Huawei's shengteng training chip has always been what we are looking forward to. At present, it has begun to provide public test. How to run a training task on the shengteng training chip is a process that many people are in the pit at present. So I wrote a guidance article with all relevant source codes attached. Note that this article does not include the installation of the environment, please check other related documents.
Environmental constraints: Currently, the shengteng 910 only supports tensorflow version 1.15.
After the basic image is uploaded, we need to start the image command. The following command mounts 8 cards (all cards of a single machine):
docker run -it --net=host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /var/log/npu/slog/container/docker:/var/log/npu/slog -v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/tools/:/usr/local/Ascend/driver/tools/ -v /data/:/data/ -v /home/code:/home/local/code -v ~/context:/cache ubuntu_18.04-docker.arm64v8:v2 /bin/bash
Set the environment variable and start the handwriting training network:
#!/bin/bash export LD_LIBRARY_PATH=/usr/local/lib/:/usr/local/HiAI/runtime/lib64 export PATH=/usr/local/HiAI/runtime/ccec_compiler/bin:$PATH export CUSTOM_OP_LIB_PATH=/usr/local/HiAI/runtime/ops/framework/built-in/tensorflow export DDK_VERSION_PATH=/usr/local/HiAI/runtime/ddk_info export WHICH_OP=GEOP export NEW_GE_FE_ID=1 export GE_AICPU_FLAG=1 export OPTION_EXEC_EXTERN_PLUGIN_PATH=/usr/local/HiAI/runtime/lib64/plugin/opskernel/libfe.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libaicpu_plugin.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libge_local_engine.so:/usr/local/H iAI/runtime/lib64/plugin/opskernel/librts_engine.so:/usr/local/HiAI/runtime/lib64/libhccl.so export OP_PROTOLIB_PATH=/usr/local/HiAI/runtime/ops/built-in/ export DEVICE_ID=2 export PRINT_MODEL=1 #export DUMP_GE_GRAPH=2 #export DISABLE_REUSE_MEMORY=1 #export DUMP_OP=1 #export SLOG_PRINT_TO_STDOUT=1 export RANK_ID=0 export RANK_SIZE=1 export JOB_ID=10087 export OPTION_PROTO_LIB_PATH=/usr/local/HiAI/runtime/ops/op_proto/built-in/ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/fwkacllib/lib64/:/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver/:/usr/local/Ascend/add-ons/ export PYTHONPATH=$PYTHONPATH:/usr/local/Ascend/opp/op_impl/built-in/ai_core/tbe export PATH=$PATH:/usr/local/Ascend/fwkacllib/ccec_compiler/bin export ASCEND_HOME=/usr/local/Ascend export ASCEND_OPP_PATH=/usr/local/Ascend/opp export SOC_VERSION=Ascend910 rm -f *.pbtxt rm -f *.txt rm -r /var/log/npu/slog/*.log rm -rf train_url/* python3 mnist_train.py
In the following training cases, I used master lecun's LeNet-5 network. First, I briefly introduced the LeNet-5 network:
LeNet5 was born in 1994. It is one of the earliest convolutional neural networks and promotes the development of deep learning. Since 1988, after years of research and many successful iterations, this pioneering achievement completed by Yann LeCun has been named LeNet5.
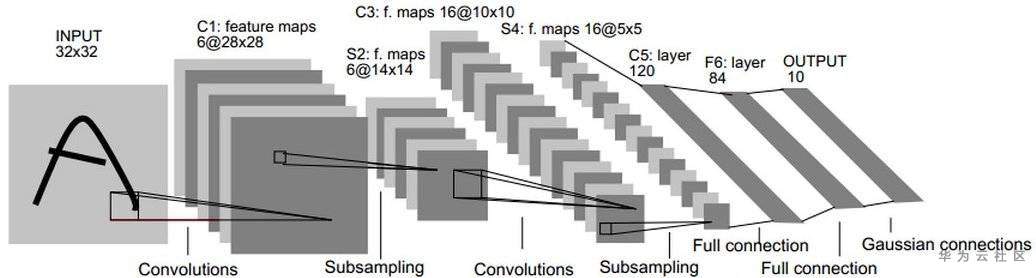
LeNet-5 contains seven layers, excluding input. Each layer contains trainable parameters (weights). At that time, the input data used was 32 * 32 pixel image. Next, we will introduce the structure of LeNet-5 layer by layer, and the convolution layer will be represented by Cx, the subsampling layer will be marked as Sx, and the fully connected layer will be marked as Fx, where x is the layer index.
Layer C1 is a convolution layer with six 5 * 5 convolution kernels. The size of the feature map is 28 * 28, which can prevent the information of the input image from falling out of the convolution kernel boundary. C1 contains 156 trainable parameters and 122304 connections.
Layer S2 is a subsampling/pooling layer that outputs six characteristic graphs of 14 * 14 size. Each unit in each feature map is connected to 2 * 2 neighborhoods in the corresponding feature map in C1. The four inputs of the unit in S2 are added, multiplied by the trainable coefficient (weight), and then added to the trainable bias (bias). The results are transferred by S-function. Because 2 * 2 receptive domains do not overlap, the number of rows and columns in S2 is only half of that in C1. S2 layer has 12 trainable parameters and 5880 connections.
Layer C3 is a convolution layer with 16 convolution kernels of 5-5. The input of the first six C3 feature graphs is each continuous subset of the three S2 feature graphs, the input of the next six feature graphs is from the input of the four continuous subsets, and the input of the next three feature graphs is from the four discontinuous subsets. Finally, the input of the last feature map comes from all S2 feature maps. C3 layer has 1516 trainable parameters and 156000 connections.
Layer S4 is similar to S2, with a size of 2 * 2 and an output of 16 5 * 5 characteristic graphs. S4 layer has 32 trainable parameters and 2000 connections.
Layer C5 is a convolution layer with 120 convolution kernels of size 5 * 5. Each unit is connected to 5 * 5 neighborhoods on all 16 characteristic graphs of S4. Here, because the size of S4's characteristic graph is also 5 * 5, the output size of C5 is 1 * 1. So S4 and C5 are completely connected. C5 is marked as a rollup layer, not a fully connected layer, because if the LeNet-5 input becomes larger and its structure remains unchanged, its output size will be greater than 1 * 1, that is, it is not a fully connected layer. C5 layer has 48120 trainable connections.
F6 layer is fully connected to C5, and 84 feature maps are output. It has 10164 trainable parameters. Here 84 is related to the design of the output layer.
The design of LeNet is relatively simple, so its ability to process complex data is limited; in addition, in recent years, many scholars have found that the computing cost of the full connection layer is too high, and use the neural network composed of all the convolution layers.
LeNet-5 network training script is mnist_train.py , specific code:
import os import numpy as np import tensorflow as tf import time from tensorflow.examples.tutorials.mnist import input_data import mnist_inference from npu_bridge.estimator import npu_ops #Import NPU operator Library from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig #Rewrite the configuration in tensorFlow for NPU batch_size = 100 learning_rate = 0.1 training_step = 10000 model_save_path = "./model/" model_name = "model.ckpt" def train(mnist): x = tf.placeholder(tf.float32, [batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels], name = 'x-input') y_ = tf.placeholder(tf.float32, [batch_size, mnist_inference.num_labels], name = "y-input") regularizer = tf.contrib.layers.l2_regularizer(0.001) y = mnist_inference.inference(x, train = True, regularizer = regularizer) #reasoning process global_step = tf.Variable(0, trainable=False) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, 1)) #loss function cross_entropy_mean = tf.reduce_mean(cross_entropy) loss = cross_entropy_mean + tf.add_n(tf.get_collection("loss")) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step = global_step) #Optimizer call saver = tf.train.Saver() #Start training #The following code is necessary for NPU to start configuration of parameters config = tf.ConfigProto( allow_soft_placement = True, log_device_placement = False) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True #custom_op.parameter_map["profiling_mode"].b = True #custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes("task_trace:training_trace") config.graph_options.rewrite_options.remapping = RewriterConfig.OFF #End of configuration parameters writer = tf.summary.FileWriter("./log_dir", tf.get_default_graph()) writer.close() #Parameter initialization with tf.Session(config = config) as sess: tf.global_variables_initializer().run() start_time = time.time() for i in range(training_step): xs, ys = mnist.train.next_batch(batch_size) reshaped_xs = np.reshape(xs, (batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels)) _, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:reshaped_xs, y_:ys}) #Print loss function output log every 10 epoch s trained if i % 10 == 0: print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10) print("After %d training steps, loss on training batch is %g, total time in this 1000 steps is %s." % (step, loss_value, time.time() - start_time)) #saver.save(sess, os.path.join(model_save_path, model_name), global_step = global_step) print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10) start_time = time.time() def main(): mnist = input_data.read_data_sets('MNIST_DATA/', one_hot= True) train(mnist) if __name__ == "__main__": main()
This paper mainly describes the LeNet-5 network model of the classic convolutional neural network and the implementation of the migration to shengteng D910. I hope you can try it quickly!
Click here to learn about Huawei's new cloud technology for the first time~