Because it is necessary to provide various network services to millions, tens of millions, or even billions of users, one of the key requirements for trying and promoting back-end development students in front-line Internet enterprises is to support high concurrency, understand performance overhead, and optimize performance. Many times, if you don't have a deep understanding of the underlying Linux, you will feel that the dog can't start with a hedgehog when you encounter many online performance bottlenecks.
Today, we use a graphical way to deeply understand the receiving process of network packets under Linux. Or follow the Convention to borrow the simplest piece of code and start thinking. For simplicity, we use udp as an example, as follows:
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0';
printf("Receive from client:%s\n", buff);
}
The above code is a section of udp server receiving receipt logic. From the perspective of development, as long as the client sends the corresponding data, the server executes recv_from, you can receive it and print it out. What we want to know now is what happens when the network packet reaches the network card until our recvfrom receives data?
Through this article, you will have an in-depth understanding of how the Linux network system is implemented internally and how each part interacts with each other. I believe this will be of great help to your work. This article is based on Linux 3.10. For the source code, see https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ , the network card driver adopts Intel's igb network card as an example.
Friendly tips, this article is slightly longer, you can read it after Mark!
1, Overview of Linux network packet collection
In the TCP/IP network layered model, the whole protocol stack is divided into physical layer, link layer, network layer, transport layer and application layer. The physical layer corresponds to the network card and network cable, and the application layer corresponds to our common applications such as Nginx, FTP and so on. Linux implements three layers: link layer, network layer and transport layer.
In the Linux kernel implementation, the link layer protocol is realized by the network card driver, and the kernel protocol stack is used to realize the network layer and transport layer. The kernel provides socket interface to the upper application layer for user process access. The TCP/IP network layered model we see from the perspective of Linux should look like this.
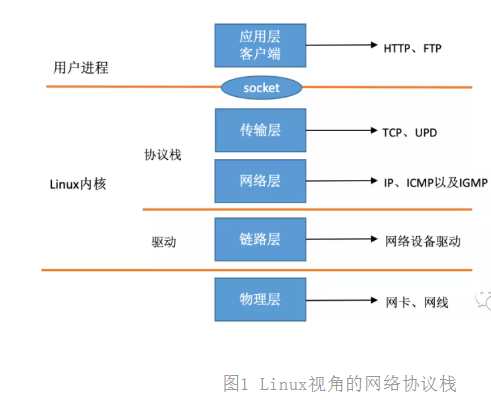
Figure 1 network protocol stack from Linux Perspective
In the source code of Linux, the logic corresponding to the network device driver is located in driver/net/ethernet, and the driver of intel series network card is in driver/net/ethernet/intel directory. The protocol stack module code is located in the kernel and net directories.
Kernel and network device drivers are handled by interrupt. When data arrives on the device, a voltage change will be triggered on the relevant pin of the CPU to inform the CPU to process the data. For the network module, due to the complex and time-consuming processing process, if all processing is completed in the interrupt function, the interrupt processing function (high priority) will occupy the CPU excessively, and the CPU will not respond to the messages of other devices, such as mouse and keyboard. Therefore, the Linux interrupt processing function is divided into the upper half and the lower half. The top half only performs the simplest work, quickly processes and releases the CPU, and then the CPU can allow other interrupts to come in. Most of the rest of the work will be put into the lower half, which can be handled slowly and calmly. The lower half of the kernel version after 2.4 is implemented by soft interrupt, which is handled by Ksoft irqd kernel thread. Unlike hard interrupts, hard interrupts notify the soft interrupt handler by applying a voltage change to the CPU physical pin, while soft interrupts notify the soft interrupt handler by giving the binary value of a variable in memory.
Well, after understanding the network card driver, hard interrupt, soft interrupt and ksoftirqd thread, we will give a path diagram of kernel packet collection based on these concepts:
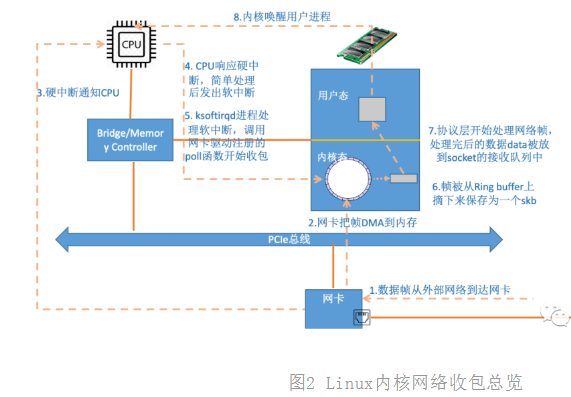
Figure 2 overview of Linux kernel network packet collection
When the data is received on the network card, the first working module in Linux is the network driver. The network driver will write the frames received on the network card to memory by DMA. An interrupt is sent to the CPU to notify the CPU that data has arrived. Second, when the CPU receives the interrupt request, it will call the interrupt processing function registered by the network driver. The interrupt processing function of the network card does not do too much work, sends a soft interrupt request, and then releases the CPU as soon as possible. Ksoft irqd detects that a soft interrupt request has arrived. It calls poll to start polling and receiving packets. After receiving it, it is handed over to the protocol stack at all levels for processing. For UDP packets, they will be placed in the receiving queue of the user socket.
From the above figure, we have grasped the packet processing process of Linux as a whole. But to learn more about the details of how the network module works, we have to look down.
2, Linux boot
Linux driver, kernel protocol stack and other modules need to do a lot of preparation before they can receive network card packets. For example, create ksoftirqd kernel threads in advance, register the processing functions corresponding to each protocol, initialize the network device subsystem in advance, and start the network card. Only when these are Ready can we really start receiving packets. Now let's see how these preparations are done.
2.1 creating ksoftirqd kernel threads
Linux soft interrupts are carried out in special kernel threads (Ksoft irqd), so it is very necessary to see how these processes are initialized, so that we can understand the packet receiving process more accurately later. The number of processes is not 1, but N, where N is equal to the number of cores of your machine.
When the system is initialized, it is in kernel / smpboot Smpboot_ is invoked in C. register_ percpu_ Thread, the function will be further executed to spawn_ksoftirqd (located in kernel/softirq.c) to create softirqd process.

Figure 3 creating ksoftirqd kernel threads
Relevant codes are as follows:
//file: kernel/softirq.c
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",};
static __init int spawn_ksoftirqd(void){
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
When Ksoft irqd is created, it enters its own thread loop function Ksoft irqd_ should_ Run and run_ksoftirqd. Constantly determine whether soft interrupts need to be processed. One thing to note here is that soft interrupts are not only network soft interrupts, but also other types.
//file: include/linux/interrupt.h
enum{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
};
2.2 network subsystem initialization
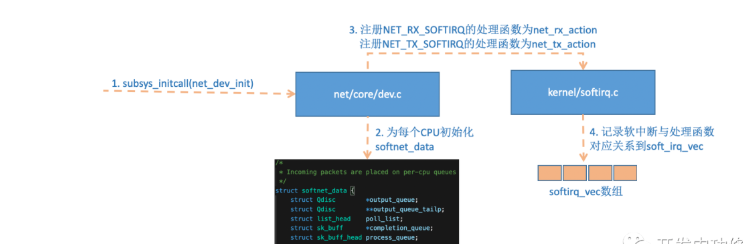
Figure 4 network subsystem initialization
The linux kernel calls subsys_initcall to initialize each subsystem. In the source code directory, you can grep make many calls to this function. What we want to say here is the initialization of the network subsystem, which will be executed to net_dev_init function.
//file: net/core/dev.c
static int __init net_dev_init(void){
......
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
memset(sd, 0, sizeof(*sd));
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
sd->completion_queue = NULL;
INIT_LIST_HEAD(&sd->poll_list);
......
}
......
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
subsys_initcall(net_dev_init);
In this function, a softnet will be applied for each CPU_ Data data structure, poll in this data structure_ List is waiting for the driver to register its poll function. We can see this process later when the network card driver initializes.
In addition, open_softirq registers a handler for each soft interrupt. NET_ TX_ The processing function of softirq is net_tx_action,NET_ RX_ The of softirq is net_rx_action. Continue tracking open_ After softirq, it is found that the registration method is recorded in softirq_ In the VEC variable. When the following ksoftirqd thread receives a soft interrupt, it will also use this variable to find the processing function corresponding to each soft interrupt.
//file: kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *)){
softirq_vec[nr].action = action;
}
2.3 protocol stack registration
The kernel implements ip protocol of network layer, TCP protocol and udp protocol of transport layer. The corresponding implementation functions of these protocols are ip_rcv(),tcp_v4_rcv() and udp_rcv(). Unlike the way we usually write code, the kernel is implemented by registration. FS in Linux kernel_ Initcall and subsys_ Similar to initcall, it is also the entry to the initialization module. fs_initcall calls INET_ Start network protocol stack registration after init. Through inet_init, which registers these functions with inet_protos and ptype_base data structure. As shown below:
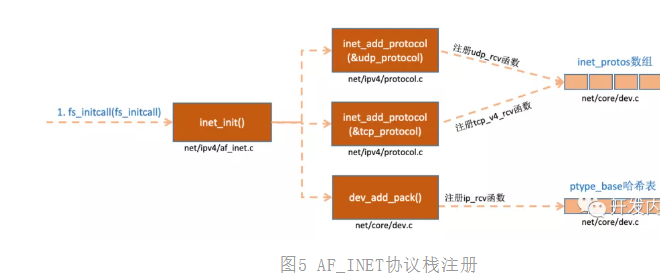
Figure 5 AF_INET protocol stack registration
The relevant codes are as follows
//file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,};static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,};static const struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
};
static int __init inet_init(void){
......
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
......
dev_add_pack(&ip_packet_type);
}
In the above code, we can see that UDP_ The handler in the protocol structure is udp_rcv,tcp_ The handler in the protocol structure is tcp_v4_rcv, through INET_ add_ The protocol is initialized.
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
inet_ add_ The protocol function registers the processing functions corresponding to tcp and udp with INET_ In the PROTOS array. Look at dev again_ add_ pack(&ip_packet_type); This line, IP_ packet_ In the type structure, type is the protocol name and func is ip_rcv function, in dev_ add_ The pack will be registered to ptype_base hash table.
//file: net/core/dev.c
void dev_add_pack(struct packet_type *pt){
struct list_head *head = ptype_head(pt);
......
}
static inline struct list_head *ptype_head(const struct packet_type *pt){
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else
return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
Here we need to remember inet_protos records the address and ptype of udp and tcp processing functions_ Base stores ip_ The processing address of the rcv() function. Later, we will see that ptype is used in soft interrupt_ Base found ip_rcv function address, and then send the ip packet to ip correctly_ Execute in RCV (). In ip_ The RCV will pass inet_protos finds the processing function of tcp or udp, and then forwards the packet to udp_rcv() or tcp_v4_rcv() function.
Expand, if you look at ip_rcv and UDP_ The code of functions such as RCV can see the processing process of many protocols. For example, ip_rcv will handle netfilter and iptable filtering. If you have many or complex netfilter or iptables rules, these rules are executed in the context of soft interrupt, which will increase the network delay. Another example is udp_rcv will judge whether the socket receive queue is full. The corresponding kernel parameter is net core. rmem_ Max and net core. rmem_ default. If you are interested, I suggest you read INET carefully_ Init is the code of this function.
2.4 network card driver initialization
Every driver (not just the network card driver) will use module_init registers an initialization function with the kernel. When the driver is loaded, the kernel will call this function. For example, the code of igb network card driver is located in drivers/net/ethernet/intel/igb/igb_main.c
//file: drivers/net/ethernet/intel/igb/igb_main.c
static struct pci_driver igb_driver = {
.name = igb_driver_name,
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove,
......
};
static int __init igb_init_module(void){
......
ret = pci_register_driver(&igb_driver);
return ret;
}
PCI Driver_ register_ After the driver call is completed, the Linux kernel knows the relevant information of the driver, such as the IGB of the IGB network card driver_ driver_ Name and IGB_ Probe function address, etc. When the network card device is recognized, the kernel will call the probe method driven by it (the probe method of igb_driver is igb_probe). The purpose of driving the probe method is to make the device ready. For the IGB network card, its IGB_ The probe is located at drivers/net/ethernet/intel/igb/igb_main.c lower. The main operations are as follows:

Figure 6 network card driver initialization
In step 5, we see that the network card driver implements the interface required by ethtool, and registers the function address here. When ethtool initiates a system call, the kernel will find the callback function of the corresponding operation. For igb network card, its implementation functions are drivers/net/ethernet/intel/igb/igb_ethtool.c lower. I believe you can fully understand the working principle of ethtool this time? The reason why this command can view the network card receiving and sending statistics, modify the network card adaptive mode, and adjust the number and size of RX queues is that the ethtool command finally calls the corresponding method driven by the network card, rather than the super ability of ethtool itself.
Step 6 registered igb_netdev_ops contains igb_open and other functions, which will be called when the network card is started.
//file: drivers/net/ethernet/intel/igb/igb_main.c
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_do_ioctl = igb_ioctl,
......
In step 7, in igb_ igb is also called during probe initialization_ alloc_ q_ vector. It registers a poll function necessary for the NAPI mechanism. For the igb network card driver, this function is igb_poll, as shown in the following code.
static int igb_alloc_q_vector(struct igb_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int rxr_count, int rxr_idx){
......
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi,
igb_poll, 64);
}
2.5 start the network card
When the above initialization is completed, you can start the network card. Recall that when the network card driver was initialized, we mentioned that the driver registered structure net with the kernel_ device_ Ops variable, which contains callback functions (function pointers) such as network card enabling, contracting and setting mac address. When a network card is enabled (for example, through ifconfig eth0 up), net_ device_ IGB in Ops_ The open method is called. It usually does the following:

Figure 7 starting the network card
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming){
/* allocate transmit descriptors */
err = igb_setup_all_tx_resources(adapter);
/* allocate receive descriptors */
err = igb_setup_all_rx_resources(adapter);
/* Register interrupt handler */
err = igb_request_irq(adapter);
if (err)
goto err_req_irq;
/* Enable NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
......
}
Up there__ igb_ The open function called igb_setup_all_tx_resources, and igb_setup_all_rx_resources. In IGB_ setup_ all_ rx_ In the step of resources, RingBuffer is allocated and the mapping relationship between memory and Rx queue is established. (the number and size of Rx Tx queues can be configured through ethtool). Let's move on to interrupt function registration igb_request_irq:
static int igb_request_irq(struct igb_adapter *adapter){
if (adapter->msix_entries) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
......
}
}
static int igb_request_msix(struct igb_adapter *adapter){
......
for (i = 0; i < adapter->num_q_vectors; i++) {
...
err = request_irq(adapter->msix_entries[vector].vector,
igb_msix_ring, 0, q_vector->name,
}
Trace function calls in the above code__ igb_ open => igb_ request_ irq => igb_request_msix, in IGB_ request_ In msix, we can see that for multi queue network cards, interrupts are registered for each queue, and the corresponding interrupt processing function is igb_msix_ring (this function is also under drivers/net/ethernet/intel/igb/igb_main.c). We can also see that in msix mode, each RX queue has an independent MSI-X interrupt. From the level of network card hardware interrupt, you can set to let the received packets be processed by different CPUs. (you can modify the binding behavior with CPU through irqbalance or modify / proc/irq/IRQ_NUMBER/smp_affinity).
When the above preparations are made, you can open the door to welcome guests (data packet)!
3, Welcome the arrival of data
3.1 hard interrupt processing
First, when the data frame arrives on the network card from the network cable, the first station is the receiving queue of the network card. The network card looks for the available memory location in the RingBuffer allocated to it. After finding it, the DMA engine will DMA the data to the memory associated with the network card. At this time, the CPU is insensitive. After the DMA operation is completed, the network card will initiate a hard interrupt like the CPU to notify the CPU that data has arrived.
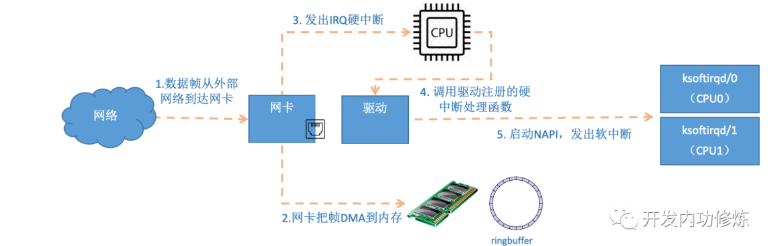
Figure 8 network card data hard interrupt processing process
Note: when RingBuffer is full, new packets will be discarded. When ifconfig checks the network card, there can be an overruns in it, indicating that the ring queue is full of discarded packets. If packet loss is found, you may need to increase the length of the ring queue through the ethtool command.
In the section of starting the network card, we talked about the hard interrupt registration of the network card. The processing function is igb_msix_ring.
//file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data){
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
igb_write_itr only records the hardware interrupt frequency (it is said that the purpose is to reduce the interrupt frequency to the CPU). Follow NaPi_ The schedule call is tracked all the way__ napi_schedule=>____ napi_schedule
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi){
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
Here we see, list_add_tail modifies the CPU variable softnet_ Poll in data_ List, which will drive NaPi_ Poll from struct_ List was added. Softnet_ Poll in data_ List is a two-way list in which devices have input frames waiting to be processed. Then__ raise_softirq_irqoff triggered a soft interrupt_ RX_ Softirq, the so-called trigger process, only performs a or operation on a variable.
void __raise_softirq_irqoff(unsigned int nr){
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
//file: include/linux/irq_cpustat.h
#define or_softirq_pending(x) (local_softirq_pending() |= (x))
As we said, Linux only completes the simple and necessary work in the hard interrupt, and most of the remaining processing is transferred to the soft interrupt. As can be seen from the above code, the hard interrupt processing process is really very short. Just recorded a register and modified the poll of the CPU_ List, and then issue a soft interrupt. It's that simple. Hard interrupt work is finished.
3.2 ksoftirqd kernel thread handling soft interrupt
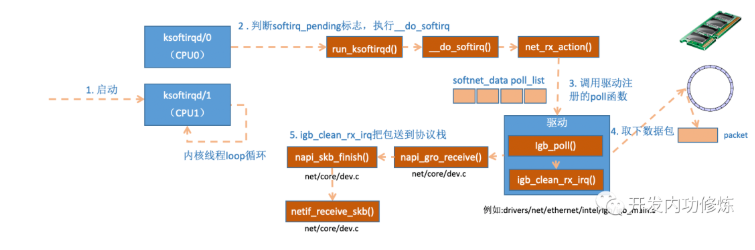
Figure 9 ksoftirqd kernel threads
During kernel thread initialization, we introduced two thread functions Ksoft irqd in Ksoft irqd_ should_ Run and run_ksoftirqd. Where ksoftirqd_ should_ The run code is as follows:
static int ksoftirqd_should_run(unsigned int cpu){
return local_softirq_pending();
}
#define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)
Here we see the same function called local_ in hard interrupt. softirq_ pending. The difference is that the hard interrupt position is used to write the mark, and here it is only read. If net is set in hard interrupt_ RX_ Softirq, you can read it here naturally. Next, it will really enter the thread function run_ksoftirqd processing:
static void run_ksoftirqd(unsigned int cpu){
local_irq_disable();
if (local_softirq_pending()) {
__do_softirq();
rcu_note_context_switch(cpu);
local_irq_enable();
cond_resched();
return;
}
local_irq_enable();
}
stay__do_softirq In, judge according to the current CPU The type of soft interrupt that calls its registered action method.
asmlinkage void __do_softirq(void){
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
...
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
...
}
h++;
pending >>= 1;
} while (pending);
}
In the network subsystem initialization section, we see that we are NET_RX_SOFTIRQ registers the handler function net_rx_action. So net_ rx_ The action function will be executed.
Here we need to pay attention to a detail. Setting the soft interrupt flag in the hard interrupt and ksoftirq's judgment of whether a soft interrupt arrives are all based on smp_processor_id(). This means that as long as the hard interrupt is responded to on which CPU, the soft interrupt is also processed on this CPU. Therefore, if you find that your Linux soft interrupt CPU consumption is concentrated on one core, you should adjust the CPU affinity of hard interrupts to disperse hard interrupts to different CPU cores.
Let's focus on the core function net_rx_action up.
static void net_rx_action(struct softirq_action *h){
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
......
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
budget -= work;
}
}
Time at the beginning of the function_ Limit and budget are used to control net_ rx_ The action function exits automatically to ensure that the network packet reception does not occupy the CPU. Wait until the next hard interrupt from the network card, and then process the remaining received packets. The budget can be adjusted by kernel parameters. The remaining core logic in this function is to get the current CPU variable softnet_data, poll_list, and then execute the poll function registered with the network card driver. For the igb network card, it is the igb driving force_ The poll function.
static int igb_poll(struct napi_struct *napi, int budget){
...
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget);
...
}
In a read operation, igb_poll's focus is on IGB_ clean_ rx_ Call to IRQ.
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget){
...
do {
/* retrieve a buffer from the ring */
skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
}
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
}
igb_fetch_rx_buffer and IGB_ is_ non_ The function of EOP is to remove data frames from RingBuffer. Why do you need two functions? Because it is possible that the frame will occupy many ringbuffers, it is obtained in a loop until the end of the frame. A SK is used to obtain a data frame_ Buff. After receiving the data, check it, and then set the timestamp, VLAN id, protocol and other fields of sbk variable. Next, go to NaPi_ gro_ In receive:
//file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb){
skb_gro_reset_offset(skb);
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
dev_ GRO_ The receive function represents the GRO feature of the network card. It can be simply understood as merging related small packets into one large packet. The purpose is to reduce the number of packets transmitted to the network stack, which helps to reduce CPU usage. Let's ignore it and look directly at napi_skb_finish, this function mainly calls netif_receive_skb.
//file: net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb){
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb(skb))
ret = GRO_DROP;
break;
......
}
In netif_ receive_ In SKB, packets will be sent to the protocol stack. It is stated that the following 3.3, 3.4 and 3.5 also belong to the processing process of soft interrupt, but they are taken out into separate sections due to their long length.
3.3 network protocol stack processing
netif_ receive_ The SKB function will send the packets to IP in turn according to the protocol of the packet. If it is a UDP packet, the SKB function will send the packets to IP in turn_ rcv(),udp_ RCV () is processed in the protocol processing function.
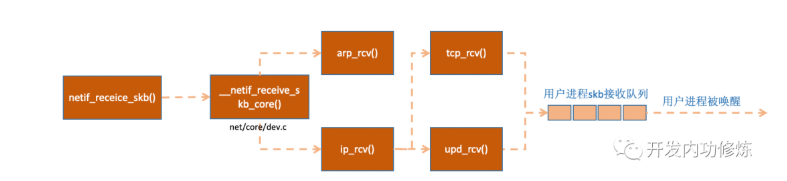
Figure 10 network protocol stack processing
//file: net/core/dev.c
int netif_receive_skb(struct sk_buff *skb){
//RPS processing logic, ignore
return __netif_receive_skb(skb);
}
static int __netif_receive_skb(struct sk_buff *skb){
......
ret = __netif_receive_skb_core(skb, false);}static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc){
......
//pcap logic, where the data will be sent to the packet capture point. tcpdump obtains the package list from this entry_ for_ each_ entry_ rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
......
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
}
In__ netif_ receive_ skb_ In core, I was very excited when I looked at the packet capture point of tcpdump, which was often used. It seems that the time to read the source code is really not wasted. Then__ netif_ receive_ skb_ The core takes out the protocol. It will take out the protocol information from the packet, and then traverse the list of callback functions registered on the protocol. ptype_base is a hash table, which we mentioned in the protocol registration section. ip_ The RCV function address exists in this hash table.
//file: net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev){
......
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
pt_ Prev - > func calls the processing function registered at the protocol layer. For ip packets, it will enter ip_rcv (if it is an ARP package, it will enter arp_rcv).
3.4 IP protocol layer processing
Let's take a general look at what linux does in the ip protocol layer and how packets are further sent to udp or tcp protocol processing functions.
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
}
Here NF_HOOK is a hook function. When the registered hook is executed, it will be executed to the function IP pointed to by the last parameter_ rcv_ finish.
static int ip_rcv_finish(struct sk_buff *skb){
......
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
...
}
......
return dst_input(skb);
}
Tracking IP_ route_ input_ After noref, I see that it calls IP again_ route_ input_ mc. In IP_ route_ input_ In MC, function IP_ local_ The delivery is assigned to DST Input, as follows:
//file: net/ipv4/route.c
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev, int our){
if (our) {
rth->dst.input= ip_local_deliver;
rth->rt_flags |= RTCF_LOCAL;
}
}
So back ip_rcv_finish Medium return dst_input(skb);.
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb){
return skb_dst(skb)->input(skb);
}
skb_ The input method called by DST (SKB) - > input is the IP assigned by the routing subsystem_ local_ deliver.
//file: net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb){
/* * Reassemble IP fragments. */
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct sk_buff *skb){
......
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
ret = ipprot->handler(skb);
}
}
See INET in the agreement registration section_ tcp is stored in the protocol_ RCV () and udp_ Function address of rcv(). Here, skb packets will be distributed according to the protocol type in the packet. Here, skb packets will be further sent to the higher layer protocols, udp and tcp.
3.5 UDP protocol layer processing
In the protocol registration section, we said that the processing function of udp protocol is udp_rcv.
//file: net/ipv4/udp.c
int udp_rcv(struct sk_buff *skb){
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto){
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
int ret = udp_queue_rcv_skb(sk, skb
}
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
}
__ udp4_lib_lookup_skb is to find the corresponding socket according to skb. When it is found, it will put the data packet into the cache queue of the socket. If not found, an icmp packet with unreachable destination is sent.
//file: net/ipv4/udp.c
int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb){
......
if (sk_rcvqueues_full(sk, skb, sk->sk_rcvbuf))
goto drop;
rc = 0;
ipv4_pktinfo_prepare(skb);
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk);
return rc;
}
sock_ owned_ by_ The user determines whether the user is making a system call on the socket (the socket is occupied). If not, it can be directly placed in the socket receiving queue. If so, pass sk_add_backlog adds packets to the backlog queue. When the user releases the socket, the kernel will check the backlog queue and move the data to the receive queue if any.
sk_ rcvqueues_ If the receive queue is full, the packet will be discarded directly. The receive queue size is controlled by the kernel parameter net core. rmem_ Max and net core. rmem_ Default effect.
4, recvfrom system call
Two flowers, one for each. Above, we have finished the whole process of receiving and processing packets by the Linux kernel, and finally put the packets in the socket receiving queue. Then let's look back at what happened after the user process called recvfrom. Recvfrom we call in the code is a glibc library function. After execution, this function will put the user into the kernel state and enter the system call sys implemented by Linux_ recvfrom. Understanding the impact of Linux on sys_ Before revvfrom, let's take a brief look at the core data structure socket. This data structure is too large. We only draw the contents related to our topic today, as follows:
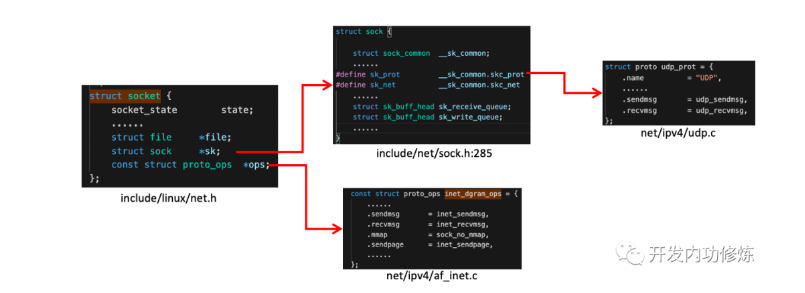
Figure 11 socket kernel data mechanism
Const struct proto in socket data structure_ Ops corresponds to the method set of the protocol. Each protocol will implement different method sets. For IPv4 Internet protocol family, each protocol has corresponding processing methods, as follows. For udp, it is through inet_dgram_ops, where INET is registered_ Recvmsg method.
//file: net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
......
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
......
}
const struct proto_ops inet_dgram_ops = {
......
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
......
}
Another data structure in socket data structure struct socket * SK is a very large and important substructure. Where sk_prot also defines the secondary processing function. For UDP protocol, it will be set as the method set UDP implemented by UDP protocol_ prot.
//file: net/ipv4/udp.c
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
......
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage,
......
}
After reading the socket variable, let's look at sys again_ The implementation process of revvfrom.
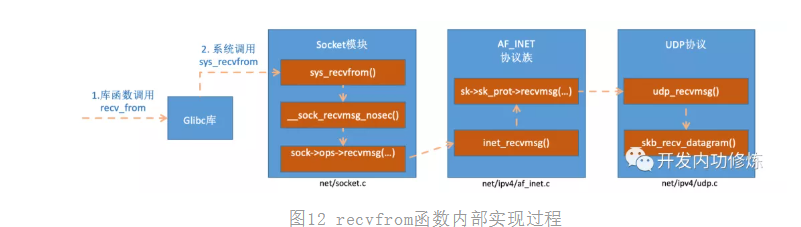
Figure 12 internal implementation process of recvfrom function
In inet_recvmsg called SK - > sk_ prot->recvmsg.
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,size_t size, int flags){
......
err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
As mentioned above, for the socket of udp protocol, this sk_prot is net / IPv4 / udp Struct proto udp under c_ prot. So we found udp_recvmsg method.
//file:net/core/datagram.c:EXPORT_SYMBOL(__skb_recv_datagram);
struct sk_buff *__skb_recv_datagram(struct sock *sk, unsigned int flags,int *peeked, int *off, int *err){
......
do {
struct sk_buff_head *queue = &sk->sk_receive_queue;
skb_queue_walk(queue, skb) {
......
}
/* User doesn't want to wait */
error = -EAGAIN;
if (!timeo)
goto no_packet;
} while (!wait_for_more_packets(sk, err, &timeo, last));
}
Finally, we found the key point we want to see. We saw the so-called reading process above, which is to access SK - > sk_ receive_ queue. If there is no data and the user is allowed to wait, wait is called_ for_ more_ Packets () performs a wait operation, which will put the user process into sleep.
5, Summary
Network module is the most complex module in Linux kernel. It seems that a simple packet receiving process involves the interaction between many kernel components, such as network card driver, protocol stack, kernel ksoftirqd thread, etc. It seems very complex. This paper wants to explain the kernel packet receiving process in an easy to understand way through illustration. Now let's go through the whole packet receiving process.
After the user executes the recvfrom call, the user process will work in the kernel state through the system call. If there is no data in the receive queue, the process goes to sleep and is suspended by the operating system. This is relatively simple. Most of the remaining scenes are performed by other modules of the Linux kernel.
First of all, Linux needs to do a lot of preparatory work before receiving packets:
-
Create ksoftirqd thread, set its own thread function for it, and expect it to handle soft interrupts later
-
For protocol stack registration, linux needs to implement many protocols, such as arp, icmp, ip, udp and tcp. Each protocol will register its own processing function to facilitate the package to quickly find the corresponding processing function
-
Network card driver initialization. Each driver has an initialization function. The kernel will also initialize the driver. In this initialization process, prepare your DMA and tell the kernel the poll function address of NAPI
-
Start the network card, allocate RX and TX queues, and register the processing function corresponding to the interrupt
The above is the important work before the kernel is ready to receive the packet. When all the above are ready, you can open the hard interrupt and wait for the arrival of the packet.
When the data arrives, the first person to greet it is the network card (I'll go, isn't this nonsense):
-
The network card DMA the data frame into the RingBuffer of the memory, and then sends an interrupt notification to the CPU
-
The CPU responds to the interrupt request and calls the interrupt processing function registered when the network card is started
-
The interrupt handler did little to initiate a soft interrupt request
-
When the kernel thread ksoftirqd thread finds that a soft interrupt request has arrived, it closes the hard interrupt first
-
The ksoftirqd thread starts to call the poll function of the driver to receive packets
-
The poll function sends the received packet to the IP address registered in the protocol stack_ In RCV function
-
ip_ The RCV function sends packets to UDP_ In the RCV function (for TCP packets, it is sent to tcp_rcv)
Now we can go back to the problem at the beginning. We saw a simple line recvfrom in the user layer. The Linux kernel has to do so much for us to receive data smoothly. This is a simple UDP. If it is TCP, the kernel has to do more work. I can't help but sigh that the kernel developers are really well intentioned.
After understanding the whole package receiving process, we can clearly know the CPU overhead of Linux receiving a package. The first is the cost of user process calls and system calls falling into kernel state. The second block is the CPU overhead of the hard interrupt of the CPU response packet. The third is the cost of the soft interrupt context of the ksoftirqd kernel thread. Later, we will send an article to actually observe these expenses.
In addition, there are many terminal details in network transceiver, such as no NAPI, GRO, RPS, etc. Because I think what I said is too right, it will affect everyone's grasp of the whole process, so try to keep only the main framework, less is more!