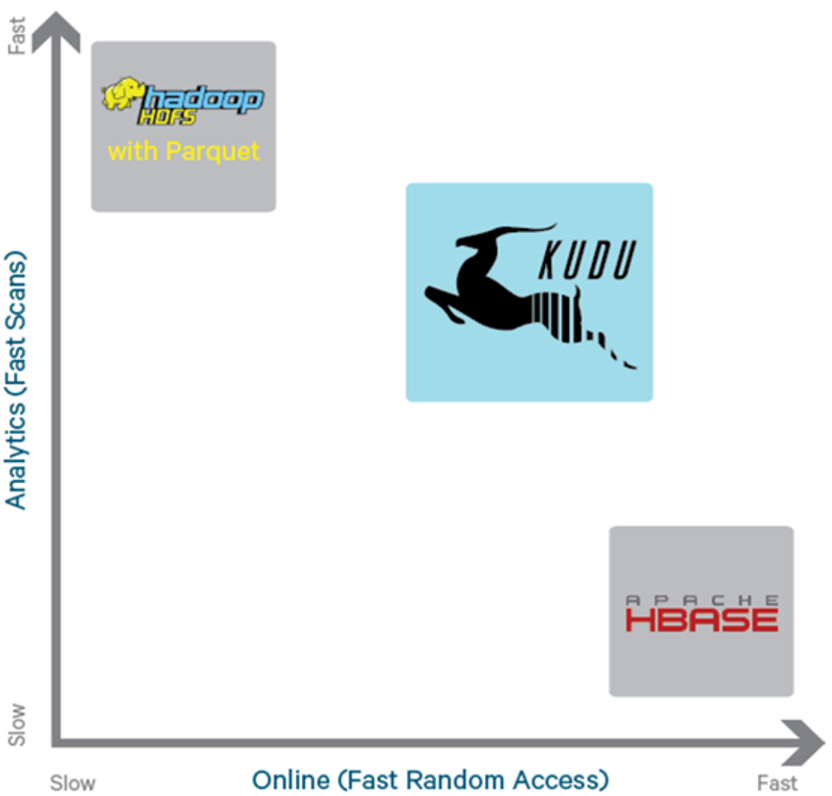
As can be seen from the above figure, KUDU is a compromise product, which balances the performance of random read-write and batch analysis among HDFS and HBase. From the birth of KUDU, it can be explained that the development of the underlying technology is often driven by the business of the upper layer, and the technology separated from the business is likely to be a castle in the air.
2. Architecture introduction
2.1 basic structure
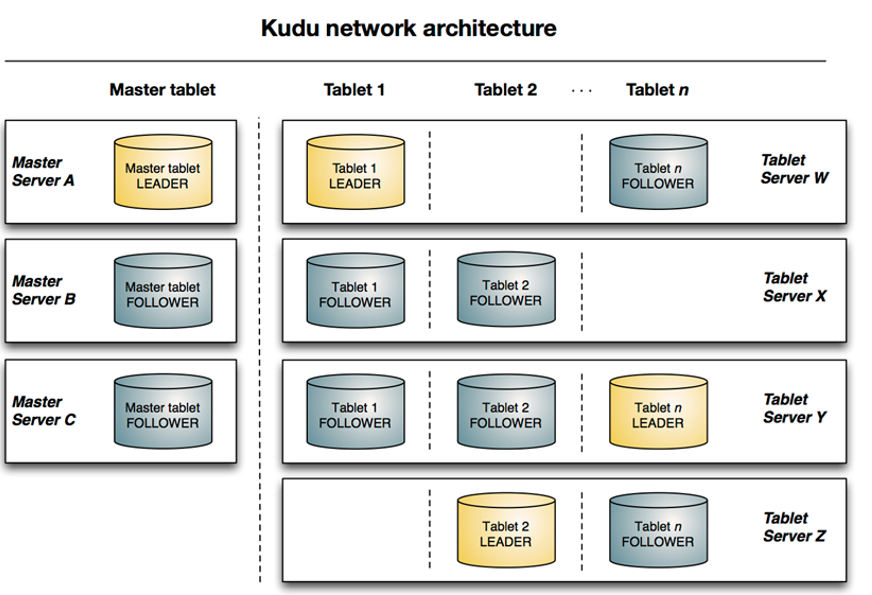
2.1.1 concept
Table: a table is the location where data is stored in kudu. Table has a schema and a globally ordered primary key. Tables are divided into many segments, that is, tables
Table (segment): a table is a continuous segment of a table, which is similar to the partition of other data storage engines or relational data. The Tablet has a copy mechanism, one of which is the leader tablet. Any replica can serve reading, and consistency needs to be reached between the Tablet servers corresponding to all replicas when writing.
Tablet server: stores and provides services to client s for tablets. For a given tablet, one tablet server acts as the leader and other tablet servers act as the follower copy of the tablet. Only leader services write requests, and leader and follower provide read requests for each service.
Master: it is mainly used to manage metadata (metadata is stored in the catalog table with only one tablet), that is, the basic information of the tablet and the table, and monitor the status of tserver
Catalog Table: metadata table, which is used to store the information of table(schema, locations, states) and tablet (existing tablet list, tserver of each tablet and its copy, current state of tablet and start and end keys).
3. Storage mechanism
3.1 panorama of storage structure
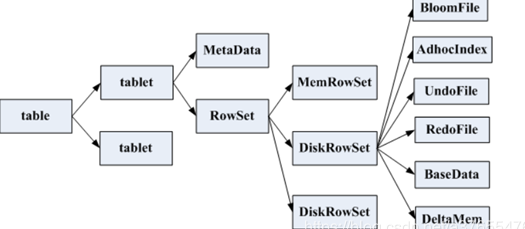
3.2. Storage structure analysis
a Table contains multiple tables, and the number of tables is set according to hash or range
a Tablet contains MetaData information and multiple RowSet information
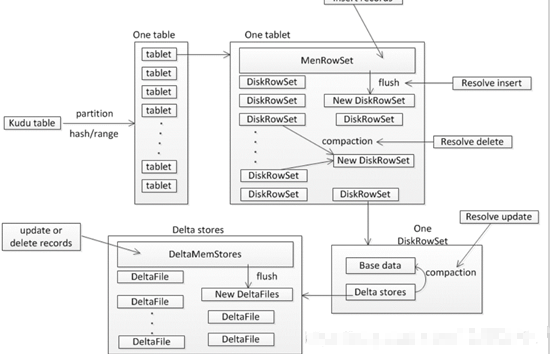
a Rowset contains a MemRowSet and 0 or more diskrowsets. The MemRowSet stores the insert ed data. Once the MemRowSet is full, it will flush to the disk to generate one or more diskrowsets. At this time, the MemRowSet is empty. MemRowSet writes 1G or 120s flush by default
(Note: MemRowSet is row storage, diskrowset is column storage, and MemRowSet is ordered based on primary key). Every tablet will perform a periodic compaction operation on some diskrowsets to reorder multiple diskrowsets, so as to make them more orderly and reduce the number of diskrowsets. At the same time, Huihui resolve s the delete records in the deletestores during the compaction process
a DiskRowSet includes two parts: baseData and DeltaStores. The data stored in baseData looks unchangeable, and the data stored in DeltaStores is changed
DeltaStores includes one DeltaMemStores and multiple deltafiles. DeltaMemStores are placed in memory to store update and delete data. Once the DeltaMemStores are full, it will flush into DeltaFile.
When there are too many deltafiles, the query performance will be affected. Therefore, KUDU will perform the compaction operation every once in a while to merge them into the baseData, mainly to resolve the update data.
4. Working mechanism of kudu
4.1 overview
1. The main roles of kudu are divided into master and tserver
2. The master is mainly responsible for managing metadata information, monitoring the server, and reallocating the tablet after the server goes down
3. tserver is mainly responsible for the storage and of tablet and the addition, deletion, modification and query of data
4.2 schematic diagram of internal implementation
4.2 reading process
4.2.1 overview
The client sends the data information to be read to the master, and the master checks it, such as whether the table and field exist. The master returns the metaData information to the client, then the client establishes a connection with the tserver, finds the RowSet where the data is located through the metaData, first loads the data in the memory (MemRowSet and DeltMemStore), then loads the data in the disk, and finally returns the final data to the client
4.2.2 detailed step diagram
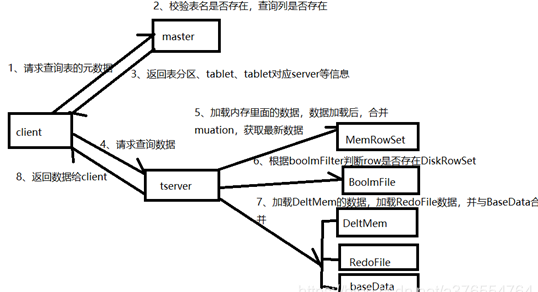
4.2.3 detailed step analysis
1. The client master requests to query the data specified in the table
2. The master verifies the request, whether the table exists, whether the field of the specified query exists in the schema, and whether the primary key exists
3. The master returns the table by querying the catalog Table, and returns the tserver information, tserver status and other metadata information corresponding to the tablet to the client
4. The client establishes a connection with the tserver and finds the RowSet corresponding to the primary key through metaData.
5. First, load the data in MemRowSet and DeltMemStore in RowSet memory
6. Then load the data in the disk, that is, the data in BaseData and DeltFile in DiskRowSet
7. Return data to Client
8. Continue steps 4-7 until all the data is returned to the client
4.3. Insert process
4.3.1 overview
The Client first connects to the master to obtain metadata information. Then connect tserver and find out whether the same primary key exists in MemRowSet and DeltMemStore. If so, an error is reported; If it does not exist, write the data to be inserted to the WAL log, and then write the data to the MemRowSet.
4.3.2 detailed step diagram
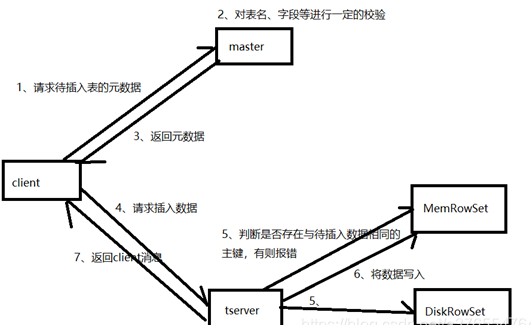
4.3.3 detailed step analysis
1. The client requests metadata information of the pre written table from the master
2. The master will check whether the table and field exist
3. If the master verification passes, the partition of the table, the tablet and its corresponding tserver will be returned to the client; If the verification fails, an error is reported to the client.
4. The client sends the request to the tserver corresponding to the tablet according to the metadata information returned by the master
5. tserver will first query whether there is data with the same primary key as the data to be inserted in MemRowSet and DeltMemStore in memory. If so, an error will be reported
6. tserver will pre write the write request to the WAL log, which is used to recover after the server goes down
7. Write data into the MemRowSet in memory. Once the size of the MemRowSet reaches 1G or 120s, the MemRowSet will be flush ed into one or DiskRowSet to persist the data
8. Return to client data processing completed
4.4 data update process
4.4.1 overview
The Client first requests metadata from the master, and then connects to the tserver according to the tablet information provided by the metadata. There are different operations according to the location of the data: for the data in the MemRowSet memory, the update information will be written into the mutation linked list of the row where the data is located; The data in the disk will write the update information to DeltMemStore.
4.4.2 detailed step diagram
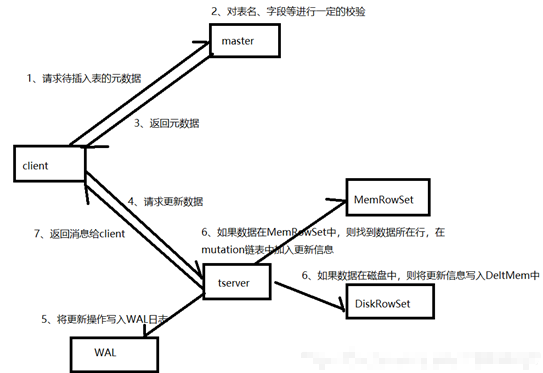
4.4.3 detailed step analysis
1. The client requests the master to pre update the metadata of the table. First, the master will verify whether the table exists and whether the fields exist. If the verification passes, it will return the partition, tablet and tserver information of the client table
2. client sends update request to tserver
3. Pre write the update operation, such as WAL log, for data recovery after server downtime
4. There are different processing methods according to the location of the data to be updated in tserver:
If the data is in memory, find the row in which the data is located from the MemRowSet, and then write the update information in the mutation linked list of the changed row. When the MemRowSet flush, merge the update into the baseData
If the data is in the DiskRowSet, the update information will be written into the DeltMemStore. When the DeltMemStore reaches a certain size, it will be flush ed into DeltFile.
5. After the update, a message is returned to the client.
5. java operation of KUDU
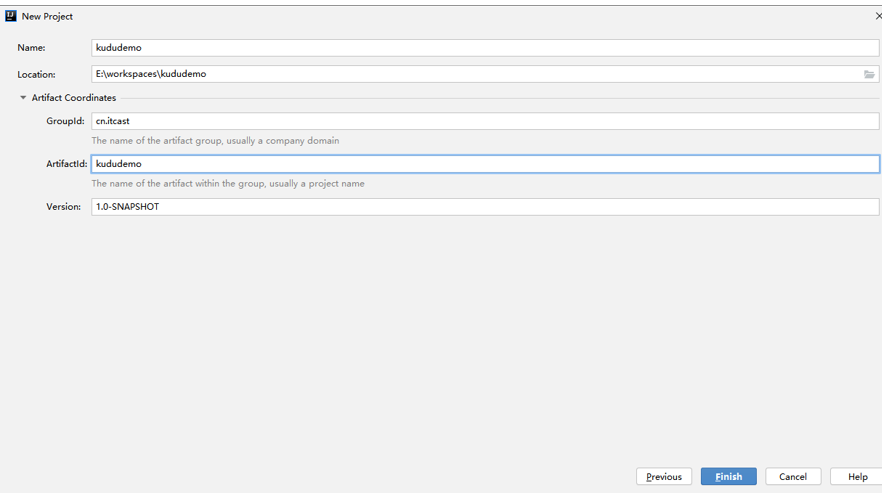
5.1. Build maven project
5.2 import dependency
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client-tools</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
5.3 initialization method
package cn.itcast;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Type;
import org.apache.kudu.client.KuduClient;
import org.junit.Before;
public class TestKudu {
//Define KuduClient client object
private static KuduClient kuduClient;
//Define table name
private static String tableName = "person";
/**
* Initialization method
*/
@Before
public void init() {
//Specify the master address
String masterAddress = "node2.itcast.cn";
//Create database connection for kudu
kuduClient = new KuduClient.KuduClientBuilder(masterAddress).defaultSocketReadTimeoutMs(6000).build();
}
//Build field information of table schema
//Whether the field name and data type are primary keys
public ColumnSchema newColumn(String name, Type type, boolean isKey) {
ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type);
column.key(isKey);
return column.build();
}
}
5.4 creating tables
/** Test with junit
*
* Create table
* @throws KuduException
*/
@Test
public void createTable() throws KuduException {
//Set the schema of the table
List<ColumnSchema> columns = new LinkedList<ColumnSchema>();
columns.add(newColumn("CompanyId", Type.INT32, true));
columns.add(newColumn("WorkId", Type.INT32, false));
columns.add(newColumn("Name", Type.STRING, false));
columns.add(newColumn("Gender", Type.STRING, false));
columns.add(newColumn("Photo", Type.STRING, false));
Schema schema = new Schema(columns);
//All options available when creating tables
CreateTableOptions tableOptions = new CreateTableOptions();
//Set replica and partition rules for tables
LinkedList<String> list = new LinkedList<String>();
list.add("CompanyId");
//Set the number of table copies
tableOptions.setNumReplicas(1);
//Set range partition
//tableOptions.setRangePartitionColumns(list);
//Set the number of hash partitions and partitions
tableOptions.addHashPartitions(list, 3);
try {
kuduClient.createTable("person", schema, tableOptions);
} catch (Exception e) {
e.printStackTrace();
}
kuduClient.close();
}
5.5 insert data
/**
* Loading data into a table
* @throws KuduException
*/
@Test
public void loadData() throws KuduException {
//Open table
KuduTable kuduTable = kuduClient.openTable(tableName);
//Create a KuduSession object. kudu must write data through KuduSession
KuduSession kuduSession = kuduClient.newSession();
//Refresh manually in flush mode
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
kuduSession.setMutationBufferSpace(3000);
//Prepare data
for(int i=1; i<=10; i++){
Insert insert = kuduTable.newInsert();
//Set the contents of the field
insert.getRow().addInt("CompanyId",i);
insert.getRow().addInt("WorkId",i);
insert.getRow().addString("Name","lisi"+i);
insert.getRow().addString("Gender","male");
insert.getRow().addString("Photo","person"+i);
kuduSession.flush();
kuduSession.apply(insert);
}
kuduSession.close();
kuduClient.close();
}
5.6 query data
/**
* Query table data
* @throws KuduException
*/
@Test
public void queryData() throws KuduException {
//Open table
KuduTable kuduTable = kuduClient.openTable(tableName);
//Get scanner scanner
KuduScanner.KuduScannerBuilder scannerBuilder = kuduClient.newScannerBuilder(kuduTable);
KuduScanner scanner = scannerBuilder.build();
//ergodic
while(scanner.hasMoreRows()){
RowResultIterator rowResults = scanner.nextRows();
while (rowResults.hasNext()){
RowResult result = rowResults.next();
int companyId = result.getInt("CompanyId");
int workId = result.getInt("WorkId");
String name = result.getString("Name");
String gender = result.getString("Gender");
String photo = result.getString("Photo");
System.out.print("companyId:"+companyId+" ");
System.out.print("workId:"+workId+" ");
System.out.print("name:"+name+" ");
System.out.print("gender:"+gender+" ");
System.out.println("photo:"+photo);
}
}
//close
scanner.close();
kuduClient.close();
}
5.7 modifying data
/**
* Modify data
* @throws KuduException
*/
@Test
public void upDATEData() throws KuduException {
//Open table
KuduTable kuduTable = kuduClient.openTable(tableName);
//Building kuduSession objects
KuduSession kuduSession = kuduClient.newSession();
//Set refresh data mode and submit automatically
kuduSession.setFlushMode(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND);
//UpDATE object is required to UpDATE data
UpDATE upDATE = kuduTable.newUpDATE();
//Get row object
PartialRow row = upDATE.getRow();
//Set data information to update
row.addInt("CompanyId",1);
row.addString("Name","kobe");
//Manipulate this upDATE object
kuduSession.apply(upDATE);
kuduSession.close();
}
5.8 deleting data
/**
* Delete data in table
*/
@Test
public void deleteData() throws KuduException {
//Open table
KuduTable kuduTable = kuduClient.openTable(tableName);
KuduSession kuduSession = kuduClient.newSession();
//Get Delete object
Delete delete = kuduTable.newDelete();
//Build the row object to delete
PartialRow row = delete.getRow();
//Set conditions for deleting data
row.addInt("CompanyId",2);
kuduSession.flush();
kuduSession.apply(delete);
kuduSession.close();
kuduClient.close();
}