Catalog
1.2.1. Add in/etc/passwd line 4
2.3.1. Select columns for output printing
2.3.3. Execution file calling awk-f
2.3.6. regular expression matching
2.4.2. Case 2 Print 99 Multiplication Table
1. SED of Three Swordsmen
1.1. Fundamentals
1.1.1. Summary
- The Linux sed command uses scripts to process text files.
- sed can process and edit text files as directed by the script.
- Sed is mainly used to automatically edit one or more files, simplify repetitive operations on files, write conversion programs, etc.
1.1.2. grammar
sed [-hnV][-e<script>][-f<script file>][text file] #Parameter Description -e<script>or--expression=<script> As specified in the option script To process the input text file. -f<script file>or--file=<script file> As specified in the option script File to process the input text file. -h or--help Show help. -n or--quiet or--silent Show Only script The result after processing. -V or--version Display version information. #Action description a : Newly added, a Strings can be followed, and they appear on a new line(Current Next Line)~ c : Replace, c Strings can be followed, which can be replaced n1,n2 Between lines! d : Delete, because it is delete, so d Usually there is no click after; i : Insert, i Strings can be followed, and they appear on a new line(Current previous line); p : Print, or print out a selected data. usually p Will and parameter sed -n Run together~ s : Substitution, can be done directly instead of the work mile! Usually this s Actions can be paired with regular representations! For example, 1,20s/old/new/g That's it!
1.2. List display
1.2.1. Add in/etc/passwd line 4
sed -e 4a\newLine /etc/passwd
1.2.2. Append insert
#You don't need to add a line break\n before or after you append a line, only between lines when you append multiple lines (you don't need to add a line at the end of the last line, there will be an extra line if you add one). sed -e '4 a newline\nnewline2' /etc/passwd
Addition of i
cat /etc/passwd | sed '2i drink tea'
1.2.3. delete
#Delete 2 to 5 lines cat /etc/passwd | sed '2,5d' #Delete 2 to last line cat /etc/passwd | sed '2,$d'
1.2.4. replace
#Use-c for whole line replacement [root@www ~]# cat /etc/passwd | sed '2,5c No 2-5 number' #Replace the root contained in the full text with ROOT using sed'/', cat /etc/passwd | sed '/s/root/ROOT/g' #The exact match root can be substituted or \<\> can be used for precise positioning cat /etc/passwd | sed '/s/(root)/ROOT/g'
1.2.5. Print Display
#Print lines 5 to 7. Repeat if -n is not added, -p is the action command cat /etc/passwd | sed -n '5,7p'
1.2.6. Multipoint Editing
#A sed command that deletes/etc/passwd data from the third line to the end and replaces bash with blueshell cat /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1.2.7 Modify text content
#Content can be modified directly by sed-i sed -i 's/\.$/\!/g' regular_express.txt #None-i ignores case sed '5,7/root/Ipg' #Yes-i ignores case sed -i '5,7/root/ipg'
2. AWK of Three Swordsmen
2.1. Summary
- AWK is a language for processing text files and a powerful text analysis tool.
- AWK is called because it takes the first characters of three founders, Alfred Aho, Peter Weinberger, and Brian Kernighan's Family Name.
2.2. grammar
awk [Option parameters] 'script' var=value file(s) or awk [Option parameters] -f scriptfile var=value file(s) #Option parameter description: -F fs or --field-separator fs Specify the input file delimiter, fs Is a string or is a regular expression, such as-F:. -v var=value or --asign var=value Assign a user-defined variable. -f scripfile or --file scriptfile Read from script file awk Command. -mf nnn and -mr nnn Yes nnn Value setting intrinsic limits,-mf Option Restrictions Assigned to nnn Maximum number of blocks;-mr Options limit the maximum number of records. These two functions are Bell Lab Edition awk Extended functionality in standard awk Not applicable. -W compact or --compat, -W traditional or --traditional Run in Compatibility Mode awk. therefore gawk Behavior and Standard awk Exactly the same, all awk Extensions are ignored. -W copyleft or --copyleft, -W copyright or --copyright Print short copyright information. -W help or --help, -W usage or --usage Print All awk Options and a brief description of each option. -W lint or --lint Printing cannot go to tradition unix Warning for the structure of platform porting. -W lint-old or --lint-old Print about not being able to move to tradition unix Warning for the structure of platform porting. -W posix Turn on compatibility mode. However, the following limitations are not recognized:/x,Function keywords, func,Transcoding sequence and when fs When a space is specified, the new line is used as a field separator. Operator**and**=Not Replaceable^and^=;fflush Invalid. -W re-interval or --re-inerval Allow the use of interval regular expressions, see(grep In Posix Character class),Such as bracket expressions[[:alpha:]]. -W source program-text or --source program-text Use program-text As source code, can be used with-f Command mix. -W version or --version Print bug Version of report information.
2.3. List
2.3.1. Select columns for output printing
#Basic usage
awk '{[pattern] action}' {filenames} # Row matching statement awk''can only use single quotation marks
#Listed below
#Print/etc/passwd Columns 1 and 2 Here-F is the divider
awk -F: '{print $1,$2}' /etc/passwd2.3.2. set variable
#-va=1 sets the value of a variable to 1, while $1+1 represents the second column
awk -va=1 '{print $1,$1+a}' /etc/passwd2.3.3. Execution file calling awk-f
awk -f {awk Script} {file name}2.3.4. operator
| operator | describe |
|---|---|
| = += -= *= /= %= ^= **= | assignment |
| ?: | C Conditional Expression |
| || | Logical or |
| && | Logical and |
| ~and!~ | Matching regular expressions and mismatching regular expressions |
| < <= > >= != == | Relational Operators |
| Spaces | Connect |
| + - | Add, subtract |
| * / % | Multiplication, Division and Remainder |
| + - ! | Unary addition, subtraction and logical negation |
| ^ *** | Exponentiation |
| ++ -- | Increase or decrease as prefix or suffix |
| $ | Field Reference |
| in | Array members |
#Column: Filter rows where the first column is greater than 2 and the second column is equal to'Are'
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #command
#output
3 Are you2.3.5. Built-in variables
| variable | describe |
|---|---|
| $n | The nth field of the current record, separated by FS |
| $0 | Complete input record |
| ARGC | Number of command line parameters |
| ARGIND | Location of the current file on the command line (from 0) |
| ARGV | Array containing command line parameters |
| CONVFMT | Number Conversion Format (default is%.6g)ENVIRON Environment Variable Associated Array |
| ERRNO | Description of the last system error |
| FIELDWIDTHS | Field Width List (spacebar delimited) |
| FILENAME | Current File Name |
| FNR | Line number counted separately for each file |
| FS | Field delimiter (default is any space) |
| IGNORECASE | Ignore case matching if true |
| NF | Number of fields in a record |
| NR | Number of records that have been read, which is the line number, starting from 1 |
| OFMT | Output format of numbers (default is%.6g) |
| OFS | Output field delimiter with default values consistent with input field delimiter. |
| ORS | Output record delimiter (default is a line break) |
| RLENGTH | The length of the string matched by the match function |
| RS | Record delimiter (default is a line break) |
| RSTART | The first position of the string matched by the match function |
| SUBSEP | Array subscript separator (default is/034) |
2.3.6. regular expression matching
#~Indicates the start of the pattern. // Medium is the mode. awk '/re/ ' log.txt
2.3.7. ignore case
awk 'BEGIN{IGNORECASE=1} /this/' log.txt2.4.awk script
With awk scripts, we need to be aware of two keywords, BEGIN and END.
- BEGIN{Here's the statement before execution}
- END {Statement to execute after all lines have been processed}
- {Here's the statement to execute when processing each line}
2.4.1. List
Suppose there is such a file (student report form):
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
Ours awk The script is as follows:
$ cat cal.awk
#!/bin/awk -f
#Before running
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#Running
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#After running
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
Let's look at the results:
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.002.4.2. Case 2 Print 99 Multiplication Table
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
3. Widget Expansion
3.1.sort tool
- -f: Ignore case
- o-b: Ignore spaces in front of each line
- -M: Sort by month
- o-n: Sort by number
- -r: reverse sort
- -u: Equivalent to uniq, meaning the same data displays only one row
- -t: Specifies the separator, separated by [Tab] key by default
- -o<Output File>: Save the sorted results to the specified file
- -k: Specify the sorting area
3.2.uniq Tools
- Reporting or ignoring duplicate lines in a file is typically used in conjunction with the sort command
- o-c:Count
- o-d: Show only duplicate rows
- -u: Show rows that appear only once
3.3.cut tool
- -b:intercept by byte
- -c: intercept by character, commonly used in Chinese
- -d: Specifies what to intercept as a delimiter, defaults to tab
- -f: usually with-d
3.3.1 Columns
- Intercept/etc/passwd to: 1 to 3 columns of split data
cat /etc/passwd |cut -d: -f1-3
- Intercept/etc/passwd to: 1 and 3 columns of split data
cat /etc/passwd |cut -d: -f1,3
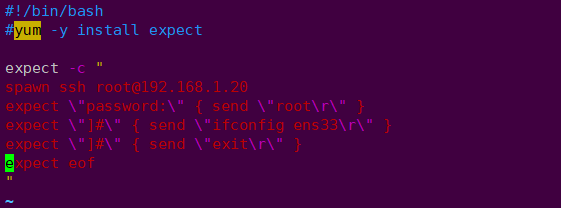
3.4.expect tool



3.5.tr tool
Convert input characters from uppercase to lowercase
[root@localhost ~]# echo "KGC" | tr 'A-Z" 'a-z'
Compress duplicate characters in input
[root@localhost ~]# echo "thissss isa text linnnnnnne." | tr -s ' sn'
Remove some characters from the string
[root@localhost ~]# echo 'hello world' | tr -d 'od'
3.6 Logon User Commands
[root@pxeserver ~]# last