LinkList source code analysis
@auther worry free youth
@creatTime 2020/07/16
1, Foreword
This time, let's take a look at the second of the common lists - LinkedList. When analyzing ArrayList earlier, we mentioned that LinkedList is a linked List structure. In fact, it is similar to the LinkedHashMap structure we talked about when analyzing map, but it is much simpler. Let's take a look at its specific structure in detail today, And the scenarios used.
2, LinkedList structure overview
Before looking at the specific structure, let's take a look at its inheritance relationship:
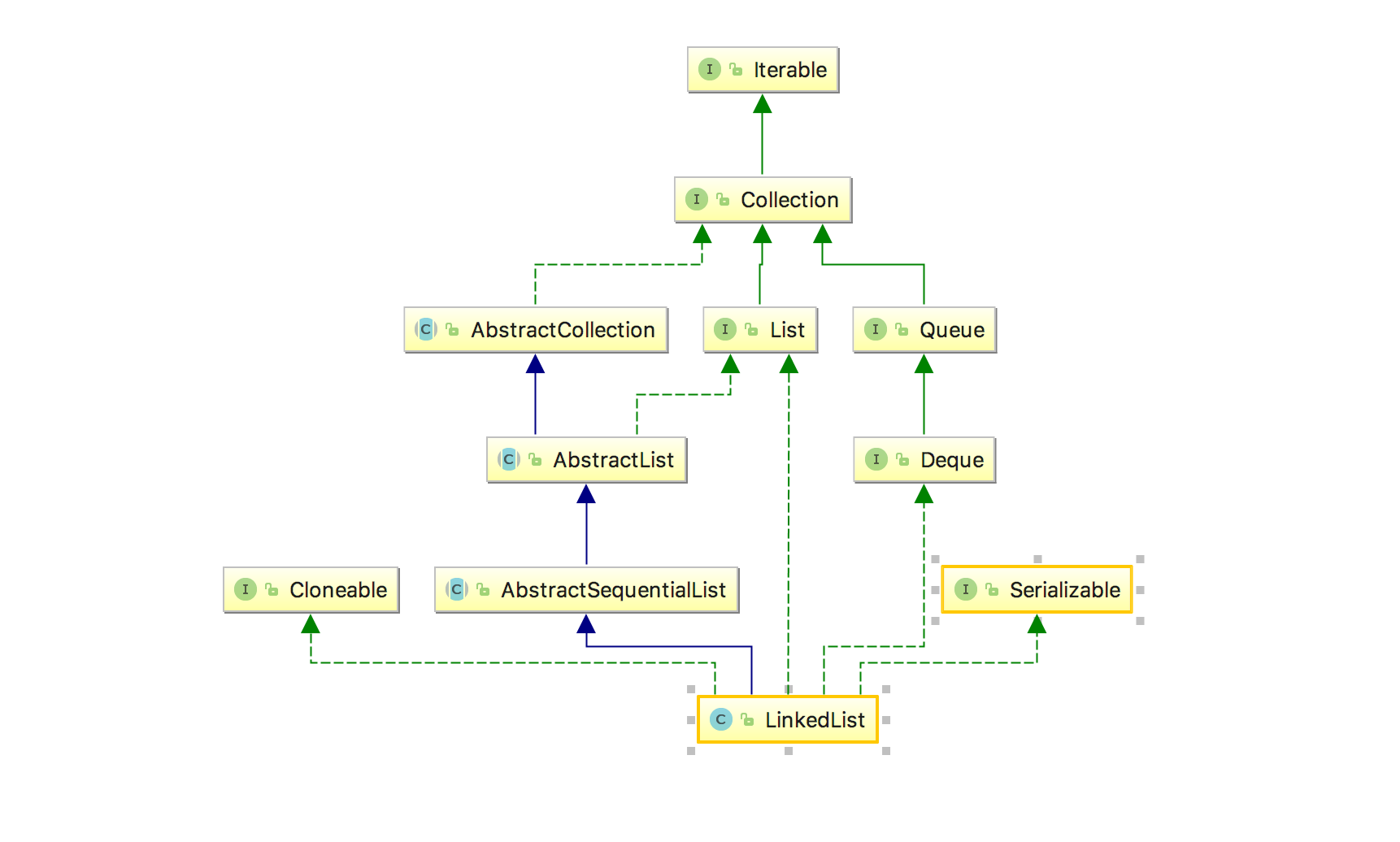
Unlike ArrayList, LinkedList inherits AbstractSequentialList. It can be seen from the word Sequential that the abstract class implements the structure of Sequential access, because it can be inferred that it may be related to the linked list.
In addition, it is worth noting that the Deque interface, the origin of the class name is "double ended queue", that is, a two-way queue, that is, queue operations can be performed from the head and tail.
So to sum up, we can know that LinkedList is a two-way linked list data structure:
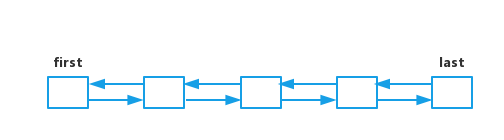
LinkedList can be traversed from the head and tail.
3, LinkedList source code reading
3.1 LinkedList member variable
// Number of elements in list transient int size = 0; // Head node of linked list transient Node<E> first; // Tail node of linked list transient Node<E> last;
The internal class Node called Node is the key to implementing the linked list:
private static class Node<E> {
// Actual stored elements
E item;
// Last element
Node<E> next;
// Previous element
Node<E> prev;
// The order of constructor elements is before, after and after. It's like waiting in line
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3.2 LinkedList construction method
Because the linked list structure is adopted, LinkedList does not have the construction method of specified capacity like ArrayList, so here we mainly talk about the construction method of pass through set.
public LinkedList(Collection<? extends E> c) {
// Call the construction method without parameters, but there is nothing in it
this();
// Add the elements in the c set to the list
addAll(c);
}
Considering that addall (collection <? Extensions E > C) is a public method, consider adding elements at the end of the linked list when elements already exist in the list:
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// Check whether the index is correct, i.e. between 0-size
checkPositionIndex(index);
// Convert collection to array
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// pred is the preceding element and succ is the successor element
Node<E> pred, succ;
// Initialize pred and succ.
if (index == size) {
// index == size, indicating that the position of the element to be inserted is at the end of the linked list. The post element is null, and the previous element is last
succ = null;
pred = last;
// index != size, indicating that it is inserted in the middle of the linked list. pred is the prev of the original index, and succ is the original element
} else {
succ = node(index);
pred = succ.prev;
}
// Find out the relationship between the front and back elements, that is, traverse the array and add them one by one
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
// If the subsequent element is empty, the last element after insertion is prev last
if (succ == null) {
last = pred;
// Otherwise, the relationship between the last element and the previous element is maintained
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
The logic for traversing the Collection and inserting the linked list should be very clear:
- Call the Node's construction method according to the pre self post relationship for initialization.
- Since the previous element pred may be empty (constructor call), if it is judged that pred is empty, the initialized element is the header node
- Otherwise, maintain the direct relationship between pred and the new node newNode.
- Use the new node as pred to prepare for the next element insertion
In addition, as a two-way linked list, the node(int index) method also uses this feature to traverse faster:
Node<E> node(int index) {
// If the index is in the first half of the linked list, the traversal starts from the head node
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
// If the index is in the second half of the linked list, it will traverse from the tail node
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
The elements in the first half are traversed from scratch, and the elements in the second half are traversed from the tail.
3.3 important methods of LinkedList
3.3.1 add(E e)
First, let's talk about the specific idea. As a linked list structure, adding elements is to insert elements at the end of the linked list. In this process, we should consider:
- What should I do if the last element is null
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
// Record last node
final Node<E> l = last;
// Initialize a new node
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// Judge the last node
if (l == null)
first = newNode;
else
l.next = newNode;
// Number of elements + 1
size++;
// Add modification times
modCount++;
}
The general processing is similar to linkNodeLast of LinkedHashMap.
3.3.2 remove(Object o)
Similarly, let's talk about the specific treatment ideas first:
- Since the inserted element may be null, judge O. otherwise, null pointer exceptions will be reported whether o is null or the element is null during traversal
- After finding the element, re maintain the relationship between the front and back elements, taking into account whether the element is at the beginning and end
public boolean remove(Object o) {
// Judgment of whether it is empty
if (o == null) {
// Traverse the linked list to find elements
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
// Once found, re maintain the relationship between the elements before and after deleting the element
unlink(x);
return true;
}
}
// Same as above
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
When unlink ing, you need to consider the second point mentioned earlier:
E unlink(Node<E> x) {
final E element = x.item;
// Elements before and after recording
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// If prev is null, it means that x node is the first node. After deletion, next is the first node
if (prev == null) {
first = next;
// Otherwise, the next element of prev is the next element of x
} else {
prev.next = next;
// Set to null to facilitate prev's GC
x.prev = null;
}
// ditto
if (next == null) {
last = prev;
} else {
next.prev = prev;
// Set to null to facilitate the GC of next
x.next = null;
}
// Set to null for GC convenience
x.item = null;
size--;
modCount++;
return element;
}
3.3.3 listIterator(int index)
Finally, the author makes a brief analysis on the implementation of iterator.
public Iterator<E> iterator() { // Call the method return listiterator() in AbstractList;} public ListIterator<E> listIterator() { return listIterator(0);}
What iterator() calls is actually the listIterator() method. Different implementation classes will implement different methods. In LinkedList, what is it like:
public ListIterator<E> listIterator(int index) { checkPositionIndex(index); return new ListItr(index);}
The call returns the ListItr object.
private class ListItr implements ListIterator<E> { // Record the last returned element private node < E > lastreturned// Record the next element private node < E > next; private int nextIndex; // It is used to judge whether there are changes to elements during iteration. Private int expectedmodcount = modcount; Listitr (int index) {/ / initialize next to return next = (index = = size)? Null in the next method: node (index); nextindex = index;} public boolean hasNext() { return nextIndex < size; } Public e next() {/ / judge whether there is any change to the element. If so, throw an exception checkforcomodification(); if (! Hasnext()) throw new nosuchelementexception(); // The next element in next () is the result to be returned lastreturned = next; next = next. next; nextIndex++; return lastReturned. item; } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }}
From the source code, we can know why we throw exceptions when we modify the collection in the process of iteration. The purpose of doing so is to prevent problems caused by multithreading operating the same collection.
4, Usage scenario of LinkedList
As a feature of the linked list structure, LinkedList can ensure its endpoint operations, such as insertion and deletion, which is faster than ArrayList. The reason is very simple. After ArrayList is deleted, the following elements must be moved forward every time (although the copy method is adopted), and LinkedList only needs to maintain the relationship between the front and rear elements again.
Quote from Java programming thought:
The best practice may be to use ArrayList as the default choice. Only when you need to use additional functions (personally understood as the operation of Queue), or when the performance of the program deteriorates due to frequent insertion and deletion from the middle of the table, you can choose LinkedList.
5, Summary
For frequent insert and delete operations in the middle of the collection, or when the queue feature needs to be used, we can consider using LinkedList. Finally, thank you for watching. If there is something wrong, please correct it and make progress with you!