catalogue
1. Netlink communication data structure
1.1 netlink message header: struct nlmsghdr
1.2 socket message packet structure: struct msghdr
1.3 netlink message processing macro
2 application layer sends netlink message to kernel
3. The kernel sends netlink message to the application layer
4. The application layer receives the kernel netlink message
1. Netlink communication data structure
1.1 netlink message header: struct nlmsghdr
struct nlmsghdr {
__u32 nlmsg_len; /* Length of message including header */
__u16 nlmsg_type; /* Message content */
__u16 nlmsg_flags; /* Additional flags */
__u32 nlmsg_seq; /* Sequence number */
__u32 nlmsg_pid; /* Sending process port ID */
};Like TCP/UDP messages, netlink messages also need to follow the format required by the protocol. The beginning of each netlink message is a fixed length netlink header, and the actual load is after the header. The netlink header takes up a total of 16 bytes. The specific content is the same as that defined in struct nlmsghdr.
nlmsg_len: the length of the entire netlink message (including the message header);
nlmsg_type: message status. The kernel is in include / UAPI / Linux / netlink H defines the following four general message types:
- NLMSG_NOOP: the message must be discarded without performing any action;
- NLMSG_ERROR: an error occurred in the message;
- NLMSG_DONE: identifies the end of the packet message;
- NLMSG_ Override: buffer overflow, indicating that some messages have been lost.
In addition to these four types of messages, different netlink protocols can also add their own unique message types, but the kernel defines a type retention macro (#define NLMSG_MIN_TYPE 0x10), that is, the message type value less than this value is reserved by the kernel and is not available.
nlmsg_flags: message tags, which are used to indicate the type of message. They are also defined in include / UAPI / Linux / netlink H medium;
#define NLM_F_REQUEST 1 /* It is request message. */ #define NLM_F_MULTI 2 /* Multipart message, terminated by NLMSG_DONE */ #define NLM_F_ACK 4 /* Reply with ack, with zero or error code */ #define NLM_F_ECHO 8 /* Echo this request */ #define NLM_F_DUMP_INTR 16 /* Dump was inconsistent due to sequence change */ /* Modifiers to GET request */ #define NLM_F_ROOT 0x100 /* specify tree root */ #define NLM_F_MATCH 0x200 /* return all matching */ #define NLM_F_ATOMIC 0x400 /* atomic GET */ #define NLM_F_DUMP (NLM_F_ROOT|NLM_F_MATCH) /* Modifiers to NEW request */ #define NLM_F_REPLACE 0x100 /* Override existing */ #define NLM_F_EXCL 0x200 /* Do not touch, if it exists */ #define NLM_F_CREATE 0x400 /* Create, if it does not exist */ #define NLM_F_APPEND 0x800 /* Add to end of list */
nlmsg_seq: message sequence number, which is used to queue messages. It is somewhat similar to the sequence number in TCP protocol (not exactly the same), but this field of netlink is optional and not mandatory;
nlmsg_pid: the ID number of the sending port. For the kernel, this value is 0. For the user process, it is the ID number bound to its socket.
1.2 socket message packet structure: struct msghdr
struct user_msghdr {
void __user *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iovec __user *msg_iov; /* scatter/gather array */
__kernel_size_t msg_iovlen; /* # elements in msg_iov */
void __user *msg_control; /* ancillary data */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
unsigned int msg_flags; /* flags on received message */
};The application layer can use sendto() or sendmsg() functions to pass messages to the kernel. Sendmsg function requires the application to manually encapsulate msghdr message structure, and sendto() function will be allocated by the kernel. among
msg_name: the destination address of the packet;
msg_namelen: length of destination address data structure;
msg_iov: the actual data block of the message package, which is defined as follows:
struct iovec
{
void *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
//iov_base: the first address of the actual load of the message packet;
//iov_len: the length of the actual load of the message.msg_control: auxiliary data of the message;
msg_controllen: the size of message auxiliary data;
msg_flags: the identification of the received message.
For this structure, we need to pay more attention to the first three variable parameters, including MSG for netlink packets_ Name points to the destination sockaddr_nl first address of the address structure instance, iov_base refers to the address of the nlmsghdr header in the message entity, while iov_len is assigned to nlmsg in nlmsghdr_ Len (message header + actual data).
1.3 netlink message processing macro
#define NLMSG_ALIGNTO 4U #define NLMSG_ ALIGN(len) ( ((len)+NLMSG_ ALIGNTO-1) & ~(NLMSG_ALIGNTO-1) ) /* Perform 4-byte alignment on len*/ #define NLMSG_HDRLEN ((int) NLMSG_ALIGN(sizeof(struct nlmsghdr))) /* netlink header length*/ #define NLMSG_LENGTH(len) ((len) + NLMSG_HDRLEN) /* netlink message payload len plus message header*/ #define NLMSG_SPACE(len) NLMSG_ALIGN(NLMSG_LENGTH(len)) /* Performs byte alignment on the entire length of the netlink message*/ #define NLMSG_DATA(nlh) ((void*)(((char*)nlh) + NLMSG_LENGTH(0))) /* Get the actual payload location of netlink message*/ #define NLMSG_NEXT(nlh,len) ((len) -= NLMSG_ALIGN((nlh)->nlmsg_len), \ (struct nlmsghdr*)(((char*)(nlh)) + NLMSG_ALIGN((nlh)->nlmsg_len)))/* Get the first address of the next message and reduce len to the total length of the remaining messages */ #define NLMSG_OK(nlh,len) ((len) >= (int)sizeof(struct nlmsghdr) && \ (nlh)->nlmsg_len >= sizeof(struct nlmsghdr) && \ (nlh)->nlmsg_len <= (len)) /* Verify the length of the message */ #define NLMSG_ PAYLOAD(nlh,len) ((nlh)->nlmsg_ len - NLMSG_ SPACE((len))) /* Returns the length of payload*/
In order to process netlink messages conveniently, Linux uses # include / UAPI / Linux / netlink H defines the above message processing macros for various occasions. For netlink messages, the processing format is as follows (see netlink.h):
/* ======================================================================== * Netlink Messages and Attributes Interface (As Seen On TV) * ------------------------------------------------------------------------ * Messages Interface * ------------------------------------------------------------------------ * * Message Format: * <--- nlmsg_total_size(payload) ---> * <-- nlmsg_msg_size(payload) -> * +----------+- - -+-------------+- - -+-------- - - * | nlmsghdr | Pad | Payload | Pad | nlmsghdr * +----------+- - -+-------------+- - -+-------- - - * nlmsg_data(nlh)---^ ^ * nlmsg_next(nlh)-----------------------+ * * Payload Format: * <---------------------- nlmsg_len(nlh) ---------------------> * <------ hdrlen ------> <- nlmsg_attrlen(nlh, hdrlen) -> * +----------------------+- - -+--------------------------------+ * | Family Header | Pad | Attributes | * +----------------------+- - -+--------------------------------+ * nlmsg_attrdata(nlh, hdrlen)---^ * * ------------------------------------------------------------------------ * Attributes Interface * ------------------------------------------------------------------------ * * Attribute Format: * <------- nla_total_size(payload) -------> * <---- nla_attr_size(payload) -----> * +----------+- - -+- - - - - - - - - +- - -+-------- - - * | Header | Pad | Payload | Pad | Header * +----------+- - -+- - - - - - - - - +- - -+-------- - - * <- nla_len(nla) -> ^ * nla_data(nla)----^ | * nla_next(nla)-----------------------------' * *========================================================================= */
2 application layer sends netlink message to kernel
Use the following example program to send messages to the kernel netlink socket:
#define TEST_DATA_LEN 16 #DEFINE TEST_DATA "netlink send test" /* For example only, the kernel netlink_ The route socket could not be resolved*/ struct sockaddr_nl nladdr; struct msghdr msg; struct nlmsghdr *nlhdr; struct iovec iov; /* Populate destination address structure */ memset(&nladdr, 0, sizeof(nladdr)); nladdr.nl_family = AF_NETLINK; nladdr.nl_pid = 0; /* Address is kernel */ nladdr.nl_groups = 0; /* unicast */ /* Populate netlink headers */ nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(TEST_DATA_LEN)); nlhdr->nlmsg_len = NLMSG_LENGTH(TEST_DATA_LEN); nlhdr->nlmsg_flags = NLM_F_REQUEST; nlhdr->nlmsg_pid = get_pid(); /* ID number of the current socket binding (here is the PID of this process) */ nlhdr->nlmsg_seq = 0; /* netlink actual payload */ strcpy(NLMSG_DATA(nlhdr), TEST_DATA); iov.iov_base = (void *)nlhdr; iov.iov_len = nlhdr->nlmsg_len; /* Populate data message structure */ memset(&msg, 0, sizeof(msg)); msg.msg_name = (void *)&(nladdr); msg.msg_namelen = sizeof(nladdr); msg.msg_iov = &iov; msg.msg_iovlen = 1; /* Send netlink message */ sendmsg (sock, &msg, 0); /* sock See Netlink Kernel Implementation Analysis (I): creation for the descriptor, which is NETLINK_ROUTE type socket */
Here is a sample code fragment that calls sendmsg to send a message to the kernel (for example only, the sent message may not be parsed by the kernel netlink socket). First, initialize the destination address data structure and set nl_pid and nl_groups specifies that the destination address of the message is the kernel for 0; Then initialize the netlink header, indicating that the length of the message is TEST_DATA_LEN + NLMSG_ALIGN(sizeof(struct nlmsghdr)) (including message header), and the ID number of the sender is the ID number bound to the socket message (so that the kernel knows who sent the message); Then set the actual load of the message and copy the data to the actual load part immediately after the message header; Finally, assemble the msg message and call sendmsg to send it to the kernel.
Follow the whole process of sendmsg system call of the kernel to analyze how messages are sent to the kernel (it should be noted that there are 1 ~ 2 memory copy actions of data in the whole sending process without using NETLINK_MMAP technology, which will be listed one by one later!):
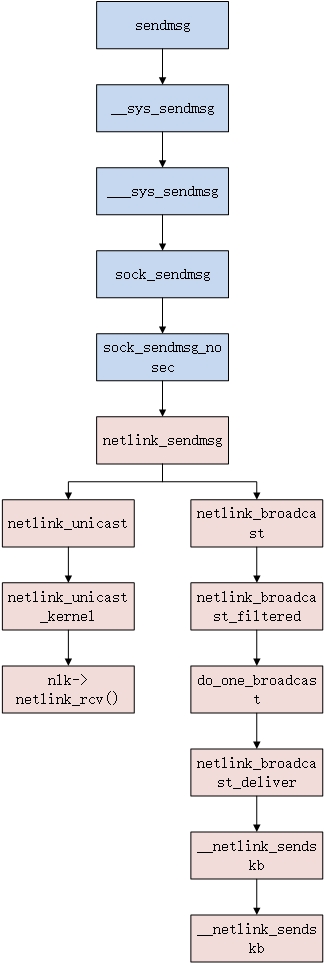
Figure 1 user status netlink data sending process
SYSCALL_DEFINE3(sendmsg, int, fd, struct user_msghdr __user *, msg, unsigned int, flags)
{
if (flags & MSG_CMSG_COMPAT)
return -EINVAL;
return __sys_sendmsg(fd, msg, flags);
}
long __sys_sendmsg(int fd, struct user_msghdr __user *msg, unsigned flags)
{
int fput_needed, err;
struct msghdr msg_sys;
struct socket *sock;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = ___sys_sendmsg(sock, msg, &msg_sys, flags, NULL);
fput_light(sock->file, fput_needed);
out:
return err;
}Sendmsg system call__ sys_sendmsg to carry out the actual operation, here first through the fd descriptor to find the corresponding socket socket structure instance, and then call the sys_ The third and last parameters of sendmsg() function should be paid attention to. The third one is a socket message packet structure of kernel version, which is slightly different from that of application layer. Its definition is as follows:
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iov_iter msg_iter; /* data */
void *msg_control; /* ancillary data */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
unsigned int msg_flags; /* flags on received message */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
};Where msg_name,msg_namelen,msg_control,msg_controllen and MSG_ The flags field has the same meaning as the application layer, msg_iter is msg_iov and MSG_ The combination of iovlen, and finally MSG_ Used for asynchronous IOCB requests. The last parameter is a struct used_address structure pointer. This structure is defined as follows:
struct used_address {
struct sockaddr_storage name;
unsigned int name_len;
};The name field here is used to store the address of the message, name_ The len field is the length of the message address, which is consistent with the first two fields of the struct msghdr structure. This structure is mainly used to save the destination addresses of multiple data packets with sendmmsg system call (for colleagues to send multiple data packets to a socket address, which can avoid repeated network security check, so as to improve the sending efficiency). Now it is set to NULL, which means it is not used. Continue to analyze and enter___ sys_ Inside the sendmsg() function, this function is relatively long and is analyzed in segments:
static int ___sys_sendmsg(struct socket *sock, struct user_msghdr __user *msg,
struct msghdr *msg_sys, unsigned int flags,
struct used_address *used_address)
{
struct compat_msghdr __user *msg_compat =
(struct compat_msghdr __user *)msg;
struct sockaddr_storage address;
struct iovec iovstack[UIO_FASTIOV], *iov = iovstack;
unsigned char ctl[sizeof(struct cmsghdr) + 20]
__attribute__ ((aligned(sizeof(__kernel_size_t))));
/* 20 is size of ipv6_pktinfo */
unsigned char *ctl_buf = ctl;
int ctl_len;
ssize_t err;
msg_sys->msg_name = &address;
if (MSG_CMSG_COMPAT & flags)
err = get_compat_msghdr(msg_sys, msg_compat, NULL, &iov);
else
err = copy_msghdr_from_user(msg_sys, msg, NULL, &iov);
if (err < 0)
return err;The iovstack array here is used to speed up the copying of user data (it is assumed that the number of iovec s of user data usually does not exceed UIO_FASTIOV. If it exceeds, memory will be allocated through kmalloc). First of all, judge whether the 32bit correction flag is set in the flag. It can be seen from the entrance of the system call in the previous article that the flag bit will not be set here, so copy is called here_ msghdr_ from_ The user function copies the message (struct user_msghdr _user * MSG) passed in from the user space to the kernel space (struct msghdr *msg_sys). Take a simple look at this function:
static int copy_msghdr_from_user(struct msghdr *kmsg,
struct user_msghdr __user *umsg,
struct sockaddr __user **save_addr,
struct iovec **iov)
{
struct sockaddr __user *uaddr;
struct iovec __user *uiov;
size_t nr_segs;
ssize_t err;
if (!access_ok(VERIFY_READ, umsg, sizeof(*umsg)) ||
__get_user(uaddr, &umsg->msg_name) ||
__get_user(kmsg->msg_namelen, &umsg->msg_namelen) ||
__get_user(uiov, &umsg->msg_iov) ||
__get_user(nr_segs, &umsg->msg_iovlen) ||
__get_user(kmsg->msg_control, &umsg->msg_control) ||
__get_user(kmsg->msg_controllen, &umsg->msg_controllen) ||
__get_user(kmsg->msg_flags, &umsg->msg_flags))
return -EFAULT;
if (!uaddr)
kmsg->msg_namelen = 0;
if (kmsg->msg_namelen < 0)
return -EINVAL;
if (kmsg->msg_namelen > sizeof(struct sockaddr_storage))
kmsg->msg_namelen = sizeof(struct sockaddr_storage);
if (save_addr)
*save_addr = uaddr;
if (uaddr && kmsg->msg_namelen) {
if (!save_addr) {
err = move_addr_to_kernel(uaddr, kmsg->msg_namelen,
kmsg->msg_name);
if (err < 0)
return err;
}
} else {
kmsg->msg_name = NULL;
kmsg->msg_namelen = 0;
}
if (nr_segs > UIO_MAXIOV)
return -EMSGSIZE;
kmsg->msg_iocb = NULL;
return import_iovec(save_addr ? READ : WRITE, uiov, nr_segs,
UIO_FASTIOV, iov, &kmsg->msg_iter);
}The function first calls access_ok checks the validity of user data and then calls it. get_ The user function performs the copy operation of the single data (the contents of the data package are not copied), and then makes some simple input parameter judgments. Then, if the destination address exists in the user message and enter the parameter save_ If addr is empty (this is exactly the case in the current scenario), call move_ addr_ to_ The kernel () function copies the message address into the structure of the kernel kmsg, otherwise the destination address and length fields in the kmsg are set to null. Next, judge the number of iovec structures actually loaded by the message, here is UIO_ The Maximov value is defined as 1024, which means that the maximum number of message data iovec structures cannot exceed this value. This is very important.
Finally, call import_. Iovec() function starts to copy the actual data from the user state to the inner core state (note that the actual message load data in the user space is not copied here, but the validity of the user address is checked and the length and other fields are copied). After the copy is completed, & kmsg - > MSG_ The initialization of data in ITER is as follows:
int type: WRITE;
size_t iov_offset: initialized to 0;
size_t count: the total length of all iovec structure data (i.e. the sum of IOV - > iov_len);
Construct iovec * iov: pointer to the first iov structure;
unsigned long nr_segs: the number of iovec structures.
After the data copy is completed, go back to___ sys_ Continue analysis in sendmsg function:
err = -ENOBUFS;
if (msg_sys->msg_controllen > INT_MAX)
goto out_freeiov;
ctl_len = msg_sys->msg_controllen;
if ((MSG_CMSG_COMPAT & flags) && ctl_len) {
err =
cmsghdr_from_user_compat_to_kern(msg_sys, sock->sk, ctl,
sizeof(ctl));
if (err)
goto out_freeiov;
ctl_buf = msg_sys->msg_control;
ctl_len = msg_sys->msg_controllen;
} else if (ctl_len) {
if (ctl_len > sizeof(ctl)) {
ctl_buf = sock_kmalloc(sock->sk, ctl_len, GFP_KERNEL);
if (ctl_buf == NULL)
goto out_freeiov;
}
err = -EFAULT;
/*
* Careful! Before this, msg_sys->msg_control contains a user pointer.
* Afterwards, it will be a kernel pointer. Thus the compiler-assisted
* checking falls down on this.
*/
if (copy_from_user(ctl_buf,
(void __user __force *)msg_sys->msg_control,
ctl_len))
goto out_freectl;
msg_sys->msg_control = ctl_buf;
}This section of the program is used to copy the auxiliary data of the message, which is more intuitive. The example program in our previous article does not transmit the auxiliary data, so we will not analyze it in detail here, and continue to look at it:
msg_sys->msg_flags = flags;
if (sock->file->f_flags & O_NONBLOCK)
msg_sys->msg_flags |= MSG_DONTWAIT;
/*
* If this is sendmmsg() and current destination address is same as
* previously succeeded address, omit asking LSM's decision.
* used_address->name_len is initialized to UINT_MAX so that the first
* destination address never matches.
*/
if (used_address && msg_sys->msg_name &&
used_address->name_len == msg_sys->msg_namelen &&
!memcmp(&used_address->name, msg_sys->msg_name,
used_address->name_len)) {
err = sock_sendmsg_nosec(sock, msg_sys);
goto out_freectl;
}
err = sock_sendmsg(sock, msg_sys);
/*
* If this is sendmmsg() and sending to current destination address was
* successful, remember it.
*/
if (used_address && err >= 0) {
used_address->name_len = msg_sys->msg_namelen;
if (msg_sys->msg_name)
memcpy(&used_address->name, msg_sys->msg_name,
used_address->name_len);
}Here, first save the flag ID passed by the user, and then judge that if the current socket has been configured as non blocking mode, set MSG_ Donwait ID (defined in include/linux/socket.h). Next, through the passed in used_ The address pointer determines whether the destination address of the currently sent message is consistent with its record. If so, call sock_ sendmsg_ The nosec() function sends data, otherwise the sock is called_ Sendmsg() function sends data, sock_sendmsg() actually ends up by calling sock_sendmsg_nosec() to send data. The difference between them is whether to call the security check function, as follows:
int sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
EXPORT_SYMBOL(sock_sendmsg);When sendmsg system calls to send multiple messages every time, because the sending destinations are generally the same, it is only necessary to check when sending the first message burst. This strategy can speed up the sending of data. Finally, after sending the data, if the incoming used_ If the address pointer is not empty, the destination address of the data successfully sent this time will be recorded for comparison of the data sent next time. Next, enter the sock_sendmsg_nosec(sock, msg_sys) continues to analyze the message sending process internally:
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
return ret;
}Here, the special data sending hook function of the protocol bound to the socket is called, and the last parameter is MSG - > MSG_ ITER - > count, that is, the total length of the actual load of the message. As you saw in the previous article, for sockets of netlink type, this function is registered as netlink_sendmsg(), let's analyze this function. This function is long and segmented:
static int netlink_sendmsg(struct socket *sock, struct msghdr *msg, size_t len)
{
struct sock *sk = sock->sk;
struct netlink_sock *nlk = nlk_sk(sk);
DECLARE_SOCKADDR(struct sockaddr_nl *, addr, msg->msg_name);
u32 dst_portid;
u32 dst_group;
struct sk_buff *skb;
int err;
struct scm_cookie scm;
u32 netlink_skb_flags = 0;
if (msg->msg_flags&MSG_OOB)
return -EOPNOTSUPP;
err = scm_send(sock, msg, &scm, true);
if (err < 0)
return err;First, a struct SOCKADDR is defined here_ NL * addr pointer, which points to MSG - > MSG_ Name indicates the destination address of the message (address length check will be performed); Then call scm_. Send() sends message auxiliary data (not analyzed).
if (msg->msg_namelen) {
err = -EINVAL;
if (addr->nl_family != AF_NETLINK)
goto out;
dst_portid = addr->nl_pid;
dst_group = ffs(addr->nl_groups);
err = -EPERM;
if ((dst_group || dst_portid) &&
!netlink_allowed(sock, NL_CFG_F_NONROOT_SEND))
goto out;
netlink_skb_flags |= NETLINK_SKB_DST;
} else {
dst_portid = nlk->dst_portid;
dst_group = nlk->dst_group;
}Here, if the user specifies the destination address of the netlink message, check it, and then judge the NL of the current netlink protocol_ CFG_ F_ NONROOT_ Whether the send ID is set. If the change ID is set, non root users are allowed to send multicast. For netlink_ The netlink socket of route type is not set with this ID, indicating that non root users cannot send multicast messages; Then set up NETLINK_SKB_DST identification. If the user does not specify the destination address of the netlink message, the default value of the netlink socket is used (the default value is 0, which will be assigned to the value set by the user in netlink_connect() when calling the connect system call). Notice here, DST_ After being processed by ffs, the group is converted into the number of multicast address bits (find the least significant bit).
if (!nlk->bound) {
err = netlink_autobind(sock);
if (err)
goto out;
} else {
/* Ensure nlk is hashed and visible. */
smp_rmb();
}Next, judge whether the current netlink socket has been bound. If not, call netlink here_ Autobind() performs dynamic binding. This function has been analyzed in the previous article. Continue to analyze it
/* It's a really convoluted way for userland to ask for mmaped
* sendmsg(), but that's what we've got...
*/
if (netlink_tx_is_mmaped(sk) &&
msg->msg_iter.type == ITER_IOVEC &&
msg->msg_iter.nr_segs == 1 &&
msg->msg_iter.iov->iov_base == NULL) {
err = netlink_mmap_sendmsg(sk, msg, dst_portid, dst_group,
&scm);
goto out;
}If the kernel is configured with config_ NETLINK_ The MMAP kernel option indicates that the message sending queue of kernel space and application layer supports memory mapping, and then call netlink_mmap_sendmsg to send netlink messages. This method will reduce the memory of data, the copy action of data, and the sending time and resource occupation. It is not supported in my environment now. Continue to analyze:
err = -EMSGSIZE; if (len > sk->sk_sndbuf - 32) goto out; err = -ENOBUFS; skb = netlink_alloc_large_skb(len, dst_group); if (skb == NULL) goto out;
Next, judge whether the data to be sent is too long (longer than the sending cache size), and then use netlink_alloc_large_skb allocates skb structure (the incoming parameters are the length of message load and multicast address).
NETLINK_CB(skb).portid = nlk->portid;
NETLINK_CB(skb).dst_group = dst_group;
NETLINK_CB(skb).creds = scm.creds;
NETLINK_CB(skb).flags = netlink_skb_flags;
err = -EFAULT;
if (memcpy_from_msg(skb_put(skb, len), msg, len)) {
kfree_skb(skb);
goto out;
}
err = security_netlink_send(sk, skb);
if (err) {
kfree_skb(skb);
goto out;
}
if (dst_group) {
atomic_inc(&skb->users);
netlink_broadcast(sk, skb, dst_portid, dst_group, GFP_KERNEL);
}
err = netlink_unicast(sk, skb, dst_portid, msg->msg_flags&MSG_DONTWAIT);After the SKB structure is successfully created, it is initialized here. The extended cb field in SKB (char cb [48] _aligned (8), a total of 48 bytes, is used to store the address and identification of netlink, and the relevant additional information is enough). At the same time, the macro netlink is used_ cb to manipulate these fields. Netlink forces the cb field of SKB to be defined as struct netlink_skb_parms structure:
struct netlink_skb_parms {
struct scm_creds creds; /* Skb credentials */
__u32 portid;
__u32 dst_group;
__u32 flags;
struct sock *sk;
};Where portid represents the id bound to the original socket, dst_group indicates the multicast address of the message destination, flag is the identification, and sk points to the sock structure of the original socket.
Here, first assign the portid of socket binding to the cb field of SKB, and set the number of multicast addresses and netlink at the same time_ SKB identification (here is the NETLINK_SKB_DST that has been set). Next, call the most critical call memcpy_from_msg copies the data. It first calls skb_put adjust the SKB - > tail pointer, and then execute copy_ from_ ITER (data, len, & MSG - > msg_iter) transfers data from MSG - > MSG_ ITER to SKB - > data (this is the first memory copy action! Copy user space data directly to kernel SKB).
Next, call security_netlink_send() performs security check. Finally, if it is multicast sending, it calls netlink_broadcast() sends a message, otherwise netlink is called_ Unicast() sends unicast messages. We first follow the current scenario to analyze the unicast sending function netlink_unicast():
int netlink_unicast(struct sock *ssk, struct sk_buff *skb,
u32 portid, int nonblock)
{
struct sock *sk;
int err;
long timeo;
skb = netlink_trim(skb, gfp_any());
timeo = sock_sndtimeo(ssk, nonblock);
retry:
sk = netlink_getsockbyportid(ssk, portid);
if (IS_ERR(sk)) {
kfree_skb(skb);
return PTR_ERR(sk);
}
if (netlink_is_kernel(sk))
return netlink_unicast_kernel(sk, skb, ssk);
if (sk_filter(sk, skb)) {
err = skb->len;
kfree_skb(skb);
sock_put(sk);
return err;
}
err = netlink_attachskb(sk, skb, &timeo, ssk);
if (err == 1)
goto retry;
if (err)
return err;
return netlink_sendskb(sk, skb);
}Here, first call netlink_trim() re cuts the size of the data area of skb, which may clone a new skb structure and reallocate the memory space of skb - > data (this is the third memory copy action!), Of course, if the redundant memory data area in the original skb is very small or the memory space is in the vmalloc space, the above operation will not be performed. The latter case is in the context of the scenario we are following now, and the space will not be reallocated.
Next, write down the sending timeout waiting time, if MSG has been set_ Donwait ID, the waiting time is 0, otherwise SK - > SK is returned_ Sndtimeo (this value is assigned to Max by the sock_init_data() function during sock initialization)_ SCHEDULE_ TIMEOUT).
Next, find the sock structure of the destination according to the destination portid number and the original sock structure:
static struct sock *netlink_getsockbyportid(struct sock *ssk, u32 portid)
{
struct sock *sock;
struct netlink_sock *nlk;
sock = netlink_lookup(sock_net(ssk), ssk->sk_protocol, portid);
if (!sock)
return ERR_PTR(-ECONNREFUSED);
/* Don't bother queuing skb if kernel socket has no input function */
nlk = nlk_sk(sock);
if (sock->sk_state == NETLINK_CONNECTED &&
nlk->dst_portid != nlk_sk(ssk)->portid) {
sock_put(sock);
return ERR_PTR(-ECONNREFUSED);
}
return sock;
}Here, first call netlink_lookup performs the search. The namespace and protocol number searched are the same as the original sock, and it will start from NL_ Find the registered destination sock socket in the hash table of table [protocol]. After finding the socket, perform verification. If the socket found has been connect ed, its destination portid must be the portid of the original end.
Next, judge whether the target netlink socket is the kernel netlink socket:
static inline int netlink_is_kernel(struct sock *sk)
{
return nlk_sk(sk)->flags & NETLINK_KERNEL_SOCKET;
}If the destination address is kernel space, netlink is called_ unicast_ The kernel unicast to the kernel, and the input parameters are the target sock, the original sock and the data skb. Otherwise, continue to execute downward. In the current scenario, we follow the data sent in the user space and enter netlink_ unicast_ In kernel():
static int netlink_unicast_kernel(struct sock *sk, struct sk_buff *skb,
struct sock *ssk)
{
int ret;
struct netlink_sock *nlk = nlk_sk(sk);
ret = -ECONNREFUSED;
if (nlk->netlink_rcv != NULL) {
ret = skb->len;
netlink_skb_set_owner_r(skb, sk);
NETLINK_CB(skb).sk = ssk;
netlink_deliver_tap_kernel(sk, ssk, skb);
nlk->netlink_rcv(skb);
consume_skb(skb);
} else {
kfree_skb(skb);
}
sock_put(sk);
return ret;
}Check whether the target netlink socket is registered with netlink_rcv() receiving function. If not, the packet will be discarded directly. Otherwise, the sending process will continue. Here, first set some identifiers:
skb->sk = sk; / * assign the target sock to the SKB - > SK pointer*/
skb->destructor = netlink_ skb_ destructor; / * register destructor hook function*/
NETLINK_CB(skb).sk = ssk; / * save the original sock in the cb extension field of the early SKB*/
Finally, NLK - > netlink is called_ The RCV (SKB) function sends the message to the destination netlink socket in the kernel. In the previous article, we saw that when the kernel registers the netlink socket, its receiving function has been registered to netlink_ In RCV:
struct sock *
__netlink_kernel_create(struct net *net, int unit, struct module *module,
struct netlink_kernel_cfg *cfg)
{
......
if (cfg && cfg->input)
nlk_sk(sk)->netlink_rcv = cfg->input;For netlink_ For a socket of type route, it is rtnetlink_rcv, netlink_ The RCV () hook function will receive and parse the data passed down by the user. Different types of netlink protocols are different, so we won't analyze them here. At this point, the application layer sends the unicast netlink data.
Now let's go back to netlink_ In sendmsg() function, briefly analyze the process of sending multicast data:
static int netlink_sendmsg(struct socket *sock, struct msghdr *msg, size_t len)
{
......
if (dst_group) {
atomic_inc(&skb->users);
netlink_broadcast(sk, skb, dst_portid, dst_group, GFP_KERNEL);
}
int netlink_broadcast(struct sock *ssk, struct sk_buff *skb, u32 portid,
u32 group, gfp_t allocation)
{
return netlink_broadcast_filtered(ssk, skb, portid, group, allocation,
NULL, NULL);
}
EXPORT_SYMBOL(netlink_broadcast);
int netlink_broadcast_filtered(struct sock *ssk, struct sk_buff *skb, u32 portid,
u32 group, gfp_t allocation,
int (*filter)(struct sock *dsk, struct sk_buff *skb, void *data),
void *filter_data)
{
struct net *net = sock_net(ssk);
struct netlink_broadcast_data info;
struct sock *sk;
skb = netlink_trim(skb, allocation);
info.exclude_sk = ssk;
info.net = net;
info.portid = portid;
info.group = group;
info.failure = 0;
info.delivery_failure = 0;
info.congested = 0;
info.delivered = 0;
info.allocation = allocation;
info.skb = skb;
info.skb2 = NULL;
info.tx_filter = filter;
info.tx_data = filter_data;
/* While we sleep in clone, do not allow to change socket list */
netlink_lock_table();
sk_for_each_bound(sk, &nl_table[ssk->sk_protocol].mc_list)
do_one_broadcast(sk, &info);
......
}Here, first initialize the netlink multicast data structure netlink_broadcast_data, where info The destination multicast address is saved in group, and then from NL_ table[ssk->sk_protocol]. mc_ Find the socket to join the multicast group in the list and call do_one_broadcast() function sends multicast data in sequence:
static void do_one_broadcast(struct sock *sk,
struct netlink_broadcast_data *p)
{
struct netlink_sock *nlk = nlk_sk(sk);
int val;
if (p->exclude_sk == sk)
return;
if (nlk->portid == p->portid || p->group - 1 >= nlk->ngroups ||
!test_bit(p->group - 1, nlk->groups))
return;
if (!net_eq(sock_net(sk), p->net))
return;
if (p->failure) {
netlink_overrun(sk);
return;
}
......
} else if ((val = netlink_broadcast_deliver(sk, p->skb2)) < 0) {
netlink_overrun(sk);
if (nlk->flags & NETLINK_BROADCAST_SEND_ERROR)
p->delivery_failure = 1;
......
}Of course, some necessary checks will be made before sending. For example, it will ensure that the original sock and the destination sock are not the same, they belong to the same network namespace, and the multicast address of the destination is the multicast address of the sending destination. Then, netlink will be constructed for skb and multicast data_ broadcast_ Data does some processing, and finally calls netlink_. broadcast_ The deliver() function sends data skb to the destination sock:
static int netlink_broadcast_deliver(struct sock *sk, struct sk_buff *skb)
{
......
__netlink_sendskb(sk, skb);
......
}
static int __netlink_sendskb(struct sock *sk, struct sk_buff *skb)
{
int len = skb->len;
......
skb_queue_tail(&sk->sk_receive_queue, skb);
sk->sk_data_ready(sk);
return len;
}As you can see, the skb to be sent here is added to the end of the receiving queue at destination sock, and then called sk_. data_ Ready() notifies the hook function that the destination sock has data and executes the processing flow. For kernel netlink, it has been registered as
struct sock *
__netlink_kernel_create(struct net *net, int unit, struct module *module,
struct netlink_kernel_cfg *cfg)
{
......
sk->sk_data_ready = netlink_data_ready;
......
}
static void netlink_data_ready(struct sock *sk)
{
BUG();
}Obviously, the kernel netlink socket should not receive multicast messages anyway. However, for application layer netlink sockets, the sk_ data_ The ready() hook function is initializing the netlink function sock_ init_ It is registered as a sock in data()_ def_ Readable(), which will be analyzed later. So far, the netlink data flow analysis issued by the application layer is over.
3. The kernel sends netlink message to the application layer
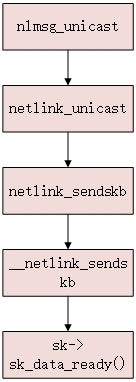
Figure 2 kernel sending netlink unicast message
The kernel can use nlmsg_unicast() function sends unicast message to the application layer, which is called by each netlink protocol. Some protocols call netlink directly_ Unicast() function, actually nlmsg_unicast() is only netlink_unicast() is just an encapsulation:
/**
* nlmsg_unicast - unicast a netlink message
* @sk: netlink socket to spread message to
* @skb: netlink message as socket buffer
* @portid: netlink portid of the destination socket
*/
static inline int nlmsg_unicast(struct sock *sk, struct sk_buff *skb, u32 portid)
{
int err;
err = netlink_unicast(sk, skb, portid, MSG_DONTWAIT);
if (err > 0)
err = 0;
return err;
}Here, the message is sent to the application layer in the form of non blocking (MSG_DONTWAIT). At this time, the portid is the id number bound by the application layer socket. We re-enter netlink_ Inside unicast (), this time, because the target sock is no longer the kernel, we have to take different branches
int netlink_unicast(struct sock *ssk, struct sk_buff *skb,
u32 portid, int nonblock)
{
struct sock *sk;
int err;
long timeo;
skb = netlink_trim(skb, gfp_any());
timeo = sock_sndtimeo(ssk, nonblock);
retry:
sk = netlink_getsockbyportid(ssk, portid);
if (IS_ERR(sk)) {
kfree_skb(skb);
return PTR_ERR(sk);
}
if (netlink_is_kernel(sk))
return netlink_unicast_kernel(sk, skb, ssk);
if (sk_filter(sk, skb)) {
err = skb->len;
kfree_skb(skb);
sock_put(sk);
return err;
}
err = netlink_attachskb(sk, skb, &timeo, ssk);
if (err == 1)
goto retry;
if (err)
return err;
return netlink_sendskb(sk, skb);
}
EXPORT_SYMBOL(netlink_unicast);Here first sk_filter performs firewall filtering to ensure that netlink_ can be sent later. Attachskb binds the skb to be sent to the netlink sock.
int netlink_attachskb(struct sock *sk, struct sk_buff *skb,
long *timeo, struct sock *ssk)
{
struct netlink_sock *nlk;
nlk = nlk_sk(sk);
if ((atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf ||
test_bit(NETLINK_CONGESTED, &nlk->state)) &&
!netlink_skb_is_mmaped(skb)) {
DECLARE_WAITQUEUE(wait, current);
if (!*timeo) {
if (!ssk || netlink_is_kernel(ssk))
netlink_overrun(sk);
sock_put(sk);
kfree_skb(skb);
return -EAGAIN;
}
__set_current_state(TASK_INTERRUPTIBLE);
add_wait_queue(&nlk->wait, &wait);
if ((atomic_read(&sk->sk_rmem_alloc) > sk->sk_rcvbuf ||
test_bit(NETLINK_CONGESTED, &nlk->state)) &&
!sock_flag(sk, SOCK_DEAD))
*timeo = schedule_timeout(*timeo);
__set_current_state(TASK_RUNNING);
remove_wait_queue(&nlk->wait, &wait);
sock_put(sk);
if (signal_pending(current)) {
kfree_skb(skb);
return sock_intr_errno(*timeo);
}
return 1;
}
netlink_skb_set_owner_r(skb, sk);
return 0;
}If the remaining cache size of the receiving buffer of the destination sock is less than the amount of data that has been submitted, or the flag bit has set the blocking ID NETLINK_CONGESTED, which indicates that the data cannot be immediately sent to the receiving cache of the destination. Therefore, when the original end is not a kernel socket and the non blocking ID is not set, a waiting queue will be defined and wait for the specified time and return 1. Otherwise, the skb packet will be directly discarded and return failure.
If the receiving buffer space of the destination is enough, netlink will be called_ skb_ set_ owner_ R to bind.
Back to netlink_ In the unicast () function, you can see that if netlink is executed_ If the return value of attachskb() is 1, the send operation will be tried again. Finally, call netlink_. Sendskb() performs a send operation:
int netlink_sendskb(struct sock *sk, struct sk_buff *skb)
{
int len = __netlink_sendskb(sk, skb);
sock_put(sk);
return len;
}
It's back here again__ netlink_sendskb function executes the sending process:
static int __netlink_sendskb(struct sock *sk, struct sk_buff *skb)
{
int len = skb->len;
netlink_deliver_tap(skb);
#ifdef CONFIG_NETLINK_MMAP
if (netlink_skb_is_mmaped(skb))
netlink_queue_mmaped_skb(sk, skb);
else if (netlink_rx_is_mmaped(sk))
netlink_ring_set_copied(sk, skb);
else
#endif /* CONFIG_NETLINK_MMAP */
skb_queue_tail(&sk->sk_receive_queue, skb);
sk->sk_data_ready(sk);
return len;
}Sk here_ data_ The ready() hook function is initializing the netlink function sock_ init_ It is registered as a sock in data()_ def_ Readable (), enter the analysis:
static void sock_def_readable(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (wq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
Here, wake up the waiting queue of the socket at the destination receiver, so that the application layer socket can receive and process messages.
After analyzing the unicast message sent by the kernel, let's take a look at the process of sending multicast message by the kernel. The process is very simple. Its entry is nlmsg_multicast():
static inline int nlmsg_multicast(struct sock *sk, struct sk_buff *skb,
u32 portid, unsigned int group, gfp_t flags)
{
int err;
NETLINK_CB(skb).dst_group = group;
err = netlink_broadcast(sk, skb, portid, group, flags);
if (err > 0)
err = 0;
return err;
}nlmsg_multicast and subsequent processes have been analyzed in the previous article and will not be repeated here. So far, the kernel has finished sending the netlink message. Let's take a look at how the application layer receives the message.
4. The application layer receives the kernel netlink message
Using the following example program, you can receive the netlink message sent by the kernel in a blocking manner:
#define TEST_DATA_LEN 16 struct sockaddr_nl nladdr; struct msghdr msg; struct nlmsghdr *nlhdr; struct iovec iov; /* Clear source address structure */ memset(&nladdr, 0, sizeof(nladdr)); /* Clear netlink header */ nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(TEST_DATA_LEN)); memset(nlhdr, 0, NLMSG_SPACE(TEST_DATA_LEN)); /* Encapsulate netlink messages */ iov.iov_base = (void *)nlhdr; /* Receive cache address */ iov.iov_len = NLMSG_LENGTH(TEST_DATA_LEN);; /* Receive cache size */ /* Populate data message structure */ memset(&msg, 0, sizeof(msg)); msg.msg_name = (void *)&(nladdr); msg.msg_namelen = sizeof(nladdr); /* The address length is assigned by the kernel */ msg.msg_iov = &iov; msg.msg_iovlen = 1; /* Receive netlink message */ recvmsg(sock_fd, &msg, 0);
The sequence of this routine is similar to the sending program in the previous article. The receiving end needs to be assembled to receive msg messages. The difference from the sending process is:
(1)msg. msg_ The name address structure stores the address information of the message source, which is filled by the kernel.
(2)iov.iov_base is the address space of receiving cache, which needs to be cleared before receiving.
(3)iov.iov_len is the length of a single IOV receive cache, which needs to be specified.
(4)msg.msg_namelen: the length occupied by the address, which is filled by the kernel.
(5)msg.msg_iovlen: the number of received iov space, which needs to be specified.
The recvmsg system call is used here. Now we enter the whole receiving process of the system call analysis message (note that there is a memory copy of data in the whole receiving process without using NETLINK_MMAP technology!):
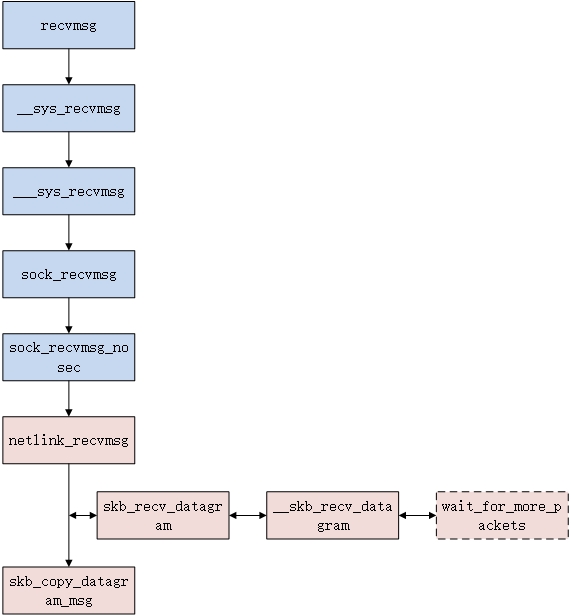
Figure 3 user state netlink receiving process
SYSCALL_DEFINE3(recvmsg, int, fd, struct user_msghdr __user *, msg,
unsigned int, flags)
{
if (flags & MSG_CMSG_COMPAT)
return -EINVAL;
return __sys_recvmsg(fd, msg, flags);
}
long __sys_recvmsg(int fd, struct user_msghdr __user *msg, unsigned flags)
{
int fput_needed, err;
struct msghdr msg_sys;
struct socket *sock;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = ___sys_recvmsg(sock, msg, &msg_sys, flags, 0);
fput_light(sock->file, fput_needed);
out:
return err;
}Similar to sendmsg system calls, here is also the first way to find the corresponding socket socket structure through the fd descriptor, and then invoke it. sys_recvmsg() performs the actual work. This function is relatively long. Segment analysis:
static int ___sys_recvmsg(struct socket *sock, struct user_msghdr __user *msg,
struct msghdr *msg_sys, unsigned int flags, int nosec)
{
struct compat_msghdr __user *msg_compat =
(struct compat_msghdr __user *)msg;
struct iovec iovstack[UIO_FASTIOV];
struct iovec *iov = iovstack;
unsigned long cmsg_ptr;
int total_len, len;
ssize_t err;
/* kernel mode address */
struct sockaddr_storage addr;
/* user mode address pointers */
struct sockaddr __user *uaddr;
int __user *uaddr_len = COMPAT_NAMELEN(msg);
msg_sys->msg_name = &addr;Similar to sendmsg, an iovstack array cache with a size of 8 is also defined here to speed up message processing; Then obtain the address of the address length field of the user space.
if (MSG_CMSG_COMPAT & flags) err = get_compat_msghdr(msg_sys, msg_compat, &uaddr, &iov); else err = copy_msghdr_from_user(msg_sys, msg, &uaddr, &iov); if (err < 0) return err; total_len = iov_iter_count(&msg_sys->msg_iter); cmsg_ptr = (unsigned long)msg_sys->msg_control; msg_sys->msg_flags = flags & (MSG_CMSG_CLOEXEC|MSG_CMSG_COMPAT);
Here, copy is called_ msghdr_ from_ User copies the data in user mode msg to kernel mode msg_sys. Of course, this is mainly to receive messages from the kernel. There is no actual data in the user space. The main function here is to determine how much data the user needs to receive. Note that the third parameter is no longer NULL, but points to the address of the uaddr pointer. Enter the function again for detailed analysis:
static int copy_msghdr_from_user(struct msghdr *kmsg,
struct user_msghdr __user *umsg,
struct sockaddr __user **save_addr,
struct iovec **iov)
{
struct sockaddr __user *uaddr;
struct iovec __user *uiov;
size_t nr_segs;
ssize_t err;
if (!access_ok(VERIFY_READ, umsg, sizeof(*umsg)) ||
<span style="color:#ff0000;"> __get_user(uaddr, &umsg->msg_name) ||</span>
__get_user(kmsg->msg_namelen, &umsg->msg_namelen) ||
__get_user(uiov, &umsg->msg_iov) ||
__get_user(nr_segs, &umsg->msg_iovlen) ||
__get_user(kmsg->msg_control, &umsg->msg_control) ||
__get_user(kmsg->msg_controllen, &umsg->msg_controllen) ||
__get_user(kmsg->msg_flags, &umsg->msg_flags))
return -EFAULT;
if (!uaddr)
kmsg->msg_namelen = 0;
if (kmsg->msg_namelen < 0)
return -EINVAL;
if (kmsg->msg_namelen > sizeof(struct sockaddr_storage))
kmsg->msg_namelen = sizeof(struct sockaddr_storage);
<span style="color:#ff0000;"> if (save_addr)
*save_addr = uaddr;</span>
if (uaddr && kmsg->msg_namelen) {
<span style="color:#ff0000;"> if (!save_addr) {
err = move_addr_to_kernel(uaddr, kmsg->msg_namelen,
kmsg->msg_name);</span>
if (err < 0)
return err;
}
} else {
kmsg->msg_name = NULL;
kmsg->msg_namelen = 0;
}
if (nr_segs > UIO_MAXIOV)
return -EMSGSIZE;
kmsg->msg_iocb = NULL;
return import_iovec(<span style="color:#ff0000;">save_addr ? READ : WRITE</span>, uiov, nr_segs,
UIO_FASTIOV, iov, &kmsg->msg_iter);
}Notice the red lines, in which the incoming uaddr pointer is pointed to the user space MSG - > MSG_ Name address, and then the kernel will no longer call move_ addr_ to_ The kernel copies the message address field in the user space to the kernel space (because it is not necessary at all), and then calls import in the way of READ_ Iovec() function, which will check whether the message data address in the user space can be written, and then according to the MSG received by the user_ Iovlen length package kmsg - > MSG_ ITER structure. Back to___ sys_ The recvmsg() function saves the total length of the receive cache to total_len, and then set the flag ID.
/* We assume all kernel code knows the size of sockaddr_storage */ msg_sys->msg_namelen = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = (nosec ? sock_recvmsg_nosec : sock_recvmsg)(sock, msg_sys, total_len, flags);
The length field of the address is cleared and no user space is introduced here. (suppose the kernel knows the length of the address), then the sock_ is called according to whether the value of nosec is 0. recvmsg_ Nosec() or sock_ The recvmsg() function receives data. The number of messages passed in by nosec in the recvmsg system call is 0. When the recvmmsg system can call to receive multiple messages, the number of accepted messages is passed in.
Like the sendmsg() and sendmsg() system calls sent, this design is also designed to speed up message reception. recvmmsg() is a sock_ recvmsg_ It's just a package of nosec(), but it will add security check:
int sock_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
int err = security_socket_recvmsg(sock, msg, size, flags);
return err ?: sock_recvmsg_nosec(sock, msg, size, flags);
}
EXPORT_SYMBOL(sock_recvmsg);
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
return sock->ops->recvmsg(sock, msg, size, flags);
}Here, the recvmsg receive hook function of the protocol where the socket is received is called. For netlink, it is netlink_recvmsg() function:
static int netlink_recvmsg(struct socket *sock, struct msghdr *msg, size_t len,
int flags)
{
struct scm_cookie scm;
struct sock *sk = sock->sk;
struct netlink_sock *nlk = nlk_sk(sk);
int noblock = flags&MSG_DONTWAIT;
size_t copied;
struct sk_buff *skb, *data_skb;
int err, ret;
if (flags&MSG_OOB)
return -EOPNOTSUPP;
copied = 0;
skb = skb_recv_datagram(sk, flags, noblock, &err);
if (skb == NULL)
goto out;
data_skb = skb;Here we call skb first_ recv_ Datagram () receives messages from the cache of the receiving socket and returns them through skb. If MSG is set_ Donwait returns immediately when there is no message in the receiving queue, otherwise it will block the waiting. Enter the function for detailed analysis:
struct sk_buff *skb_recv_datagram(struct sock *sk, unsigned int flags,
int noblock, int *err)
{
int peeked, off = 0;
return __skb_recv_datagram(sk, flags | (noblock ? MSG_DONTWAIT : 0),
&peeked, &off, err);
}
EXPORT_SYMBOL(skb_recv_datagram);
struct sk_buff *__skb_recv_datagram(struct sock *sk, unsigned int flags,
int *peeked, int *off, int *err)
{
struct sk_buff_head *queue = &sk->sk_receive_queue;
struct sk_buff *skb, *last;
unsigned long cpu_flags;
long timeo;
/*
* Caller is allowed not to check sk->sk_err before skb_recv_datagram()
*/
int error = sock_error(sk);
if (error)
goto no_packet;
timeo = sock_rcvtimeo(sk, flags & MSG_DONTWAIT);
do {
/* Again only user level code calls this function, so nothing
* interrupt level will suddenly eat the receive_queue.
*
* Look at current nfs client by the way...
* However, this function was correct in any case. 8)
*/
int _off = *off;
last = (struct sk_buff *)queue;
spin_lock_irqsave(&queue->lock, cpu_flags);
skb_queue_walk(queue, skb) {
last = skb;
*peeked = skb->peeked;
if (flags & MSG_PEEK) {
if (_off >= skb->len && (skb->len || _off ||
skb->peeked)) {
_off -= skb->len;
continue;
}
skb = skb_set_peeked(skb);
error = PTR_ERR(skb);
if (IS_ERR(skb))
goto unlock_err;
atomic_inc(&skb->users);
} else
__skb_unlink(skb, queue);
spin_unlock_irqrestore(&queue->lock, cpu_flags);
*off = _off;
return skb;
}
spin_unlock_irqrestore(&queue->lock, cpu_flags);
if (sk_can_busy_loop(sk) &&
sk_busy_loop(sk, flags & MSG_DONTWAIT))
continue;
/* User doesn't want to wait */
error = -EAGAIN;
if (!timeo)
goto no_packet;
} while (!wait_for_more_packets(sk, err, &timeo, last));
return NULL;
unlock_err:
spin_unlock_irqrestore(&queue->lock, cpu_flags);
no_packet:
*err = error;
return NULL;
}First, get the receive queue pointer of the socket and save it to the queue variable, and then get the waiting time SK - > sk_ Rcvtimeo (it is set to MAX_SCHEDULE_TIMEOUT during socket initialization, which can also be modified through set_socketopt), and then enter a do while() loop to wait for data to be obtained from the receive cache.
First, assuming that there is data in the current receiving queue, lock the queue and take out a SKB packet from the queue, and then judge whether MSG is set_ Peek identifier (if it has been set, it indicates that only the SKB packet is obtained but not deleted from the receiving queue). If it is set, SKB is called_ set_ Peeked() function skb_clone sends out a SKB message package and returns it. Otherwise, call directly__ skb_unlink deletes the SKB package from the list and returns it.
Then assume that there is no message in the current receiving queue. Here, it will be determined according to whether config is set_ NET_ RX_ BUSY_ The poll kernel option performs two wait scenarios. If the change option is set, it will try to use a busy waiting scheme (similar to the device driven napi), which does not need to make the current execution stream sleep and cut out, which can speed up the data receiving speed, and it will call sk_can_busy_loop() and sk_busy_loop() determines whether the scheme can be used. If this option is not set, the traditional scheme is used and wait is called_ for_ more_ Packets() performs the wait operation. It joins the wait queue to make the process sleep:
static int wait_for_more_packets(struct sock *sk, int *err, long *timeo_p,
const struct sk_buff *skb)
{
int error;
DEFINE_WAIT_FUNC(wait, receiver_wake_function);
prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
......
/* handle signals */
if (signal_pending(current))
goto interrupted;
error = 0;
*timeo_p = schedule_timeout(*timeo_p);
out:
finish_wait(sk_sleep(sk), &wait);
return error;
interrupted:
error = sock_intr_errno(*timeo_p);
......
}This function will make some necessary judgments, but the core is the above lines of code. First, set the process to the intermittent state. If no message arrives or a signal is received, it will sleep all the time (the timeout timeo can be set, which is generally the default value. In the case of max_schedule_timeout, it will call schedule()) in the schedule_ On the timeout() function. As we have seen in the previous article, at the end of the kernel netlink sending process, after sending the data to the receiving queue, the waiting queue will be awakened, and the process will return to the receiving queue after waking up__ skb_recv_datagram receives messages in the big loop. If it is interrupted by a signal, the message cannot be obtained in the big loop, and it will return here to execute the signal exit action.
After getting an skb from the receive queue, we return to netlink_ Continue to analyze in recvmsg() function:
/* Record the max length of recvmsg() calls for future allocations */
nlk->max_recvmsg_len = max(nlk->max_recvmsg_len, len);
nlk->max_recvmsg_len = min_t(size_t, nlk->max_recvmsg_len,
16384);
copied = data_skb->len;
if (len < copied) {
msg->msg_flags |= MSG_TRUNC;
copied = len;
}
skb_reset_transport_header(data_skb);
err = skb_copy_datagram_msg(data_skb, 0, msg, copied);Here, the longest received data length is updated, and then it is judged that if the obtained skb data length is greater than the maximum length of this received cache, MSG is set_ TRUNC ID, and set the amount of data to be received this time as the length of the receive cache.
Then call skb_copy_datagram_msg() function copies the actual data in skb to msg message (here, a data copy operation is performed, and the data in skb is directly copied to the user space address pointed to by msg).
if (msg->msg_name) {
DECLARE_SOCKADDR(struct sockaddr_nl *, addr, msg->msg_name);
addr->nl_family = AF_NETLINK;
addr->nl_pad = 0;
addr->nl_pid = NETLINK_CB(skb).portid;
addr->nl_groups = netlink_group_mask(NETLINK_CB(skb).dst_group);
msg->msg_namelen = sizeof(*addr);
}This is where the AF structure will start after the copy is completed_ Netlink address family, and then set the portid number as the portid saved in the original skb extension cb field. For the skb message sent by the kernel, this field is 0, and then set the multicast address. This value is called nlmsg by the kernel in the previous text_ Multicast() is set when sending multicast messages (0 for unicast), netlink_ group_ The mask () function converts the tag number of the multicast address into the actual multicast address (mask), and then this is the address length of msg, which is NL_ Length of addr.
if (nlk->flags & NETLINK_RECV_PKTINFO)
netlink_cmsg_recv_pktinfo(msg, skb);
memset(&scm, 0, sizeof(scm));
scm.creds = *NETLINK_CREDS(skb);
if (flags & MSG_TRUNC)
copied = data_skb->len;
skb_free_datagram(sk, skb);
if (nlk->cb_running &&
atomic_read(&sk->sk_rmem_alloc) <= sk->sk_rcvbuf / 2) {
ret = netlink_dump(sk);
if (ret) {
sk->sk_err = -ret;
sk->sk_error_report(sk);
}
}
scm_recv(sock, msg, &scm, flags);
out:
netlink_rcv_wake(sk);
return err ? : copied;
}If netlink is set here_ RECV_ Pktinfo identity copies the auxiliary message header to user space. Then judge whether MSG is set_ TRUNC identifier. If it is set, reset copied to the length of the data obtained from the extracted SKB this time (special attention!). Then call skb_. free_ Datagram () releases the SKB message packet, and finally returns the received data length. Back to___ sys_ Continue to analyze in recvmsg() function:
err = (nosec ? sock_recvmsg_nosec : sock_recvmsg)(sock, msg_sys,
total_len, flags);
if (err < 0)
goto out_freeiov;
len = err;
if (uaddr != NULL) {
err = move_addr_to_user(&addr,
msg_sys->msg_namelen, uaddr,
uaddr_len);
if (err < 0)
goto out_freeiov;
}Here len saves the length of the received data, and then copies the message address information from kernel space to user space.
err = __put_user((msg_sys->msg_flags & ~MSG_CMSG_COMPAT), COMPAT_FLAGS(msg)); if (err) goto out_freeiov; if (MSG_CMSG_COMPAT & flags) err = __put_user((unsigned long)msg_sys->msg_control - cmsg_ptr, &msg_compat->msg_controllen); else err = __put_user((unsigned long)msg_sys->msg_control - cmsg_ptr, &msg->msg_controllen); if (err) goto out_freeiov; err = len; out_freeiov: kfree(iov); return err; }
Finally, the flag and message auxiliary data are copied to the user space. So far, the recvmsg system call returns upward, and the application layer can also use the obtained data. The application layer receives the netlink message and the process ends.