For reprint, please indicate the source: http://www.cnblogs.com/qm-article/p/8903893.html
I. Introduction
Before introducing the source code, let's first learn about the linked list. Everyone who has touched the data structure knows that there is a kind of structure called linked list. Of course, there are many kinds of linked list, such as the common single-linked list, double-linked list, etc. The single-linked list structure is shown in the following figure (the figure is from Baidu).
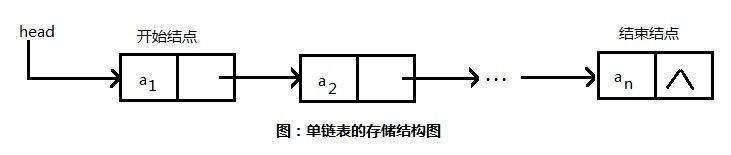
A header node points to the location of the next node, and the a1 node stores the memory location of the a2 node, which forms a single linked list. Let's look at the structure of the double linked list.
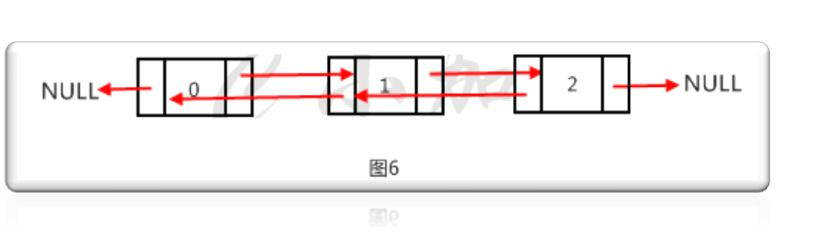
Compared with single linked list structure, each node of double linked list stores one more data, that is, the memory address of its former node. The difference between linked list and array is as follows.
1. The memory of the linked list is not necessarily contiguous, but the memory address of the array must be contiguous.
2. The operation of adding and deleting linked list is fast, and the query of array is fast.
3. Once the memory address is opened, the size of the array is basically fixed, but the size of the linked list is not fixed.
And the java class introduced in this blog is a linked list structure, and it is a two-way linked list. Next, we will analyze it around its use. Speaking of the operation of a data structure, we can only add, delete and check. Next, we will look at the source code design of this class.
Chain List Design
If we don't look at the source code first and let us design a bi-directional linked list with relatively simple functions, what's the idea? If we have learnt how to design a linked list, and the linked list is made up of each node, then we should design an internal node class to represent each node and its attributes. According to the normal operation, there must be the value of the node. The preceding node of the node, the next node of the node, and the constructor of the class, as follows
1 private static class Node{//For simplicity, generics are not used here, only int is used to represent the node worth type. 2 int val; 3 Node pre; 4 Node next; 5 public Node(int val, Node pre, Node next) { 6 super(); 7 this.val = val; 8 this.pre = pre; 9 this.next = next; 10 } 11 12 }
Simply, an internal class is designed. After considering each node, the next step is to consider the whole chain. It must write a class, which contains the internal class Node. As for attributes, because this is a double-linked list, there must be a head node, a tail node, and the length of the linked list, so it is easy to get the following code
1 public class LinkedList { 2 private Node first;//head node 3 private Node last;//Tail node 4 private Node size;//Length of linked list 5 6 7 private static class Node{ 8 int val; 9 Node pre; 10 Node next; 11 public Node(int val, Node pre, Node next) { 12 super(); 13 this.val = val; 14 this.pre = pre; 15 this.next = next; 16 } 17 18 } 19 }
Now that we have designed this class, it must be used, with a data structure, as mentioned earlier, that is, add, delete and check.
2.1. Increase
Here is just a brief introduction to the process of adding. For adding nodes, it can be roughly divided into these categories.
1. Adding nodes before the original node
2. Adding nodes before the original tail node
3. Adding Nodes between Head Node and End Node
Two and three of them, I believe you can see a lot, so how to deal with one? Keep looking.
1. If we increase for the first time, then both the head node and the end node are null, it is very simple to assign the head node and the end node directly with the added node.
2. If it is not the first increase, we need to add the node before the head node. First, we must get the head node. The specific logic is as follows.
1 public void addHeadNode(Node node){ 2 //Assign header node references to temporary nodes to avoid direct operation first variable 3 Node temp = first; 4 if(temp == null){//Represents the first addition 5 first = node;// 1 6 last = node;//Head Node null,that last Nodes must also be null,So assign it to the tail node at the same time 7 }else{ 8 temp.pre = node;//Will be the origin of the nodal point of the ___________ pre Pointer to add node 9 node.next = temp;//The node's next The pointer executes the origin node. 10 first = node;//Assign the add node to the header node ,2 11 } 12 size++;//Length of linked list+1; 13 }
For the above code, the two lines of markup 1 and 2 can actually be merged. Here, in order to distinguish well, they are distinguished.
So for type 2, the principle is similar to type 1, without too much explanation. The code is as follows
1 public void addLastNode(Node node){ 2 Node temp = last;//Temporary node 3 if(temp == null){//First addition 4 first = node; 5 last = node; 6 }else{ 7 temp.next = node;//The original tail node next Pointer Execution Add Node 8 node.pre = temp;//The node's pre Pointer Execution Original Tail Node 9 last = node;//Set the add node as the tail node 10 } 11 size++;//Length of linked list+1 12 }
For type three, compared with 1 and 2, it's a little more complicated, but it's almost the same. To imitate this type as type 2, there are more nodes behind it. The language seems to be unclear. You can just understand that meaning. Here's the logic.
There is a linked list a - > b - > C - > d, (forehead! This is a two-way linked list, the expression is not reflected. If you insert node e directly into B and c, then you must replace node C with a temporary variable, such as f=b.next, in order to ensure that the node is not lost, you must not directly b.next=e, which will lose the node behind C. After that, it is basically the same as Type 2. Finally, make an e.next = f,f,pre = e to ensure the unimpeded node. The code is as follows
1 //preNode Represents inserting after the node node node 2 public void add(Node preNode,Node node){ 3 //It is not checked here.(I was supposed to do something. preNode Is it not?·Verification of Existence or Something) 4 Node nextNode = preNode.next; 5 //The following two lines of code are used for preNode and node Connectivity of nodes 6 preNode.next = node; 7 node.pre = preNode; 8 9 //These two lines of code are guarantees node Node sum nextNode Connectivity of nodes 10 node.next = nextNode; 11 nextNode.pre = node; 12 13 size++; 14 }
2.2. Delete
For deletion of linked list, it can be divided into three categories as well as adding.
1. Delete the original header node and return the value of the deleted node.
2. Delete the original tail node and return the value of the deleted node.
3. Delete a node value between the head node and the end node.
The principle is similar to the addition, but more narrative, direct code
1 //Delete header nodes 2 public int deleteFirstNode(){ 3 Node temp = first; 4 int oldVal = temp.val; 5 Node next = temp.next; 6 if(temp == null){//Explain that the list has no nodes 7 throw new RuntimeException("the class do not have head node"); 8 } 9 first = next; 10 first.pre = null; 11 if(next == null){//If the condition is satisfied, it means that the list has only one node.,Namely first==last by true; 12 last = null; 13 }else{ 14 temp = null; 15 } 16 size--; 17 return oldVal; 18 } 19 20 //Delete tail nodes 21 public int deleteLastNode(){ 22 Node temp = last; 23 int oldVal = last.val; 24 Node pre = temp.pre; 25 if(temp == null){//Explain that the list has no nodes 26 throw new RuntimeException("the class do not have last node"); 27 } 28 last = pre;//Take the previous node of the original tail node as the tail node 29 if(pre == null){//Only one node 30 first = null; 31 }else{ 32 temp = null; 33 } 34 size--; 35 return oldVal; 36 } 37 38 //Delete a node between the head node and the end node. pre by node The preceding node of a node 39 //There are also some special cases where the deletion of a node must be between two nodes. 40 public int delete(Node pre,Node node){ 41 int oldVal = node.val; 42 Node next = node.next; 43 //structure node Connectivity between front and back nodes 44 pre.next = next; 45 next.pre = pre; 46 47 node = null; 48 return oldVal; 49 }
2.3. Amendment
This operation is very simple. Find the node and set the node value to a new value. The search process can not locate subscripts directly like an array. This search process needs to traverse the list, the code is as follows.
1 //true Represents the success of setting values. false Failure to set a value 2 public boolean set(int oldVal,int newVal){ 3 Node temp = first; 4 while(temp != null){ 5 if(temp.val == oldVal){ 6 temp.val = newVal; 7 return true; 8 } 9 temp = temp.next; 10 } 11 return false; 12 }
2.4. Search
Finding and modifying are similar, except that the operation of setting values is omitted. The code is as follows
1 //Return to the lookup node 2 public Node find(int val){ 3 Node temp = first; 4 while(temp != null){ 5 if(temp.val == val){ 6 return temp; 7 } 8 temp = temp.next; 9 } 10 return null; 11 }
In fact, we can find out carefully what to do if the same value. To be honest, we can only find the nearest node to the head node here. If we use generics, we can rewrite hash and equals methods to ensure uniqueness as far as possible.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
The above describes a lot of operations about how to implement a two-way linked list. Now let's look at how jdk source code can be implemented.
3. Source code analysis
With regard to source code analysis, for the principle similar to the previous design, to avoid verbosity, I have just skipped it.
3.1. Increase
There are several additions to LinkedList
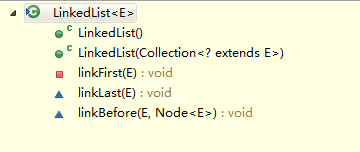

For example, in the left graph, the first and second constructors are of this kind, while the last three methods are private, protected and protected, respectively.
1. Adding Nodes before Head Nodes
The code is also very concise, similar to the previous design code, but more narrative, similar principle, as for the role of modCount, please refer to a previous blog. Source Code Analysis of ArrayList of Sets
1 private void linkFirst(E e) { 2 final Node<E> f = first; 3 final Node<E> newNode = new Node<>(null, e, f); 4 first = newNode; 5 if (f == null) 6 last = newNode; 7 else 8 f.prev = newNode; 9 size++; 10 modCount++; 11 }
2. Adding nodes after tail nodes
1 void linkLast(E e) { 2 final Node<E> l = last; 3 final Node<E> newNode = new Node<>(l, e, null); 4 last = newNode; 5 if (l == null) 6 first = newNode; 7 else 8 l.next = newNode; 9 size++; 10 modCount++; 11 }
3. Adding Nodes between Head Node and End Node
1 void linkBefore(E e, Node<E> succ) { 2 // assert succ != null; 3 final Node<E> pred = succ.prev; 4 final Node<E> newNode = new Node<>(pred, e, succ); 5 succ.prev = newNode; 6 if (pred == null) 7 first = newNode; 8 else 9 pred.next = newNode; 10 size++; 11 modCount++; 12 }
As for the right figure, this class is exposed to other classes for use. But in the end, one of the three methods mentioned above is invoked to complete the additional operation.
The commonly used add(E) method is added after the tail node by default.
As for the add(int,E) method, we should pay attention to it. According to our normal guess, first we traverse the list directly, find a node, and insert a new node after that node, but!!! That's not the case here. It's like an array that inserts directly at a certain location. Don't panic, paste the code first.
1 public void add(int index, E element) { 2 checkPositionIndex(index);//inspect index Correctness 3 4 if (index == size)//Insert after the end node 5 linkLast(element); 6 else 7 linkBefore(element, node(index));//Notice here node(int)Method 8 } 9 10 11 Node<E> node(int index) { 12 // assert isElementIndex(index); 13 14 if (index < (size >> 1)) { 15 Node<E> x = first; 16 for (int i = 0; i < index; i++) 17 x = x.next; 18 return x; 19 } else { 20 Node<E> x = last; 21 for (int i = size - 1; i > index; i--) 22 x = x.prev; 23 return x; 24 } 25 }
You can see the operation in the node method, which is a little more efficient than traversing the list directly from the original node. It's a bit like half-search, finding the corresponding node, and then doing something similar.
3.2, delete
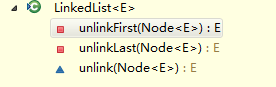

Like the addition method, the three deletion methods of the left graph are the core, and the deletion of the right one is exposed to other methods. The principle is similar to the previous one. The last two methods of the right graph are afraid of having two identical obj, so they are classified into the following categories: from the beginning to the end, and from the end to the end, they are found and deleted.
Where remove() also removes the header node by default
3.3, modify

This class has only one method.
The node method is also used to find the node corresponding to index, and then set the value. And return
3.4, query
get (int) also uses node method to find the corresponding node node
3.5, summary
For LinkedList's other methods, we don't introduce them here. We usually use them around adding, deleting and altering checks, so we only introduce these four categories here.
4. Comparisons with Array List
1. Their data structures are different. ArrayList's structure is an array, LinkedList's structure is a linked list. All their memory addresses are sorted differently. One is continuous and the other is discontinuous.
2. In theory, the maximum length of ArrayList is Integer.MAX_VALUE, while the length of linked list is theoretically unlimited.
3. ArrayList increases or deletes slowly, queries are fast, LinkedList increases or deletes quickly, and queries are slow. The opposite is true.
4. Both can add null elements and can add the same elements.
5. Both have thread security issues
5, last
For this class, I think we only need to understand its internal principle of adding, deleting and modifying, its data structure, and the difference between it and Array List.
If there are any shortcomings or mistakes, I hope you will correct them.