Linux as a general hardware kernel, how to achieve general and efficient memory management. In the previous article on Linux memory segmentation and paging, we mainly explain that the Linux kernel carries out the abstract mapping of physical address, logical address and linear address, which is like dividing territory for families in a wilderness, which is very much like land reform. Considering a country's land governance process, in the early days of the founding of the people's Republic of China, all waste is waiting for prosperity, and memory resources are as precious and limited as land resources. How to carry out land reform is a national event, which is related to the planning, construction and development of the country. For example, how to carry out memory management planning is related to the overall planning and development of the system. Just as the land reform divided the land for each family, the kernel divided the memory according to the address, arranged through the virtual address, and each memory address was planned into the page table. However, this is not enough. You can see that in terms of land management, the state not only divides by households, but also by provinces and urban areas, and by development functional areas, such as development zones, tourist areas, residential areas, etc., organizes the land structure through a variety of concepts to meet the needs of development. Like land management, in addition to the basic division of segmented paging address arrangement, Linux also divides the management memory through multiple groups of concepts, such as flat (uma) and non flat (numa) memory according to the organizational structure of memory and CPU, DMA, normal and highmem concepts according to the functional domain, and nodes, memory zones and pages according to the organizational structure, Linux memory management has the concepts of kernel and user space. In the kernel, there are subsystems such as memory allocation management system hubby, slab, vmalloc and so on. There is a virtual memory management system in user space.
I node
Linux system divides memory into nodes and includes UMA as an extreme case of NUMA. Each node is associated with a processor in the system, and PA is used in the kernel_ data_ T. Then, each node is divided into memory domain, and memory page is the division of another dimension. Each memory node is connected to a single linked list. Each node saves the fields of other nodes. When allocating memory, it traverses each memory node and memory field according to the distance between nodes, allocation speed and allocation cost to achieve the efficiency of memory allocation. In the kernel, the concept of node is through pglist_data structure.
linux-5.4.80/include/linux/mmzone.h
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //Array of fields for this node
struct zonelist node_zonelists[MAX_ZONELISTS];//Array of alternate fields for this node
int nr_zones;
....
} pg_data_t;
II Memory domain
1. 32-bit Division
Firstly, the Linux kernel is divided into user state and kernel state. In 32bit x86 machines, the division ratio of 4G address space between user process and kernel is 3:1, 0 ~ 3G is used for user space and 3 ~ 4G is used for kernel.

3 ~ 4G in the virtual address space is the Linux kernel virtual address space, in which the kernel space 3G ~ 3G+896M corresponds to 0 ~ 896M of the physical memory space, and the 3G ~ 3G+896M (0xC0000 0000 ~ 0xF7FF FFFF) virtual address space has been corresponding to 0 ~ 896M of the physical memory space during kernel initialization. When the kernel accesses the memory of 0 ~ 896M, Just add an offset to its corresponding virtual address space. For physical address spaces over 896M, they belong to high-end memory. The memory pages contained in the high-end memory area cannot be accessed directly by the kernel, although they are also linearly mapped to the fourth g of the linear address space. In other words, for the high-end memory area, only 128M linear addresses (0xf80000 ~ 0xFFFF ffff) are left for mapping.

Linux divides the physical memory of each memory node into three management areas, that is, ZONE_DMA: the range is 0 ~ 1:6M. The physical page in this area is specially used for DMA of I/O devices. ZONE_NORMAL: the range is 16 ~ 896M. The physical page in this area is zone that can be directly used by the kernel_ Highmem: the range is 896 ~ end, high-end memory, and the kernel cannot be used directly.
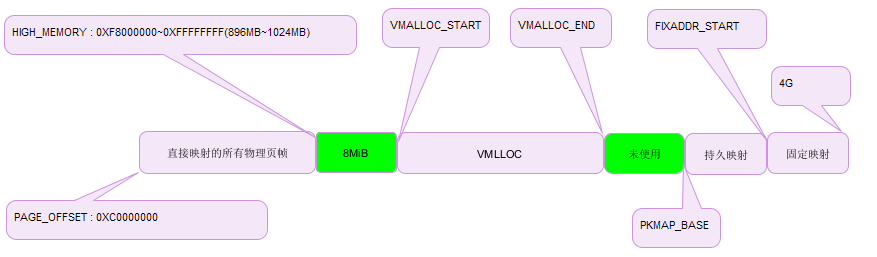
PAGE_OFFSET is usually 0xC000 0000 and high_memory refers to 0xF7FF FFFF. The 8MB memory area inserted between the physical memory mapping area and the first vmalloc area is a safe area. Its purpose is to "capture" cross-border access to memory. For the same reason, insert other 4KB safe areas to isolate discontinuous memory areas. The Linux kernel can use three different mechanisms to map the page frame to the high-end memory area, which are called permanent kernel mapping, temporary kernel mapping and discontinuous memory allocation.
Physical memory mapping: it maps the 0 ~ 896M part of the physical memory space, which can be accessed directly by the kernel. Permanent kernel mapping: allows the kernel to establish a long-term mapping from the high-end page frame to the kernel virtual address space. Permanent kernel mapping cannot be used for interrupt handlers and delayable functions because establishing permanent kernel mapping may block the current process. Fixed mapped linear address space: part of it is used to establish temporary kernel mapping. vmalloc area: this area is used to establish discontinuous memory allocation.
2. 64 bit partition
In the memory segmented paging, we talked about the memory four-level and five-level paging management of 64 bit machines. The 64 bit address space span is quite large. At present, it is limited to 48 bits wide, and the address space can reach 256TB. Theoretically, it can also be used for a period of time. In order to meet the subsequent address space expansion from 48 bits to 46 or 64 bits. The kernel divides the 64 bit virtual address space into two ends, and fills [47:63] with 0 or 1 to divide the user space and kernel space, so as to effectively manage the kernel address space and meet the scalability at the same time. The middle undeveloped area will be vacated for later expansion to a memory bit width of more than 48 bits. Because both spaces are extremely large, there is no need to divide the scale like a 32-bit machine. At the same time, there is no need to divide the high-end memory domain.
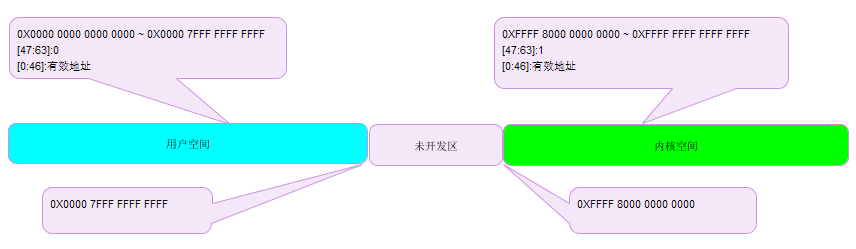
Physical memory pages are consistently mapped to page_ In the kernel space from offset, the whole left half of the accessible space is used as the user space, and the whole right half is used as the kernel space.
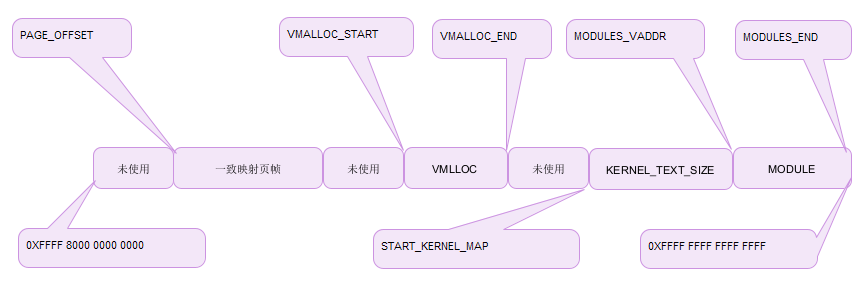
Because the memory space of 64 bit machines is so large that there is enough space for the kernel to access and use, there is no need for high-end memory. The domain division is shown in the figure above. The consistent mapping area is directly accessed by the kernel, the vmalloc area is used for kernel mapping, and the kernel code segment is mapped from_ start_ kernek_ The memory area starting from map. module is used by kernel modules.
In the kernel, the concept of domain is represented by zone structure
linux-5.4.80/include/linux/mmzone.h
struct zone {
unsigned long _watermark[NR_WMARK]; //Memory load pressure line
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat; //Point backwards to the node that contains the domain
struct per_cpu_pageset __percpu *pageset;
......
} ____cacheline_internodealigned_in_smp;
The concept of page is represented by the page structure
linux-5.4.80/include/linux/mm_types.h
struct page {
struct address_space *mapping;// address space
struct kmem_cache *slab_cache; //Point to slab cache
......
}
III structure
In the Linux kernel startup process, we know that the Linux kernel enters the protected mode through the real address mode and transitions to start_ The kernel starts the entry, and the kernel transitions from segment management to page management. Now let's look at the construction process of memory management. First of all, before the Linux kernel builds page management, the kernel runs in the real address mode. At the initial stage of startup, the kernel does not have page management. The kernel manages memory by building a temporary memory allocator to provide a memory allocation mechanism for the further operation of the kernel, such as allocating running space for the memory management structure.
linux-5.4.80/init/main.c
asmlinkage __visible void __init start_kernel(void)
{
setup_arch(&command_line); //CPU related initialization
build_all_zonelists(NULL); //Build alternate domains for each memory node
......
}
linux-5.4.80/arch/x86/kernel/setup.c
Processor related processing
void __init setup_arch(char **cmdline_p)
{
//Reserved for kernel code snippets
memblock_reserve(__pa_symbol(_text),
(unsigned long)__end_of_kernel_reserve - (unsigned long)_text);
memblock_reserve(0, PAGE_SIZE); //First page reserved
early_reserve_initrd(); //Reserved for initramfs
......
init_mem_mapping();
......
x86_init.paging.pagetable_init();
......
}
1. Kernel startup memory management
memblock is a memory manager during Linux startup. It is mainly constructed by the following three data structures. After the kernel is started, it will be replaced and destroyed
linux-5.4.80/include/linux/memblock.h
struct memblock {
bool bottom_up; /* is bottom up direction? */
phys_addr_t current_limit;
struct memblock_type memory;
struct memblock_type reserved;
#ifdef CONFIG_HAVE_MEMBLOCK_PHYS_MAP
struct memblock_type physmem;
#endif
};
linux-5.4.80/include/linux/memblock.h
Describes the memory block type and the memory block linked list
struct memblock_type {
unsigned long cnt;
unsigned long max;
phys_addr_t total_size;
struct memblock_region *regions;
char *name;
};
linux-5.4.80/include/linux/memblock.h
Memory area number, memory base address, area memory size
struct memblock_region {
phys_addr_t base;
phys_addr_t size;
enum memblock_flags flags;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
int nid;
#endif
};
After the construction of memory management is completed, switch to page management, then lose the temporary allocator and transition to a new memory manager. Then build the hubby system based on the memory manager, and then build the slab, slob and slub memory allocators based on the hubby. Today we'll just look at the process of building the memory manager.
2. Kernel virtual memory area mapping
linux-5.4.80/arch/x86/mm/init.c
Memory mapping
void __init init_mem_mapping(void)
{
unsigned long end;
pti_check_boottime_disable();
probe_page_size_mask();
setup_pcid();
#ifdef CONFIG_X86_64
end = max_pfn << PAGE_SHIFT;
#else
end = max_low_pfn << PAGE_SHIFT;
#endif
init_memory_mapping(0, ISA_END_ADDRESS);
init_trampoline();
if (memblock_bottom_up()) {
unsigned long kernel_end = __pa_symbol(_end);
memory_map_bottom_up(kernel_end, end);
memory_map_bottom_up(ISA_END_ADDRESS, kernel_end);
} else {
memory_map_top_down(ISA_END_ADDRESS, end);
}
load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
}
linux-5.4.80/arch/x86/mm/init.c
static void __init memory_map_bottom_up(unsigned long map_start,
unsigned long map_end)
{
unsigned long next, start;
unsigned long mapped_ram_size = 0;
/* step_size need to be small so pgt_buf from BRK could cover it */
unsigned long step_size = PMD_SIZE;
start = map_start;
min_pfn_mapped = start >> PAGE_SHIFT;
while (start < map_end) {
if (step_size && map_end - start > step_size) {
next = round_up(start + 1, step_size);
if (next > map_end)
next = map_end;
} else {
next = map_end;
}
mapped_ram_size += init_range_memory_mapping(start, next);
start = next;
if (mapped_ram_size >= step_size)
step_size = get_new_step_size(step_size);
}
}
linux-5.4.80/arch/x86/mm/init.c
You need to traverse the E820 memory map and create a direct map
static unsigned long __init init_range_memory_mapping(
unsigned long r_start,
unsigned long r_end)
{
unsigned long start_pfn, end_pfn;
unsigned long mapped_ram_size = 0;
int i;
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, NULL) {
u64 start = clamp_val(PFN_PHYS(start_pfn), r_start, r_end);
u64 end = clamp_val(PFN_PHYS(end_pfn), r_start, r_end);
if (start >= end)
continue;
can_use_brk_pgt = max(start, (u64)pgt_buf_end<<PAGE_SHIFT) >=
min(end, (u64)pgt_buf_top<<PAGE_SHIFT);
init_memory_mapping(start, end);
mapped_ram_size += end - start;
can_use_brk_pgt = true;
}
return mapped_ram_size;
}
linux-5.4.80/arch/x86/mm/init.c
Sets the direct mapping of physical memory at the page offset
unsigned long __ref init_memory_mapping(unsigned long start,
unsigned long end)
{
struct map_range mr[NR_RANGE_MR];
unsigned long ret = 0;
int nr_range, i;
memset(mr, 0, sizeof(mr));
nr_range = split_mem_range(mr, 0, start, end);
for (i = 0; i < nr_range; i++)
ret = kernel_physical_mapping_init(mr[i].start, mr[i].end,
mr[i].page_size_mask);
add_pfn_range_mapped(start >> PAGE_SHIFT, ret >> PAGE_SHIFT);
return ret >> PAGE_SHIFT;
}
linux-5.4.80/arch/x86/mm/init_64.c
Build a page table for the mapped area and allocate memory
static unsigned long __meminit
__kernel_physical_mapping_init(unsigned long paddr_start,
unsigned long paddr_end,
unsigned long page_size_mask,
bool init)
{
bool pgd_changed = false;
unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
paddr_last = paddr_end;
vaddr = (unsigned long)__va(paddr_start);
vaddr_end = (unsigned long)__va(paddr_end);
vaddr_start = vaddr;
//Loop map to page table
for (; vaddr < vaddr_end; vaddr = vaddr_next) {
pgd_t *pgd = pgd_offset_k(vaddr);
p4d_t *p4d;
vaddr_next = (vaddr & PGDIR_MASK) + PGDIR_SIZE;
if (pgd_val(*pgd)) {
p4d = (p4d_t *)pgd_page_vaddr(*pgd);
paddr_last = phys_p4d_init(p4d, __pa(vaddr),
__pa(vaddr_end),
page_size_mask,
init);
continue;
}
p4d = alloc_low_page();
paddr_last = phys_p4d_init(p4d, __pa(vaddr), __pa(vaddr_end),
page_size_mask, init);
spin_lock(&init_mm.page_table_lock);
if (pgtable_l5_enabled())
pgd_populate_init(&init_mm, pgd, p4d, init);
else
p4d_populate_init(&init_mm, p4d_offset(pgd, vaddr),
(pud_t *) p4d, init);
spin_unlock(&init_mm.page_table_lock);
pgd_changed = true;
}
if (pgd_changed)
sync_global_pgds(vaddr_start, vaddr_end - 1);
return paddr_last;
}
4. Kernel node domain page table mapping
linux-5.4.80/arch/x86/kernel/x86_init.c
Kernel memory node, memory domain, page table, three-level management mapping
.paging = {
.pagetable_init = native_pagetable_init,
},
linux-5.4.80/arch/x86/mm/init_32.c
void __init native_pagetable_init(void)
{
unsigned long pfn, va;
pgd_t *pgd, *base = swapper_pg_dir;
p4d_t *p4d;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
//Circular construction of page table memory mapping, offset PAGE_SHIFT
for (pfn = max_low_pfn; pfn < 1<<(32-PAGE_SHIFT); pfn++) {
va = PAGE_OFFSET + (pfn<<PAGE_SHIFT);
pgd = base + pgd_index(va);
if (!pgd_present(*pgd))
break;
p4d = p4d_offset(pgd, va);
pud = pud_offset(p4d, va);
pmd = pmd_offset(pud, va);
if (!pmd_present(*pmd))
break;
pte = pte_offset_kernel(pmd, va);
if (!pte_present(*pte))
break;
pte_clear(NULL, va, pte);
}
paravirt_alloc_pmd(&init_mm, __pa(base) >> PAGE_SHIFT);
//Partition system nodes and domains
paging_init();
}
linux-5.4.80/arch/x86/mm/init_32.c
void __init paging_init(void)
{
pagetable_init(); //Page directory base address and persistent area initialization
__flush_tlb_all();
kmap_init(); //Persistent mapping area
olpc_dt_build_devicetree();
sparse_memory_present_with_active_regions(MAX_NUMNODES);
sparse_init();
zone_sizes_init(); //Memory domain initialization
}
linux-5.4.80/arch/x86/mm/init_32.c
ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM area initialization
void __init zone_sizes_init(void)
{
unsigned long max_zone_pfns[MAX_NR_ZONES];
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
#ifdef CONFIG_ZONE_DMA
max_zone_pfns[ZONE_DMA] = min(MAX_DMA_PFN, max_low_pfn);
#endif
#ifdef CONFIG_ZONE_DMA32
max_zone_pfns[ZONE_DMA32] = min(MAX_DMA32_PFN, max_low_pfn);
#endif
max_zone_pfns[ZONE_NORMAL] = max_low_pfn;
#ifdef CONFIG_HIGHMEM
max_zone_pfns[ZONE_HIGHMEM] = max_pfn;
#endif
free_area_init_nodes(max_zone_pfns);
}
linux-5.4.80/mm/page_alloc.c
Loop map each node
void __init free_area_init_nodes(unsigned long *max_zone_pfn)
{
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
free_area_init_node(nid, NULL,
find_min_pfn_for_node(nid), NULL);
}
}
linux-5.4.80/mm/page_alloc.c
Compute the virtual mapping memory required by the node
void __init free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn,
unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
alloc_node_mem_map(pgdat);
pgdat_set_deferred_range(pgdat);
free_area_init_core(pgdat);
}
linux-5.4.80/mm/page_alloc.c
Loop through all nodes in the system, initialize and map the virtual memory of each Zone of each node
static void __init free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_init_internals(pgdat);
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
freesize = zone->present_pages;
memmap_pages = calc_memmap_size(size, freesize);
zone_init_internals(zone, j, nid, freesize);
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
init_currently_empty_zone(zone, zone_start_pfn, size);
memmap_init(size, nid, j, zone_start_pfn);
}
}
So far, the kernel has built a three-level management structure of node, memory domain and page table based on the memory allocator in the startup period. We will look at the replacement of memory allocator, partner system and slab allocator in the next article.