Linux Learning (1): File Operation
VFS
I don't want to see it, but I can just go to the File Operation section.
1. Virtual File System
Before learning Linux file operations, we need to have a general understanding of VFS
VFS (Virtual Filesystem Switch): Virtual file system or virtual file system conversion
VFS is called a subsystem of the kernel. VFS provides a unified interface. To be supported by Linux, a specific file system must write its own operation functions according to this interface and hide its details from other subsystems of the kernel.
2. Main role of VFS
a) Support mutual access between multiple specific file systems;
b) Accept user-level system calls, such as open, link, write, and so on;
c) To abstract the data structure of a specific file system and manage it in a unified data structure
d) Accept operating instructions from other subsystems of the kernel
3. File System Logical Relational Architecture in Linux System
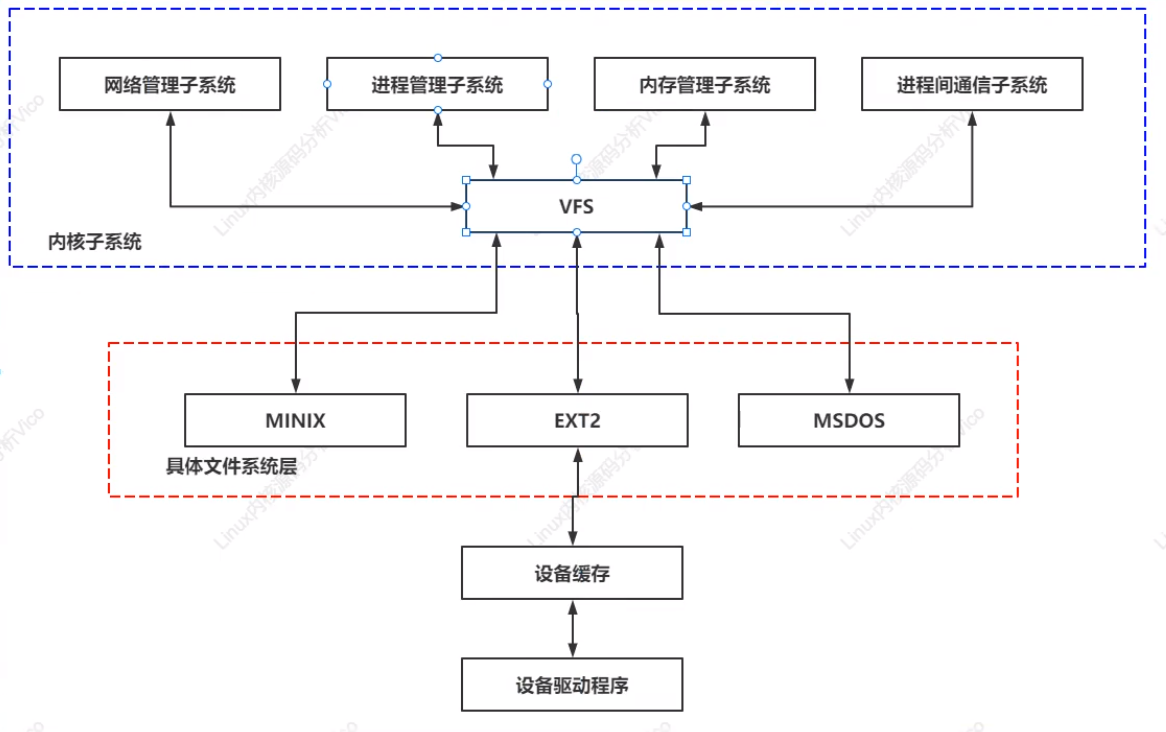
4. VFS Common Operations in Actual System Calls
mount()/umount(), sysfs(), chroot(), chdir()/fchdir()/getcwd(), mkdir()/rmdir(), readlink()/symlink(), chown()/fchown()/lchown, select()/poll(), flock().
5. VFS Core Data Structure (Object)
a) Super Block Objects - Every file system has a Super Block Object
b) Index Node Object - Each file has an index node object, and each index node object has an index node number that uniquely identifies the file specified in a file system
c) Directory item (dentry) object
d) File (file) object
It should be enough to know so much in the current learning stage, and the following content has not been touched yet
File Operation
File Information View
Instruction to view file details - stat filename
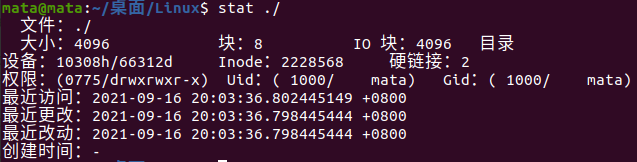
View file information for the current directory as shown
Size: Everything on Linux is a file, so the directory is also a file and has a size. Here, the directory is 4096 in size. Note that the size here is not the size of the file. If you need to view the size of a file or folder, you need to use the du-sh command
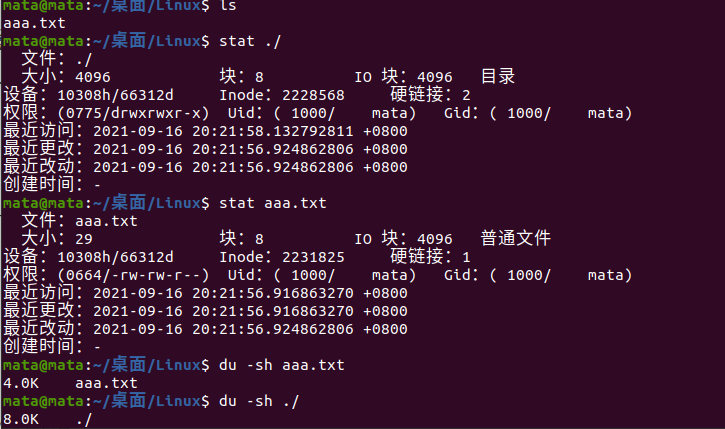
On Linux systems, directory is also a kind of file. Opening a directory means opening a directory file. The structure of a directory file is very simple, it is a series of directory items (dirent).Each directory item consists of two parts: the file name of the included file and the inode number corresponding to the file name. So the size here is not the size of the file size
Blocks: The smallest unit of storage for a hard disk is called a Sector. Each sector stores 512 bytes (equivalent to 0.5KB). The size of a Block, most commonly 4KB, is when eight consecutive sectors form a block.
Device: Device number.
Inode: Inode number, all files should have an Inode number.
Hard links: The number of hard links is how many ways you can access the current directory or file. The number of hard links for a file is usually 1 (absolute path). The number of hard links for a directory is at least 2 (absolute path or cd.). The more subdirectories a directory contains, the more hard links it has (subdirectories go into superior cds...).
Permission: to (0664/-rw-rw-r-)For example, let's look at the following four groups of -r W-R w-r-, which are -r W-R w-r--. The first group, which represents the file type, for example, the first group of directories is d, which means directory, directory, the second group represents user rights, the third group represents group rights to which the user belongs, and the fourth group represents other rights. The last three groups mainly contain three rights, which are R W-R w-r--.X, means readable, writable, executable. The preceding number is a representation of the following permissions. r stands for 4, w for 2, x for 1, so 4 is r-x, 5 is r-x, 6 is R w-, 7 is r w x, and so on.
Change file permissions
First you can view permissions using ls-l
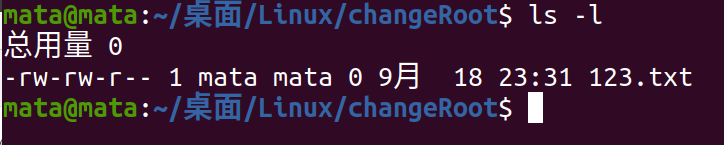
Method One
As shown in the figure, using ls - to view the file permissions of 123.txt, you can see that the permissions are -rw-rw-r-. Next, we can use chmod to modify the file permissions.
First, use the chmod prefix, then the format is to modify the object+/- corresponding permissions, +to allow the permissions, -to prohibit the permissions, see the following cases:
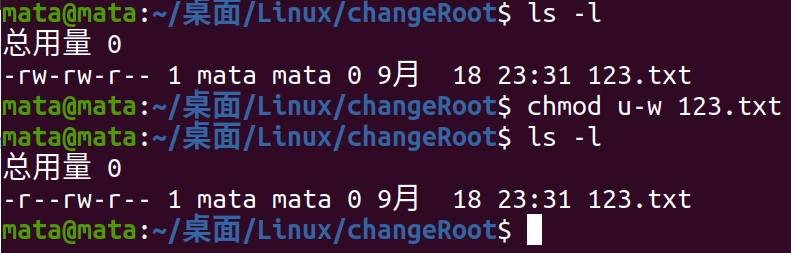
U stands for user here, so u-w here means prohibiting the user from writing, while u+w can be used to give the user write access.
u - - User, g - - Subordinate Group, o - - Other, a - - All Identities. w - - Write, r - - Read, x - - Execute.
Method 2

As shown in the figure, the 123.txt file no longer has any permissions. Now we want to add readable and executable permissions to the user, what else can we do except method one. We can avoid Chmod u+r 123.txt;Chmod u+x 123.txt. Instead, override permissions.
As shown in the diagram,

You can see that u=r x means that the user's permissions are overridden by r-x.
Method Three
R--4, w--2, x--1. Remember the numbers for the three permissions
So there are:
0 corresponds to -
1 corresponding - x
2 corresponding-w-
3 corresponding-wx
4 for r-
5 corresponds to r-x
6 corresponds to rw-
7 corresponds to rwx
As you can see, there are eight permissions in all three permissions, so we can use these numbers to represent all permissions
Now we have a file 123.txt with no permissions

Now we want to add readable permissions to its users, read and write permissions to its groups, and all other permissions to it
So now there's chmod 467 123.txt
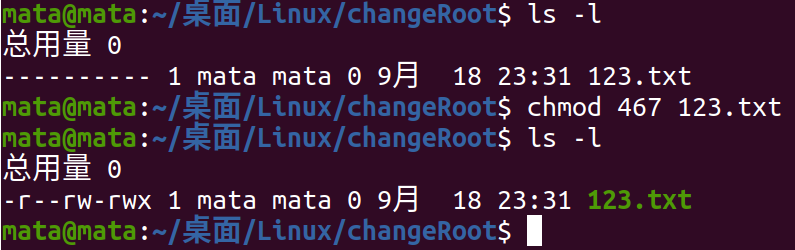
This is the permission to modify numeric methods
c Language Query File Permissions
We can also use c-language code to implement query privileges:
Code
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
typedef unsigned int u32;
int main(int argc, char *argv[])
{
u32 i, mask = 0700;
struct stat fileAttribute;
static char *filePermissions[] = {"---", "--x", "-w-", "-wx", "r--", "r-x", "rw-", "rwx"};
if (argc > 1)
{
if ((stat(argv[1], &fileAttribute) != -1))
{
printf("%s Permissions are:", argv[1]);
for (i = 3; i; --i)
{
printf("%3s", filePermissions[(fileAttribute.st_mode & mask) >> (i - 1) * 3]);
mask >>= 3;
}
printf("\n");
}
}
else
printf("Please enter the file you need to query\n");
return 0;
}
Compile instructions: gcc -g filename.c -o filename
The result is shown in the figure:
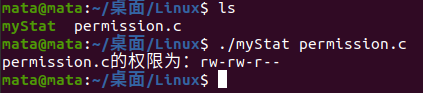
Code parsing
Before parsing, you need to know something about bit operations in C. You can see it in more detail C Language Bit Operations
Don't dwell here
What do the parameters argc and argv in the main function mean? Refer to this video
Parameters in main function
fileAttribute.st_mode - Represents file permissions. If you understand the third way to modify permissions above, you should know that permissions are actually stored as numbers in this property. Note that mask=0700 is used in this code, and mask>=3 is used, so every permission comparison is performed with 7.
We analyze the for loop part of the code line by line:
First look at the first cycle, i=3.
What exactly does fileAttribute.st_mode & mask mean?
Let's take a file as an example and assume that it has permissions of rw-r---wx
So there are
| fileAttribute.st_mode: | 6 | 4 | 3 |
|---|---|---|---|
| mask: | 7 | 0 | 0 |
If you already know what bits and operations mean, you should clear that bits and operations of 6 and 7 are converted to binary before they are compared.
First look at 6 and 7, 110 and 111. After comparison, the final result is still 110. Then look at the subsequent comparison, we can see that all of them are 000.
After comparing the results to 110,000,000 and then moving right, you get 110 by moving six bits to the right. That is, 6, when the subscript of the filePermissions array is 6, it is rw-.
Then the mask moves 3 bits to the right, changing the original 700 to 70. Continue the same operation until i=0.
c View additional information about the file
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
typedef unsigned int u32;
int main(int argc, char *argv[])
{
u32 i, mask = 0777;
struct stat fileAttribute;
static char *filePermissions[] = {"---", "--x", "-w-", "-wx", "r--", "r-x", "rw-", "rwx"};
if (argc > 1)
{
if ((stat(argv[1], &fileAttribute) != -1))
{
printf("%s Permissions are:", argv[1]);
for (i = 3; i; --i)
{
printf("%3s", filePermissions[(fileAttribute.st_mode & mask) >> (i - 1) * 3]);
mask >>= 3;
}
printf("\n");
char *fileType;
if (S_ISREG(fileAttribute.st_mode)) // Determine whether it is a normal file
fileType = "regular file";
else if (S_ISDIR(fileAttribute.st_mode)) // Catalog Files
fileType = "directory file";
else if (S_ISFIFO(fileAttribute.st_mode)) // Pipeline File
fileType = "fifo file";
else if (S_ISCHR(fileAttribute.st_mode)) // Character Device Files
fileType = "character file";
printf("File type:%s\n", fileType);
printf("Size:%ld\n", fileAttribute.st_size);
printf("Block:%ld\n", fileAttribute.st_blocks);
printf("Block size:%ld\n", fileAttribute.st_blksize);
printf("Equipment:%ld\n", fileAttribute.st_dev);
printf("inode: %ld\n", fileAttribute.st_ino);
printf("Number of hard links:%ld\n", fileAttribute.st_nlink);
printf("uid: %d\n", fileAttribute.st_uid);
printf("gid: %d\n", fileAttribute.st_gid);
}
}
else
printf("Please enter the file you need to query\n");
return 0;
}
Mainly remember the internal parameters, the structure members, and the corresponding functions.
File Lookup
File name lookup
Format: find find find directory-name file name

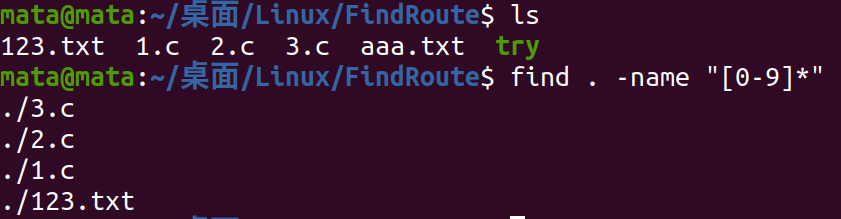
As shown in the figure, there are two txt files and two.c files in the FindRoute directory. Now we find 123.txt in FindRoute in the Linux directory. The process and results are shown in the following figure

Similarly, we find all the.c files that need to be escaped with \ when using * wildcards

Find files starting with 0 to 9
File Size Lookup
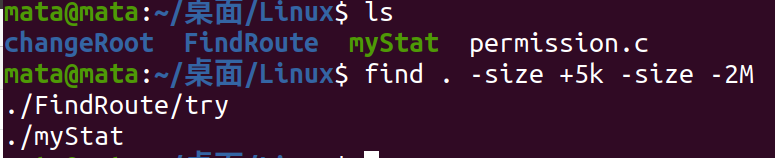
Find files with current directory larger than 5k

Find files in the current directory that are larger than 5k and smaller than 2M
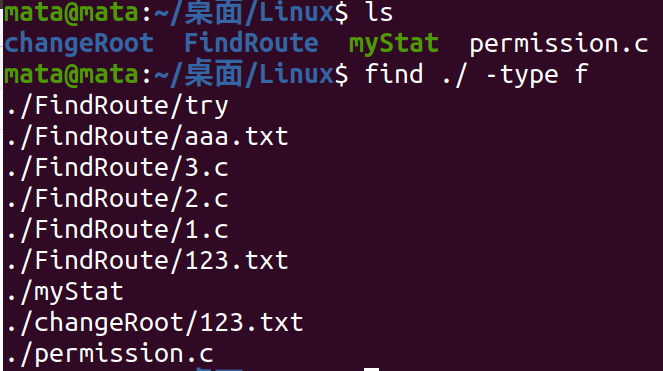
File type lookup
Find all normal files in the current directory
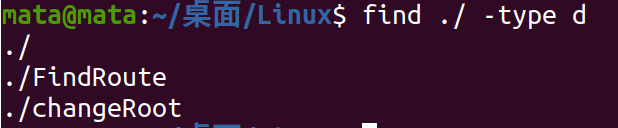
Find all directory files in the current directory
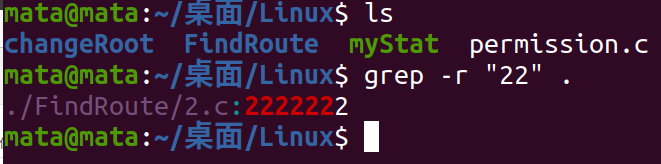
Find by file content
Previously written 22222 and 333333 in 2.c and 3.c of the FindRoute folder, respectively
We look up the contents of these two files in FindRoute's parent directory
Find the file containing the string'#include'in the current directory
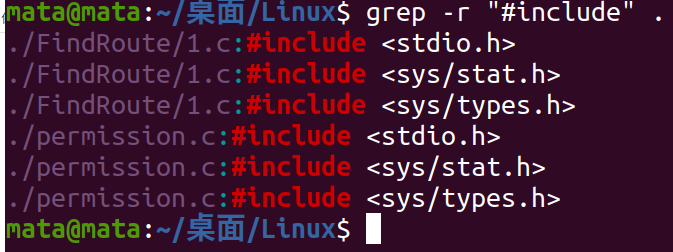
File Compression and Decompression

gzip compression gunzip decompression
You can see that there are two folders (blue) under the current directory, one executable (green) and one normal file (white).
Now let's compress the white file

This red file is the compressed file, you can see that after compression, the original file disappears, keep the original file compressed. Next, let's see how to decompress the file
Unzip by gunzip command

bzip2 compressed bunzip2 decompression
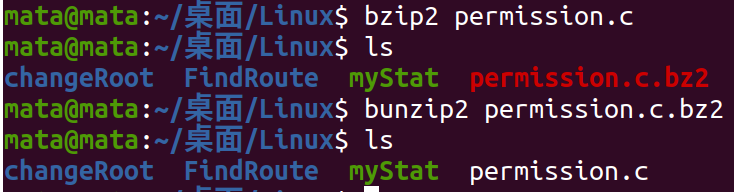
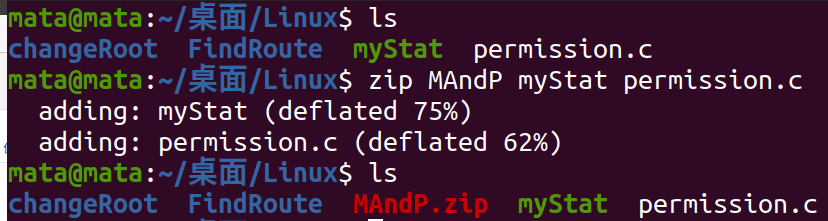
Decompression using zip compression

As shown, the myStat and permission.c files are compressed together and the original file is not deleted
Unzip it again
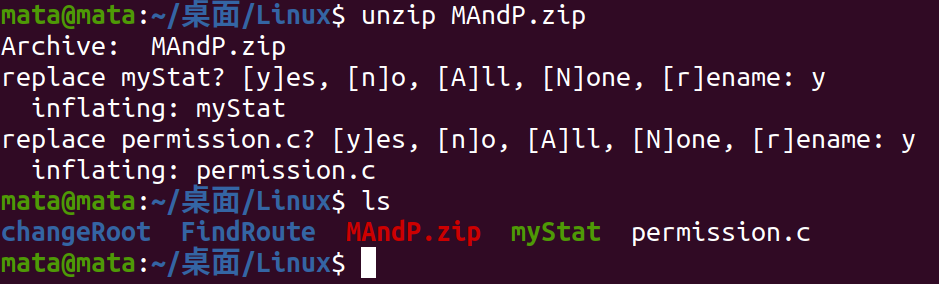
Because the original file has not been deleted, you will be asked if you want to replace it or rename it.
File Operation Buffer
Standard input: stdin - handle 0
Standard Output: stdout - Handle 1
Standard error: stderr - Handle 2
The handle here is an integer, not too complex to think about. It can find the corresponding file through VFS, pointing to several operations above.
What is Buffer
In the process of input and output, the computer usually stores the data in memory first, then fetches the data directly from the memory. This reduces the direct operation on the hard disk and improves the processing speed of the computer.
An analogy is made: there are now manufacturers and buyers. Buyers go to the producers to buy goods, but the buyers buy much faster than the producers produce, so there will be a shortage of supply. In fact, here you can see that the producers correspond to the low-speed devices (hard drives, etc.) in the computer, and the buyers correspond to the high-speed devices in the computer.(CPU, etc.), and the mismatch between high-speed and low-speed devices can cause computer performance not to be fully released, so warehouses (memory) emerge, where buyers can buy other goods before they can buy them, then manufacturers can quickly put them in the warehouse and buy them when the next buyer arrives.
This is a comparison that people who want to know can help point out if something is inappropriate, but the general idea of a buffer is to store data between input and output devices so that high-speed and low-speed devices can work together to get the best performance.
Three Buffers
There are three typical buffers:
1. Full buffer
Typical Representation: Read and write to disk files
2. Line Buffer
Typical Representations: Standard Input and Standard Output
3. No Buffer
Typical Representation: Standard Error
c Language Setting Buffer
Code
The code logic is simple and has been explained in the comment, so don't override it
#include <stdio.h>
#include <string.h>
#Include <errno.h> //Standard Error Related Function
// setbuf(FILE *stream, char* buf);The output written to parameter 1 is in the buffer of parameter 2. When the buffer of parameter 2 is full or fflush, the content of parameter 2 is written to parameter 1.
// Setvbuf (FILE *stream, char * buf, int mode, size_t size);Model refers to three buffers, and size refers to buffer size
int main(int argc, char *argv[])
{
FILE *pf;
char msg1[] = "hello world\n";
char msg2[] = "hello\nworld";
char buff[128];
//==============================================================================================================
memset(buff, 0, sizeof(char) * 128); // Empty buffer buff
if ((pf = fopen("no_buf1.txt", "w")) == NULL)
{
perror("file open failure!\n");
return 1;
}
setbuf(pf, NULL); // Set no buffer
fwrite(msg1, 8, 1, pf); // Write the contents of MSG 1 into pf, 8 characters, once
printf("test setbuff(no buff)! check no_buf1.txt\n");
printf("now buff data is : %s \n", buff);
printf("enter the enter to continue!\n");
getchar();
fclose(pf);
//==============================================================================================================
memset(buff, 0, sizeof(char) * 128); // Empty buffer buff
if ((pf = fopen("no_buf2.txt", "w")) == NULL)
{
perror("file open failure!\n");
return 1;
}
setvbuf(pf, NULL, _IONBF, 0); // 1: File pointer to the desired buffer. 2: Address of the buffer. 3. Buffer type. 4. Buffer size
fwrite(msg1, 8, 1, pf); // Write the contents of MSG 1 into pf, 8 characters, once
printf("test setbuff(no buff)! check no_buf2.txt\n");
printf("now buff data is : %s \n", buff);
printf("enter the enter to continue!\n");
getchar();
fclose(pf);
//===============================================================================================================
memset(buff, 0, sizeof(char) * 128); // Empty buffer buff
if ((pf = fopen("l_buf.txt", "w")) == NULL)
{
perror("file open failure!\n");
return 1;
}
setvbuf(pf, buff, _IOLBF, 128); // 1: File pointer to the desired buffer. 2: Address of the buffer. 3. Buffer type. 4. Buffer size
fwrite(msg2, sizeof(msg2), 1, pf); // Write the contents of MSG 1 into pf, 8 characters, once
printf("test setbuff(line buff)! check l_buf.txt\n");
printf("now buff data is : %s \n", buff);
printf("enter the enter to continue!\n");
getchar();
fclose(pf);
//===============================================================================================================
memset(buff, 0, sizeof(char) * 128); // Empty buffer buff
if ((pf = fopen("f_buf.txt", "w")) == NULL)
{
perror("file open failure!\n");
return 1;
}
setvbuf(pf, buff, _IOFBF, 128); // 1: File pointer to the desired buffer. 2: Address of the buffer. 3. Buffer type. 4. Buffer size
fwrite(msg2, sizeof(msg2), 1, pf); // Write the contents of MSG 1 into pf, 8 characters, once
printf("test setbuff(full buff)! check f_buf.txt\n");
printf("now buff data is : %s \n", buff);
printf("enter the enter to continue!\n");
getchar();
fclose(pf);
//===============================================================================================================
return 0;
}
Running result analysis
Let's look at it step by step
Open two terminals, one to run code, one to view the created

Since there is no buffer, the output is written directly to no_buf1.txt
**NOTE: **The world is not completely displayed here because only eight characters were written in the previous settings.

The second run yielded the same results as the first because no buffers were set

The result of the third run is no longer the same as the first run, only one hello is output
Before analyzing the cause, let's look at what msg2 is about:
char msg2[] = "hello\nworld";
We can see that hello is followed by a line break \n, and the line break refreshes the buffer, so the condition for output to the device is line break, so Hello has been in the buffer at first, until it encounters a line break, the buffer refreshes to l_buf.txt.
So when we run it again and the program runs to fclose, the buffer refreshes again, and helloworld should output all of it. When we press enter again, we can see:

Sure enough, helloworld is all written to l_buf.txt
But let's look at what's in f_buf.txt

You can see that the content is empty because in the fourth step we set up a full buffer and did not refresh the buffer manually, it always existed in the buffer and would not be written to the f_buf file.
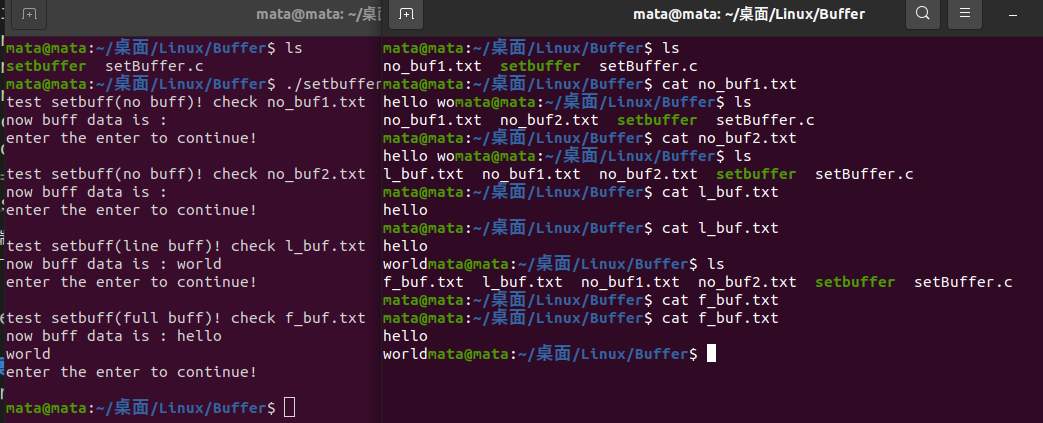
ps: In addition to fclose, you can use the fflush function to refresh the buffer.
With this code, you can get a general idea of the three buffers
I am just a beginner, if there are some problems, I welcome you to point out