preface
Recently, I was studying and learning the source code of leveldb and tried to rewrite leveldb RS with Rust. The memdb module in leveldb uses skiplist as a kv memory storage. The implementation of the relevant code is very beautiful, so I have this article. Leveldb implements skiplist by using Arena mode. In short, it uses linear arrays to simulate the relationship between nodes, which can effectively avoid circular references.
- Although leveldb of c + + version also uses arena mode, the application and access of node data memory are encapsulated. The structure definition and implementation of skiplist are very similar to the code implementation of skiplist in the traditional sense. If you have known skiplist before, the code of c + + version is very easy to understand.
- leveldb in the golang version lacks the encapsulation of arena and directly operates slice. If you are not familiar with arena mode, it will be troublesome to understand. From the perspective of software engineering, the code of the golang version of memdb is not well written, and the operation of arena can be further optimized and reconstructed.
The following will be explained in this article:
- Compare the implementation of query, insert and delete in c + + and golang
- Analyze what can be optimized in the golang version
Then it will be introduced in the next article
- Rewrite memdb (arena version) with t rust based on golang version
- Use t rust to rewrite a non arena version of memdb, which is the classic implementation of linked list structure
Type declaration
First, let's compare the skipplist definitions in C + + and Golang's code:
C++
https://github.com/google/lev...
The key member variables are listed here. For details, see the source code:
template <typename Key, class Comparator>
class SkipList {
...
// Immutable after construction
Comparator const compare_;
Arena* const arena_; // Arena used for allocations of nodes
Node* const head_;
// Modified only by Insert(). Read racily by readers, but stale
// values are ok.
std::atomic<int> max_height_; // Height of the entire list
// Read/written only by Insert().
Random rnd_;
};- Comparator const compare_; Used to compare node key s when traversing skiplist
- Arena* const arena_; Memory management using arena mode
- Node* const head_; First node
- std::atomic max_ height_; The layer height of skiplist may change during insertion
- Random rnd_; The random number generator is used to generate the floor height of new nodes at each insertion
Golang
https://github.com/syndtr/gol...
type DB struct {
cmp comparer.BasicComparer
rnd *rand.Rand
mu sync.RWMutex
kvData []byte
nodeData []int
prevNode [tMaxHeight]int
maxHeight int
n int
kvSize int
}
- cmp comparer.BasicComparer: used to compare node key s when traversing skiplist
- rnd *rand.Rand: random number generator, which is used to generate the floor height of new nodes at each insertion
- Kvdata [] byte: where the key and value actual data are stored
- nodeData[]int: stores the information of each node
- prevNode [tMaxHeight]int: used to save the previous node of each layer when traversing the skiplist
- Maxheight int: the layer height of skiplist may change during insertion
- n int: total number of nodes
- Kvsize: the total number of bytes storing key and value in skiplist
The most difficult thing to understand in the golang version is NoData. Only by understanding the data layout of NoData, the following code is easy to understand.
- kvData stores real byte data of key and value
- Kvnode stores all the nodes in the skiplist, but the node does not store the actual data of key and value, but the offset in kvdata, the length of key and value, which are read in kvdata according to the offset and length during comparison. In addition, kvnode also stores the layer height of the current node and the offset of the next node of each layer in kvnode. When querying, you can jump to the position of the next node in kvnode according to the offset and read information from it.
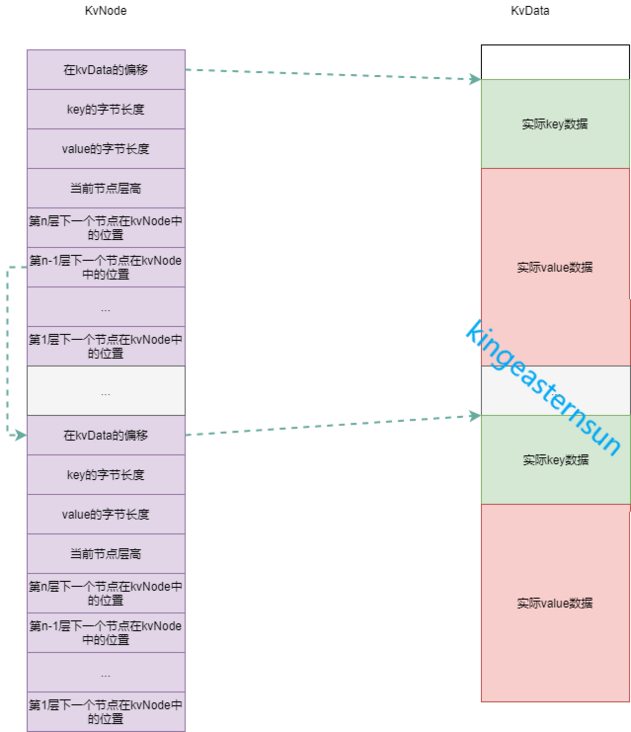
Query a specific Key greater than or equal to
Let's first look at the query in skiplist. The implementation of query in leveldb is the most critical. Insertion and deletion are also based on query implementation. Let's briefly review the query process:
- Firstly, the head node of the highest layer is selected according to the height of the jump table;
- If the content of the node in the hop table is less than that of the lookup node, take the next node of the layer to continue the comparison;
- If the content of the node in the hop table is equal to the content of the lookup node, it will be returned directly;
- If the content of the node in the hop table is greater than that of the lookup node, and the layer height is not 0, reduce the layer height, and start from the previous node to find the node information in the lower layer again; If the floor height is 0, the current node is returned, and the key of this node is greater than the key of the node being searched.
For example, if you want to query 17 nodes with key in the following skiplist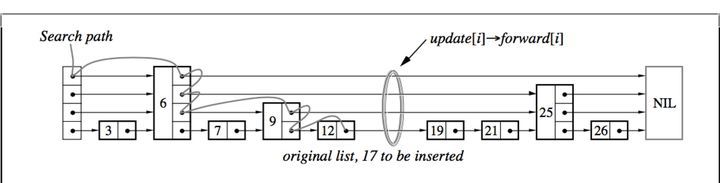
- Starting from the leftmost head node, the current floor height is 4;
- The key of the head node in the next node of layer 4 is 6. Since 17 is greater than 6, on the right side of the current node, go to the next node along the linked list of the current layer, that is, the key is 6.
- The next node of node 6 in layer 4 is NIL, that is, there is no node behind, so you need to go down to layer 3 in the current node.
- The key of the next node of node 6 in layer 3 is 25. Since 17 is less than 25, you need to go down to layer 2 in the current node.
- The key of node 6 in the next node of layer 2 is 9. Since 17 is greater than 9, go to the next node along the linked list of the current layer, that is, the node with key 9.
- The key of the nex node of node 9 in layer 2 is 25. Since 17 is less than 25, you need to go down to layer 1 in the current node.
- The key of the next node of node 8 in layer 1 is 12. Since 17 is greater than 12, go to the next node along the linked list of the current layer, that is, the node with key 12.
- The key of the next node of node 12 in the first layer is 19. Since 17 is less than 19, it should continue to the next layer. However, since it is already the last layer, it directly returns the next node of node 12, that is, node 19
C++
https://github.com/google/lev...
The method to query the minimum node greater than or equal to key in skiplist is as follows
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key,
Node** prev) const {
Node* x = head_; // head node
int level = GetMaxHeight() - 1;// Current floor height
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {// If the key of the next node of x in the current layer is less than the key
x = next; // Continue searching in the list of the current layer
} else {
if (prev != nullptr) prev[level] = x; // If you want to record the pre node during traversal, record
if (level == 0) { // Search to the end and return
return next;
} else {
// If the key of x the next node in the current layer is greater than the key, search the next layer
level--;
}
}
}
}
Go
https://github.com/syndtr/gol...
The method to query the minimum node greater than or equal to key in skiplist is as follows
// Must hold RW-lock if prev == true, as it use shared prevNode slice.
func (p *DB) findGE(key []byte, prev bool) (int, bool) {
node := 0 // head node
h := p.maxHeight - 1 // Current floor height
for {
next := p.nodeData[node+nNext+h]
cmp := 1
if next != 0 {
o := p.nodeData[next]
cmp = p.cmp.Compare(p.kvData[o:o+p.nodeData[next+nKey]], key)
}
// If the key of the next node of the node in the current layer is less than the key, continue to search in the list of the current layer
if cmp < 0 {
// Keep searching in this list
node = next
} else {
if prev { // For the search for insertion or deletion, you should continue to the next level of comparison even if you encounter the same
p.prevNode[h] = node
} else if cmp == 0 {
return next, true
}
if h == 0 {
return next, cmp == 0
}
// If the key of the next node in the current layer is greater than the key, the current node searches the next layer
h--
}
}
}- node + nNext + i we can treat it as a linked list structure in C + + code. The node in the skiplist is at layer i, and then p.nodeData[node+nNext+i] is treated as node - > next (i)
- p.nodeData[next+nKey] get the length of the key
Query less than or equal to
GE search is very similar to LT search, and the key difference is
- GE search returns the next node and LT returns the current node
- In the process of GE search, if the next key is the same as the current key, it will return. In LT, if the next key is the same as the current key, it will enter the next layer, which will limit the search range to less than the key.
C++
https://github.com/google/lev... The method to query the largest node less than key in skiplist is as follows
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindLessThan(const Key& key) const {
Node* x = head_; // head node
int level = GetMaxHeight() - 1; // Current floor height
while (true) {
assert(x == head_ || compare_(x->key, key) < 0);
Node* next = x->Next(level);
if (next == nullptr || compare_(next->key, key) >= 0) { // If the next node is empty or the next node is greater than or equal to the request key
if (level == 0) { // This is the last layer. Return to the current node
return x;
} else {
level--; // Go to the next floor
}
} else {
x = next; // If the next node is smaller than the request key, go to the next node along the current layer
}
}
}Golang
https://github.com/syndtr/gol... The method to query the largest node less than key in skiplist is as follows
func (p *DB) findLT(key []byte) int {
node := 0 // head node
h := p.maxHeight - 1 // Current floor height
for {
next := p.nodeData[node+nNext+h] // Find the next node of the current node
o := p.nodeData[next] // Data offset of next node in nodeData
if next == 0 || p.cmp.Compare(p.kvData[o:o+p.nodeData[next+nKey]], key) >= 0 {// If the next node is empty or the next node is greater than or equal to the request key
if h == 0 {// This is the last layer. Return to the current node
break
}
h-- // Go to the next floor
} else {
node = next // If the next node is smaller than the request key, go to the next node along the current layer
}
}
return node
}- node + nNext + i can be regarded as the node in the linked list structure skiplist in C + + code, and then p.nodeData[node+nNext+i] can be regarded as node - > next (i),
- p.nodeData[next+nKey] gets the length of the key, so p.kvData[o:o+p.nodeData[next+nKey]] gets the real data corresponding to the key
Here, the operation of obtaining the key can be encapsulated as a separate method to improve the readability of the code
Query last node
From the top to the bottom, judge whether the next is empty (that is, whether the current layer list has reached the last node),
- If it is not empty, continue to jump to the next node
- If empty, move to the next level
C++
https://github.com/google/lev...
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node* SkipList<Key, Comparator>::FindLast()
const {
Node* x = head_;
int level = GetMaxHeight() - 1;
while (true) {
Node* next = x->Next(level);
if (next == nullptr) { // If the next node is empty, move to the next layer
if (level == 0) {
return x;
} else {
// Switch to next list
level--;
}
} else { // If the current next is not empty, move to next
x = next;
}
}
}Golang
https://github.com/syndtr/gol...
func (p *DB) findLast() int {
node := 0
h := p.maxHeight - 1
for {
next := p.nodeData[node+nNext+h] // Get next
if next == 0 { // If next is empty, go to the next floor
if h == 0 {
break
}
h--
} else {
node = next // Move to next
}
}
return node
}- node + nNext + i can be regarded as the node in the linked list structure skiplist in C + + code, and then p.nodeData[node+nNext+i] can be regarded as node - > next (i),
insert
Borrow here https://www.bookstack.cn/read... Example diagram of
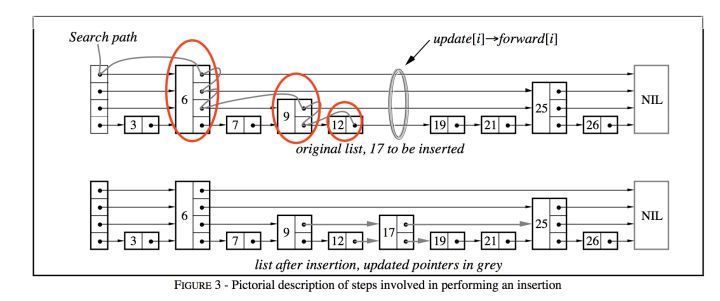
- In the process of searching, the predecessor nodes of each layer are continuously recorded, as shown by the red circle in the figure;
- Randomly generate the layer height for the newly inserted node (the algorithm for randomly generating the layer height is relatively simple and depends on the highest layer number and probability value p, which can be seen in the code implementation below);
- Insert a new node at an appropriate position (for example, between node 12 and node 19 in the figure), and insert the node into the link of each layer in the way of linked list insertion in each layer according to the predecessor node information recorded during search.
C++
https://github.com/google/lev...
template <typename Key, class Comparator>
void SkipList<Key, Comparator>::Insert(const Key& key) {
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];// Used to record the previous node of each layer in the traversal process
Node* x = FindGreaterOrEqual(key, prev); // Find insertion point
// Our data structure does not allow duplicate insertion
assert(x == nullptr || !Equal(key, x->key));
// Generates a random floor height for the point to be inserted
int height = RandomHeight();
if (height > GetMaxHeight()) {
// If the newly generated layer height is higher than the maximum layer height of the current skiplist,
// There is no next node in (getmaxheight()) height] before the head node, so it needs to be compensated
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
// It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (nullptr), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since nullptr sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.store(height, std::memory_order_relaxed);
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
// Insert the linked list of each layer through which the new node passes
// That is, for each forward node recorded above, x - > next points to prenode - > next, and then prenode - > next points to x
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}Golang
https://github.com/syndtr/gol...
// Put sets the value for the given key. It overwrites any previous value
// for that key; a DB is not a multi-map.
//
// It is safe to modify the contents of the arguments after Put returns.
func (p *DB) Put(key []byte, value []byte) error {
p.mu.Lock()
defer p.mu.Unlock()
// Find insertion location
if node, exact := p.findGE(key, true); exact {
// If the key already exists,
kvOffset := len(p.kvData) // Because the following key and value are appended to kvData, the length of kvData recorded here is the offset of the new node
p.kvData = append(p.kvData, key...)//Append key data
p.kvData = append(p.kvData, value...)// Append value data
p.nodeData[node] = kvOffset // Update offset
m := p.nodeData[node+nVal] // Length of previous value
p.nodeData[node+nVal] = len(value) // Update the length of value. Since the key remains unchanged, the length of key does not need to be updated
p.kvSize += len(value) - m //Total length of updated data
return nil
}
// Insert a new node to obtain the floor height of the current node
h := p.randHeight()
if h > p.maxHeight {
// If the newly generated layer height is higher than the maximum layer height of the current skiplist,
// There is no next node in (p.maxHeight, h] before the head node, so it needs to be compensated
for i := p.maxHeight; i < h; i++ {
p.prevNode[i] = 0
}
p.maxHeight = h
}
kvOffset := len(p.kvData) // Record the length of the current kvData as the offset of the new node
p.kvData = append(p.kvData, key...) // Append key data
p.kvData = append(p.kvData, value...)// Append value data
// Node
node := len(p.nodeData)
p.nodeData = append(p.nodeData, kvOffset, len(key), len(value), h)// Add node information
for i, n := range p.prevNode[:h] {
m := n + nNext + i
p.nodeData = append(p.nodeData, p.nodeData[m]) // The next of each layer of the current node points to the next of each layer of the forward node
p.nodeData[m] = node // The next of the forward node points to the current node
}
p.kvSize += len(key) + len(value) // Total length
p.n++
return nil
}This paragraph is more important, https://github.com/syndtr/gol... Is the core code that executes the insert
// Node
node := len(p.nodeData)
p.nodeData = append(p.nodeData, kvOffset, len(key), len(value), h)
for i, n := range p.prevNode[:h] {
m := n + nNext + i
p.nodeData = append(p.nodeData, p.nodeData[m])
p.nodeData[m] = node
}It was not easy to understand and explain at first. We modified the code a little and changed it to this
// Node
node := len(p.nodeData)
p.nodeData = append(p.nodeData, kvOffset, len(key), len(value), h)
// Add index of h nextnodes
p.nodeData = append(p.nodeData, make([]int,h)...)
for i, n := range p.prevNode[:h] {
m := n + nNext + i
p.nodeData[node+nNext+i] = p.nodeData[m]
p.nodeData[m] = node
}This makes it easier to explain:
First of all, M: = n + nnext + i can be regarded as the nth node in the linked list structure skiplist in C + + code, then p.nodata [n + nnext + i] is regarded as N - > next (i), and p.nodeData[node+nNext+i] is regarded as node - > next (i). Then the part of the above loop becomes
for i, n := range p.prevNode[:h] {
m := n + nNext + i
node.Next(i) = n->Next(i)//The current node points to the next node of the pre node
n->Next(i) = node // The next node of the pre node becomes the current node
}delete
Only goleveldb provides this method for deletion, which is relatively simple
Golang
https://github.com/syndtr/gol...
func (p *DB) Delete(key []byte) error {
p.mu.Lock()
defer p.mu.Unlock()
node, exact := p.findGE(key, true)// Find delete point
if !exact {
return ErrNotFound
}
h := p.nodeData[node+nHeight]
for i, n := range p.prevNode[:h] {
m := n + nNext + i
p.nodeData[m] = p.nodeData[p.nodeData[m]+nNext+i] // The next of the forward node of each layer points to the next of the current node
}
p.kvSize -= p.nodeData[node+nKey] + p.nodeData[node+nVal]
p.n--
return nil
}- n + nNext + i can be regarded as the node in the linked list structure skipplist in C + + code, and then p.nodeData[node+nNext+i] can be regarded as node - > next (i),
- p.nodeData[m] = p.nodeData[p.nodeData[m]+nNext+i] can be understood as node - > next (I) = node - > next (I) - > next (I). Delete
Golang version optimization
When studying goleveldb, we found some places that can be optimized, as follows:
Delete optimization
When deleting a node, go through the forward node prenode of each layer in goleveldb, and then let the prenode next = preNode. next. The next linked list is deleted. In fact, the next node of the forward node is the current node, so it can be changed to prenode next = cur. Next is
p.nodeData[m] = p.nodeData[node+nNext+i]
Insert optimization
When inserting a node, whether the key already exists or not, data is directly added to kvData. In fact, it can be further optimized here. If the length of the new value is equal to the original value or the length of the new value is less than the length of the original value, the previous memory space can be reused.
The value s inserted in the original goleveldb performance test code are nil, so here we write a new performance test code for the test function
func BenchmarkPutRandomKV(b *testing.B) {
buf := make([][4]byte, b.N)
value := make([][]byte, b.N)
for i := range buf {
tmp := uint32(rand.Int()) % 100000
binary.LittleEndian.PutUint32(buf[i][:], tmp)
value[i] = make([]byte, tmp)
}
b.ResetTimer()
p := New(comparer.DefaultComparer, 0)
for i := range buf {
p.Put(buf[i][:], value[i][:])
}
}Before optimization
goos: linux goarch: amd64 pkg: github.com/syndtr/goleveldb/leveldb/memdb cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz BenchmarkPutRandomKV-8 20180 53760 ns/op 273344 B/op 0 allocs/op PASS ok github.com/syndtr/goleveldb/leveldb/memdb 2.000s
After optimization
goos: linux goarch: amd64 pkg: github.com/syndtr/goleveldb/leveldb/memdb cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz BenchmarkPutRandomKV-8 29634 51464 ns/op 232687 B/op 0 allocs/op PASS ok github.com/syndtr/goleveldb/leveldb/memdb 2.264s
This performance improvement is mainly related to the probability of key repetition and the probability that the newly inserted value is less than the previous value.
Further thinking
goleveldb always occupies the space occupied by the deleted node in KvData and has not been reused. Here you can also find a way to reuse it, which is left to the readers.
Epilogue
This article has basically finished the core code of memdb in leveldb. If you have a Rust background, you can expect to rewrite the skipplist with Rust in the next article.
reference material
- Jump table https://www.bookstack.cn/read...
- Jump linked list https://www.cnblogs.com/s-lis...
