There are three memory allocators in linux: boot memory allocator, partner allocator and slab allocator
Partner distributor
After the initialization of the system kernel, the page allocator is used to manage the physical pages. When the page allocator is a partner allocator, the partner allocator is characterized by simple and efficient algorithm and supports memory nodes and regions. In order to prevent memory fragmentation, the physical memory is grouped according to mobility, and the performance is optimized for allocating a single page. In order to reduce the lock competition of the processor, Add 1 page per processor set in the memory area.
1. Principle of partner distributor
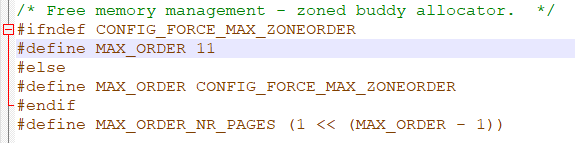
Successive physical pages are called page blocks. Order is a professional term of partner allocator, which is the unit of number of pages. 2 n consecutive pages are called n-order page blocks. The physical memory is divided into 11 orders: 0 ~ 10. The number of consecutive pages in each order is 2order. If the available memory size in an order is less than the expected allocated size, the memory blocks of a larger order will be split in half, and the two small blocks after splitting are buddies to each other. One sub block is used for allocation and the other is idle. These blocks will be halved continuously when necessary until they reach the memory block of the required size. When a block is released, it will check whether its buddies are also free. If so, the pair of buddies will be merged.
Two n-order page blocks that meet the following conditions are called Partners:
1) Two page blocks are adjacent, that is, the physical address is continuous;
2) The physical page number of the first page of the page block must be an integer multiple of 2 n;
3) If combined into (n+1) order page blocks, the physical page number of the first page must be an integer multiple of 2 n+1.
2. Advantages and disadvantages of partner distributor
Advantages: because the physical memory is put into different orders according to PFN, the size of the memory is allocated according to the needs, and the order in which the current allocation should find the free memory block is calculated. If there is no free order in the current order, the allocation efficiency is much faster than the linear scan bitmap of boot memory.
Disadvantages:
1) When releasing a page, the caller must remember the order allocated by the page before, and then release the 2order pages from the page, which is a little inconvenient for the caller
2) Because each allocation of buddy allocator must be 2order page s allocated at the same time, so when the actual required memory size is less than 2order, it will cause memory waste. Therefore, in order to solve the problem of internal fragmentation caused by Buddy allocator, Linux will introduce slab allocator later.
3. Distribution and release process of partner distributor
The number of physical pages allocated and released by the partner allocator, in order. The process of allocating n-order page blocks is as follows:
1) Check whether there are free n-order page blocks. If so, allocate them directly; Otherwise, proceed to the next step;
2) Check whether there are idle (n+1) order page blocks. If so, divide the (n+1) order page block into two n-order page blocks, one is inserted into the idle n-order page block chain list, and the other is allocated; Otherwise, proceed to the next step.
3) Check whether there are free (n+2) page blocks. If there are, split the (n+2) page blocks into two (n+1) page blocks. One is inserted into the free (n+1) page block linked list, and the other is split into two N-level page blocks. One is inserted into the space N-level page block linked list, and the other is allocated; If not, continue to check whether there are free page blocks at higher levels.
4. Data structure of partner distributor
The partition's partner allocator focuses on an area of a memory node. Structure member free of memory area_ Area is used to maintain free page blocks. The index of the array corresponds to the order of page blocks.
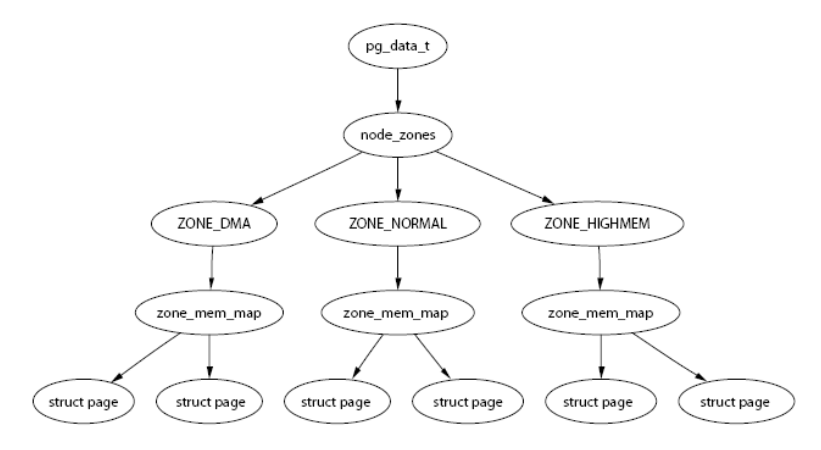
Kernel source code structure:

struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
The kernel uses GFP_ZONE_TABLE defines the flag combination of the area type mapping table, where GFP_ZONES_SHIFT is the number of digits occupied by the area type, GFP_ZONE_TABLE maps each flag combination to a position of a 32-bit integer. The offset is (flag combination * region type bits), and the GFP starts from this offset_ ZONES_ Shift is a binary storage area type.
#define GFP_ZONE_TABLE ( \ (ZONE_NORMAL << 0 * GFP_ZONES_SHIFT) \ | (OPT_ZONE_DMA << ___GFP_DMA * GFP_ZONES_SHIFT) \ | (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * GFP_ZONES_SHIFT) \ | (OPT_ZONE_DMA32 << ___GFP_DMA32 * GFP_ZONES_SHIFT) \ | (ZONE_NORMAL << ___GFP_MOVABLE * GFP_ZONES_SHIFT) \ | (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * GFP_ZONES_SHIFT) \ | (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * GFP_ZONES_SHIFT)\ | (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * GFP_ZONES_SHIFT)\ ) //Get the preferred area according to the flags flag #define ___GFP_DMA 0x01u #define ___GFP_HIGHMEM 0x02u #define ___GFP_DMA32 0x04u #define ___GFP_MOVABLE 0x08u
5. List of spare areas
The standby area is very important, but I can't fully understand it now. I only know that it can speed up our application for memory, and it will be used in the following fast path.
If the preferred memory node or region cannot meet the allocation request, you can borrow physical pages from the standby memory region. Borrowing must comply with the corresponding rules.
Borrowing rules:
1) An area type of a memory node can borrow physical pages from the same area type of another memory node. For example, the common area of node 0 can borrow physical pages from the common area of node 1.
2) High area type can borrow physical pages from area type, for example, ordinary area can borrow physical pages from DMA area
3) Physical pages cannot be borrowed from high area type for area type. For example, physical pages cannot be borrowed from normal area for DMA area
Structure PG of memory node_ data_ T the instance has defined an alternate area list node_zonelists.
6. Structure of partner distributor
The kernel source code is as follows:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];//Memory area array
struct zonelist node_zonelists[MAX_ZONELISTS];//MAX_ZONELISTS is an array of alternate areas
int nr_zones;//The number of memory areas that this node contains
......
}
//Application of struct zone in linux memory management (I)
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
struct zoneref {
struct zone *zone;//Data structure pointing to memory area
int zone_idx;//The member zone points to the type of memory area
};
enum {
ZONELIST_FALLBACK,//List of spare areas containing all memory nodes
#ifdef CONFIG_NUMA
/*
* The NUMA zonelists are doubled because we need zonelists that
* restrict the allocations to a single node for __GFP_THISNODE.
*/
ZONELIST_NOFALLBACK,//Contains only the spare area list of the current node (NUMA only)
#endif
MAX_ZONELISTS//Indicates the number of spare area lists
};
UMA system only has a list of spare areas, which are arranged from high to low according to the area type. Assuming that the UMA system contains common area and DMA area, the list of standby areas is: (common area, MDA area). Each memory node in NUMA system has two spare area lists: one contains the memory area of all nodes, and the other only contains the memory area of the current node.
ZONELIST_ The fallback list has two sorting methods:
a. Node priority
First, sort from small to large according to the node distance, and then sort from high to low according to the area type in each node.
The advantage is to preferentially select the memory with close distance, while the disadvantage is to use the low area before the high area is exhausted.
b. Regional priority
First sort from high to low according to the area type, and then sort from small to large according to the node distance in each area type.
The advantage is to reduce the probability of low area depletion, but the disadvantage is that it can not guarantee the priority of selecting memory close to each other.
The default sorting method is to automatically select the optimal sorting method: for example, in a 64 bit system, the node priority is selected because there are relatively few spare DMA and DMA32 areas; If it is a 32-bit system, select area priority.
7. Water line of memory area
The preferred memory area. Under what circumstances do you borrow physical pages from the standby area? Each memory area has 3 waterlines:
a. High waterline: if the number of free pages in the memory area is greater than the high waterline, it indicates that the memory in the memory area is very sufficient;
b. Low waterline: if the number of free pages in the memory area is less than the low waterline, it indicates that the memory in the memory area is slightly insufficient;
c. Minimum waterline (min): if the number of free pages in the memory area is less than the minimum waterline, it indicates that the memory in the memory area is seriously insufficient.
Moreover, the water level of each area is calculated through the physical page of each area during initialization. After calculation, it is stored in the watermark array of struct zone. When used, it is directly obtained through the following macro definition:
#define min_wmark_pages(z) (z->watermark[WMARK_MIN]) #define low_wmark_pages(z) (z->watermark[WMARK_LOW]) #define high_wmark_pages(z) (z->watermark[WMARK_HIGH])
Data structure of struct zone:


spanned_pages = zone_end_pfn - zone_start_pfn;//The physical page at the end of the region minus the starting page = the total number of pages crossed by the current region (including holes) present_pages = spanned_pages - absent_pages(pages in holes)//Total pages crossed by the current region - empty pages = available physical pages in the current region managed_pages = present_pages - reserved_pages//Available physical pages in current area - reserved pages = physical pages managed by partner allocator
The memory below the lowest waterline is called emergency reserved memory, which is generally used for memory recovery. Emergency reserved memory can not be used in other situations. In case of serious shortage of memory, it is used by the process that promises to "give us a small amount of emergency reserved memory, and I can release more memory".
You can see the water level and physical page of the system zone through / proc/zoneinfo
jian@ubuntu:~/share/linux-4.19.40-note$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3912
min 7
low 8
high 10
scanned 0
spanned 4095
present 3997
managed 3976
...
Node 0, zone DMA32
pages free 6515
min 1497
low 1871
high 2245
scanned 0
spanned 1044480
present 782288
managed 762172
...
Node 0, zone Normal
pages free 2964
min 474
low 592
high 711
scanned 0
spanned 262144
present 262144
managed 241089
...
8. Partner distributor allocation process analysis
When the partner allocator allocates pages, it first calls alloc_pages,alloc_ Pages will call alloc_pages_current,alloc_pages_ Current will call__ alloc_pages_nodemask function, which is the core function of partner allocator:
/* The ALLOC_WMARK bits are used as an index to zone->watermark */ #define ALLOC_WMARK_MIN WMARK_MIN // Use lowest waterline #define ALLOC_WMARK_LOW WMARK_LOW // Use low waterline #define ALLOC_WMARK_HIGH WMARK_HIGH // Use high waterline #define ALLOC_NO_WATERMARKS 0x04 // Don't check the waterline at all #define ALLOC_WMARK_MASK (ALLOC_NO_WATERMARKS-1) / / get the mask of the watermark #ifdef CONFIG_MMU #define ALLOC_OOM 0x08 // Allow memory to run out #else #define ALLOC_OOM ALLOC_NO_WATERMARKS / / allow memory exhaustion #endif #define ALLOC_HARDER 0x10 / / try harder to allocate #define ALLOC_HIGH 0x20 / / the caller is of high priority #define ALLOC_CPUSET 0x40 / / check whether cpuset allows the process to allocate pages from a memory node #define ALLOC_CMA 0x80 / / allow migration of type allocation from CMA (continuous memory allocator)
Above is alloc_ The first parameter of pages allocates a flag bit, indicating the allocation permission, alloc_ The second parameter of pages indicates the order of allocation
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
...
/* First allocation attempt */ //Fast path assignment function
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
...
//If the fast path allocation fails, the following slow allocation function will be called
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}
Core functions from partner allocator__ alloc_pages_nodemask can see two main parts of the function. One is to execute the quick allocation function get_page_from_freelist, the second is to execute the slow allocation function__ alloc_pages_slowpath. Now let's look at the quick allocation function get_page_from_freelist
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
//Scan every qualified area in the standby area list: the area type is less than or equal to the preferred area type
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() && //If the cpuset function is compiled
(alloc_flags & ALLOC_CPUSET) && //If alloc is set_ CPUSET
!__cpuset_zone_allowed(zone, gfp_mask)) //If the cpu is set to disallow memory allocation from the current region
continue; //Then it is not allowed to allocate from this area and enter the next cycle
if (ac->spread_dirty_pages) {//If the write flag bit is set, it indicates that the write cache is to be allocated
//Then check whether the number of dirty pages in memory exceeds the limit. If it exceeds the limit, it cannot be allocated from this area
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];//Check the allowable distribution water line
//Judge whether (area free Pages - number of application pages) is less than the waterline
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
//If there is no water line requirement, select this area directly
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
//If the node recycling function is not enabled or the distance between the current node and the preferred node is greater than the recycling distance
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
//Reclaim "memory pages not mapped to the process virtual address space" from the node, and then check the waterline
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone://When the above conditions are met, start allocation
//Assign page from current region
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
//Allocation succeeded, initialization page
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
//If this is a high-level memory and alloc_ Order, you need to check whether it needs to be retained in the future
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
//Delay allocation if allocation fails
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
return NULL;
}
Then look at the slow allocation function__ alloc_pages_slowpath:
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
//Later, you may check whether cpuset allows the current process to request pages from which memory nodes
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
//Convert the allocation flag bit to the internal allocation flag bit
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* We need to recalculate the starting point for the zonelist iterator
* because we might have used different nodemask in the fast path, or
* there was a cpuset modification and we are retrying - otherwise we
* could end up iterating over non-eligible zones endlessly.
*/
//Get the preferred memory area because different node masks are used in the fast path to avoid traversing the unqualified area again.
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
//Asynchronously reclaim pages and wake up the kswapd kernel thread to reclaim pages
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, gfp_mask, ac);
/*
* The adjusted alloc_flags might result in immediate success, so try
* that first
*/
//Adjust alloc_ The application may succeed immediately after flags, so try it first
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
* For costly allocations, try direct compaction first, as it's likely
* that we have enough base pages and don't need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* Don't try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen.
*/
//If the application order is greater than 0, it is immovable and located in the high order, and the water mark is ignored
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
//Direct page recycling and then page allocation
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes THP page fault allocations
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
/*
* If compaction is deferred for high-order allocations,
* it is because sync compaction recently failed. If
* this is the case and the caller requested a THP
* allocation, we do not want to heavily disrupt the
* system, so we fail the allocation instead of entering
* direct reclaim.
*/
if (compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
//Synchronous compression is very expensive, so continue to use asynchronous compression
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
//Wake up again if the page recycle thread sleeps unexpectedly
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, gfp_mask, ac);
//If the caller promises to give us emergency memory use, we ignore the waterline
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = reserve_flags;
/*
* Reset the nodemask and zonelist iterators if memory policies can be
* ignored. These allocations are high priority and system rather than
* user oriented.
*/
//If the memory policy can be ignored, reset nodemask and zonelist
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
//Try to use the area alternate list and allocation flags that may be adjusted
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
//If it cannot be recycled directly, the application fails
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
//Direct page recycling and then page allocation
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
//Compress the page, and then allocate the page
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
//If the caller asks not to retry, discard
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
//Do not retry expensive higher-order assignments unless they are__ GFP_RETRY_MAYFAIL
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
//Retry recycling page
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
/*
* It doesn't make any sense to retry for the compaction if the order-0
* reclaim is not able to make any progress because the current
* implementation of the compaction depends on the sufficient amount
* of free memory (see __compaction_suitable)
*/
//If the application order is greater than 0, judge whether it is necessary to retry compression
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
//If cpuset allows to modify the memory node, the request will be modified
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
//Use oom to select a process
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
//If the current process is the process selected by oom and the waterline is ignored, the application will be abandoned
if (tsk_is_oom_victim(current) &&
(alloc_flags == ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
//If the OOM killer is making progress, try again
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/* Deal with possible cpuset update races before we fail */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/*
* Make sure that __GFP_NOFAIL request doesn't leak out and make sure
* we always retry
*/
if (gfp_mask & __GFP_NOFAIL) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually require GFP_NOWAIT
*/
if (WARN_ON_ONCE(!can_direct_reclaim))
goto fail;
/*
* PF_MEMALLOC request from this context is rather bizarre
* because we cannot reclaim anything and only can loop waiting
* for somebody to do a work for us
*/
WARN_ON_ONCE(current->flags & PF_MEMALLOC);
/*
* non failing costly orders are a hard requirement which we
* are not prepared for much so let's warn about these users
* so that we can identify them and convert them to something
* else.
*/
WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);
/*
* Help non-failing allocations by giving them access to memory
* reserves but do not use ALLOC_NO_WATERMARKS because this
* could deplete whole memory reserves which would just make
* the situation worse
*/
//Allow them to access the memory spare list
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);
if (page)
goto got_pg;
cond_resched();
goto retry;
}
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}