Introduction
The first series War of mixed parts - on CPU isolation of cloud native resource isolation technology (I) This paper introduces the core technology of CPU resource isolation in the cloud native hybrid scenario: kernel scheduler. This series of articles "source code analysis of Linux kernel scheduler" will analyze the specific principle and implementation of kernel scheduling from the perspective of source code. We will take Linux kernel version 5.4 (default kernel version of TencentOS Server3) as the object, starting with the initialization code of the scheduler subsystem, This paper analyzes the design and implementation of Linux kernel scheduler.
The scheduler subsystem is one of the core subsystems of the kernel. It is responsible for the rational allocation of CPU resources in the system. It needs to be able to deal with the scheduling requirements of complex different types of tasks, deal with various complex concurrent competitive environments, and take into account the overall throughput performance and real-time requirements (itself is a pair of contradictions), Its design and implementation are very challenging.
In order to understand the design and implementation of Linux scheduler, we will take Linux kernel version 5.4 (default kernel version of TencentOS Server3) as the object and analyze the design and implementation of Linux kernel scheduler from the initialization code of scheduler subsystem.
By analyzing the design and implementation of Linux scheduler (mainly for CFS), this (Series) article hopes to let readers understand:
- Basic concept of scheduler
- Initialization of the scheduler (including all kinds related to the scheduling domain)
- Process creation, execution and destruction
- Principle and implementation of process switching
- CFS process scheduling strategy (single core)
- How to ensure the rational use of CPU resources in the scheduling of the global system
- How to balance the relationship between CPU cache heat and CPU load
- Very special scheduler features analysis
Basic concept of scheduler
Before analyzing the relevant code of the scheduler, you need to understand the core data (structure) involved in the scheduler and their functions
Run queue (rq)
The kernel will create a Running queue for each CPU, and the ready (Running) processes (tasks) in the system will be organized into the kernel Running queue, and then schedule the processes on the Running queue to execute on the CPU according to the corresponding policies.
Sched_class
The kernel abstracts the sched_class to form a sched_class. The scheduling class can fully decouple the public code (mechanism) of the scheduler from the scheduling strategies provided by specific different scheduling classes, which is a typical OO (object-oriented) idea. Through this design, the kernel scheduler can be highly extensible. Developers can add a new scheduling class with little code (basically without changing the public code), so as to realize a new scheduler (class). For example, the deadline scheduling class is 3 The new addition in X is only DL from the code level_ sched_ Class, a new real-time scheduling type is conveniently added.
The current 5.4 kernel has five scheduling classes, and the priority is distributed from high to low as follows:
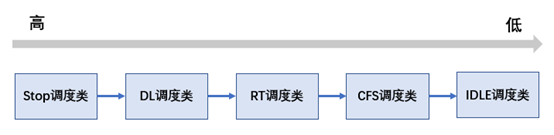
stop_sched_class:
The scheduling class with the highest priority, which is similar to idle_sched_class is a special scheduling type (except for migration thread, other tasks cannot or should not be set as stop scheduling class). This scheduling class is dedicated to implementing "urgent" tasks that depend on migration threads, such as active balance or stop machine.
dl_sched_class:
It is a kind of real-time scheduling algorithm based on the priority of EDL.
rt_sched_class:
The priority of rt scheduling class is lower than that of dl scheduling class. It is a real-time scheduler based on priority.
fair_sched_class:
The priority of CFS scheduler is lower than the above three scheduling classes. It is a scheduling type designed based on the idea of fair scheduling. It is the default scheduling class of Linux kernel.
idle_sched_class:
The idle scheduling type is the swap thread, which is mainly used to let the swap thread take over the CPU and make the CPU enter the energy-saving state through cpuidle/nohz and other frameworks.
Sched_domain
The scheduling domain is introduced into the kernel in 2.6. Through the introduction of multi-level scheduling domain, the scheduler can better adapt to the physical characteristics of hardware (the scheduling domain can better adapt to the challenges brought by CPU multi-level cache and NUMA physical characteristics to load balancing) and achieve better scheduling performance (the planned_domain is a mechanism developed for CFS scheduling class load balancing).
Sched_group
The scheduling group is introduced into the kernel together with the scheduling domain. It will cooperate with the scheduling domain to assist the CFS scheduler to complete the load balancing among multiple cores.
Root_domain
The root domain is mainly a data structure designed for load balancing of real-time scheduling classes (including dl and rt scheduling classes) to assist dl and rt scheduling classes to complete the reasonable scheduling of real-time tasks. When the scheduling domain is not modified with isolate or cpuset cgroup, all CPU s will be in the same root domain by default.
group_sched
In order to control the resources in the system more finely, the kernel introduces cgroup mechanism to control the resources. And group_sched is the underlying implementation mechanism of cpu cgroup. Through cpu cgroup, we can set some processes as a cgroup, and configure the corresponding bandwidth, share and other parameters through the control interface of cpu cgroup, so that we can fine control the CPU resources according to the unit of group.
Scheduler initialization (sched_init)
Now let's get to the point and start analyzing the initialization process of the kernel scheduler. I hope you can understand through the analysis here:
1. How is the run queue initialized
2. How is group scheduling associated with rq (group scheduling can only be performed through group_sched after Association)
3. CFS soft interrupt SCHED_SOFTIRQ registration
Sched_init
start_kernel
|----setup_arch
|----build_all_zonelists
|----mm_init
|----sched_init scheduling initialization
Scheduling initialization is at start_ The kernel is relatively backward. At this time, the memory initialization has been completed, so you can see sched_init can already call kzmalloc and other memory application functions.
sched_init needs to initialize the run queue (rq) for each CPU, the global default bandwidth of dl/rt, the run queue of each scheduling class, and CFS soft interrupt registration.
Next, let's look at sched_ Specific implementation of init (some codes are omitted):
void __init sched_init(void)
{
unsigned long ptr = 0;
int i;
/*
* Initialize the global default rt and dl CPU bandwidth control data structures
*
* RT here_ Bandwidth and dl_bandwidth is used to control the global bandwidth used by DL and RT to prevent real-time processes
* CPU Excessive use leads to starvation of ordinary CFS processes
*/
init_rt_bandwidth(&def_rt_bandwidth, global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth, global_rt_period(), global_rt_runtime());
#ifdef CONFIG_SMP
/*
* Initialize default root domain
*
* Root domain is an important data structure for global balancing of real-time processes such as dl/rt. take rt as an example
* root_domain->cpupri Is the highest priority of RT tasks running on each CPU within the root domain, and
* The distribution of priority tasks on the CPU, through the data of cpupri, is in rt enqueue/dequeue
* The rt scheduler can ensure that high priority tasks are given priority according to the distribution of rt tasks
* function
*/
init_defrootdomain();
#endif
#ifdef CONFIG_RT_GROUP_SCHED
/*
* If the kernel supports rt_group_sched, cgroup can be used to control the bandwidth of RT tasks
* To control the CPU bandwidth usage of rt tasks in each group
*
* RT_GROUP_SCHED The rt task can control the bandwidth as a whole in the form of cpu cgroup
* This can bring greater flexibility to RT bandwidth control (without RT_GROUP_SCHED, you can only control the global bandwidth of RT
* Bandwidth usage. Part of RT process bandwidth cannot be controlled by specifying a group)
*/
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
/* Initialize its run queue for each CPU */
for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
/*
* Initialize the run queue of cfs/rt/dl on rq
* Each scheduling type has its own running queue on rq, and each scheduling class manages its own process
* Pick_ next_ During task (), the kernel selects tasks from top to bottom according to the priority order of scheduling classes
* This ensures that high priority scheduling tasks will be run first
*
* stop And idle are special scheduling types. They are scheduling classes designed for special purposes. Users are not allowed
* Create the corresponding type of process, so the kernel does not design the corresponding run queue in rq
*/
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt);
init_dl_rq(&rq->dl);
#ifdef CONFIG_FAIR_GROUP_SCHED
/*
* CFS The CFS can be controlled through the cpu cgroup
* You can use CPU Shares to provide CPU proportion control between groups (let different cgroup s correspond to each other)
* To share the CPU), or through the CPU cfs_ quota_ Us to set the quota (compared with RT)
* Bandwidth control (similar). CFS group_sched bandwidth control is one of the basic underlying technologies of container implementation
*
* root_task_group Is the default root task_group, and other CPU cgroups will use it as a reference
* parent Or ancestor. The initialization here will be root_ task_ cfs running queue of group and rq
* It's interesting to do here. Directly connect root_ task_ group->cfs_ rq[cpu] = &rq->cfs
* In this way, the process under the cpu cgroup root or the sched of cgroup tg_ Cfrq - > will be added directly to
* In the queue, one layer of search overhead can be reduced.
*/
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
/* Initialize the rt run queue on rq, which is similar to the group scheduling initialization of CFS above */
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);
#endif
#ifdef CONFIG_SMP
/*
* Here, rq is compared with the default def_root_domain. If it is an SMP system, it will be later
* In sched_ init_ When SMP, the kernel will create a new root_domain, and then replace here
* def_root_domain
*/
rq_attach_root(rq, &def_root_domain);
#endif /* CONFIG_SMP */
}
/*
* Registered sched of CFS_ Softirq soft interrupt service function
* This soft interrupt is prepared for periodic load balancing and nohz idle load balance
*/
init_sched_fair_class();
scheduler_running = 1;
}Multi core scheduling initialization (sched_init_smp)
start_kernel
|----rest_init
|----kernel_init
|----kernel_init_freeable
|----smp_init
|----sched_init_smp
|---- sched_init_numa
|---- sched_init_domains
|---- build_sched_domains
Multi core scheduling initialization is mainly to complete the initialization of scheduling domain / scheduling group (of course, the root domain will also do it, but relatively speaking, the initialization of the root domain will be relatively simple).
Linux is an operating system that can run on a variety of chip architectures and memory architectures (UMA/NUMA), so Linu x needs to be able to adapt to a variety of physical structures, so its scheduling domain design and implementation is relatively complex.
Implementation principle of scheduling domain
Before talking about the specific scheduling domain initialization code, we need to understand the relationship between the scheduling domain and the physical topology (because the design of the scheduling domain is closely related to the physical topology. If we don't understand the physical topology, we can't really understand the implementation of the scheduling domain)
Physical topology of CPU

Let's assume a computer system (similar to intel chip, but reduce the number of CPU cores to facilitate representation):
For a dual socket computer system, each socket is composed of 2 cores and 4 threads, so the computer system should be a NUMA system with 4 cores and 8 threads (the above is only the physical topology of intel, while AMD ZEN architecture adopts the design of chiplet, which will have a layer of DIE domain between MC and NUMA domain).
Layer 1 (SMT domain):
As shown in CORE0 above, two hyper threads constitute the SMT domain. For Intel CPUs, hyper threads share L1 and L2 (even store buffs are shared to some extent), so there is no loss of cache heat when SMT domains migrate to each other
Layer 2 (MC domain):
As shown in the figure above, CORE0 and CORE1 are located in the same SOCKET and belong to the MC domain. For Intel CPUs, they generally share LLC (generally L3). In this domain, although process migration will lose the heat of L1 and L2, the cache heat of L3 can be maintained
Layer 3 (NUMA domain):
As shown in SOCKET0 and SOCKET1 in the figure above, the process migration between them will lead to the loss of all cache heat and a large overhead. Therefore, the migration of NUMA domain needs to be relatively cautious.
It is precisely because of such hardware physical characteristics (hardware factors such as cache heat at different levels and NUMA access latency) that the kernel abstracts sched_domain and sched_group to represent such physical characteristics. When doing load balancing, different scheduling strategies (such as the frequency of load balancing, unbalanced factors and wake-up core selection logic) are made according to the characteristics of the corresponding scheduling domain, so as to better balance the CPU load and cache affinity.
Implementation of scheduling domain
Next, we can see how the kernel establishes the relationship between the scheduling domain and the scheduling group on the above physical topology

The kernel will establish a corresponding level of scheduling domain according to the physical topology, and then establish a corresponding scheduling group on each level of scheduling domain. Load balancing in the scheduling domain is to find the busiest sg(sched_group) with the heaviest load in the scheduling domain of the corresponding level, and then judge whether the load of buiest sg and local sg (but the scheduling group of the former CPU) is uneven. If the load is uneven, choose the buisest cpu from the buiest sg, and then balance the load between the two CPUs.
smt domain is the lowest scheduling domain. You can see that each hyper thread pair is an smt domain. There are two scheds in the smt domain_ Group, and each sched_group will have only one CPU. Therefore, load balancing in smt domain is to perform process migration between hyper threads. The load balancing time is the shortest and the conditions are the most relaxed.
For the architecture without hyper threading (or the chip does not turn on hyper threading), the lowest domain is the MC domain (at this time, there are only two-tier domains, MC and NUMA). In this way, each CORE in the MC domain is a sched_group, the kernel can also adapt to this scenario when scheduling.
The MC domain is composed of all CPUs on the socket, and each sg is composed of all CPUs of the superior smt domain. Therefore, for the above figure, the sg of MC is composed of two CPUs. The kernel is designed in the MC domain in such a way that the CFS scheduling class requires the sg of the MC domain to be balanced when waking up load balancing and idle load balancing.
This design is very important for hyper threading. We can also observe this situation in some actual businesses. For example, we have an encoding and decoding service, and found that its test data in some virtual machines is better, while the test data in some virtual machines is worse. After analysis, it is found that this is due to whether the hyper threading information is transmitted to the virtual machine. When we transparently transmit hyper threading information to the virtual machine, the virtual opportunity forms a two-tier scheduling domain (SMT and MC domain). When waking up load balancing, CFS tends to schedule services to idle sg (i.e. idle physical CORE rather than idle CPU). At this time, when the CPU utilization of services is not high (no more than 40%), It can make full use of the performance of the physical CORE (it is still an old problem. When a hyper thread pair on the physical CORE runs CPU consuming services at the same time, the performance gain is only about 1.2 times that of a single thread), So as to obtain better performance gain. If there is no transparent hyper threading information, the virtual machine has only one layer of physical topology (MC domain). Since the business is likely to be scheduled through the hyper threading pair of a physical CORE, the system will not make full use of the performance of the physical CORE, resulting in low business performance.
NUMA domain is composed of all CPUs in the system. All CPUs on SOCKET constitute one sg. NUMA domain in the above figure is composed of two SGS. When there is a large imbalance between sg of NuMA (and the imbalance here is sg level, that is, the total load of all CPUs on sg is unbalanced with another sg), The process migration across NUMA can only be carried out (because the migration across NUMA will lead to the loss of all cache heat of L1, L2 and L3, and may lead to more memory access across NUMA, so it needs to be handled carefully).
As you can see from the above introduction, sched_domain and sched_ With the cooperation of group, the kernel can adapt to various physical topologies (whether to enable hyper threading and NUMA) and use CPU resources efficiently.
smp_init
/*
* Called by boot processor to activate the rest.
*
* In SMP architecture, BSP needs to bring up all other non boot CPS
*/
void __init smp_init(void)
{
int num_nodes, num_cpus;
unsigned int cpu;
/* Create its idle thread for each CPU */
idle_threads_init();
/* Register cpuhp threads with the kernel */
cpuhp_threads_init();
pr_info("Bringing up secondary CPUs ...\n");
/*
* FIXME: This should be done in userspace --RR
*
* If the CPU is not online, use the cpu_up bring it up
*/
for_each_present_cpu(cpu) {
if (num_online_cpus() >= setup_max_cpus)
break;
if (!cpu_online(cpu))
cpu_up(cpu);
}
.............
}At the beginning of the real sched_ init_ Before the initialization of SMP scheduling domain, you need to bring up all non boot CPUs to ensure that these CPUs are in ready state, and then you can start the initialization of multi-core scheduling domain.
sched_init_smp
Let's take a look at the specific code implementation of multi-core scheduling initialization (if CONFIG_SMP is not configured, the relevant implementation here will not be executed)
sched_init_numa
sched_init_numa() is used to detect whether there is NUMA in the system. If so, the NUMA domain needs to be added dynamically.
/*
* Topology list, bottom-up.
*
* Linux Default physical topology
*
* There is only a three-level physical topology, and the NUMA domain is in sched_init_numa() automatic detection
* If there is a NUMA domain, the corresponding NUMA scheduling domain will be added
*
* Note: the default here is default_ There may be some problems in the topology scheduling domain, such as
* Some platforms do not have a DIE domain (intel platform), so LLC and DIE domains may overlap
* Therefore, after the scheduling domain is established, the kernel will_ attach_ Scan all schedules in domain()
* If there is scheduling overlap, it will be destroyed_ sched_ Overlapping scheduling domain corresponding to domain
*/
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};Default physical topology of Linux
/*
* NUMA Scheduling domain initialization (create a new sched_domain_topology physical topology according to the hardware information)
*
* By default, the kernel does not actively add NUMA topology. It needs to be configured according to the configuration (if NUMA is enabled)
* If NUMA is enabled, it is necessary to judge whether it needs to be added according to the hardware topology information
* sched_domain_topology_level Domain (the kernel will not initialize later until this domain is added
* sched_domain NUMA domain is created when
*/
void sched_init_numa(void)
{
...................
/*
* Here, check whether there is NUMA domain (or even multi-level NUMA domain) according to distance, and then
* Update it to the physical topology according to the situation. When the scheduling domain is established later, this new domain will be created
* Physical topology to establish a new scheduling domain
*/
for (j = 1; j < level; i++, j++) {
tl[i] = (struct sched_domain_topology_level){
.mask = sd_numa_mask,
.sd_flags = cpu_numa_flags,
.flags = SDTL_OVERLAP,
.numa_level = j,
SD_INIT_NAME(NUMA)
};
}
sched_domain_topology = tl;
sched_domains_numa_levels = level;
sched_max_numa_distance = sched_domains_numa_distance[level - 1];
init_numa_topology_type();
}Detect the physical topology of the system. If there is a NUMA domain, it needs to be added to the schema_ domain_ In topology, it will be based on sched later_ domain_ Topology is the physical topology to establish the corresponding scheduling domain.
sched_init_domains
Next, we will analyze sched_init_domains is the scheduling domain establishment function
/*
* Set up scheduler domains and groups. For now this just excludes isolated
* CPUs, but could be used to exclude other special cases in the future.
*/
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology();
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
if (!doms_cur)
doms_cur = &fallback_doms;
/*
* doms_cur[0] Indicates the cpumask that the scheduling domain needs to cover
*
* If some CPUs are isolated with isolcpus = in the system, these CPUs will not be added to the scheduling
* In the domain, that is, these CPU s will not participate in load balancing (load balancing here includes DL/RT and CFS).
* CPU is used here_ map & housekeeping_ Use cpumask (hk_flag_domain) to isolate
* cpu Remove, so that the isolate cpu is not included in the established scheduling domain
*/
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN));
/* Implementation function of scheduling domain establishment */
err = build_sched_domains(doms_cur[0], NULL);
register_sched_domain_sysctl();
return err;
}/*
* Build sched domains for a given set of CPUs and attach the sched domains
* to the individual CPUs
*/
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
struct sched_domain_topology_level *tl_asym;
bool has_asym = false;
if (WARN_ON(cpumask_empty(cpu_map)))
goto error;
/*
* Linux Most processes in CFS are CFS scheduling classes, so sched in CFS_ Domain will be used frequently
* Access and modification (such as various statistics in nohz_idle and sched_domain), so sched_ domain
* The design of sched needs to give priority to efficiency, so the kernel adopts percpu to implement sched_domain
* CPU Each level of sd between is a percpu variable applied independently, so you can use the characteristics of percpu to solve them
* Concurrency competition between (1. No lock protection required; 2. No cachline pseudo sharing)
*/
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
tl_asym = asym_cpu_capacity_level(cpu_map);
/*
* Set up domains for CPUs specified by the cpu_map:
*
* This will traverse the cpu_map all CPUs, and create corresponding physical topology for these CPUs(
* for_each_sd_topology)Multilevel scheduling domain.
*
* When the scheduling domain is established, the corresponding cpu in the scheduling domain of this level will be obtained through TL - > mask (cpu)
* Span (that is, the cpu and other corresponding CPUs form this scheduling domain), which is in the same scheduling domain
* The sd corresponding to the CPU of will be initialized to the same at the beginning (including sd - > Pan
* sd->imbalance_pct And SD - > flags and other parameters).
*/
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) {
int dflags = 0;
if (tl == tl_asym) {
dflags |= SD_ASYM_CPUCAPACITY;
has_asym = true;
}
sd = build_sched_domain(tl, cpu_map, attr, sd, dflags, i);
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
/*
* Build the groups for the domains
*
* Create scheduling group
*
* We can see sched from the implementation of two scheduling domains_ Role of group
* 1,NUMA Domain 2. LLC domain
*
* numa sched_domain->span It will include all CPU s in NUMA domain when balancing is required
* NUMA The domain should not be in cpu units, but in socket units, that is, only socket1 and socket2
* The CPU is migrated between the two sockets only when it is extremely unbalanced. If sched is used_ Domain to implement this
* Abstraction will lead to insufficient flexibility (as you can see in the MC domain later), so the kernel will use sched_group come
* Represents a cpu set, and each socket belongs to a sched_group. When these two sched_group imbalance
* Migration will only be allowed when
*
* MC The domain is similar. The CPU may be hyper threading, and the performance of hyper threading is not equal to that of the physical core. a pair
* Hyper threading is roughly equal to 1.2 times the performance of the physical core. So when scheduling, we need to consider hyper threading
* The balance between pairs, that is, the balance between CPUs must be met first, and then the hyper thread balance in the CPU. At this time
* Using sched_group for abstraction, a sched_group refers to a physical CPU(2 hyper threads). At this time
* LLC Ensure the balance between CPU s, so as to avoid an extreme situation: the balance between hyper threads, but the physical core is unbalanced
* At the same time, it can ensure that when scheduling and core selection, the kernel will give priority to the implementation of physical threads, only physical threads
* After use, consider using another hyper thread, so that the system can make more full use of CPU computing power
*/
for_each_cpu(i, cpu_map) {
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
if (build_sched_groups(sd, i))
goto error;
}
}
}
/*
* Calculate CPU capacity for physical packages and nodes
*
* sched_group_capacity Is used to represent sg available CPU computing power
*
* sched_group_capacity It is considered that the computing power of each CPU is different (the highest dominant frequency setting is different
* ARM Remove the CPU used by the RT process (SG is prepared for CFS, so it is necessary to
* After removing the CPU computing power used by DL/RT processes on the CPU, the available computing power left to CFS sg (because
* In load balancing, you should consider not only the load on the CPU, but also the CFS on this sg
* Available computing power. If there are few processes on this sg, but sched_group_capacity is also small, so
* The process should not be migrated to this sg)
*/
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
/* Attach the domains */
rcu_read_lock();
/*
* Bind the rq of each CPU to rd(root_domain), and check whether sd overlaps
* If yes, you need to use destroy_sched_domain() removes it (so we can see
* intel The server has only a three-tier scheduling domain. The DIE domain actually overlaps with the LLC domain, so it is here
* Will be removed)
*/
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
if (has_asym)
static_branch_inc_cpuslocked(&sched_asym_cpucapacity);
if (rq && sched_debug_enabled) {
pr_info("root domain span: %*pbl (max cpu_capacity = %lu)\n",
cpumask_pr_args(cpu_map), rq->rd->max_cpu_capacity);
}
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}So far, we have built the scheduling domain of the kernel, and CFS can use sched_domain to complete the load balancing between multiple cores.
epilogue
This paper mainly introduces the basic concept of kernel scheduler. By analyzing the initialization code of scheduler in the 5.4 kernel, it introduces the specific landing methods of the basic concepts such as scheduling domain and scheduling group. On the whole, the 5.4 kernel is compared with 3.4 kernel The X kernel has no essential changes in the scheduler initialization logic and the basic design (concept / key structure) related to the scheduler, which also confirms the "stability" and "elegance" of the kernel scheduler design.
Notice: the next article in this series will focus on the basic principle, basic framework and related source code of Linux kernel scheduler. Please look forward to it.
[Tencent cloud native] cloud says new products, Yunyan new technology, cloud tours, new cloud and cloud reward information, scanning code concern about the same official account number, and get more dry cargo in time!! 