DocArray is a library recently released by Jina AI and suitable for nested and unstructured data transmission. This paper will demonstrate how to use DocArray to build a simple clothing search engine.
Good luck to start work. Hello, everyone!

We have carefully prepared a Demo and out of the box tools for you. In the new year, let's use this invincible buff to solve the headache of unstructured data transmission~
DocArray: a necessary library for deep learning engineers
DocArray: The data structure for unstructured data.
DocArray is an extensible data structure that perfectly adapts to deep learning tasks. It is mainly used for the transmission of nested and unstructured data. The supported data types include text, image, audio, video, 3D mesh, etc.
Compared with other data structures:
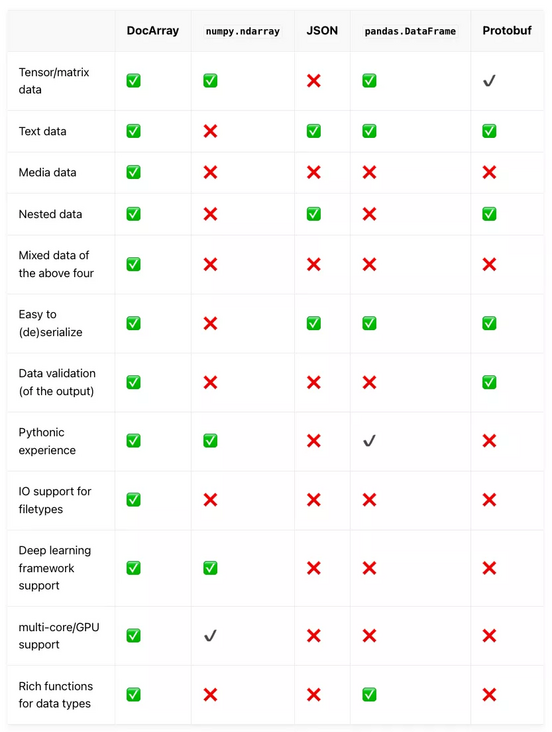
✅ Expressed full support, ✔ Expressed partial support, ❌ Indicates that it is not supported
With DocArray, deep learning engineers can effectively process, embed, search, recommend, store and transmit data with the help of Python API.
In the following tutorial examples, you will learn:
- Build a simple clothing search system with DocArray;
- Upload clothing pictures and find similar matches in the dataset
Note: all codes in this tutorial can be found in GitHub Download.
Teach you to build a clothing search system
Preparation: watch DocArray video
If you can't buy it in 5 minutes, you won't be fooled. On the contrary, it will remove the knowledge barrier and prepare for the next steps.
In the online translation of wild subtitle Jun, the Chinese subtitle video is expected to be released this week. For the English video, see Here.
from IPython.display import YouTubeVideo
YouTubeVideo("Amo19S1SrhE", width=800, height=450)Configuration: set basic variables and adjust according to items
DATA_DIR = "./data"
DATA_PATH = f"{DATA_DIR}/*.jpg"
MAX_DOCS = 1000
QUERY_IMAGE = "./query.jpg" # image we'll use to search with
PLOT_EMBEDDINGS = False # Really useful but have to manually stop it to progress to next cell
# Toy data - If data dir doesn't exist, we'll get data of ~800 fashion images from here
TOY_DATA_URL = "https://github.com/alexcg1/neural-search-notebooks/raw/main/fashion-search/data.zip?raw=true"set up
# We use "[full]" because we want to deal with more complex data like images (as opposed to text) !pip install "docarray[full]==0.4.4"
from docarray import Document, DocumentArray
Load picture
# Download images if they don't exist
import os
if not os.path.isdir(DATA_DIR) and not os.path.islink(DATA_DIR):
print(f"Can't find {DATA_DIR}. Downloading toy dataset")
!wget "$TOY_DATA_URL" -O data.zip
!unzip -q data.zip # Don't print out every darn filename
!rm -f data.zip
else:
print(f"Nothing to download. Using {DATA_DIR} for data")# Use `.from_files` to quickly load them into a `DocumentArray`
docs = DocumentArray.from_files(DATA_PATH, size=MAX_DOCS)
print(f"{len(docs)} Documents in DocumentArray")docs.plot_image_sprites() # Preview the images
Image preprocessing
from docarray import Document
# Convert to tensor, normalize so they're all similar enough
def preproc(d: Document):
return (d.load_uri_to_image_tensor() # load
.set_image_tensor_shape((80, 60)) # ensure all images right size (dataset image size _should_ be (80, 60))
.set_image_tensor_normalization() # normalize color
.set_image_tensor_channel_axis(-1, 0)) # switch color axis for the PyTorch model later# apply en masse docs.apply(preproc)
pictures embedding
!pip install torchvision==0.11.2
# Use GPU if available
import torch
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"import torchvision model = torchvision.models.resnet50(pretrained=True) # load ResNet50
docs.embed(model, device=device)
Visual embedding vector
if PLOT_EMBEDDINGS:
docs.plot_embeddings(image_sprites=True, image_source="uri")Create query Document
The first picture in the dataset is used here
# Download query doc !wget https://github.com/alexcg1/neural-search-notebooks/raw/main/fashion-search/1_build_basic_search/query.jpg -O query.jpg query_doc = Document(uri=QUERY_IMAGE) query_doc.display()
# Throw the one Document into a DocumentArray, since that's what we're matching against query_docs = DocumentArray([query_doc])
# Apply same preprocessing query_docs.apply(preproc)
# ...and create embedding just like we did with the dataset query_docs.embed(model, device=device) # If running on non-gpu machine, change "cuda" to "cpu"
matching
query_docs.match(docs, limit=9)
View results
The model will be matched according to the input image, and the matching here will even involve the matching of the model.
We only want the model to match clothes, so we use the result tuning tool of Jina AI here Finetuner Perform tuning.
(DocumentArray(query_doc.matches, copy=True)
.apply(lambda d: d.set_image_tensor_channel_axis(0, -1)
.set_image_tensor_inv_normalization())).plot_image_sprites()if PLOT_EMBEDDINGS:
query_doc.matches.plot_embeddings(image_sprites=True, image_source="uri")Advanced tutorial Preview
1. Fine tuning model
In subsequent notebook s, we will show how to use Jina Finetuner Improve the performance of the model.
2. Create application
In the following tutorial, we will demonstrate how to use Jina's neural search framework and Jina Hub Executors, build and expand search engines.

Click here View HD motion picture
Links to this article:
Jina Hub: https://hub.jina.ai/
Jina GitHub: https://github.com/jina-ai/jina/
Finetuner: https://finetuner.jina.ai/
Join Slack: https://slack.jina.ai/
View all the above codes in Colab: