Linux awk command details
1, awk
- working principle
Read the text line by line. By default, the text is separated by a space or tab key. Save the separated fields to the built-in variable, and execute the editing command according to the mode or condition.
The sed command is often used to process a whole line, while awk prefers to divide a line into multiple "fields" and then process it. The reading of awk information is also read line by line. The execution result can be printed and displayed through the function of print. In the process of using the awk command, you can use the logical operators "& &" to represent "and", "||" to represent "or" and "!" Means "not"; Simple mathematical operations can also be carried out, such as +, -, *, /,%, ^ represent addition, subtraction, multiplication, division, remainder and power respectively.
- Command format
awk option 'Mode or condition {operation}' File 1 file 2
awk -f Script file 1 file 2
- The common built-in variables of awk (which can be used directly) are as follows
- FS: column delimiter. Specifies the field separator for each line of text, which defaults to spaces or tab stops. Same as "- F"
- NF: the number of fields in the currently processed row.
- NR: the line number (ordinal number) of the currently processed line.
- $0: the entire line content of the currently processed line.
- $n: the nth field (column n) of the current processing line.
- FILENAME: the name of the file being processed.
- Rs: line separator. When awk reads data from a file, it will cut the data into many records according to the definition of RS, while awk only reads one record at a time for processing. The default is' \ n '
- Output text by line
awk '{print}' 1.txt #Output all content
awk '{print $0}' 1.txt #Output all content
awk 'NR==1,NR==3{print}' 1.txt #Output lines 1 ~ 3
awk '(NR>=1)&&(NR<=3){print}' 1.txt #Output lines 1 ~ 3

awk 'NR==1||NR==3{print}' testfile2 #Output the contents of line 1 and line 3
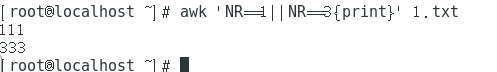
awk '(NR%2)==1{print}' testfile2 #Output the contents of all odd rows
awk '(NR%2)==0{print}' testfile2 #Output the contents of all even lines
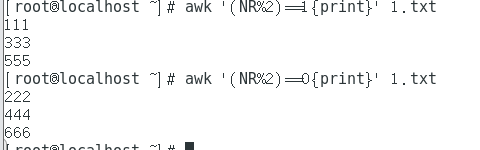
awk '/^root/{print}' /etc/passwd #Output lines starting with root
awk '/nologin$/{print}' /etc/passwd #Output lines ending with nologin
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd #Count the number of lines ending in / bin/bash, which is equivalent to grep - C "/ bin/bash $" / etc / passwd
BEGIN mode means that the actions specified in BEGIN mode need to be executed before processing the specified text; awk processes the specified text and then executes the actions specified in the END mode. In the END {} statement block, statements such as print results are often placed
- Output text by field
awk -F ":" '{print $3}' /etc/passwd #Outputs the third field in each row (separated by spaces or tab stops)

awk -F ":" '{print $1,$3}' /etc/passwd #Output the 1st and 3rd fields in each row

awk -F ":" '$3<5{print $1,$3}' /etc/passwd #Output the contents of the 1st and 3rd fields whose value of the 3rd field is less than 5

awk -F ":" '!($3<200){print}' /etc/passwd #Output the row whose value of the third field is not less than 200
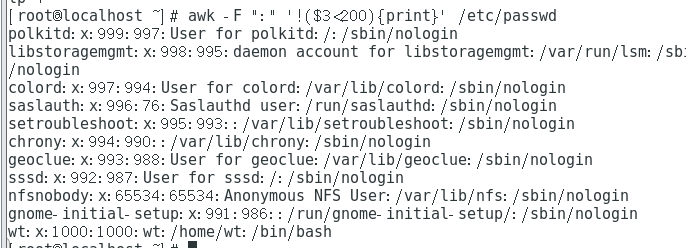
awk 'BEGIN {FS=":"};{if($3>=200){print}}' /etc/passwd #First process the content of BEGIN, and then print the content in the text
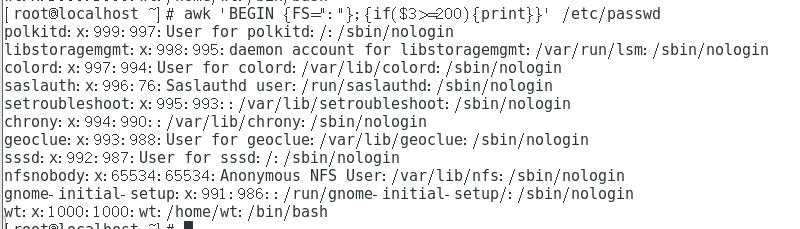
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd #($3>$4)?$ 3: $4 ternary operator: if the value of the third field is greater than the value of the fourth field, assign the value of the third field to max; otherwise, assign the value of the fourth field to max
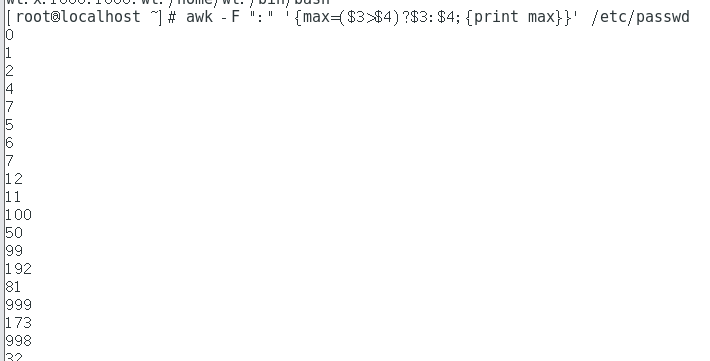
awk -F ":" '{print NR,$0}' /etc/passwd #Output the content and line number of each line. After each record is processed, the NR value is increased by 1
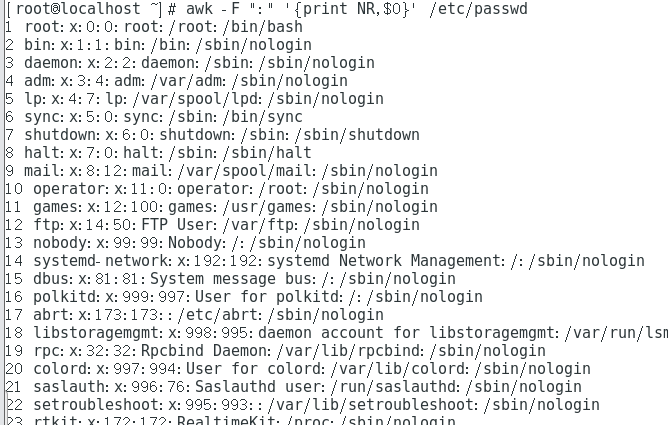
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd #The output is colon delimited and the seventh field contains the first field of the row of / bash
awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd #Output the first and second fields of the row with root and 7 fields in the first field

awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd #The seventh field of the output is not all rows with either / bin/bash or / sbin/nologin
- Call Shell commands through pipes, double quotes
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' #Count the number of text paragraphs separated by colons. In the END {} statement block, statements such as print results are often placed

awk -F: '/bash$/{print | "wc -l"}' /etc/passwd #Call the wc -l command to count the number of users using bash, which is equivalent to grep -c "bash$" /etc/passwd
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)}' #View current memory usage percentage

top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}' #View the current CPU idle rate (-b -n 1 indicates that only one output is required)

date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S" #Displays the last system restart time, which is equivalent to uptime; second ago is the time before the display. The time format of + "% F% H:% m:% s" is equivalent to + "% Y -% m -% d% H:% m:% s"

awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}"%"}' #Call the w command and use it to count the number of online users

When there is no redirection character "<" or "|" around getline, getline acts on the current file and reads the first line of the current file to the variable var or $0 followed by it; It should be noted that since awk has read in a row before processing getline, the return resu lt of getline is interlaced.
When there is a redirection character "<" or "|" around getline, getline acts on the directional input file. Since the file has just been opened and has not been read into a line by awk, but only read into by getline, getline returns the first line of the file, not interlaced.
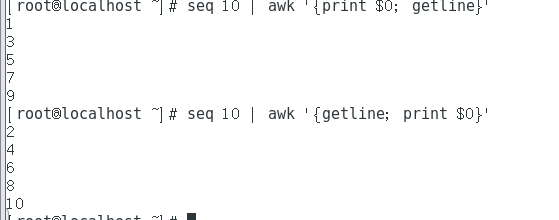
seq 10 | awk '{print $0; getline}'
seq 10 | awk '{getline; print $0}'