1 What is the Series structure?
Series structure, also known as Series sequence, is one of the common data structures used by Pandas. It is a structure similar to one-dimensional arrays, consisting of a set of data values and a set of labels, in which there is a one-to-one correspondence between labels and data values.
Series can hold any data type, such as integer, string, floating point number, Python object, etc. Its label defaults to integer and increments from 0. The structure diagram of the Series is as follows:

Tags give us a more intuitive view of where the data is indexed.
2 Series object
2.1 Creating Series objects
Pandas uses the Series() function to create a Series object through which the appropriate methods and properties can be invoked for data processing purposes:
import pandas as pd
s=pd.Series( data, index, dtype, copy)
The parameter descriptions are as follows:
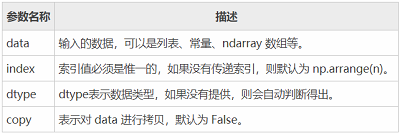
You can also use arrays, dictionaries, scalar values, or Python objects to create Series objects. The following shows different ways to create Series objects:
2.1.1 Create an empty Series object
An empty Series object can be created using the following methods, as follows:
import pandas as pd
#Output data is empty
s = pd.Series()
print(s)
The output is as follows:
Series([], dtype: float64)
2.1.2 ndarray Create Series Object
ndarray is an array type in NumPy, and when data is ndarry, the index passed must have the same length as the array. If no parameter is passed to the index parameter, by default, the index value is generated using range(n), where n represents the length of the array, as follows:
[0,1,2,3.... range(len(array))-1]
Create Series Sequence Objects using the default index:
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print (s)
The output is as follows:
0 a
1 b
2 c
3 d
dtype: object
In the example above, no index is passed, so the index is allocated from 0 by default, with an index range of 0 to len(data)-1, or 0 to 3. This setting is called Implicit Indexing.
In addition to the above methods, you can also use the Explicit Index method to define index labels as follows:
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
#Custom index labels (that is, display indexes)
s = pd.Series(data,index=[100,101,102,103])
print(s)
Output results:
100 a
101 b
102 c
103 d
dtype: object
2.1.3 dict Create Series Object
You can use dict as input data. If no index is passed in, the index is constructed according to the keys of the dictionary; Conversely, when an index is passed, one-to-one correspondence between the index label and the value in the dictionary is required.
The following two sets of examples demonstrate these two scenarios separately.
Example 1, when no index is passed:
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print(s)
Output results:
a 0.0
b 1.0
c 2.0
dtype: float64
Example 2, when passing an index for the index parameter:
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print(s)
Output results:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
Use NaN (non-numeric) padding when the passed index value cannot be found.
2.1.4 Scalar Create Series Object
If the data is a scalar value, an index must be provided, as shown in the following example:
import pandas as pd
import numpy as np
s = pd.Series(5, index=[0, 1, 2, 3])
print(s)
The output is as follows:
0 5
1 5
2 5
3 5
dtype: int64
Scalar values are repeated and correspond to the number of indices.
3 Access Series data
3.1 Location Index Access
This access is the same as ndarray and list, accessed using the element's own subscript. We know that the index count of an array starts at 0, which means that the first element is stored at the 0th index position, and so on, each element in the Series sequence can be obtained. Let's look at a simple set of examples:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[0]) #Position Subscript
print(s['a']) #Label Subscript
Output results:
1
1
The data in the Series sequence is accessed sliced as follows:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[:3])
Output results:
a 1
b 2
c 3
dtype: int64
If you want to get the last three elements, you can also use the following:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])
Output results:
c 3
d 4
e 5
dtype: int64
3.2 Index Label Access
import pandas as pd
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s['a'])
Output results:
6
Example 2, using index labels to access multiple element values
import pandas as pd
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s[['a','c','d']])
Output results:
a 6
c 8
d 9
dtype: int64
Example 3, if a tag not included in the index is used, an exception is triggered:
import pandas as pd
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
#Does not contain f value
print(s['f'])
Output results:
......
KeyError: 'f'
4. Series Common Properties
Below we describe the common properties and methods of Series. Common properties of Series objects are listed in the following table.
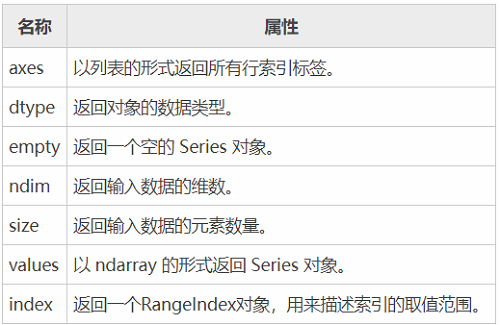
Now create a Series object and show how to use the properties in the table above. As follows:
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print(s)
Output results:
0 0.898097
1 0.730210
2 2.307401
3 -1.723065
4 0.346728
dtype: float64
The row index label for the example above is [0,1,2,3,4].
4.1 axes
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print ("The axes are:")
print(s.axes)
Output Results
The axes are:
[RangeIndex(start=0, stop=5, step=1)]
4.2 dtype
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print ("The dtype is:")
print(s.dtype)
Output results:
The dtype is:
float64
4.3 empty
Returns a Boolean value that determines whether the data object is empty. Examples are as follows:
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print("Is it an empty object?")
print (s.empty)
Output results:
Is it an empty object?
False
4.4 ndim
View the dimensions of the series. By definition, Series is a one-dimensional data structure, so it always returns 1.
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print (s)
print (s.ndim)
Output results:
0 0.311485
1 1.748860
2 -0.022721
3 -0.129223
4 -0.489824
dtype: float64
1
4.5 size
Returns the size (length) of the Series object.
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(3))
print (s)
#series Length Size
print(s.size)
Output results:
0 -1.866261
1 -0.636726
2 0.586037
dtype: float64
3
4.6 values
Returns data from a Series object as an array.
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(6))
print(s)
print("output series Medium data")
print(s.values)
Output results:
0 -0.502100
1 0.696194
2 -0.982063
3 0.416430
4 -1.384514
5 0.444303
dtype: float64
output series Medium data
[-0.50210028 0.69619407 -0.98206327 0.41642976 -1.38451433 0.44430257]
4.7 index
This property is used to view the range of values of the index in Series. Examples are as follows:
#Display Index
import pandas as pd
s=pd.Series([1,2,5,8],index=['a','b','c','d'])
print(s.index)
#Implicit Index
s1=pd.Series([1,2,5,8])
print(s1.index)
Output results:
Implicit Index:
Index(['a', 'b', 'c', 'd'], dtype='object')
Display Index:
RangeIndex(start=0, stop=4, step=1)
5. Series Common Methods
5.1 head() &tail() view data
If you want to view a portion of the Series data, you can use the head () or tail() method. Where head() returns the first n rows of data and displays the first 5 rows by default. Examples are as follows:
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print ("The original series is:")
print (s)
#Return the first three rows of data
print (s.head(3))
Output results:
Original series output:
0 1.249679
1 0.636487
2 -0.987621
3 0.999613
4 1.607751
head(3)Output:
dtype: float64
0 1.249679
1 0.636487
2 -0.987621
dtype: float64
tail() returns the last n rows of data, defaulting to the last 5 rows. Examples are as follows:
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(4))
#primary series
print(s)
#Last two rows of output data
print (s.tail(2))
Output results:
primary Series Output:
0 0.053340
1 2.165836
2 -0.719175
3 -0.035178
The last two rows of data are output:
dtype: float64
2 -0.719175
3 -0.035178
dtype: float64
5.2 isnull() &nonull() to detect missing values
isnull() and nonull() are used to detect missing values in Series. The so-called missing value, as its name implies, means that the value does not exist, is lost or is missing.
- isnull(): Returns True if the value does not exist or is missing.
- notnull(): Returns False if the value does not exist or is missing.
In fact, it is not difficult to understand that data collection often goes through a cumbersome process in the real data analysis stuff. In this process, it is unavoidable that some force majeure or human factors will cause data loss. At this time, we can use the appropriate methods to deal with missing values, such as mean interpolation, data completion, and so on. These two methods are designed to help us detect the presence of missing values. Examples are as follows:
import pandas as pd
#None Represents missing data
s=pd.Series([1,2,5,None])
print(pd.isnull(s)) #Is Null Return True
print(pd.notnull(s)) #Null Value Return False
Output results:
0 False
1 False
2 False
3 True
dtype: bool
notnull():
0 True
1 True
2 True
3 False
dtype: bool