preface
1. Hands on learning and deep learning https://zh-v2.d2l.ai/
2. Notepad https://github.com/d2l-ai/d2l-zh
3. Data operation and data preprocessing
N-dimensional array is the main data structure of machine learning and neural network
Data operation
Data operation implementation
1. First, import torch, which is called pytorch, but we should import torch instead of pytorch.
Tensors represent an array of values that may have multiple dimensions
import torch x=torch.arange(12) #tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) x.shape #Shape attribute to access the shape of the tensor and the total number of elements in the tensor #torch.Size([12]) x.numel() #12 X=x.reshape(3,4) #To change the shape of a tensor without changing the number and value of elements, you can call the reshape function torch.zeros((2,3,4)) #Create a 2 * 3 * 4 full 0 3D array torch.ones((2,3,4)) #Create 2 * 3 * 4 full 1 3D array torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]]) #tensor([[2, 1, 4, 3], # [1, 2, 3, 4], # [4, 3, 2, 1]]) torch.tensor([[[2,1,4,3],[1,2,3,4],[4,3,2,1]]]).shape #torch.Size([1, 3, 4]) x=torch.tensor([1.0,2,4,8]) y=torch.tensor([2,2,2,2]) x+y,x-y,x*y,x/y,x**y '''(tensor([ 3., 4., 6., 10.]), tensor([-1., 0., 2., 6.]), tensor([ 2., 4., 8., 16.]), tensor([0.5000, 1.0000, 2.0000, 4.0000]), tensor([ 1., 4., 16., 64.]))''' torch.exp(x) #tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])

torch.cat(X,Y) combines the two elements together, dim=0, stacked by column, dim=1, side by side by row.
# dim = 0: represents patchsize based splicing # dim = 1: represents channel based splicing # dim = 2: represents based on high splicing # dim = 3: represents width based splicing
#Connect it #Determine by element value X==Y #Output tensor ([[false, true, false, true], # [False, False, False, False], # [False, False, False, False]]) X.sum() #Sum #tensor(66.)
Even if the shapes are different, we can still perform the operation by element by calling the broadcasting mechanism
a=torch.arange(3).reshape((3,1)) b=torch.arange(2).reshape((1,2)) a,b #Output (tensor) ([[0], # [1], # [2]]), # tensor([[0, 1]])) a+b #When the shapes of a and b are different, but the dimensions are the same. They are two-dimensional arrays. We can copy both a and b into a 3 * 2 matrix so that they can be added. (broadcasting mechanism) #Output tensor([[0, 1], # [1, 2], # [2, 3]]) X[-1],X[1:3] #X[-1] takes the elements of the last line, and X[1:3] takes the elements of the second and third lines X[1,2] #Elements with subscript (1,2) X[0:2,:]=12 #Assign 12 to the elements of the first and second lines
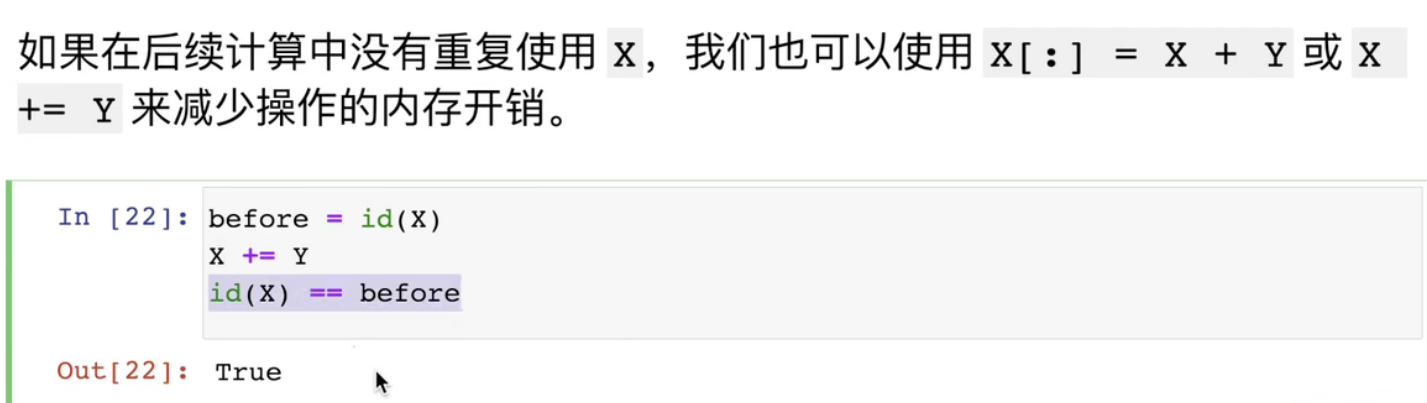
Running some operations may result in allocating memory for new results (don't constantly assign values to a large matrix)
before=id(Y) Y=Y+X id(Y)==before #Output False, which is no longer the original address
#id tells you the unique identification number of the object in python
Z=torch.zeros_like(Y) #The shape and data type of Z and Y are the same, but all elements are 0
print('id(Z):',id(Z))
Z[:]=X+Y
print('id(Z):',id(Z))
#Output: id(Z): 2027639512256
#id(Z): 2027639512256

Data preprocessing implementation
Create a manual dataset and store it in a CSV (comma separated values) file
os. The makedirs () method is used to create directories recursively.
If the subdirectory creation fails or already exists, an OSError exception will be thrown
The syntax format is as follows:
os.makedirs(path, mode=0o777)
parameter
- path – the directory that needs to be created recursively, which can be relative or absolute..
- Mode – permission mode.
Return value
The method has no return value.
os.path()
Python os.path() module - rookie tutorial (runoob.com)
os.path.join(path1[, path2 [,...]]) combines the directory and file names into one path
import os
os.makedirs(os.path.join('D:/term1/Machine learning/LM/data','data'),exist_ok=True)
#A data folder is created under'D:/term1/Machine learning/LM/data '
data_file=os.path.join('D:/term1/Machine learning/LM/data','data','house_tiny.csv')
#A 'house' is created in the data folder created above_ tiny. CSV 'file
#Open folder and write data
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') #Listing
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
#Load the original dataset from the csv file you created
import pandas as pd
data=pd.read_csv(data_file)
print(data)
''' NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000'''
#pandas. The csv () function reads a comma separated value (csv) file into the data frame
In order to deal with missing data, typical methods include interpolation and deletion. Here we consider interpolation
loc function: get the row data through the specific value in the row Index "Index" (for example, take the row with "Index" as "A")
iloc function: get line data by line number (such as the data of the second line)
The fillna() method in pandas can fill the NA/NaN value with the specified method.
Mean
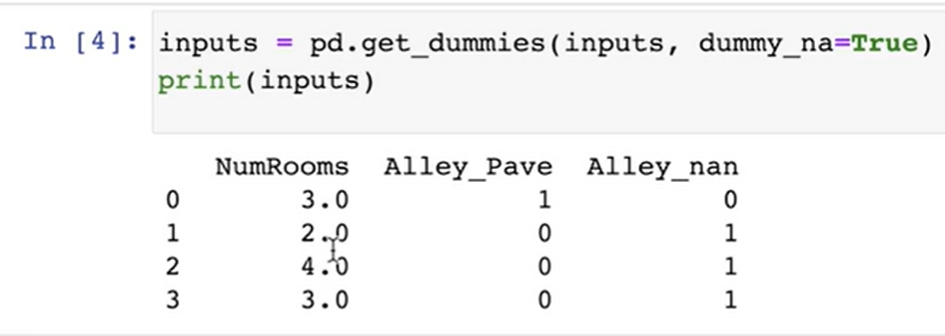
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2] inputs=inputs.fillna(inputs.mean()) print(inputs) ''' NumRooms Alley 0 3.0 Pave 1 2.0 NaN 2 4.0 NaN 3 3.0 NaN'''
For category values or discrete values in inputs, we treat "NaN" as a category
get_dummies is a way to implement one hot encode using pandas.