What is data storage
I really don't need to explain this. It is to save the crawled data. The data is stored in various forms, but it is mainly divided into two categories: one is simply saved as text files, such as txt, json, csv, etc., and the other is saved to databases, such as MySQL, MongoDB, Redis, etc. Next, let's learn these methods~
preparation
Before learning data storage, we need to crawl the data first. I won't write this part of the code here. I will directly use the code demonstration of crawling watercress in front. If you don't understand, go back to my previous blog
Save as text
File opening method
tip: here is a parameter for file saving
| parameter | meaning |
|---|---|
| r | Open in read-only mode (default) |
| rb | Open as binary read-only (for audio, pictures, video) |
| r+ | Open file read-write |
| rb+ | Open as binary read / write |
| w | Open the file by writing (overwrite if the file exists, and create if it does not exist) |
| wb | Write in binary mode (overwrite if the file exists, and create if it does not exist) |
| w+ | Open the file in read-write mode (overwrite if the file exists, and create a new one if it does not exist) |
| wb+ | Open the file in binary read-write mode (overwrite if the file exists, and create if it does not exist) |
| a | Open file as append |
| ab | Open file as binary append |
| a+ | Open file read-write |
| ab+ | Append open file in binary |
Save as txt text
This should be the simplest way to save crawler data. Look at the code directly. Here, for convenience, I define all data saving as functions and call the corresponding functions to save.
# The first way to write:
# In this way, you need to define file equal to
def save_txt_2(mystr):
file = open('../Include/film-1.txt', 'a', encoding='utf-8')
file.write(mystr+'\n')
file.close()
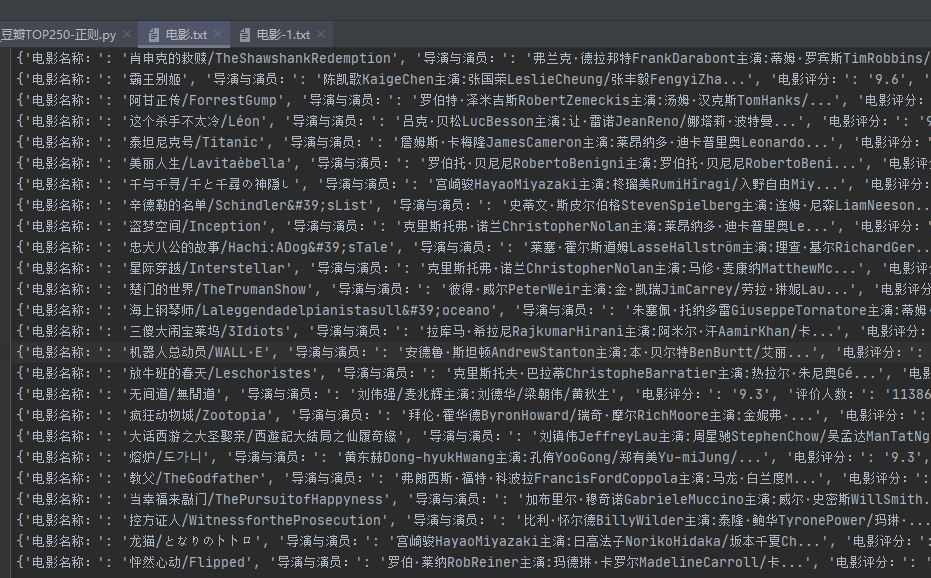
# The second way to write:
# This method simplifies a method and is generally used
# Save data as txt (short form)
def save_txt_1(mystr):
with open('../Include/film.txt', 'a', encoding='utf-8') as file:
file.write(f'{mystr}\n')

Save as JSON
json, as a common data storage format, is usually in the form of a key value pair wrapped in curly braces, such as the following data
{'name':'Zhang San', 'age':18, 'sex':'male'}
# The data is stored as json
def save_json(data):
with open('../Include/film.json', 'a', encoding='utf-8') as file:
file.write(f'{data}\n')

Save as CSV
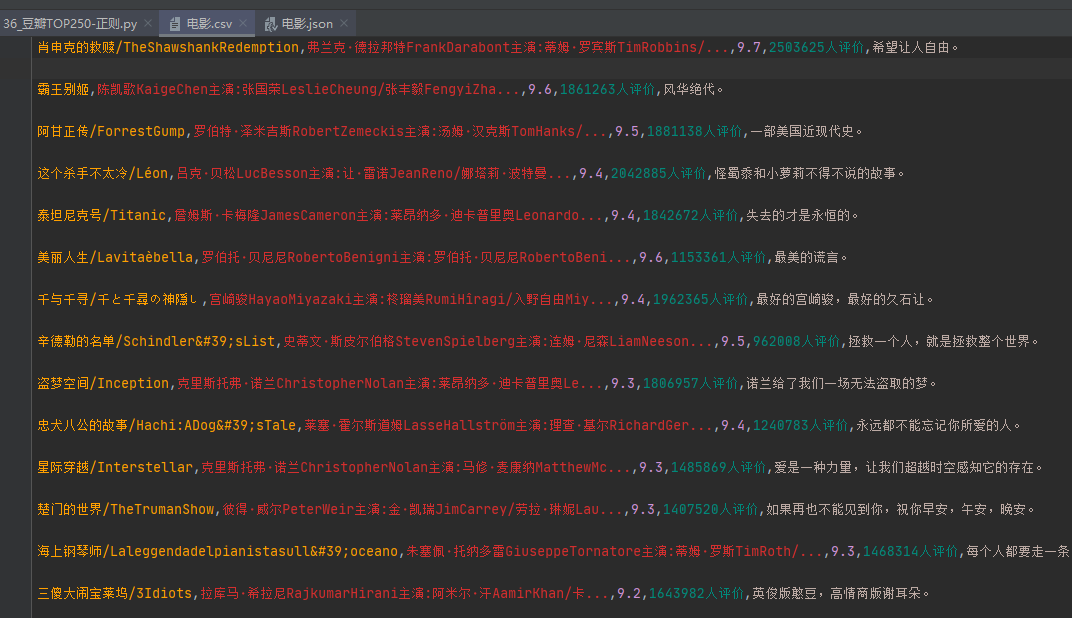
Comma separated values (CSV, sometimes called character separated values, because the separating character can also be not a comma), and its file stores table data in plain text (numbers and text). Plain text means that the file is a sequence of characters and does not contain data that must be interpreted like binary numbers. CSV files consist of any number of records separated by some line break; each record consists of fields separated by other characters or strings, most commonly commas or tabs.
Because we usually save data in the form of a dictionary in a crawler, here I will demonstrate how to store dictionary data as a csv file.
# Data is stored as csv
def save_csv(data):
with open('../Include/film.csv', 'a', encoding='utf-8') as file:
# Note that the fields in the fieldnames here must correspond to the keys in the dictionary you want to store, otherwise an error will be reported
fieldnames = ['Movie Title:', 'Director and actor:', 'Movie rating:', 'Number of evaluators:', 'Film summary:']
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
Save to database
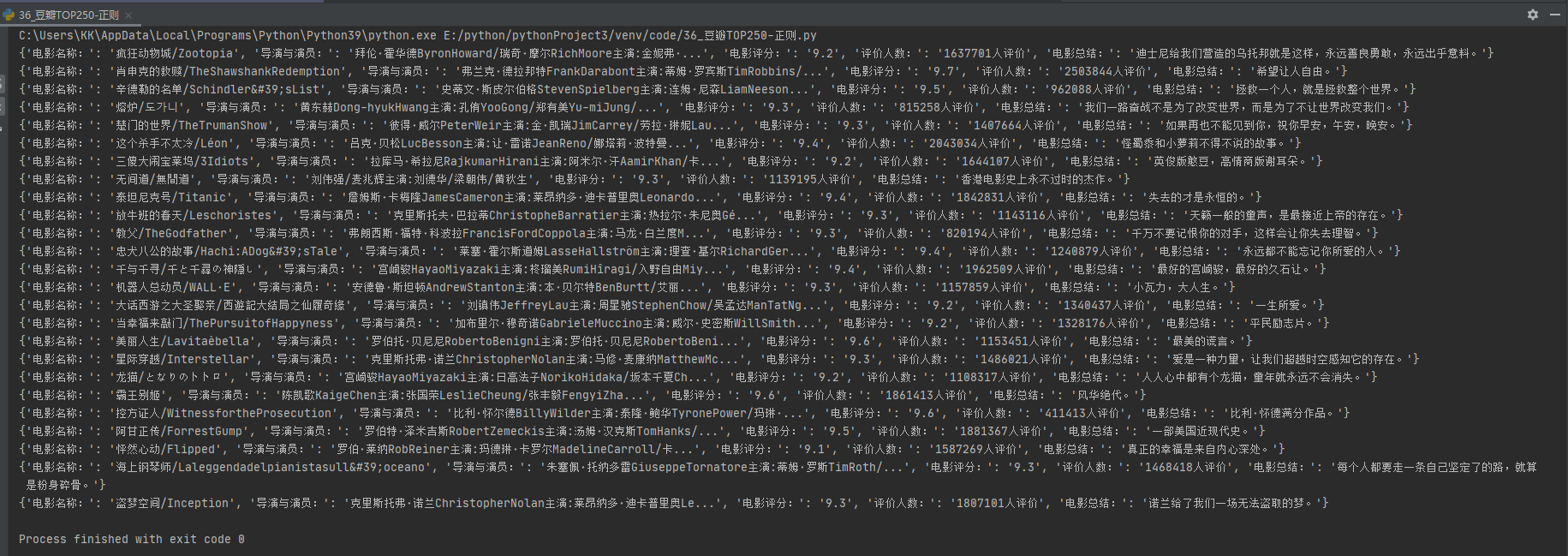
Save to MySQL
As an open source relational data, MySQL is deeply loved by developers, and we often use it in the process of crawler data storage.
Different from the previous text storage, we usually need to connect to the database before we can perform the storage operation. Here, I see a database named movies and a data table named movie in mysql in advance.
# Data storage to MySQL
def save_mysql(data):
# Establish connection
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3306, db='movies')
# Create cursor
cursor = db.cursor()
# sql statement
sql = "insert into movice(mname,director,score,allcount,summary) values (%s,%s,%s,%s,%s) "
# operation
data = (data['Movie Title:'], data['Director and actor:'], data['Movie rating:'], data['Number of evaluators:'], data['Film summary:'])
try:
cursor.execute(sql,data)
db.commit()
except Exception as e:
print('Failed to insert data', e)
db.rollback() # RollBACK
# Close cursor
cursor.close()
# Close connection
db.close()

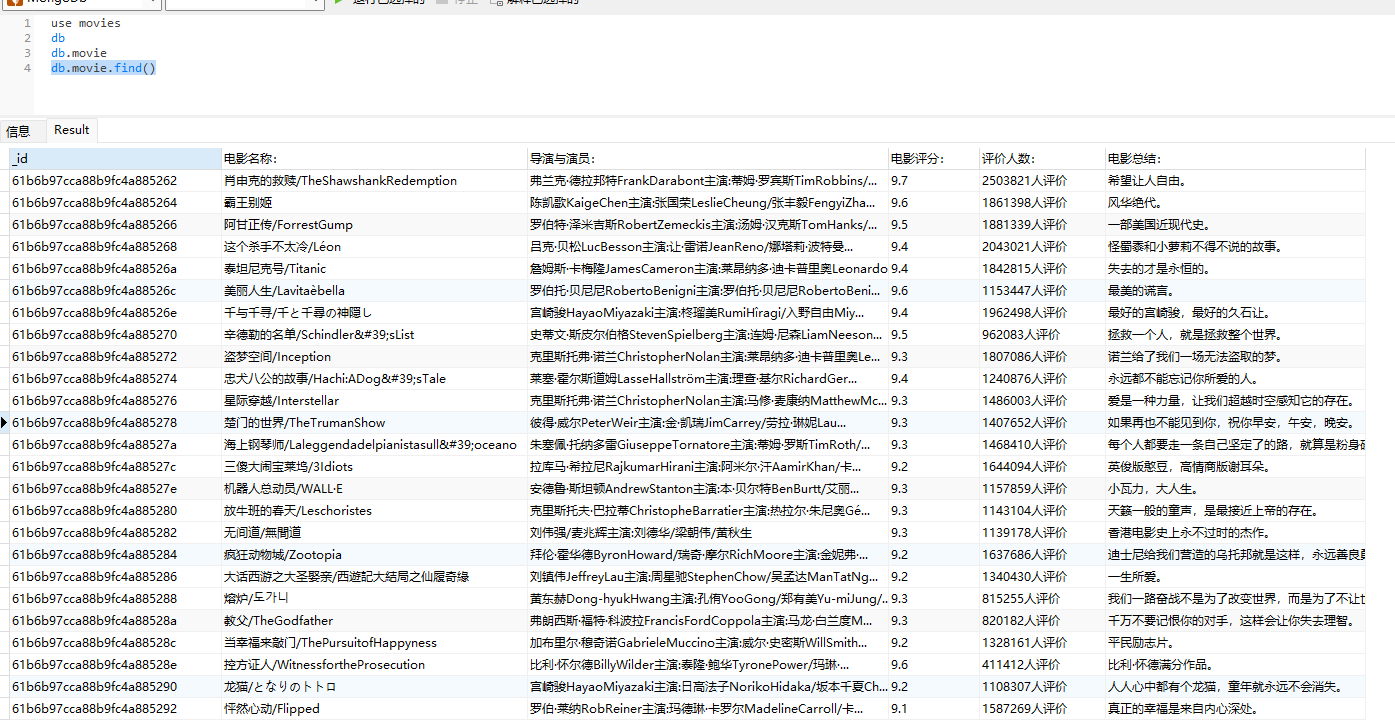
Save to MongoDB
MongoDB is a database based on distributed file storage. Written in C + +. It aims to provide scalable high-performance data storage solutions for WEB applications.
MongoDB is a product between relational database and non relational database. It is the most functional and relational database among non relational databases. The data structure it supports is very loose. It is a json like bson format, so it can store more complex data types. Mongo's biggest feature is that the query language it supports is very powerful. Its syntax is a little similar to the object-oriented query language. It can almost realize most of the functions similar to single table query in relational database, and it also supports indexing of data.
Like the database connection above, we need to connect to the database before storing data, and then execute the corresponding database statement to complete the operation.
# Store data to MongoDB
def save_mongo(data):
# Create database connection
client = pymongo.MongoClient(host='localhost', port=27017)
# Specify database
db = client.movies
# Specify collection
collection = db.movie
# Perform operation
result = collection.insert_one(data)
print(result)

Save to Redis
Redis (Remote Dictionary Server), i.e. remote dictionary service, is an open source log type key value database written in ANSI C language, supporting network, memory based and persistent, and provides API s in multiple languages. Redis is a high-performance key value database. The emergence of redis largely compensates for the shortage of key/value storage such as memcached, and can play a good supplementary role to relational databases on some occasions.
# Store data to Redis
def save_redis(data):
r = redis.Redis(host='localhost', port=6379, db=1, decode_responses=True, password='123456')
r.hset('movies', data['Movie Title:'], json.dumps(data))
# Reading Redis data
def read_redis():
r = redis.Redis(host='localhost', port=6379, db=1, decode_responses=True, password='123456')
for k in r.hkeys('movies'):
d = r.hget('movies', k)
print(json.loads(d))

summary
Through the above introduction, we have basically learned most methods of crawler data storage, which are often used in our actual production process. Some people will say that there are many other types of files, such as the xlsx format of tables and so on... But everyone who has used it should know that in fact, it is stored in the same way as csv. We only need to make small modifications to achieve it.
That's all for today. In the next issue, I will lead you to use our stored data for simple data analysis and data visualization.
Rush!!!!
author: KK
time: December 13, 2021 12:05:45
flag: 10/30