The article has been included in my Github collection. Welcome Star: https://github.com/yehongzhi/learningSummary
Introduction to MapReduce
MapReduce is mainly divided into two parts: map and reduce, which adopt the idea of "divide and rule". Mapper is responsible for "divide", dividing a huge task into several small tasks for processing, while reduce is responsible for summarizing the results of the map stage.
For example, we need to count the frequency of each word in a large text, that is, WordCount. How does it work? See the figure below:

In the map phase, the input text is divided into words one by one. Key is the word and value is the number of occurrences. Then, in the Reduce phase, the number of times for the same key is increased by 1. Finally, the results are output to the file for saving.
WordCount example
Now let's enter the actual combat. How to realize the function of WordCount?
Create project
First, we have to create a maven project. The dependencies are as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.yehongzhi</groupId>
<artifactId>hadooptest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<repositories>
<repository>
<id>apache</id>
<url>http://maven.apache.org</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.0</version>
</dependency>
</dependencies>
</project>
The first step is the Mapper stage. Create the WordcountMapper class:
/**
* Mapper There are four generic parameters to fill in
* The first parameter KEYIN: by default, it is the starting offset of a line of text read by the mr frame. The type is LongWritable
* The second parameter VALUEIN: by default, it is the content of a line of Text read by the mr frame. The type is Text
* The third parameter KEYOUT: is the key of the output data after the logic processing is completed. Here is each word, and the type is Text
* The fourth parameter VALUEOUT: is the value of the output data after the logic processing is completed. Here, it is the number of times, and the type is Intwriterable
* */
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Convert the entered text to String
String string = value.toString();
//Use spaces to separate each word
String[] words = string.split(" ");
//Output as < word, 1 >
for (String word : words) {
//Take the word as the key and the number 1 as the value
context.write(new Text(word), new IntWritable(1));
}
}
}
Then go to the Reduce stage and create a class WordcountReduce:
/**
* KEYIN, VALUEIN, Type of keyout and valueout corresponding to mapper stage
*
* KEYOUT, VALUEOUT,Is the output data type of the reduce logic processing result
*
* KEYOUT Is a word of type Text
* VALUEOUT Is the total number of times, and the type is IntWritable
*/
public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
//Number addition
for (IntWritable value : values) {
count += value.get();
}
//Output < words, total times >
context.write(key, new IntWritable(count));
}
}
Finally, create a class WordCount to provide an entry:
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//Specify the local path where the jar package of this program is located, and submit the jar package to yarn
job.setJarByClass(WordCount.class);
/*
* Tell the framework which class to call
* Specify the mapper/Reducer business class to be used in this business job
*/
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReduce.class);
/*
* Specifies the type of mapper output data
*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Specifies the kv type of final output data
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Specify the directory where the job's input file is located
FileInputFormat.setInputPaths(job, new Path(args[0]));
// Specify the directory where the output of the job is located
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean completion = job.waitForCompletion(true);
System.exit(completion ? 0 : 1);
}
}
That's it. Next, use maven to package it into a jar package and upload it to the server where hadoop is deployed.

Upload files to hadoop
Then upload the text file that needs to count words to hadoop. Here I take a redis configuration file (enough words, ha ha) and upload it.
First change the name to input Txt, then upload it to / usr/local/hadoop-3.2.2/input directory with ftp tool, and then create / user/root folder in Hadoop.
hdfs dfs -mkdir /user hdfs dfs -mkdir /user/root hadoop fs -mkdir input //Upload files to hdfs hadoop fs -put /usr/local/hadoop-3.2.2/input/input.txt input //After the upload is successful, you can use the following command to view it hadoop fs -ls /user/root/input
Execution procedure
The first step is to start hadoop and use the command in sbin directory/ start-all.sh, after successful startup, use jps to view the following processes.
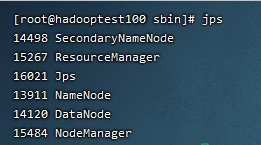
Execute the following command to execute the jar package:
hadoop jar /usr/local/hadoop-3.2.2/jar/hadooptest-1.0-SNAPSHOT.jar WordCount input output # /usr/local/hadoop-3.2.2/jar/hadooptest-1.0-SNAPSHOT.jar indicates the location of the jar package # WordCount is the class name # Input is the folder where the input file is located # Output output folder

This indicates that the operation is successful. We open the web management interface and find the output folder.
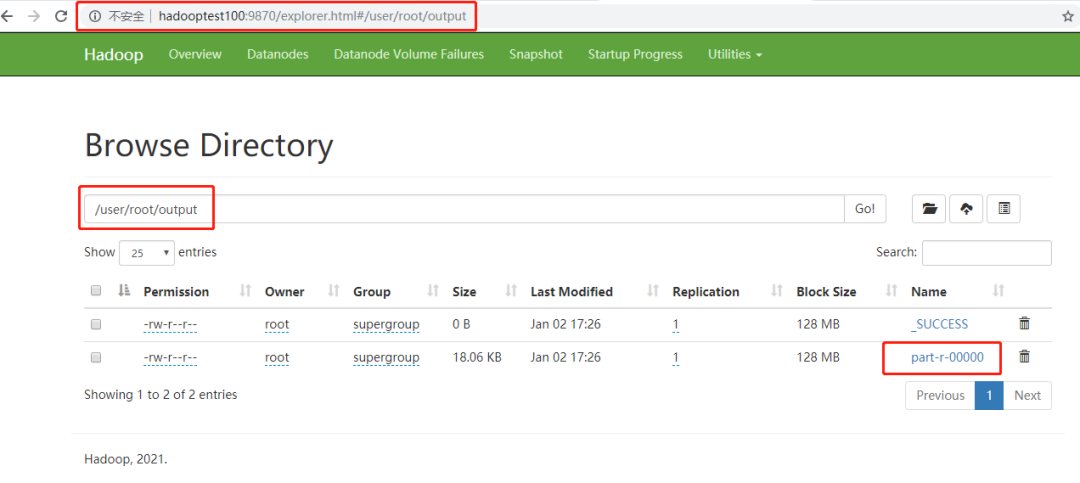
The output result is this file. Download it.

Then open the file and you can see the statistical results. The following screenshot is part of the results:

Problems encountered
If the Running Job does not respond, change mapred site XML file content:
Before change:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
After change:
<configuration>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://192.168.1.4:8001</value>
<final>true</final>
</property>
</configuration>
Then restart hadoop and execute the command to run the jar package task.
summary
WordCount is equivalent to the HelloWord program of big data. It is very helpful for beginners to learn the basic operation of MapReduce and build the environment through this example. Next, I will continue to learn about big data. I hope this article will be helpful to you.