1. Introduction
stay (4) Spare memory model of Linux memory model In, we analyze bootmem_ The upper part of the init function. This time, let's go to the lower part. The lower part mainly focuses on the zone_sizes_init function expansion.
Prospect review:
bootmem_ The init() function code is as follows:
void __init bootmem_init(void)
{
unsigned long min, max;
min = PFN_UP(memblock_start_of_DRAM());
max = PFN_DOWN(memblock_end_of_DRAM());
early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT);
max_pfn = max_low_pfn = max;
arm64_numa_init();
/*
* Sparsemem tries to allocate bootmem in memory_present(), so must be
* done after the fixed reservations.
*/
arm64_memory_present();
sparse_init();
zone_sizes_init(min, max);
memblock_dump_all();
}
In Linux, the physical memory address area is managed by zone. I'm not going to play too much foreplay. I'll play a zone first_ sizes_ Init function call graph:
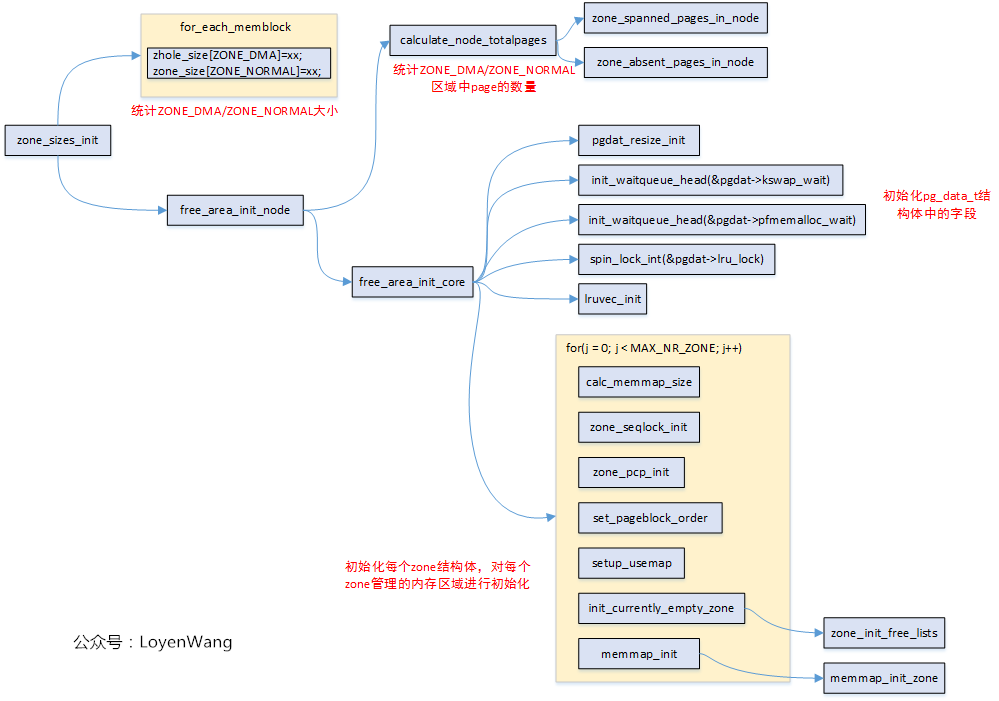
It should be noted that ARM64 and UMA are used (there is only one Node). In addition, for those macros that are not opened in the process analysis, the corresponding functions will not be analyzed in depth. Start exploring!
2. Data structure
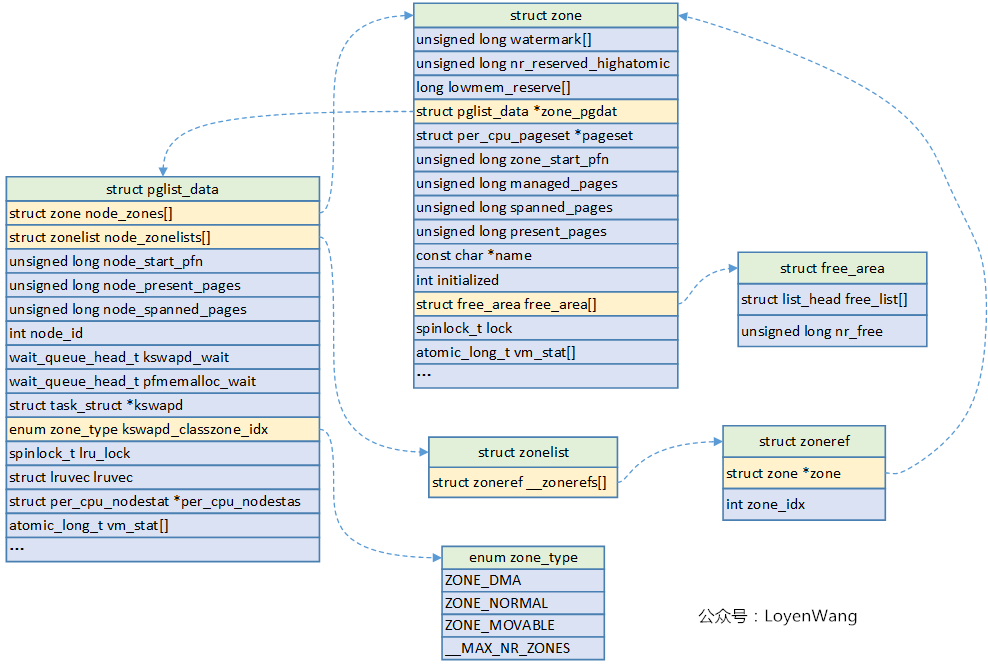
The key structure is shown in the figure above.
In NUMA architecture, each Node will correspond to a struct pglist_data, only a unique struct pglist will be used in the UMA architecture_ Data structure, such as the global variable struct pglist used in ARM64 UMA_ data __ refdata contig_ page_ data.
struct pglist_data key fields
struct zone node_zones[]; //Corresponding zone area, such as ZONE_DMA,ZONE_NORMAL et al struct zonelist_node_zonelists[]; unsigned long node_start_pfn; //The starting memory page frame number of the node unsigned long node_present_pages; //Total number of pages available unsigned long node_spanned_pages; //Total number of pages, including empty areas wait_queue_head_t kswapd_wait; //The waiting queue used by the page recycling process struct task_struct *kswapd; //Page recycling process
struct zone key fields
unsigned long watermark[]; //Water level value, WMARK_MIN/WMARK_LOV/WMARK_HIGH, which is used in page allocator and kswapd page recycling long lowmem_reserved[]; //Memory reserved in zone struct pglist_data *zone_pgdat; //Execute the pglist to which it belongs_ data struct per_cpu_pageset *pageset; //Pages on per CPU to reduce spin lock contention unsigned long zone_start_pfn; //Start memory page frame number of ZONE unsigned long managed_pages; //Number of pages managed by Buddy System unsigned long spanned_pages; //The total number of pages in ZONE, including empty areas unsigned long present_pages; //Number of pages actually managed in ZONE struct frea_area free_area[]; //Manage the list of free pages
Description of macro points: struct pglist_data describes the memory of a single Node (all memory in UMA Architecture), and then the memory is divided into different zone areas. Zone describes different pages in the area, including free pages, pages managed by Buddy System, etc.
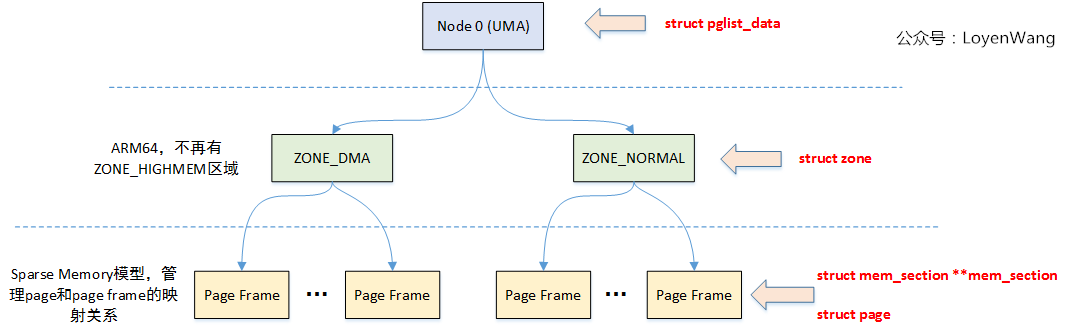
3. zone
Last code:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
General memory management should deal with different architectures, X86, ARM, MIPS, In order to reduce complexity, you only need to pick your own architecture related. At present, the platform I use is only configured with ZONE_DMA and ZONE_NORMAL. The Log output is shown in the following figure:
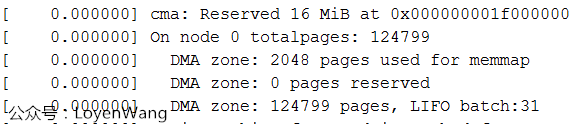
Why not zone_ In the normal area, track the one-way code and find zone_ The size of DMA area setting is the 4G area starting from the starting memory and cannot exceed the 4G boundary area, while the memory I use is 512M, so it is all in this area.
As can be seen from the above structure, ZONE_DMA is defined by macro, ZONE_NORMAL is the area that all architectures have, so why do you need a zone_ In DMA area, take a picture:
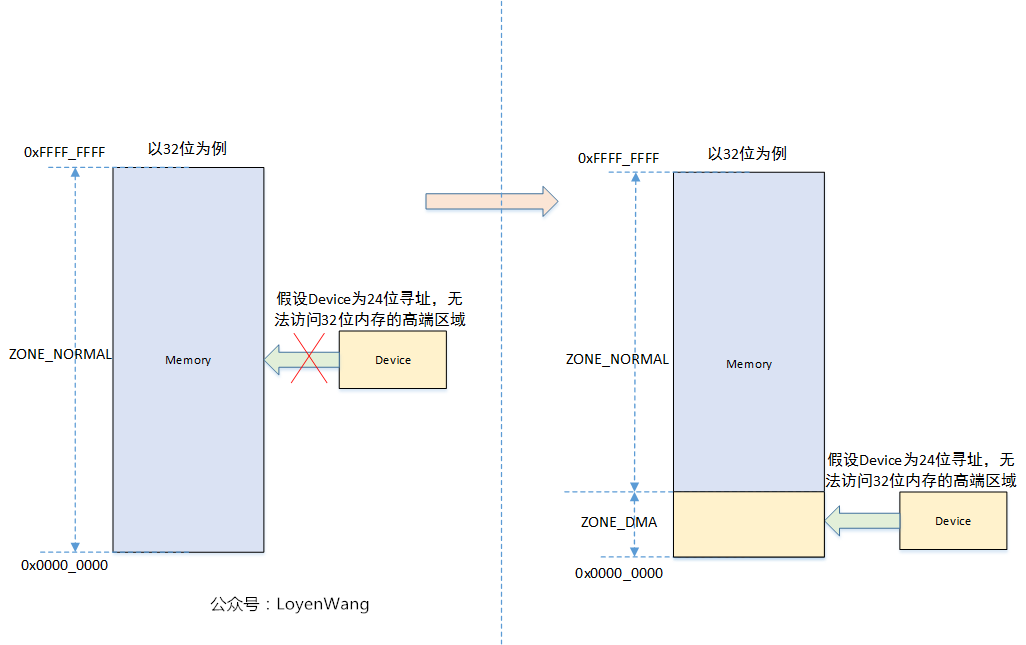
Therefore, if the addressing range of all devices is within the memory area, then a ZONE_NORMAL is enough.
4. calculate_node_totalpages
From the name, it is easy to know that this is to count the number of pages in the Node. A picture explains all:
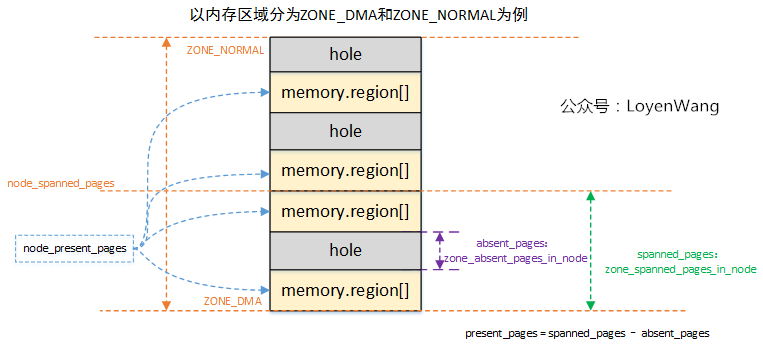
- The previous article has analyzed that the physical memory is maintained by memblock, and there may be empty areas in the whole memory area, that is, the hole part in the figure;
- For each type of ZONE area, the page frame s crossed and possible holes will be counted respectively, and the actual available page present will be calculated_ pages;
- Node manages each ZONE and its spanned_pages and present_pages is the sum of the corresponding pages of each ZONE.
After this process is calculated, the information of the page box is basically included in the management.
5. free_area_init_core
In short, free_ area_ init_ The core function mainly completes struct pglist_ Initialize the fields in the data structure and initialize the zone s it manages. Take a look at the code:
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*
* NOTE: pgdat should get zeroed by caller.
*/
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_resize_init(pgdat);
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spin_lock_init(&pgdat->split_queue_lock);
INIT_LIST_HEAD(&pgdat->split_queue);
pgdat->split_queue_len = 0;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTION
init_waitqueue_head(&pgdat->kcompactd_wait);
#endif
pgdat_page_ext_init(pgdat);
spin_lock_init(&pgdat->lru_lock);
lruvec_init(node_lruvec(pgdat));
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
#endif
zone->name = zone_names[j];
zone->zone_pgdat = pgdat;
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
init_currently_empty_zone(zone, zone_start_pfn, size);
memmap_init(size, nid, j, zone_start_pfn);
}
}
- Initialize struct pglist_ Locks and queues used internally by data;
Traverse each zone and perform the following initialization:
-
According to zone's spanned_pages and present_pages, call calc_memmap_size calculates the number of pages occupied by the struct page structure required to manage the zone_ pages;
-
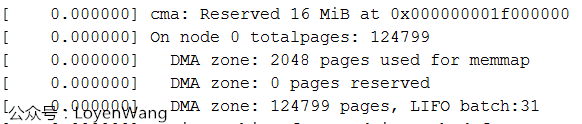
freesize in zone indicates the available area, and memmap needs to be subtracted_ Pages and DMA_RESERVE area, as shown in the Log print on the development board in the following figure: 2048 pages are used for memmap, and 0 pages are reserved for DMA};
-
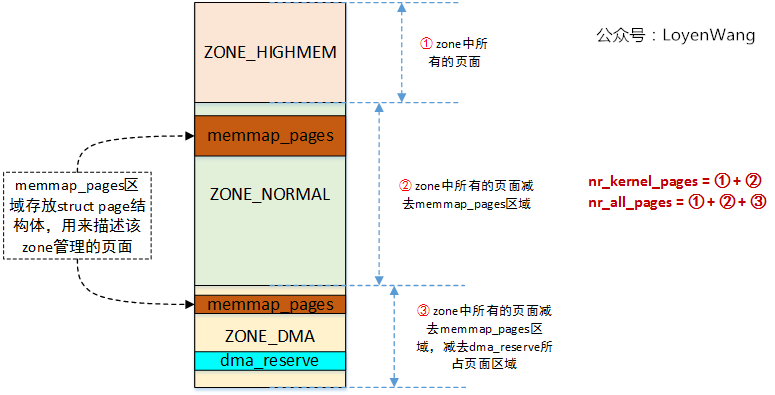
Calculate nr_kernel_pages and NR_ all_ The number of pages. In order to illustrate the relationship between these two parameters and the page, let's take ARM32 as an example (because the platform I use has only one ZONE_DMA area, and ARM64 has no ZONE_HIGHMEM area, which is not typical):
-
Initialize various locks used by the zone;
-
Allocate and initialize usemap, and initialize free used in Buddy System_ Area [], lruvec, pcp, etc;
-
memmap_ init()->memmap_ init_ Zone(), this function is mainly based on PFN, through pfn_to_page find the corresponding struct page structure, initialize the structure, and set MIGRATE_MOVABLE flag, indicating movable;
Finally, when we review bootmem_ The init function basically completes the initialization of the linux physical memory framework, including Node, Zone, Page Frame, and corresponding data structures.
Combined with the previous article (4) Spare memory model of Linux memory model Reading, the effect will be better!
Reprint link:
 https://www.cnblogs.com/LoyenWang/p/11568481.html
https://www.cnblogs.com/LoyenWang/p/11568481.html