Learn Mysql from scratch - character set and encoding (Part 2)
introduction
This series of articles is based on the personal notes summary column of "how MySQL works: understanding MySQL from the root". It is highly recommended that you read this book carefully. It is also one of the few good books that tell the principle of MySQL. Well, no more nonsense, let's get to the point.
Part I: Learn Mysql from scratch - character set and encoding (Part 1)
Since this series involves a lot of knowledge points, here is a personal mind map based on the knowledge points of the article: Screen address
Review part I
Because there is a long time between the last article and this one, let's review what we talked about in the last one:
In Mysql data, the size comparison of strings is essentially carried out in the following two ways. In short, the size comparison of strings depends on character sets and comparison rules.
- Convert the characters to uppercase or lowercase, and then make binary comparison
- Or encoding rules of different sizes can be encoded according to case
Briefly describe and master several commonly used character sets:
- ASCII character set: 128 characters,
- ISO 8859-1 character set: it is extended on the basis of ASCII character set, with a total of 256 characters. The character set is called latin1, which is also mysql5 The default character set before MySQL 8.0 (utf8mb4 after MySQL 8.0)
- GB2312: first of all, it should be noted that not only "Chinese characters" are used, but also variable length coding rules. The value of variable length coding rules is to encode different character sets according to the content of the string. For example, 'ah' in 'ah A' uses two byte coding, and 'A' can be represented by ASCII character set, so only one byte can be used for coding
- GBK character set: the character set of GB2312 is extended, and other encoding rules are consistent with GB2312
- UTF8 character set: UTF-8 specifies to encode according to the variable length encoding mode of 1-4 bytes. Finally, UTF8 is also compatible with ASCII character set like gbk
Tip: Here's a question to think about. What's the difference between UTF-8mb3 and UTF8-mb4 character sets? There is also a hole caused by a problem left over by history. If you mainly use Mysql database, it is necessary to carefully understand this hole. The answer is given at the end of the previous article, which will not be repeated here.
- Command to view character set: show charset;, For example: show charset like 'big%';
- View comparison rules: show collation [like matching pattern], such as show collation like 'utf#%';
There are four levels of character sets and comparison rules:
- Server level: it can be set through the configuration file, but the character set or comparison rule of server level cannot be modified after startup.
- Database level: if no database level comparison rule or character set is specified, the server's is used by default.
- Table level: table level uses database level character sets and comparison rules by default.
- Column level: column level rules are rarely used. They are usually specified when creating a table, but it is generally not recommended to use columns with different character sets in the same table.
- Finally, let's review common commands for character sets and comparison rules.
| Database level | View character set | View comparison rules | System variable | Modification / creation method | case |
|---|---|---|---|---|---|
| Server level | show variables like 'character_set_server'; | SHOW VARIABLES LIKE 'collation_server' | character_set_server Collation: current server comparison rule_ Server: current server comparison rule | Modify profile [server] character_set_server=gbk collation_server=gbk_chinese_ci | CREATE DATABASE charset_demo_db CHARACTER SET gb2312 COLLATE gb2312_chinese_ci; |
| Database level | show variables like 'character_set_database'; | show variables LIKE 'collation_database'; | character_set_database: current database character set collision_ Database: current database comparison rule | alter database database name [[DEFAULT] CHARACTER SET character set name] [[DEFAULT] COLLATE comparison rule name]; | CREATE DATABASE charset_demo_db CHARACTER SET gb2312 COLLATE gb2312_chinese_ci; |
| Table level | show table status from 'database name' like 'data table name' | SELECT TABLE_SCHEMA, TABLE_NAME,TABLE_COLLATION FROM INFORMATION_SCHEMA.TABLES where TABLE_NAME = 'data table name' | The level setting of the default reference database when it is not set | CREATE TABLE table name (column information) [[DEFAULT] CHARACTER SET character set name] [COLLATE comparison rule name]] ALTER TABLE table name [[DEFAULT] CHARACTER SET character set name] [COLLATE comparison rule name] | create table test( id int auto_increment primary key ) character set utf8mb4 COLLATE utf8mb4_0900_ai_ci |
| Column level | show full columns from admin like 'username'; | show full columns from admin like 'username'; | If not set, the level setting of the default reference data table | CREATE TABLE table name( Column name string type [CHARACTER SET name] [COLLATE comparison rule name], other columns ); ALTER TABLE t MODIFY col VARCHAR(10) CHARACTER SET gbk COLLATE gbk_chinese_ci; |
Article purpose
Before introducing the main body, this paper summarizes the main content in advance.
- Why is there garbled code during mysql query? Understand the context through a simple query.
- How do different operating systems get the system character set?
- Details of character set conversion rules for a Sql request (key points)
- Discussion on the comparison differences of strings under different comparison rules and the supplement of some default rules of mysql.
Version Description
In order to prevent readers from misunderstanding, here is the basic operating environment of this article:
- mysql version number: 8.0.26
- Operating system: MacOs M1 2020
How did the garbled code in the query come from?
In the world of random code, there is a very classic word: "Kun Jin copy". Here is an encyclopedia introduction to "Kun Jin copy":
It's a list of things you often see on search engine pages and other websites Garbled code Character. Garbled code comes from GBK Character set and Unicode Conversion between character sets. In addition to the Kun Jin copy, there are two groups of classic garbled codes, namely "hot" and "tuntuntun". These two garbled codes are generated from VC, which is the initialization operation of VC to memory in the debug mode.
The essence of garbled code is that the encoding method and decoding method of string are not unified. For example, in the case of UTF8 encoding, the character "I" will be translated into "æ" in other character sets ˆ‘”, Because the "I" of UTF8 uses a three byte encoding, when my character is converted to another encoding, there will be a problem because different character sets are parsed into different characters. Reading and encoding do not use the same method.
How to get the system character set?
Obtaining the character set of the system needs to be explained for different operating systems. Let's briefly mention that since mysql is basically deployed to the linux system, let's take a look at the character set of the linux operating system (see below using macos):
shell> echo $LC_ALL zh_CN.UTF-8 shell> echo $LC_CTYPE shell> echo $LANG
The priority of these three variables is: $LC_ALL>$LC_ Ctype > $Lang, the result shows that it is only $LC_ALL is valuable. There is no doubt that it is used as a reference. Here readers may ask: if $LC_ What if all has no value? In this case, the default character set of the operating system will be used.
The following is how to understand the character set in the windows system. In the windows operating system, the character set is also called code page, which means that a character set corresponds to a unique character set. For example, 936 represents GBK and 65001 represents UTF-8. Finally, we can view it in the windows window chcp. Because there are few mysql scenarios on Linux, it will not be demonstrated here.
The function of Linux bottom layer to obtain the character set is: nl_langinfo(CONDESET), windows: GetConsoleCP. If you are interested, you can learn about it.
Encoding history of a request
As we all know, the request of mysql is nothing more than sending an sql statement. After receiving the command, the server will filter and sort out the data, and finally encode and return the result. This transmission process is essentially the transmission of string and string, and the essence of string is just the specific coding rules of a segment of bytes, which are easy to understand after translation, In addition, as long as you know the data row storage rules of mysql, you will know that a data row actually stores a segment of byte code. Taking innodb as an example, you can simply think that all the data types we store are actually strings, and the text content will be processed differently according to the character set of the system, So here comes a problem. Our characters are encoded at the request of the client. How does the server decode and return them to the client? Or is there a set of internal conversion rules after it is sent to the mysql application? Let's take a look at the actual transmission process of a request:
Before the specific description, let's first understand why it is not recommended to use tools such as navicat to process the rules of verification request coding in the book. Here we can understand through practical operation:
First, we create a database through the tool navicat, and specify the character set and comparison rules when creating it.
Note: it should be noted that utf8 is utf8mb3 at this time

Then we build a simple table with only id and name columns.
CREATE TABLE `test` ( `id` int NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `name` varchar(255) DEFAULT NULL COMMENT 'name', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='Test character set and encoding';
Then we insert a piece of data:
INSERT INTO `test`.`test` (`id`, `name`) VALUES (1, 'I');
Finally, we can execute an sql statement to test. Of course, there will be no problem, but here we can play some tricks, such as changing the character set and code to the following form. At this time, you will find that you can insert Chinese or any data as usual. Why? In fact, you can see the clue by looking at the DLL table creation statement corresponding to Navicat.

-- DDL Create table statement CREATE TABLE `test` ( `id` int NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `name` varchar(255) CHARACTER SET gbk COLLATE gbk_chinese_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1 COMMENT='Test character set and encoding';
You can see that if you randomly modify the character set of the table, the character set of the column will choose a compatible scheme according to the stored content. For example, gbk encoding format is used here for processing. However, if you modify the character set of the column through the following statement, you will find that this statement cannot be executed.
ALTER TABLE test MODIFY name VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci; -- Error reporting: 1366 - Incorrect string value: '\xCE\xD2\xCA\xC7' for column 'name' at row 1, Time: 0.004000s
Through the above case, we can see that navicat "secretly" does a lot of operations in the details. If it is not for understanding the underlying processing, it is certainly very convenient, but if we want to know the processing flow of the character set, we have to break away from the visualization tool and use the command line to operate.
Let's use the command line to see how to operate. In fact, the conversion rules of character set and encoding are very simple. You can understand them with one command. From the results, you can see that 9 variables are involved, and some look similar. For example, what is the difference between client and connection? In addition, you can also see the storage location of the character set from the following contents. Because individuals use MacOS for experiments, the storage location is / usr/local/mysql-8.0.26-macos11-arm64/share/charsets /. It is suggested that readers can connect to their own database to see the configuration.
mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.00 sec)
The processing flow of a request is still cumbersome. In order to simplify the introduction, we can explain it by drawing pictures. We can directly look at the following figure:

Here we need to pay attention to character_set_client,character_set_connection,character_ set_ The three parameters of results are Session level, which means that each client connection maintains its own character set, which is why character is set_ set_ The meaning of the parameter client. In addition, if Mysql does not support the character set of the current operating system, the character set of the client will be set as the default character set of Mysql. We can understand the conversion of the character set of the client through the following example diagram.
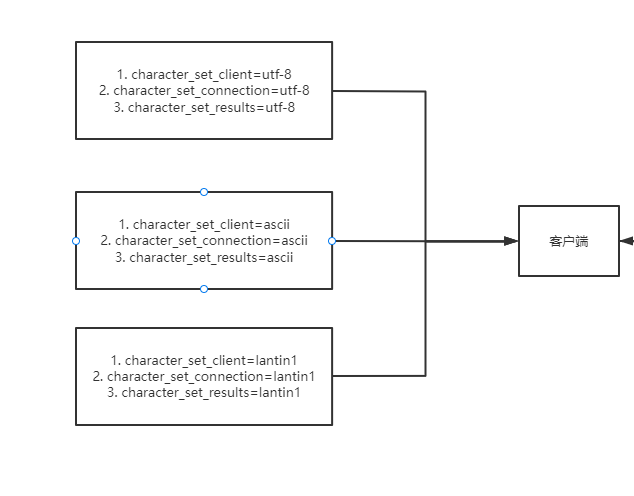
Tip: mysql5 7 (included) and earlier versions used latin1 as the default character set, mysql8 The default character set after 0 is utf8mb4.
From the above figure, we can basically understand the following information:
- If character_ set_ The character set after results conversion is different from the character set of the operating system, so it is likely to have the possibility of garbled code.
- No matter what form of coding the client uses, it will eventually be converted to character_set_connection, although character_set_connection seems useless, but if character_set_connection and character_ set_ The client character set is inconsistent, which may cause a warning in Mysql because it cannot be encoded.
- If the character set used by the client and the character used by the server_ set_ If the client character set is inconsistent, it is likely that the server cannot understand the client request
- The conversion of a requested character set will be completed twice during the interaction between the client and the server, and three times within the server. It seems very cumbersome, so remember three key parameters.
Now let's experiment with possible garbled codes on the above:
The first is the most intuitive problem, which is also the most likely problem to occur when using mysql in windows operating system. That is, we may garbled the query results. Here, we test according to the table mentioned in the above experiment. We can see the effect by directly modifying the character set of results:
mysql> set character_set_results=latin1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb3 | | character_set_filesystem | binary | | character_set_results | latin1 //Modified| | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.00 sec) mysql> select * from test; +----+------+ | id | name | +----+------+ | 1 | ?? | | 2 | ? | +----+------+ 2 rows in set (0.00 sec)
Next, let's try if character_set_client and character_ set_ What's wrong with different connections,
mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | latin1 | | character_set_connection | ascii | | character_set_database | utf8mb3 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.01 sec) mysql> set character_set_client=utf8mb4; Query OK, 0 rows affected (0.00 sec) mysql> select * from test; +----+------+ | id | name | +----+------+ | 1 | ?? | | 2 | ? | +----+------+ 2 rows in set (0.00 sec) mysql> select * from test where name= 'I'; Empty set, 1 warning (0.01 sec) //==========Note that the key point is here=========== mysql> show warnings; +---------+------+------------------------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------------------------+ | Warning | 1300 | Cannot convert string '\xE6\x88\x91' from utf8mb4 to ascii | +---------+------+------------------------------------------------------------+ 1 row in set (0.00 sec)
We set the client to latin1 and the connection to ascii. From the error report, we can see that although there is no problem when we conduct basic query, the error report will appear once the character set is set to the server. Therefore, when setting the configuration of these three parameters of mysql, we must configure them to the same character set, Otherwise, this error may not be so easy to find. (of course, it is easy to find problems in this case)
Finally, let's try how to make the server unable to understand the client's request. In fact, it's relatively simple to make the character set range used by the server smaller than that used by the client. For example, set the client to uft8 and the server to ascii. Let's try the same below to avoid too much code, Here, we omit other commands to modify the character set and directly view the results. What this string of English tells us is that the two character sets cannot be compared, which means that the server cannot understand the client request as mentioned above:
mysql> select * from test where name ='I'; ERROR 1267 (HY000): Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (ascii_general_ci,COERCIBLE) for operation '='
After the experiment of the above content is completed, at this time, we will want to modify the character set. We can find that the character set we mainly use is character_set_client,character_set_connection,character_set_results, it is troublesome to change these three character sets one by one. Mysql also takes this problem into account, so it also provides a shortcut command: set name character set (in fact, this command is easy to misunderstand). The effect of the command is roughly the same as the following command:
SET character_set_client = Character set name; SET character_set_connection = Character set name; SET character_set_results = Character set name; // Equivalent to set name character set
An interesting thing happened during the personal story operation. When setting the character set, mysql gave a prompt that the character set will be changed to by default when setting the utf8 character set; utf8mb4.
mysql> set names utf8;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 3719 | 'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8MB4 in a future release. Please consider using UTF8MB4 in order to be unambiguous. |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> set character_set_client=utf8
-> ;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 3719 | 'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8MB4 in a future release. Please consider using UTF8MB4 in order to be unambiguous. |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Another method is to configure in the configuration file. Of course, this is for the configuration parameters started by the whole server. Generally, it is recommended to display the configuration to avoid unnecessary trouble:
[client] default-character-set=utf8
After so much wordy content, we can actually summarize it in one sentence: we usually put character_set_client,character_set_connection,character_ set_ The three system variables results are set to be consistent with the character set used by the client, which reduces a lot of unnecessary character set conversion. It's that simple. As long as you set it like this, there won't be so many strange character sets and comparison rules.
Impact of comparison rules
Having finished the character set, let's talk about the comparison rules. Previously, the character set affects the content display of the string, so the comparison rules affect the character comparison operation, and the comparison operation affects the string comparison and sorting operation. In order to illustrate the impact on the comparison rules, Here we also use a simple case to understand and introduce:
Supplement: the design of comparison rules is more intuitive than the setting of character set, which is divided into three variables: collation_connection,collation_database,collation_server, as the name implies, can be divided into connection level, database level and server level. The usage rules of comparison rules are shown in Learn Mysql from scratch - character set and encoding (Part 1) After discussion, it will not be carried out here:
mysql> show variables like 'collation_%';
+----------------------+--------------------+
| Variable_name | Value |
+----------------------+--------------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8mb4_0900_ai_ci |
+----------------------+--------------------+
According to the above table, we insert several random data first:
INSERT INTO `test`.`test` (`id`, `name`) VALUES (1, 'I am'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (2, 'I'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (3, 'I'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (4, 'ABCD'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (5, 'A'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (6, 'a'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (7, 'B'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (8, 'c');
Then let's query and sort according to the order of names. Here, you can check the current comparison rules before execution:
mysql> show variables like 'collation_%'; +----------------------+--------------------+ | Variable_name | Value | +----------------------+--------------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8mb4_0900_ai_ci | +----------------------+--------------------+ 8 rows in set (0.01 sec) > select * from test order by name desc; 1 I am 2 I 3 I 8 c 7 B 4 ABCD 5 A 6 a
Finally, we can try to change the character set to other character sets, and then look at the sorting results. We can see that the sorting results have changed:
Remarks: gbk_bin is a code that directly compares characters, so it is case sensitive
ALTER TABLE test MODIFY name VARCHAR(255) COLLATE gbk_bin; 1 I am 2 I 3 I 8 c 6 a 7 B 4 ABCD 5 A
This is easy to understand. The comparison rules of different character sets are different, but how does Mysql distinguish between the following comparison operations?
select 'a' = 'A'
Whether the result is right or wrong depends on two parameters. The first parameter is character_set_connection, which is responsible for specifying the actual character set to be converted from the client to the server. The other parameter is collision_ Connection, which is responsible for setting the comparison rules of the current character set, so you can change the above query results by changing these two values. Here, you can also try to modify them according to the above experiment. There is no demonstration here, so the result may be 1 or 0 (isn't this nonsense!).
Another case is if character_ set_ The character set of connection is gbk, while the character set and comparison rules used by the data column of a table are utf8. Who should prevail at this time? There is also a hard and fast rule here: by default, the rules of the character set specified in the Mysql column will prevail, which also means that if utf8 is used for comparison, gbk will be converted to utf8 first, and then the comparison will be carried out. Of course, no one is idle about the character set of a column. It's just a small knowledge here. It doesn't matter if you can't remember it, When you actually step on the pit, just keep an eye on the data column and the character set of the system.
summary
Finally, to sum up, through this article, we know that a string itself is encoded through the character set. This article mainly understands how a request is processed by mysql. Its processing process is as follows:
- The request is first converted to character through the character set of the client_ set_ The character set of client is decoded, and then the string is passed through character_ set_ Code in the format of connection.
- If character_set_client and character_ set_ If the connection is consistent, proceed to the next step. Otherwise, you will try to remove the string in the request from character_ set_ The character set of connection is converted to the character set used by the column of specific operation. If the operation of converting to the character set of operation column still fails, the processing may be rejected.
- Convert the character set of a column to character_ set_ The character set encoding results of results are sent to the client at the same time. If the encoding sets of the client and results are inconsistent at this time, there will be garbled code.
- The client end uses the character set of the operating system to parse the byte string of the received result set.
As for the comparison rules, there are few details. Just remember that the comparison rules will affect the sorting of the content. If the sorting result of a query does not meet the expectation, you can start with the sorting rules to see whether the sorting rules can be adjusted to better meet the expected results.
Write at the end
There are still many details about the content of the character set in Mysql data. Personally, I also think that the transformation of the character set is a little around, so the knowledge points in this piece need to be reviewed more.