1. Title Description
2. Problem solving ideas
Intersection means to have a "global view" of the two arrays. One embodiment of the "global view" in the program is statistics. Therefore, I can use the hash table to count the occurrence times of each element in the two arrays, and then take the small value to build a new array.
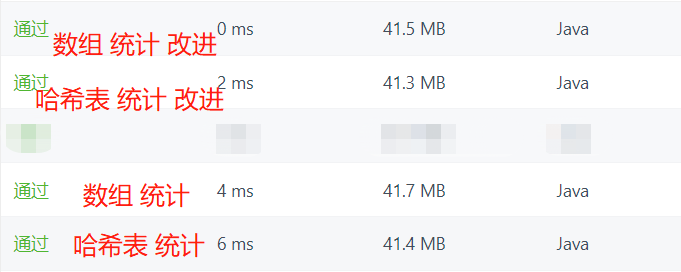
In the previous questions, it was found that the hash table actually has a great impact on the time performance. In some cases, using the array instead can greatly improve the running speed. The element range in the topic array is 0 to 1000, so I can build a 1001 length array to count the occurrence times of the corresponding subscript elements.
Although the method of using arrays instead of hash tables can improve efficiency, the data still doesn't look good enough. Is there a way for me to count the number of elements in only one array? In fact, we can count the array with the shortest length, then traverse another array, and build the return array while dynamically updating the hash table of the number of elements.
Since the idea of array instead of hash table is feasible, we can get a better solution in time by implementing the above idea with array.
3. Code implementation
3.1 hash table statistics
public int[] intersect(int[] nums1, int[] nums2) {
ArrayList<Integer> list = new ArrayList<>();
Hashtable<Integer, Integer> count1 = count(nums1);
Hashtable<Integer, Integer> count2 = count(nums2);
Set<Integer> keySet = count1.keySet();
for (Integer integer : keySet) {
if(count2.containsKey(integer)){
int value = count1.get(integer)<count2.get(integer)?count1.get(integer):count2.get(integer);
for (int i = 0; i < value; i++) {
list.add(integer);
}
}
}
return list.stream().mapToInt(Integer::valueOf).toArray();
}
public Hashtable<Integer, Integer> count(int[] nums){
Hashtable<Integer, Integer> hashtable = new Hashtable<>();
for (int num : nums) {
if(hashtable.putIfAbsent(num,1)!=null) {
hashtable.put(num, hashtable.putIfAbsent(num, 1) + 1);
}
}
return hashtable;
}
3.2 array statistics
public int[] intersect(int[] nums1, int[] nums2) {
ArrayList<Integer> list = new ArrayList<>();
int[] count1 = count(nums1);
int[] count2 = count(nums2);
for (int i = 0; i < count1.length; i++) {
for (int j = 0; j < Math.min(count1[i], count2[i]); j++) {
list.add(i);
}
}
return list.stream().mapToInt(Integer::valueOf).toArray();
}
public int[] count(int[] nums) {
int[] c = new int[1001];
for (int num : nums)
c[num] = c[num] + 1;
return c;
}
3.3 improvement of hash table statistics
public int[] intersect(int[] nums1, int[] nums2) {
if (nums2.length < nums1.length)
return intersect(nums2, nums1);
HashMap<Integer, Integer> map = new HashMap<>();
for (int i : nums1) {
map.put(i, map.getOrDefault(i, 0) + 1);
}
int[] ans = new int[nums1.length];
int index = 0;
for (int i : nums2) {
if (map.containsKey(i)) {
ans[index++] = i;
if (map.get(i) == 1)
map.remove(i);
else
map.put(i, map.get(i) - 1);
}
}
return Arrays.copyOfRange(ans, 0, index);
}
3.4 improvement of array statistics
public int[] intersect(int[] nums1, int[] nums2) {
if (nums2.length < nums1.length)
return intersect(nums2, nums1);
int[] count = new int[1001];
for (int i : nums1) {
count[i]++;
}
int[] ans = new int[nums1.length];
int index = 0;
for (int i : nums2) {
if (count[i] > 0) {
ans[index++] = i;
count[i]--;
}
}
return Arrays.copyOfRange(ans, 0, index);
}
Although the spatial performance is general, this is the solution with the best time performance.
3.5 comparison
In the first and second methods, it seems that nested loops are used, but in fact, the purpose of the nested loop is to build the return array. Its time complexity is linear, so the time complexity of the four methods is O(n). In terms of space complexity, the hash table method is O(n), while the array method is O(1), but in fact, for the actual space, the hash table will occupy less space, because n must be less than or equal to the constant 1001.