3.1. Basic queries:
Basic grammar
GET/Index Library Name/_search
{
"query":{
"Query type":{
"Query Conditions": "Query Conditional Values"
}
}
}
Here query represents a query object, which can have different query attributes.
- Query type:
- For example: match_all, match, term, range, etc.
- Query Conditions: Query Conditions will vary according to the type and the way they are written, which will be explained in detail later.
3.1.1 Query all (match_all)
Example:
GET /smallmartial/_search { "query":{ "match_all": {} } }
- Query: Represents the query object
- match_all: Represents querying all
Result:
{ "took": 3, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "2", "_score": 1, "_source": { "title": "Rice mobile phone", "images": "http://image.leyou.com/12479122.jpg", "price": 2899 } }, { "_index": "smallmartial", "_type": "goods", "_id": "vV5xK2oBwnpoSx5Aac1y", "_score": 1, "_source": { "title": "Mi phones", "images": "http://image.leyou.com/12479122.jpg", "price": 2699 } } ] } }
- Taken: Queries take time in milliseconds
- time_out: time out or not
- _ shards: fragmentation information
- hits: search results overview object
- Total: total number of searched items
- max_score: The highest score for documents in all results
- hits: An array of document objects in search results, each element being a searched document information
- _ index: index library
- _ type: Document type
- _ id: document ID
- _ score: Document score
- _ source: The source data of the document
3.1.2 match Query
Let's add a piece of data to facilitate testing:
PUT /heima/goods/3 { "title":"Millet TV 4 A", "images":"http://image.leyou.com/12479122.jpg", "price":3899.00 }
Now, there are two mobile phones and one TV in the index library:
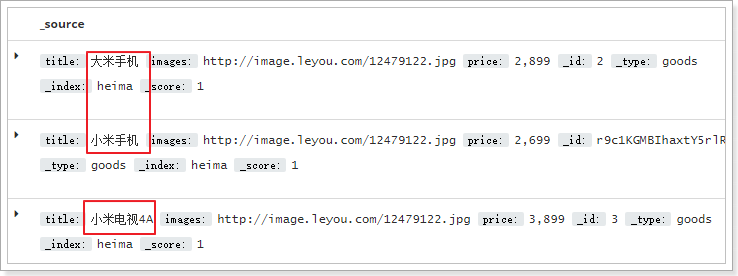
- or relationship
Matching type query, the query conditions will be partitioned, and then query, the relationship between multiple entries is or
PUT /smallmartial/goods/3 { "title":"Millet TV 4 A", "images":"http://image.leyou.com/12479122.jpg", "price":3899.00 }
Result:
{ "_index": "smallmartial", "_type": "goods", "_id": "3", "_version": 1, "result": "created", "_shards": { "total": 3, "successful": 1, "failed": 0 }, "_seq_no": 4, "_primary_term": 1 }
In the above case, not only the TV will be queried, but also the rice-related will be queried, the relationship between multiple words is or.
- and relationship
In some cases, we need to look more precisely, and we want this relationship to become and, we can do this:
GET /goods/_search { "query":{ "match":{ "title":{"query":"Mi TV","operator":"and"} } } }
Result:

In this case, only entries containing both millet and television will be searched.
- Between or and?
It's a little too black to white to choose between or and and. If there are five query terms after a user's given conditional word segmentation, and you want to find a document that contains only four of them, what should you do? Setting the operator operator parameter to and only excludes this document.
Sometimes that's exactly what we expect, but in most application scenarios of full-text search, we want to include documents that may be relevant while excluding those that are not. In other words, we want to be in the middle of something.
The match query supports the minimum_should_match minimum matching parameter, which allows us to specify the number of terms that must be matched to indicate whether a document is relevant or not. We can set it to a specific number, more commonly to a percentage, because we can't control the number of words that users enter when searching:
GET /smallmartial/_search { "query":{ "match":{ "title":{ "query":"Millet Surface TV", "minimum_should_match": "75%" } } } }
In this case, the search statement can be divided into three words. If the and relation is used, three words need to be satisfied at the same time to be searched. Here we use the smallest number of brands: 75%, that is to say, only 75% of the total number of entries can be matched, where 3 * 75% is equal to about 2. So it's enough to include only two entries.
Result:
{ "took": 32, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.77041245, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "3", "_score": 0.77041245, "_source": { "title": "Millet TV 4 A", "images": "http://image.leyou.com/12479122.jpg", "price": 3899 } } ] } }
3.1.3 Multi-field Query (multi_match)
multi_match is similar to match, except that it can be queried in multiple fields.
GET /heima/_search { "query":{ "multi_match": { "query": "millet", "fields": [ "title", "subTitle" ] } } }
In this case, we will query the word millet in the title field and subtitle field.
3.1.4 term matching
term queries are used to match exact values, which may be numbers, times, Booleans, or unsigned strings.
GET /smallmartial/_search { "query":{ "term":{ "price":2699.00 } } }
Result:
{ "took": 15, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "vV5xK2oBwnpoSx5Aac1y", "_score": 1, "_source": { "title": "Mi phones", "images": "http://image.leyou.com/12479122.jpg", "price": 2699 } } ] } }
3.1.5 Multi-entry Precise Matching (terms)
terms queries are the same as term queries, but they allow you to specify multiple values for matching. If this field contains any of the specified values, the document satisfies the criteria:
GET /smallmartial/_search { "query":{ "terms":{ "price":[2699.00,2899.00,3899.00] } } }
Result:
{ "took": 14, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "2", "_score": 1, "_source": { "title": "Rice mobile phone", "images": "http://image.leyou.com/12479122.jpg", "price": 2899 } }, { "_index": "smallmartial", "_type": "goods", "_id": "vV5xK2oBwnpoSx5Aac1y", "_score": 1, "_source": { "title": "Mi phones", "images": "http://image.leyou.com/12479122.jpg", "price": 2699 } }, { "_index": "smallmartial", "_type": "goods", "_id": "3", "_score": 1, "_source": { "title": "Millet TV 4 A", "images": "http://image.leyou.com/12479122.jpg", "price": 3899 } } ] } }
3.2. Result filtering
By default, elastic search returns all fields saved in _source in the document in the search result.
If we only want to get some of the fields, we can add a filter of _source
3.2.1. Specify fields directly
Example:
GET /smallmartial/_search { "_source": ["title","price"], "query": { "term": { "price": 2699 } } }
Returns the results:
{ "took": 13, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "vV5xK2oBwnpoSx5Aac1y", "_score": 1, "_source": { "price": 2699, "title": "Mi phones" } } ] } }
3.2.2. Specify includes and excludes
We can also do this by:
- Include: To specify the fields you want to display
- excludes: To specify fields that you do not want to display
Both are optional.
Example:
GET /smallmartial/_search { "_source": { "includes":["title","price"] }, "query": { "term": { "price": 2699 } } }
The following results will be the same:
{ "took": 4, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "vV5xK2oBwnpoSx5Aac1y", "_score": 1, "_source": { "price": 2699, "title": "Mi phones" } } ] } }
3.3 Advanced Query
3.3.1 Boolean Combination (bool)
bool combines various other queries by must (and), must_not (non), should (or)
GET /smallmartial/_search { "query":{ "bool":{ "must": { "match": { "title": "rice" }}, "must_not": { "match": { "title": "television" }}, "should": { "match": { "title": "Mobile phone" }} } } }
Result:
{ "took": 22, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.5753642, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "2", "_score": 0.5753642, "_source": { "title": "Rice mobile phone", "images": "http://image.leyou.com/12479122.jpg", "price": 2899 } } ] } }
3.3.2 Range Query
range queries identify numbers or times that fall within a specified interval
GET /smallmartial/_search { "query":{ "range": { "price": { "gte": 1000.0, "lt": 2800.00 } } } }
range queries allow the following characters:
| Operator | Explain |
|---|---|
| gt | greater than |
| gte | Greater than or equal to |
| lt | less than |
| lte | Less than or equal to |
3.3.3 Fuzzy Query
We have added a new commodity:
POST /smallmartial/goods/4 { "title":"apple Mobile phone", "images":"http://image.leyou.com/12479122.jpg", "price":6899.00 }
Fuzzy query is the fuzzy equivalence of term query. It allows users to search for entries that deviate from the actual spelling of entries, but the editing distance of the deviation should not exceed 2:
GET /smallmartial/_search { "query": { "fuzzy": { "title": "appla" } } }
The above query can also be found on the apple mobile phone.
We can specify the allowable edit distance by using fuzzines:
GET /smallmartial/_search { "query": { "fuzzy": { "title": { "value":"appla", "fuzziness":1 } } } }
reslut
{ "took": 37, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.55451775, "hits": [ { "_index": "smallmartial", "_type": "goods", "_id": "4", "_score": 0.55451775, "_source": { "title": "apple Mobile phone", "images": "http://image.leyou.com/12479122.jpg", "price": 6899 } } ] } }
3.4 Filter
Conditional queries are filtered
All queries affect the score and ranking of documents. If we need to filter the query results and do not want the filtering conditions to affect the score, then we should not use the filtering conditions as the query conditions. Instead, filter is used:
GET /smallamrtial/_search { "query":{ "bool":{ "must":{ "match": { "title": "Mi phones" }}, "filter":{ "range":{"price":{"gt":2000.00,"lt":3800.00}} } } } }
Note: bool combination conditional filtering can also be done again in the filter.
No query condition, direct filtering
If a query has only filtering, no query conditions and does not want to score, we can use constant_score instead of bool query with only filter statement. The performance is exactly the same, but it is very helpful to improve query conciseness and clarity.
GET /smallamrtial/_search { "query":{ "constant_score": { "filter": { "range":{"price":{"gt":2000.00,"lt":3000.00}} } } }
3.5 ranking
3.4.1 Single Field Sorting
Sort lets us sort by different fields and specify the sort by order
GET /smallmartial/_search { "query": { "match": { "title": "Mi phones" } }, "sort": [ { "price": { "order": "desc" } } ] }
3.4.2 Multi-field Sorting
Suppose we want to query using price and _score, and the matching results are sorted by price first, then by correlation score:
GET /goods/_search { "query":{ "bool":{ "must":{ "match": { "title": "Mi phones" }}, "filter":{ "range":{"price":{"gt":200000,"lt":300000}} } } }, "sort": [ { "price": { "order": "desc" }}, { "_score": { "order": "desc" }} ] }
4. aggregations
Aggregation can make it very convenient for us to realize the statistics and analysis of data. For example:
- What brand of mobile phone is the most popular?
- Average price, highest price, lowest price for these phones?
- How about the monthly sales of these mobile phones?
It is much more convenient to implement these statistical functions than sql in database, and the query speed is very fast, which can achieve near real-time search effect.
4.1 Basic Concepts
Aggregation in Elastic search contains many types, the two most commonly used, one is called bucket, the other is called metric:
bucket
The function of barrels is to group data in some way. Each group of data is called a barrel in ES. For example, we can get Chinese barrels, British barrels and Japanese barrels by dividing people according to their nationality. Or we divide people by age: 010, 1020, 2030, 3040, etc.
There are many ways to divide buckets in Elastic search:
- Date Histogram Aggregation: Grouping by date ladder, such as given a ladder for a week, is automatically grouped weekly.
- Histogram Aggregation: Grouped by numerical ladder, similar to date
- Terms Aggregation: Grouped according to the content of the entry, the content of the entry matches perfectly into a group.
- Range Aggregation: Range grouping of values and dates, specifying start and end, and then grouping by segments
- ......
In summary, we find that bucket aggregations are only responsible for grouping data and do not compute it, so there is often another aggregation nested in buckets: metrics aggregations, i.e. metrics aggregations.
metrics
After the grouping is completed, we usually aggregate the data in the group, such as average, maximum, minimum, sum and so on. These are called metrics in ES.
Some common measurement aggregation methods are as follows:
- Avg Aggregation: Average Value
- Max Aggregation: Maximum
- Min Aggregation: Finding the Minimum
- Percentiles Aggregation: Percentiles Aggregation
- Stats Aggregation: Also return avg, max, min, sum, count, etc.
- Sum Aggregation: Summation
- Top hits Aggregation: Find the first few
- Value Count Aggregation: Total
- ......
To test aggregation, we first import some data in batches
Create an index:
PUT /cars { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "transactions": { "properties": { "color": { "type": "keyword" }, "make": { "type": "keyword" } } } } }
Note: In ES, fields that need to be aggregated, sorted and filtered are processed in a special way, so they cannot be segmented. Here we set the fields of color and make to keyword type, which will not be segmented and will be able to participate in aggregation in the future.
Import data
POST /cars/transactions/_bulk { "index": {}} { "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" } { "index": {}} { "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" } { "index": {}} { "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" } { "index": {}} { "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
4.2 Polymerized into Buckets
First, we divide the barrels according to the color of the car.
GET /cars/_search { "size" : 0, "aggs" : { "popular_colors" : { "terms" : { "field" : "color" } } } }
- size: The number of queries, set here to 0, because we don't care about the data we've searched, we only care about aggregating the results to improve efficiency.
- aggs: Declare that this is an aggregated query, short for aggregations
- popular_colors: Give this aggregation a name, whatever.
- terms: The way to divide buckets. Here's how to divide buckets according to entries.
- Field: field for dividing buckets
- terms: The way to divide buckets. Here's how to divide buckets according to entries.
- popular_colors: Give this aggregation a name, whatever.
Result:
{ "took": 40, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "popular_colors": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "red", "doc_count": 4 }, { "key": "blue", "doc_count": 2 }, { "key": "green", "doc_count": 2 } ] } } }
- hits: The query result is empty because we set size to 0
- aggregations: results of aggregation
- popular_colors: The aggregation name we defined
- Buckets: The buckets found form one bucket for each different color field value
- key: The value of the color field corresponding to this bucket
- doc_count: Number of documents in this bucket
Through the results of the aggregation, we found that the red car is very popular at present.
4.3 barrel measurement
The previous example tells us the number of documents in each bucket, which is very useful. Usually, however, our applications need to provide more complex document metrics. For example, what is the average price of each color car?
Therefore, we need to tell Elastic search which field to use and which metric to operate on. This information is embedded in the bucket, and the metric is based on the document in the bucket.
Now, we add a measure of the average price to the just aggregated results:
GET /cars/_search { "size" : 0, "aggs" : { "popular_colors" : { "terms" : { "field" : "color" }, "aggs":{ "avg_price": { "avg": { "field": "price" } } } } } }
- Aggs: We added new aggs to the last aggs(popular_colors). Visible metrics are also an aggregation
- avg_price: The name of the aggregation
- avg: The type of measure, here is the average.
- Field: The field of a metric operation
Result:
{ "took": 35, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "popular_colors": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "red", "doc_count": 4, "avg_price": { "value": 32500 } }, { "key": "blue", "doc_count": 2, "avg_price": { "value": 20000 } }, { "key": "green", "doc_count": 2, "avg_price": { "value": 21000 } } ] } } }
You can see that each bucket has its own avg_price field, which is the result of metric aggregation
4.4 barrel nested barrel
In the previous case, we embedded metric operations in buckets. In fact, buckets can not only nest operations, but also nest other buckets. That is to say, in each group, there are more groups.
For example, we want to figure out which manufacturer each color belongs to, and then divide the buckets according to the make field.
GET /cars/_search { "size" : 0, "aggs" : { "popular_colors" : { "terms" : { "field" : "color" }, "aggs":{ "avg_price": { "avg": { "field": "price" } }, "maker":{ "terms":{ "field":"make" } } } } } }
- The original color bucket and avg calculations are unchanged
- Maker: Add a new bucket under the nested aggs called maker
- terms: Buckets are still classified as entries
- filed: This is divided by make field
Some results:
... {"aggregations": { "popular_colors": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "red", "doc_count": 4, "maker": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "honda", "doc_count": 3 }, { "key": "bmw", "doc_count": 1 } ] }, "avg_price": { "value": 32500 } }, { "key": "blue", "doc_count": 2, "maker": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "ford", "doc_count": 1 }, { "key": "toyota", "doc_count": 1 } ] }, "avg_price": { "value": 20000 } }, { "key": "green", "doc_count": 2, "maker": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "ford", "doc_count": 1 }, { "key": "toyota", "doc_count": 1 } ] }, "avg_price": { "value": 21000 } } ] } } } ...
- We can see that the new aggregate maker is nested in the original bucket of each color.
- Each color is grouped according to the make field
- The information we can read:
- There are four red cars in total.
- The average price of a red car is $32,500.
- Three of them were made by Honda Honda and one by BMW.
4.5. Other ways of dividing barrels
As mentioned earlier, there are many ways to divide buckets, such as:
- Date Histogram Aggregation: Grouping by date ladder, such as given a ladder for a week, is automatically grouped weekly.
- Histogram Aggregation: Grouped by numerical ladder, similar to date
- Terms Aggregation: Grouped according to the content of the entry, the content of the entry matches perfectly into a group.
- Range Aggregation: Range grouping of values and dates, specifying start and end, and then grouping by segments
In the last case, we used Terms Aggregation, which divides the buckets according to their entries.
Next, let's learn a few more practical ones:
4.5.1. Stepped bucket Histogram
Principle:
Hisgram is a field of numerical type, grouped according to a certain step size. You need to specify a step value (interval) to divide the step size.
Give an example:
For example, if you have a price field, if you set the interval value to 200, then the ladder will be like this:
0,200,400,600,...
The key of each step is listed above, which is also the starting point of the interval.
If the price of a commodity is 450, which step will it fall into? The calculation formula is as follows:
bucket_key = Math.floor((value - offset) / interval) * interval + offset
Value: The value of the current data, in this case 450
Offset: Initial offset, default 0
interval: step intervals, such as 200
So you get key = Math.floor((450 - 0) / 200) * 200 + 0 = 400
Operate:
For example, we grouped car prices with interval s of 5000:
GET /cars/_search { "size":0, "aggs":{ "price":{ "histogram": { "field": "price", "interval": 5000 } } } }
Result:
{ "took": 21, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "price": { "buckets": [ { "key": 10000, "doc_count": 2 }, { "key": 15000, "doc_count": 1 }, { "key": 20000, "doc_count": 2 }, { "key": 25000, "doc_count": 1 }, { "key": 30000, "doc_count": 1 }, { "key": 35000, "doc_count": 0 }, { "key": 40000, "doc_count": 0 }, { "key": 45000, "doc_count": 0 }, { "key": 50000, "doc_count": 0 }, { "key": 55000, "doc_count": 0 }, { "key": 60000, "doc_count": 0 }, { "key": 65000, "doc_count": 0 }, { "key": 70000, "doc_count": 0 }, { "key": 75000, "doc_count": 0 }, { "key": 80000, "doc_count": 1 } ] } } }
You'll find that there are a lot of buckets with zero documentation in the middle, which looks ugly.
We can add a parameter min_doc_count to 1 to restrict the minimum number of documents to 1, so that buckets with zero number of documents can be filtered.
Example:
GET /cars/_search { "size":0, "aggs":{ "price":{ "histogram": { "field": "price", "interval": 5000, "min_doc_count": 1 } } } }
Result:
{ "took": 15, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 8, "max_score": 0, "hits": [] }, "aggregations": { "price": { "buckets": [ { "key": 10000, "doc_count": 2 }, { "key": 15000, "doc_count": 1 }, { "key": 20000, "doc_count": 2 }, { "key": 25000, "doc_count": 1 }, { "key": 30000, "doc_count": 1 }, { "key": 80000, "doc_count": 1 } ] } } }
Perfect!
If you use kibana to turn the result into a bar chart, it will look better:

Pie chart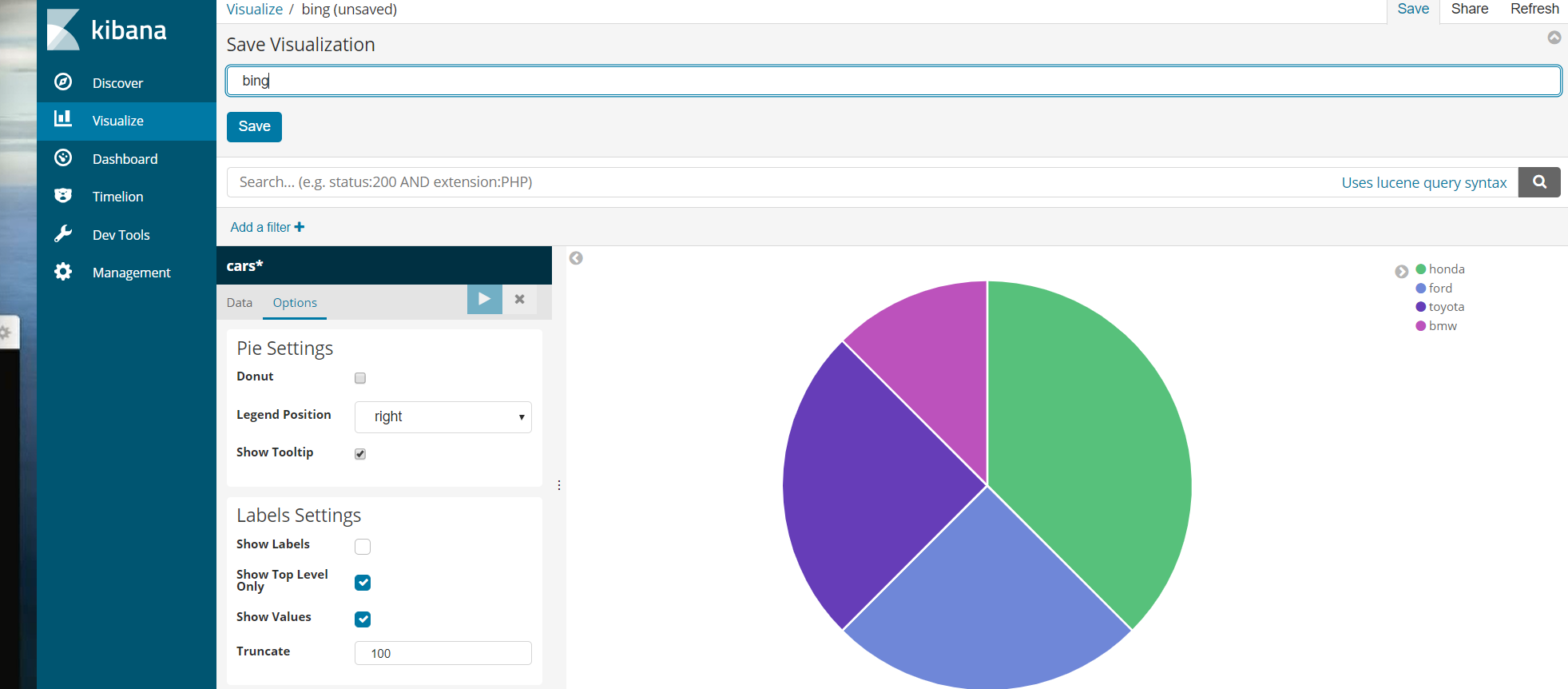
4.5.2. Scope barrel range
Range buckets are similar to ladder buckets in that they group numbers according to stages, but the range method requires you to specify the start and end sizes of each group.