😈 Blog home page: 🐼 Hello, everyone. My name is classmate Zhang🐼
💖 Welcome to praise 👍 Collection 💗 Leaving a message. 📝 Welcome to discuss! 👀
🎵 This article was originally written by [Hello, my name is classmate Zhang] and started at CSDN 🌟🌟🌟
✨ Boutique column (updated from time to time) [data structure + algorithm] [notes][C language programming learning]
☀️ Boutique article recommendation
[advanced learning notes of C language] III. detailed explanation of string function (1) (sorting out liver explosion and hematemesis, recommended collection!!!)
[notes on basic learning of C language] + [notes on advanced learning of C language] summary (persistence is the only way to gain!)
| preface |
Why write brush notes?
The process of blogging is also a sort and summary of the process of brushing questions. It is a time-consuming but effective method.
When the blog you share helps others, it will bring you extra happiness and happiness.
(the happiness of topic brushing + the happiness of blog is simply double the reward. Double the happiness has wood and QAQ 🙈)
| Topic content |
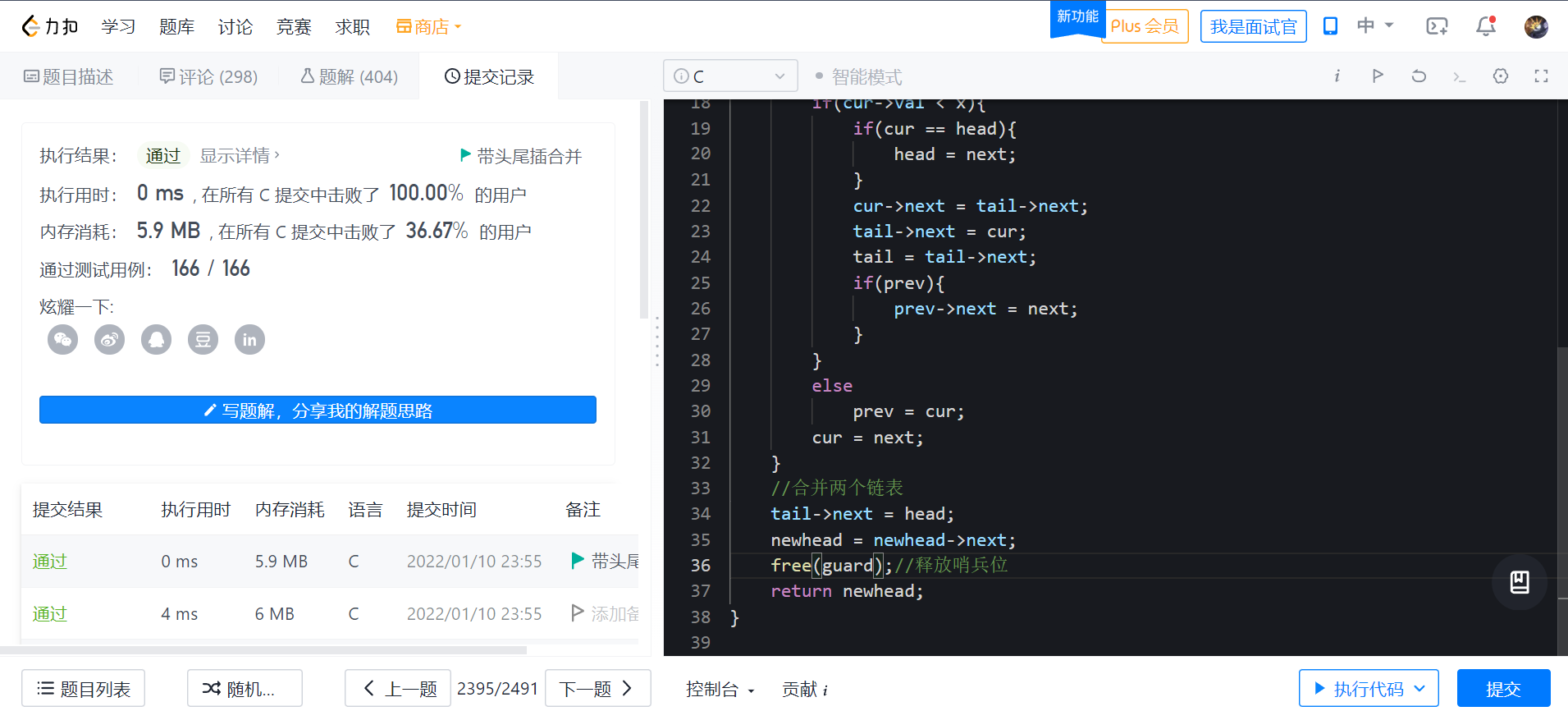
Give you a head node of the linked list and a specific value X. please separate the linked list so that all nodes less than x appear before nodes greater than or equal to X.
You do not need to keep the initial relative position of each node in each partition.
Original question link (click to jump)
| Greedy snake play |
In general, there are two major ideas to achieve the purpose of splitting linked lists. One is to directly perform corresponding operations on the original linked list without creating a new linked list. The other is to create a new linked list, move the original linked list to the new linked list, and achieve the desired effect at the same time.
Let's learn the first idea first. Instead of creating a new linked list, we can operate directly on the original linked list.
For linked list related OJ problems, especially single linked list problems, two special scenarios must be considered: the linked list is empty and there is only one node. In this question, we first judge whether the linked list is empty. If it is empty, we will directly return to the original chain header node head. (this can simplify the difficulty of subsequent thinking and writing code)
if(head == NULL || head->next == NULL)
return head;
Next, we only need to consider the case that the linked list has at least two nodes. First traverse the linked list, find the tail node of the linked list, and then traverse the linked list again. Insert the tail of the node with val value greater than or equal to k after the tail.
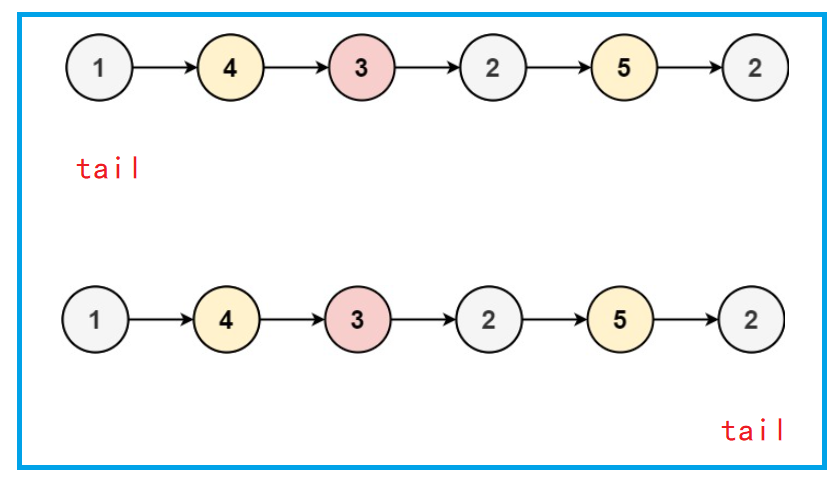
//Tail finding
struct ListNode* tail = head;
while(tail->next){
tail = tail->next;
}
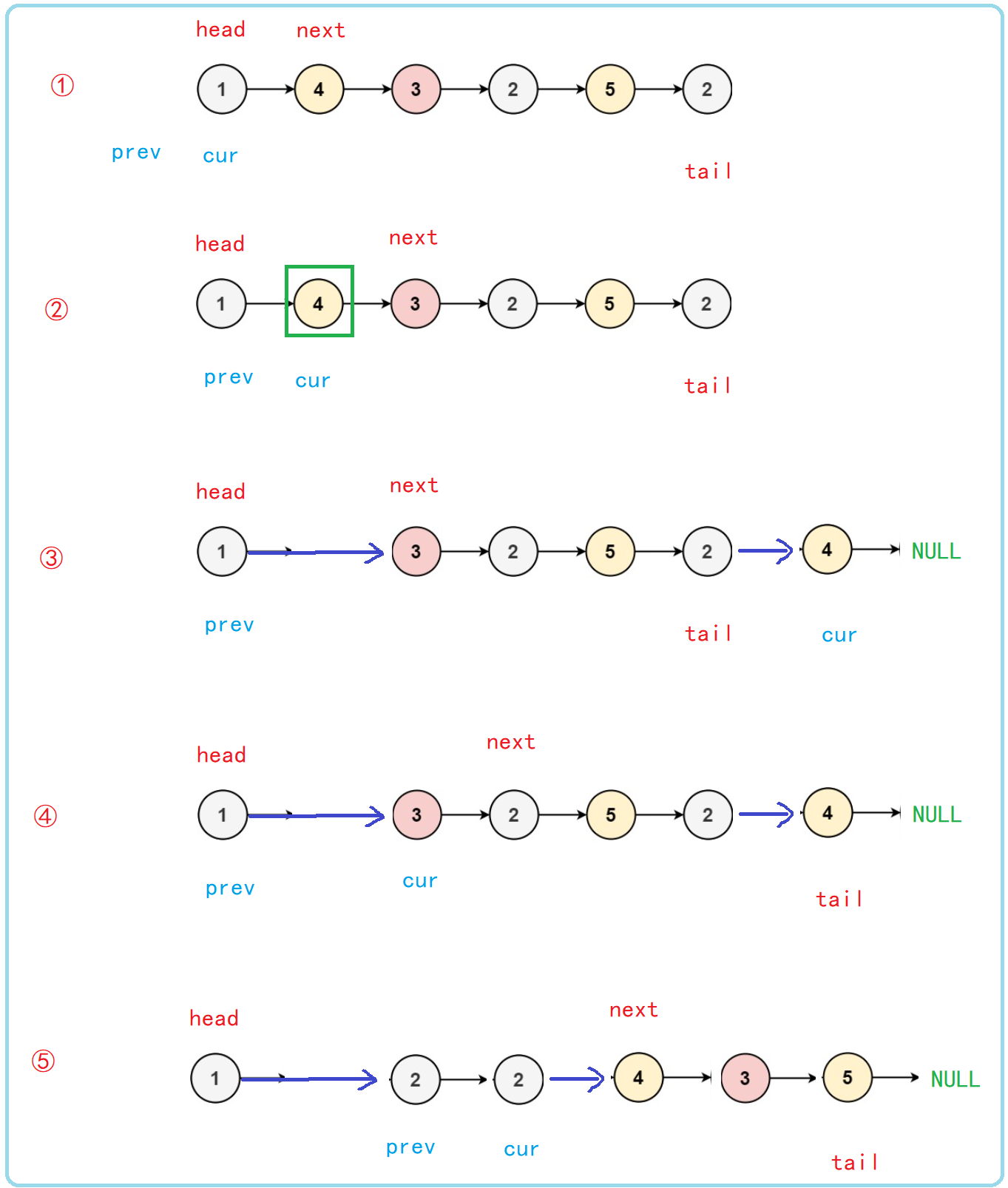
In the process of drawing and analysis, we can find that if cur re traverses the linked list and inserts the end of the previous node greater than or equal to k after the tail, what are the conditions for the termination of the whole process? Is cur coming to the end of the linked list, that is, while (cur! = null)? But the question is, can cur really go to the end of the linked list? If we go further, we will find that it seems that we have entered an dead cycle and will never meet the condition of while termination.
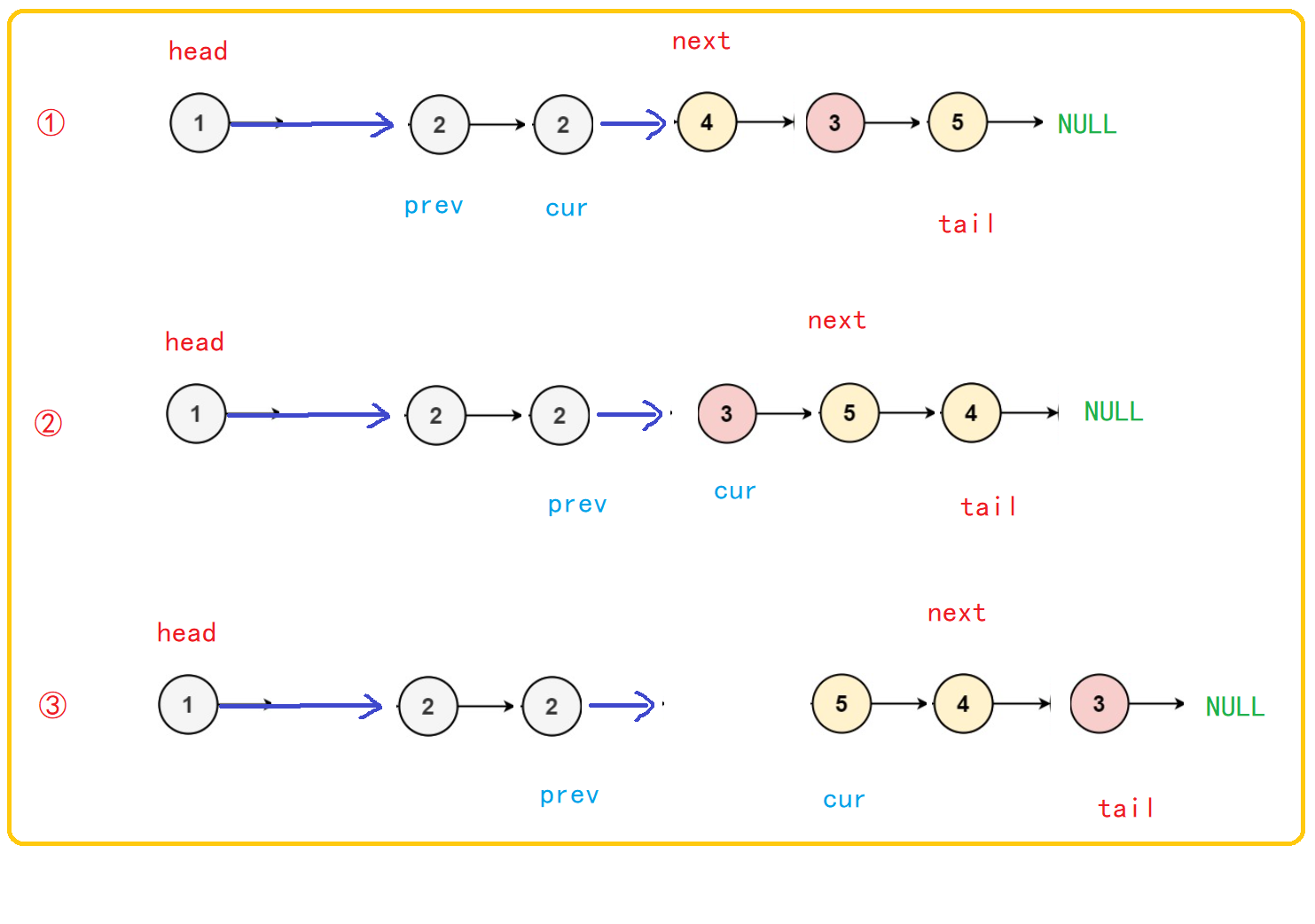
In order to solve this problem, we need a mark point mark to help us determine the stop position. What we want is cur to traverse the linked list instead of an endless loop (like a greedy snake, we eat all the time and end up eating the tail). Therefore, after finding the tail node at the beginning, this position should be marked to help us determine the conditions for the termination of the while loop.
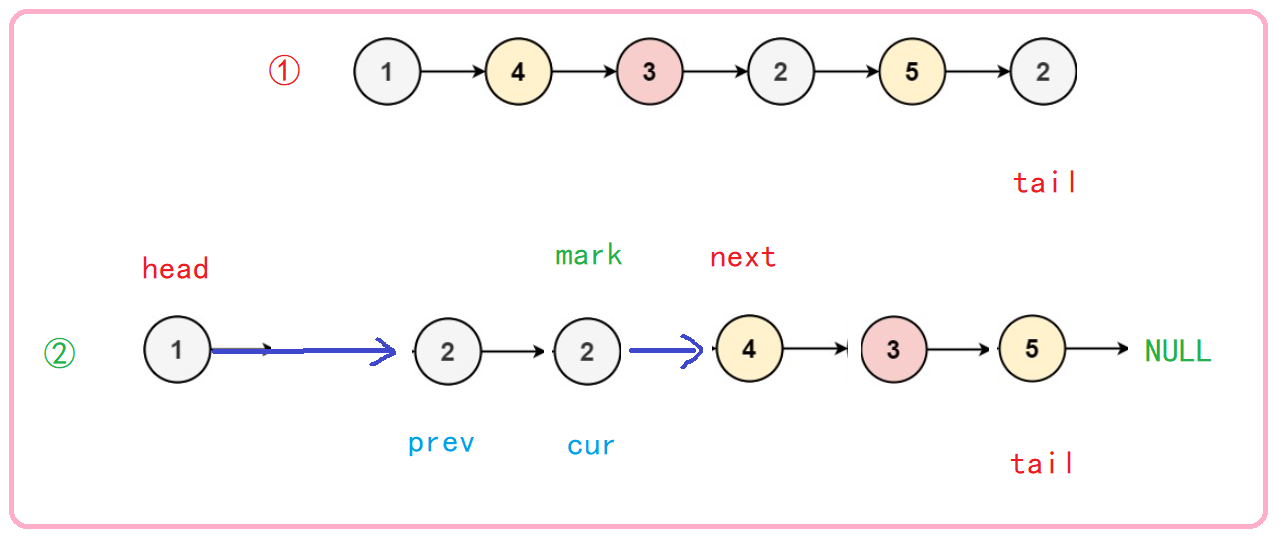
Through graphical analysis, we can determine that cur stops when it reaches the mark point. No matter whether the val value at the mark point is less than k, the position of the point does not need to be changed.
| Complete code |
//Operate on the original linked list
struct ListNode* partition(struct ListNode* head, int x){
if(head == NULL || head->next == NULL)
return head;
//Tail finding
struct ListNode* tail = head;
while(tail->next){
tail = tail->next;
}
//Traverse from the beginning and insert the end of the node Val > = x after the tail
struct ListNode *prev = NULL,*cur = head,*mark = tail;
while(cur != mark){
struct ListNode* next = cur->next;
if(cur->val >= x){
if(cur == head)
head = next;
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
if(prev)
prev->next = next;
}
else{
prev = cur;
}
cur = next;
}
return head;
}
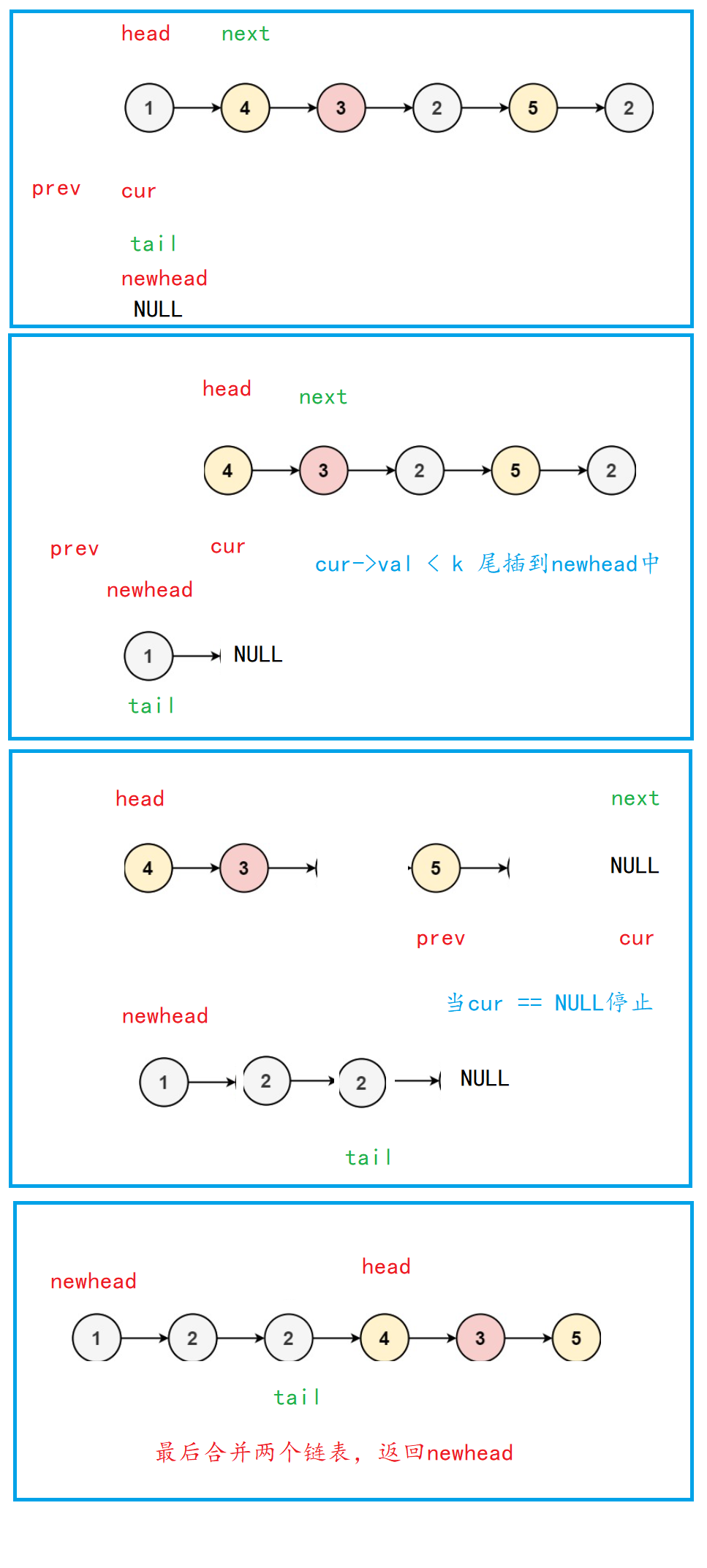
| Tail interpolation merging method |
The specific idea is: insert the end of the node with val value less than K in the original linked list into the new head of the new linked list. In this way, after traversing the original linked list, all nodes with val value less than k will be added to the new linked list newhead. The remaining nodes with val value greater than or equal to K can be directly inserted into the new linked list newhead.
| Algorithm diagram |
| Function implementation |
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode *cur = head,*prev = NULL;
struct ListNode *newhead,*tail;
newhead = tail = NULL;
while(cur){
struct ListNode* next = cur->next;
if(cur->val < x){
if(cur == head){
head = next;
}
if(tail == NULL){
cur->next = tail;
newhead = tail = cur;
}
else{
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
}
if(prev){
prev->next = next;
}
}
else
prev = cur;
cur = next;
}
//Merge two linked lists
if(tail)
tail->next = head;
else
newhead = head;
return newhead;
}
| Code optimization |
In order to simplify the judgment logic inside the function, we can use the head node guard with sentinel bit to optimize the above code. Note that after using the sentinel bit head node, release it to avoid memory leakage!
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode *cur = head,*prev = NULL;
struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));
guard->next = NULL;
struct ListNode *newhead,*tail;
newhead = tail = guard;//The new linked list points directly to the sentry position
while(cur){
struct ListNode* next = cur->next;
if(cur->val < x){
if(cur == head){
head = next;
}
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
if(prev){
prev->next = next;
}
}
else
prev = cur;
cur = next;
}
//Merge two linked lists
tail->next = head;
newhead = newhead->next;
free(guard);//Release the sentry post
return newhead;
}