preface
Look at the source code of linux kernel. You can't get around the double linked list structure of linux kernel.
This article will introduce the double linked list structure in the kernel. because The hook of LSM is inserted into the bpf system call Therefore, we need to take a brief look at the hash table structure.
Kernel code referenced in this article: linux-v5.6
Reference video: 1.3 double linked list structure of Linux kernel | 1.4 source code analysis - in the kernel
Reference blog: Linux kernel linked list - just read this article | Principle and application of hash table in LINUX
See the warehouse for details of the codes in this article: linux/code/list
Kernel double linked list structure
The double linked list structure in the kernel has only pointer field and no data field. When used, the double linked list structure is embedded into other structures.
struct list_head: via
struct list_head {
struct list_head *next, *prev;
};
Looking at the source code in the way of data structure is very boring. We introduce the double linked list structure in the kernel in the form of examples.
Because the double linked list structure is used in the kernel, we can import the code in a modular way.
Perhaps you can also choose to transplant the double linked list structure used by the kernel to user space. Because it's just a data structure. Find a list of user space on the Internet h: list. Application of H in user mode
Simple use 1
Sample code
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct person
{
struct list_head list;
int age;
};
int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos;
INIT_LIST_HEAD(&person1.list);
for (i = 0;i < 5;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*10;
list_add(&p->list,&person1.list);
}
list_for_each(pos, &person1.list) {
printf("age = %d\n",((struct person *)pos)->age);
}
return 0;
}
We nested the double linked list structure into the person structure. The data structure in the code is shown in the figure below.
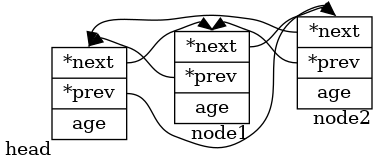
Related source code
At this point, let's take a look at INIT_LIST_HEAD,list_add,list_ for_ Source code of each.
INIT_LIST_HEAD: via
You can see INIT_LIST_HEAD will list_ The next and prev pointers in the head structure point to themselves.
/**
* INIT_LIST_HEAD - Initialize a list_head structure
* @list: list_head structure to be initialized.
*
* Initializes the list_head to point to itself. If it is a list header,
* the result is an empty list.
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
WRITE_ONCE: via . Refer to: Read in Linux kernel_ Once and WRITE_ONCE macro
READ_ONCE and WRITE_ONCE macro can only ensure that the read and write operations are not optimized by the compiler, resulting in problems in multithreading execution.
#define WRITE_ONCE(x, val) \
({ \
union { typeof(x) __val; char __c[1]; } __u = \
{ .__val = (__force typeof(x)) (val) }; \
__write_once_size(&(x), __u.__c, sizeof(x)); \
__u.__val; \
})
// For ease of reading, rearrange the above structure
#define WRITE_ONCE(x, val)
({
// Define a consortium, create a consortium variable and assign a value to it
// __ c can be used as a pointer to this consortium
union {
typeof(x) __val;
char __c[1];
} __u = { .__val = (__force typeof(x)) (val) };
__write_once_size(&(x), __u.__c, sizeof(x));
__u.__val;
})
static __always_inline void __write_once_size(volatile void *p, void *res, int size)
{
switch (size) {
case 1: *(volatile __u8 *)p = *(__u8 *)res; break;
case 2: *(volatile __u16 *)p = *(__u16 *)res; break;
case 4: *(volatile __u32 *)p = *(__u32 *)res; break;
case 8: *(volatile __u64 *)p = *(__u64 *)res; break;
default:
barrier();
__builtin_memcpy((void *)p, (const void *)res, size);
barrier();
}
}
list_add: via
As can be seen from the code, this is header insertion.
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
list_for_each: via
Here is simply the traversal of double linked list.
/** * list_for_each - iterate over a list * @pos: the &struct list_head to use as a loop cursor. * @head: the head for your list. */ #define list_for_each(pos, head) \ for (pos = (head)->next; pos != (head); pos = pos->next)
Easy to use 2
Bad sample code
When embedding the linked list structure this time, we did not embed the linked list structure at the beginning.
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct person
{
int age;
struct list_head list;
};
int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos;
INIT_LIST_HEAD(&person1.list);
for (i = 0;i < 5;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*10;
list_add(&p->list,&person1.list);
}
list_for_each(pos, &person1.list) {
printf("age = %d\n",((struct person *)pos)->age);
}
return 0;
}
Run, output error structure.
age = -692075768 age = -692075800 age = -692075832 age = -692075864 age = 2145063752
The reason for the error is also simple. Because ((struct person *) POS) - > age is the wrong cast. The position pointed by the list at this time is not at the beginning of the whole structure.
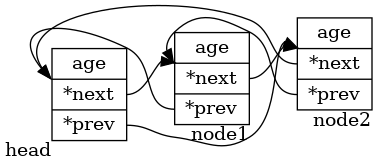
So how? If the traversal pointer can be shifted forward by one position before forced conversion when taking value. Then the problem is solved.
Correct sample code
list.h provides a list_entry is used to solve the above problems. list_ The source code of entry is expanded in the following section.
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct person
{
int age;
struct list_head list;
};
int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos;
INIT_LIST_HEAD(&person1.list);
for (i = 0;i < 5;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*10;
list_add(&p->list,&person1.list);
}
list_for_each(pos, &person1.list) {
p = list_entry(pos,struct person,list);
printf("age = %d\n",p->age);
}
return 0;
}
Related source code
list_entry: via
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. */ #define list_entry(ptr, type, member) \ container_of(ptr, type, member)
container_of: via
Type check first; Then, the starting position of the structure is calculated according to the offset.
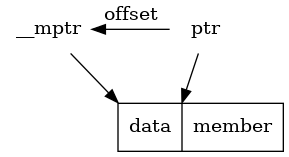
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \
!__same_type(*(ptr), void), \
"pointer type mismatch in container_of()"); \
((type *)(__mptr - offsetof(type, member))); })
/**
* BUILD_BUG_ON_MSG - break compile if a condition is true & emit supplied
* error message.
* @condition: the condition which the compiler should know is false.
*
* See BUILD_BUG_ON for description.
*/
#define BUILD_BUG_ON_MSG(cond, msg) compiletime_assert(!(cond), msg)
/* Are two types/vars the same type (ignoring qualifiers)? */
#define __same_type(a, b) __builtin_types_compatible_p(typeof(a), typeof(b))
#undef offsetof
#ifdef __compiler_offsetof
#define offsetof(TYPE, MEMBER) __compiler_offsetof(TYPE, MEMBER)
#else
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#endif
Correct sample code follow-up
Above, we use list_entry modifies the pointer position to traverse the double linked list. The kernel also provides corresponding traversal functions.
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct person
{
int age;
struct list_head list;
};
int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos;
INIT_LIST_HEAD(&person1.list);
for (i = 0;i < 5;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*10;
list_add(&p->list,&person1.list);
}
list_for_each_entry(p, &person1.list,list){
printf("age = %d\n",p->age);
}
return 0;
}
Related source code
list_for_each_entry: via
As you can see, its implementation is that the wrapper uses list_entry.
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_head within the struct. */ #define list_for_each_entry(pos, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member); \ &pos->member != (head); \ pos = list_next_entry(pos, member)) /** * list_first_entry - get the first element from a list * @ptr: the list head to take the element from. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. * * Note, that list is expected to be not empty. */ #define list_first_entry(ptr, type, member) \ list_entry((ptr)->next, type, member) /** * list_last_entry - get the last element from a list * @ptr: the list head to take the element from. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. * * Note, that list is expected to be not empty. */ #define list_last_entry(ptr, type, member) \ list_entry((ptr)->prev, type, member)
Easy to use 3
Sample code
The following shows how to delete elements during traversal.
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct person
{
int age;
struct list_head list;
};
int main(int argc,char **argv)
{
int i;
struct person *p;
struct person person1;
struct list_head *pos;
INIT_LIST_HEAD(&person1.list);
for (i = 0;i < 5;i++) {
p = (struct person *)malloc(sizeof(struct person ));
p->age=i*10;
list_add(&p->list,&person1.list);
}
// Mode 1
// list_for_each_entry(p, &person1.list,list){
// if(p->age == 30){
// list_del(&p->list);
// break;
// }
// }
// Mode 2
// list_for_each_entry(p, &person1.list,list){
// if(p->age == 30){
// struct person *tmp = list_next_entry(p, list);
// list_del(&p->list);
// p = tmp;
// }
// }
// Mode 3
struct person *n;
list_for_each_entry_safe(p,n, &person1.list,list){
if(p->age == 30){
list_del(&p->list);
free(p);
}
}
list_for_each_entry(p, &person1.list,list){
printf("age = %d\n",p->age);
}
return 0;
}
If you delete elements when traversing the linked list. You need to save the location of subsequent traversal nodes first.
We can use list_ for_ each_ The entry is traversed, and the location of subsequent nodes is saved before deletion.
We can also use the list provided by the kernel_ for_ each_ entry_ safe. Its principle is like this, that is, save the location of subsequent nodes.
Related source code
list_for_each_entry_safe: via
Add a temporary node pointer to save the location of subsequent nodes.
/** * list_for_each_entry_safe - iterate over list of given type safe against removal of list entry * @pos: the type * to use as a loop cursor. * @n: another type * to use as temporary storage * @head: the head for your list. * @member: the name of the list_head within the struct. */ #define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member), \ n = list_next_entry(pos, member); \ &pos->member != (head); \ pos = n, n = list_next_entry(n, member))
Hash table structure
For the introduction of hash table, see: Hash table
The hash table in the kernel is well organized in this blog: Principle and application of hash table in LINUX
Copy the contents of this section from the link above
Definition of hash table
Hash table (also known as hash table) is a data structure that directly accesses the memory storage location according to the Key. In other words, it accesses the records by calculating a function about the Key value and mapping the data of the required query to a position in the table, which speeds up the search speed. This mapping function is called hash function, and the array storing records is called hash.
When using keywords to calculate the storage address through hash function, conflicts will inevitably occur. The usual methods to deal with conflicts are: open addressing method (linear detection, square detection), separate linked list method, double hash and re hash. linux uses the single linked list method, that is, it uses the two-way linked list implementation introduced above to save all elements hashed to the same storage location in a linked list.
hlist_head | hlist_node : via
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
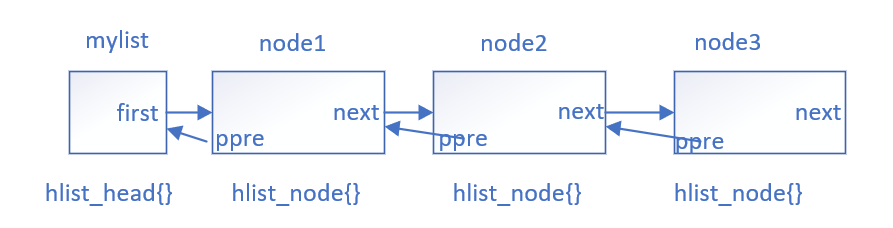
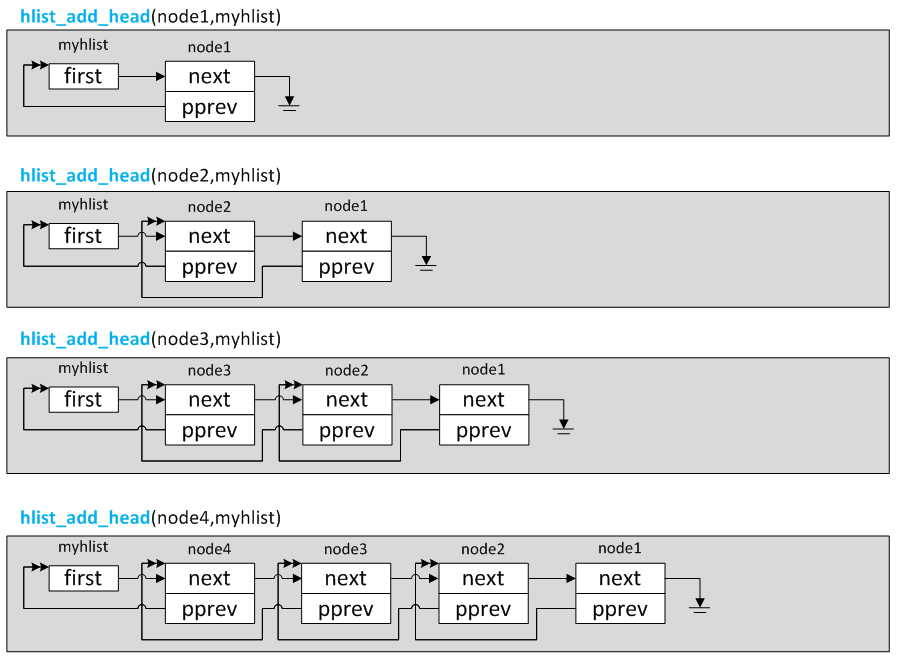
You can see that the hash table contains two data structures. One is the hash linked list node hlist_node, the other is the hash header hlist_head. You can see the hash node hlist_ The only difference between node and ordinary two-way linked list nodes in the kernel is that the forward node pprev is a two-level pointer. Also did not use hlist_ Instead of using node as the hash header, hlist is redefined_ Head structure, because the hash linked list does not need a two-way loop. In order to save space, use a pointer first to point to the first node of the hash table. The whole hash table structure is shown in the figure below. Ppre is a secondary pointer, which points to the first pointer variable of the previous node. For example, ppre of node1 points to the first pointer of mylist, and ppre of node2 points to the next pointer of node1.
The reason why ppre secondary pointer is used is to avoid the different implementation logic between inserting and deleting nodes after the first node and inserting and deleting nodes in other locations. Readers can change ppre to point to the previous node to find the different implementation logic.
Declaration and initialization macro of hash table
INIT_HLIST_NODE: via
Initializing macros is to create a hlist_head structure and set the first member to NULL.
Initialize hlist_node structure, assign two member variables to NULL.
/*
* Double linked lists with a single pointer list head.
* Mostly useful for hash tables where the two pointer list head is
* too wasteful.
* You lose the ability to access the tail in O(1).
*/
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
Add node in hash table
hlist_add_head: via
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h) static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next) static inline void hlist_add_behind(struct hlist_node *n, struct hlist_node *prev) static inline void hlist_add_fake(struct hlist_node *n)
hlist_add_head is to insert the node of a hash linked list into the back of the head node of the hash linked list, that is, head insertion. The hash header h and the node n to be inserted are passed in, and hlist is obtained first_ The first member of the head is the pointer of the following node. This node may be NULL, and then the next of the newly inserted node points to the node behind the first. If the first is not empty, that is, there is a node behind the head, the pprev member of the node behind the head points to the address of the next member of the newly inserted node, and the first of the head points to the newly inserted node, The pprev member of the newly inserted node points to the address of the first member of the head.
/**
* hlist_add_head - add a new entry at the beginning of the hlist
* @n: new entry to be added
* @h: hlist head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
WRITE_ONCE(n->next, first);
if (first)
WRITE_ONCE(first->pprev, &n->next);
WRITE_ONCE(h->first, n);
WRITE_ONCE(n->pprev, &h->first);
}
After inserting a node each time, the storage of hash table is shown in the figure below.
Traversal hash table
hlist_for_each: via
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos ; pos = pos->next)
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; pos && ({ n = pos->next; 1; }); \
pos = n)
appendix
dot_image
The pictures in the introduction of double linked list are represented by dot language. Details are as follows.
@startdot hello_list
digraph R {
rankdir=LR
node [shape=record];
node1 [xlabel="head"] [label="<f0> *next|<f1> *prev|<f2> age"];
node2 [xlabel="node1"] [label="<f0> *next|<f1> *prev|<f2> age"];
node3 [xlabel="node2"] [label="<f0> *next|<f1> *prev|<f2> age"];
node1:f0 -> node2:n;
node2:f0 -> node3:n;
node3:f0 -> node1:n;
node1:f1 -> node3:n;
node2:f1 -> node1:n;
node3:f1 -> node2:n;
}
@enddot
@startdot hello_list_error
digraph R {
rankdir=LR;
node [shape=record];
node1 [xlabel="head"] [label="<f0> age|<f1> *next|<f2> *prev"];
node2 [xlabel="node1"] [label="<f0> age|<f1> *next|<f2> *prev"];
node3 [xlabel="node2"] [label="<f0> age|<f1> *next|<f2> *prev"];
node1:f1 -> node2:f1:nw;
node2:f1 -> node3:f1:nw;
node3:f1 -> node1:f1:nw;
node1:f2 -> node3:f1:nw;
node2:f2 -> node1:f1:nw;
node3:f2 -> node2:f1:nw;
}
@enddot
@startdot hello_list_error_fix
digraph R {
// straight line
splines=false;
node [shape=record];
__mptr [shape=plaintext]
ptr [shape=plaintext]
node1 [label="<f0> data|<f1> member"]
__mptr -> node1:f0:nw
ptr -> node1:f1:nw
__mptr -> ptr [label="offset"] [dir=back]
{rank=same;ptr;__mptr}
}
@enddot