What is LTO (omitted)
What are LLVM LTO Objects?
Use Example of link time optimization An example of this is shown below.
--- a.h ---
extern int foo1(void);
extern void foo2(void);
extern void foo4(void);
--- a.c ---
#include "a.h"
static signed int i = 0;
void foo2(void) {
i = -1;
}
static int foo3() {
foo4();
return 10;
}
int foo1(void) {
int data = 0;
if (i < 0)
data = foo3();
data = data + 42;
return data;
}
--- main.c ---
#include <stdio.h>
#include "a.h"
void foo4(void) {
printf("Hi\n");
}
int main() {
return foo1();
}
Compiling the LTO version, we can see a_lto.o has 1.2 K more content than a.o.
$ clang -flto -c a.c -o a_lto.o $ clang -c a.c -o a.o $ ls -alh ... -rw-r--r-- 1 wangliushuai wangliushuai 1.6K Feb 2 14:41 a.o -rw-r--r-- 1 wangliushuai wangliushuai 2.8K Feb 2 14:41 a_lto.o
We use hexdump to print the contents of the object file, and we know magic number Usually used for identification file format . a.o must be a normal ELF file, and magic number of ELF file is 7F 45(E) 4C(L) 46(F). So let's focus on a_lto.o on magic number 4342 dec0.
$ hexdump a_lto.o | head 0000000 4342 dec0 1435 0000 0005 0000 0c62 2430 0000010 594d 66be fb8d 4fb4 c81b 4424 3201 0005 0000020 0c21 0000 0262 0000 020b 0021 0002 0000 0000030 0016 0000 8107 9123 c841 4904 1006 3932 $ hexdump a.o | head 0000000 457f 464c 0102 0001 0000 0000 0000 0000 0000010 0001 003e 0001 0000 0000 0000 0000 0000
We know from man ascii that 4243 is B C, llvm IR has three representations, text, in memory, and bitcode . So guessing BC means bitcode.
Oct Dec Hex Char Oct Dec Hex Char ------------------------------------------------------------------------ # ... 002 2 02 STX (start of text) 102 66 42 B 003 3 03 ETX (end of text) 103 67 43 C # ...
So we found bitcode's magic number Below. Corresponds to 4342 dec0, a total of 4 bytes.
[ ' B ' 8 , ' C ' 8 , 0 x 0 4 , 0 x C 4 , 0 x E 4 , 0 x D 4 ] ['B'_8, 'C'_8, 0x0_4, 0xC_4, 0xE_4, 0xD_4] ['B'8,'C'8,0x04,0xC4,0xE4,0xD4]
For bitcode file format, there are special tools llvm-bcanalyzer For analysis, dump produced a lot of data.
$ llvm-bcanalyzer -dump a_lto.o
# ...
Summary of a_lto.o:
Total size: 22592b/2824.00B/706W
Stream type: LLVM IR
# Toplevel Blocks: 4
# ...
Block ID #12 (FUNCTION_BLOCK):
Num Instances: 3
Total Size: 956b/119.50B/29W
Percent of file: 4.2316%
Average Size: 318.67/39.83B/9W
Tot/Avg SubBlocks: 6/2.000000e+00
Tot/Avg Abbrevs: 0/0.000000e+00
Tot/Avg Records: 20/6.666667e+00
Percent Abbrevs: 35.0000%
Record Histogram:
Count # Bits b/Rec % Abv Record Kind
4 184 46.0 INST_STORE
3 57 19.0 100.00 INST_LOAD
3 24 8.0 100.00 INST_RET
3 66 22.0 DECLAREBLOCKS
2 128 64.0 INST_CALL
2 56 28.0 INST_BR
1 40 INST_CMP2
1 46 INST_ALLOCA
1 28 100.00 INST_BINOP
Block ID #13 (IDENTIFICATION_BLOCK_ID):
# ...
Block ID #14 (VALUE_SYMTAB):
# ...
Block ID #15 (METADATA_BLOCK):
# ...
Block ID #17 (TYPE_BLOCK_ID):
# ...
Block ID #21 (OPERAND_BUNDLE_TAGS_BLOCK):
# ...
Block ID #22 (METADATA_KIND_BLOCK):
# ...
Block ID #23 (STRTAB_BLOCK):
# ...
Block ID #24 (FULL_LTO_GLOBALVAL_SUMMARY_BLOCK):
# ...
Block ID #25 (SYMTAB_BLOCK):
# ...
Data is organized according to bitcode file in a certain format and we do not do detailed analysis. We use llvm-dis Convert it into a human-readable form. We can see a_ Lto. The code in O is LLVM IR.
; ModuleID = 'a_lto.o'
source_filename = "a.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@i = internal global i32 0, align 4
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo2() #0 {
entry:
store i32 -1, i32* @i, align 4
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @foo1() #0 {
entry:
%data = alloca i32, align 4
store i32 0, i32* %data, align 4
%0 = load i32, i32* @i, align 4
%cmp = icmp slt i32 %0, 0
br i1 %cmp, label %if.then, label %if.end
if.then: ; preds = %entry
%call = call i32 @foo3()
store i32 %call, i32* %data, align 4
br label %if.end
if.end: ; preds = %if.then, %entry
%1 = load i32, i32* %data, align 4
%add = add nsw i32 %1, 42
store i32 %add, i32* %data, align 4
%2 = load i32, i32* %data, align 4
ret i32 %2
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @foo3() #0 {
entry:
call void @foo4()
ret i32 10
}
declare dso_local void @foo4() #1
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #1 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4}
!llvm.ident = !{!5}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 1}
!2 = !{i32 7, !"frame-pointer", i32 2}
!3 = !{i32 1, !"ThinLTO", i32 0}
!4 = !{i32 1, !"EnableSplitLTOUnit", i32 1}
!5 = !{!"clang version 14.0.0 (https://github.com/llvm/llvm-project.git 58e7bf78a3ef724b70304912fb3bb66af8c4a10c)"}
^0 = module: (path: "a_lto.o", hash: (0, 0, 0, 0, 0))
^1 = gv: (name: "foo2", summaries: (function: (module: ^0, flags: (linkage: external, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 2, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), refs: (^2)))) ; guid = 2494702099028631698
^2 = gv: (name: "i", summaries: (variable: (module: ^0, flags: (linkage: internal, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), varFlags: (readonly: 1, writeonly: 1, constant: 0)))) ; guid = 2708120569957007488
^3 = gv: (name: "foo1", summaries: (function: (module: ^0, flags: (linkage: external, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 13, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), calls: ((callee: ^5)), refs: (^2)))) ; guid = 7682762345278052905
^4 = gv: (name: "foo4") ; guid = 11564431941544006930
^5 = gv: (name: "foo3", summaries: (function: (module: ^0, flags: (linkage: internal, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 2, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), calls: ((callee: ^4))))) ; guid = 17367728344439303071
^6 = flags: 8
^7 = blockcount: 5
However, there is a problem here that lto optimization will not occur if the -flto option is not added to the link. So if there is no-flto when adding-flto links at compile time, then linker directly processes LLVM IR. Can links pass? It can be handled directly. For example, for lld, it chooses the appropriate function to process the lto bitcode file based on the type of object file. Here is LinkDriver:: link -> compileBitcodeFiles. I'll skip here for a moment, but I'll show you later.
// Do actual linking. Note that when this function is called,
// all linker scripts have already been parsed.
template <class ELFT> void LinkerDriver::link(opt::InputArgList &args) {
// ...
if (!bitcodeFiles.empty()) {
// ...
// Do link-time optimization if given files are LLVM bitcode files.
// This compiles bitcode files into real object files.
//
// With this the symbol table should be complete. After this, no new names
// except a few linker-synthesized ones will be added to the symbol table.
compileBitcodeFiles<ELFT>();
// ...
}
// ...
}
So far we know that for full LTO, bitcode is generated and LLVM IR is stored. lld chooses the appropriate function to process based on the objece file type.
How the LTO process works
First, give lld the full command when processing lto objects.
~/workspace/llvm-project/build/bin/ld.lld --hash-style=both --eh-frame-hdr -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o exe /lib/x86_64-linux-gnu/crt1.o /lib/x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/8/crtbegin.o -L/usr/lib/gcc/x86_64-linux-gnu/8 -L/usr/lib/gcc/x86_64-linux-gnu/8/../../../../lib64 -L/lib/x86_64-linux-gnu -L/lib/../lib64 -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib64 -L/usr/local/bin/../lib -L/lib -L/usr/lib -plugin-opt=mcpu=x86-64 a-lto.o main-lto.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-linux-gnu/8/crtend.o /lib/x86_64-linux-gnu/crtn.o
Next, the whole lld execution process is given, which is divided into three parts as a whole
- Preparation, the preparation process, mainly including configuration processing, searching and opening files to create corresponding lld processing objects for these files;
- LTO Backend, if lld finds lto objects in the process (we mentioned earlier that lto objects are actually bitcode format files), set up BitcodeCompiler and go into the lld lto process;
- Calculate Dead Function
- Connect them to an integrated IR Module
- Update visibility
- Building LTO optimization pipeline
- Perform real optimization
- code generation
- Linking process for LLD
- All the Files are now ready to aggregate Input Section s
- gc-sections
- Calculate offset information for each symbol s when the section s are aggregated; And reposition
- Identical Code Folding
- Final Output
The detailed process is shown in the following figure:

Preparation
1. Configuration
2. Search and Open Files
3. Add and Create Files
4. Parse the Files
LTO Backend
5-(1) Calculate the dead function
Previously, we used llvm-dis to process the bitcode file compiled by lto and got a series of gv in the IR, which means Global Value Summary Entry.
There can be multiple entries in a combined summary index for symbols with weak linkage.
The following figure is main_ Lto. gv information in o,
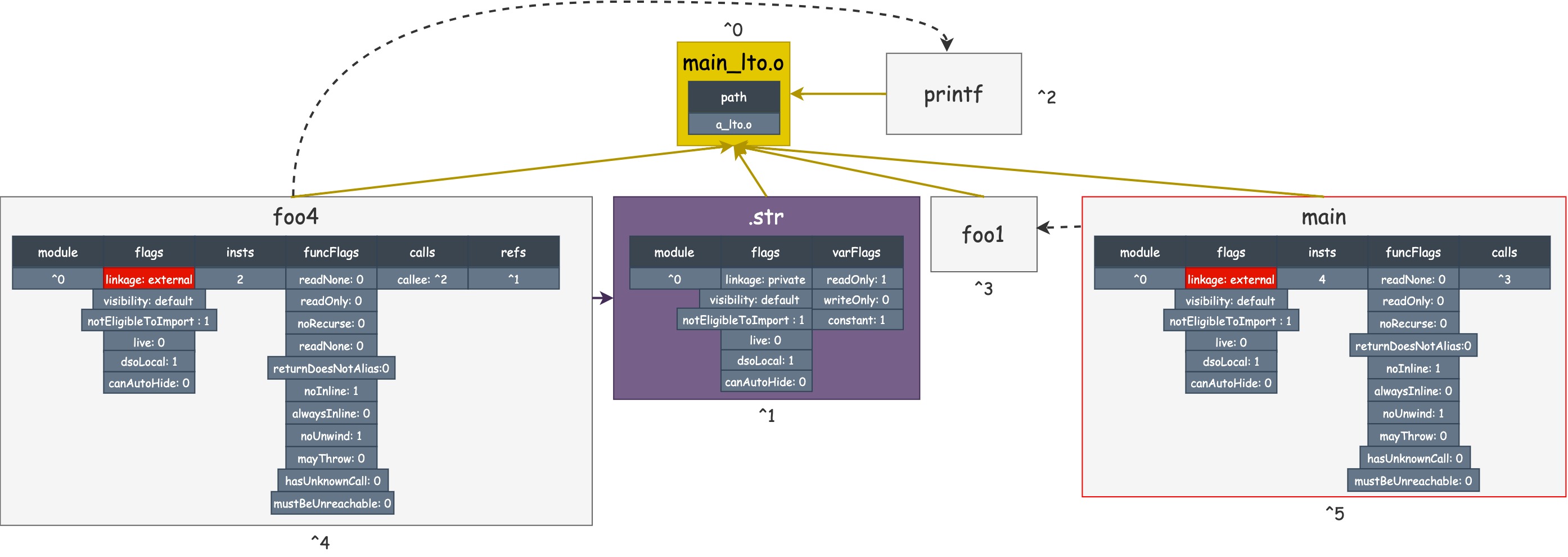
The following figure is a_ Lto. gv information in o,

computeDeadSymbolsWithConstProp() calls computeDeadSymbolsAndUpdateIndirectCalls(), which calculates live sets using the worklist algorithm based on a root set.
The root set currently has only one main function, which is set to live, pushed into the Worklist, and iterates over the Worklist continuously based on the refs and calls relationships.

5-(2) Link the IRs together
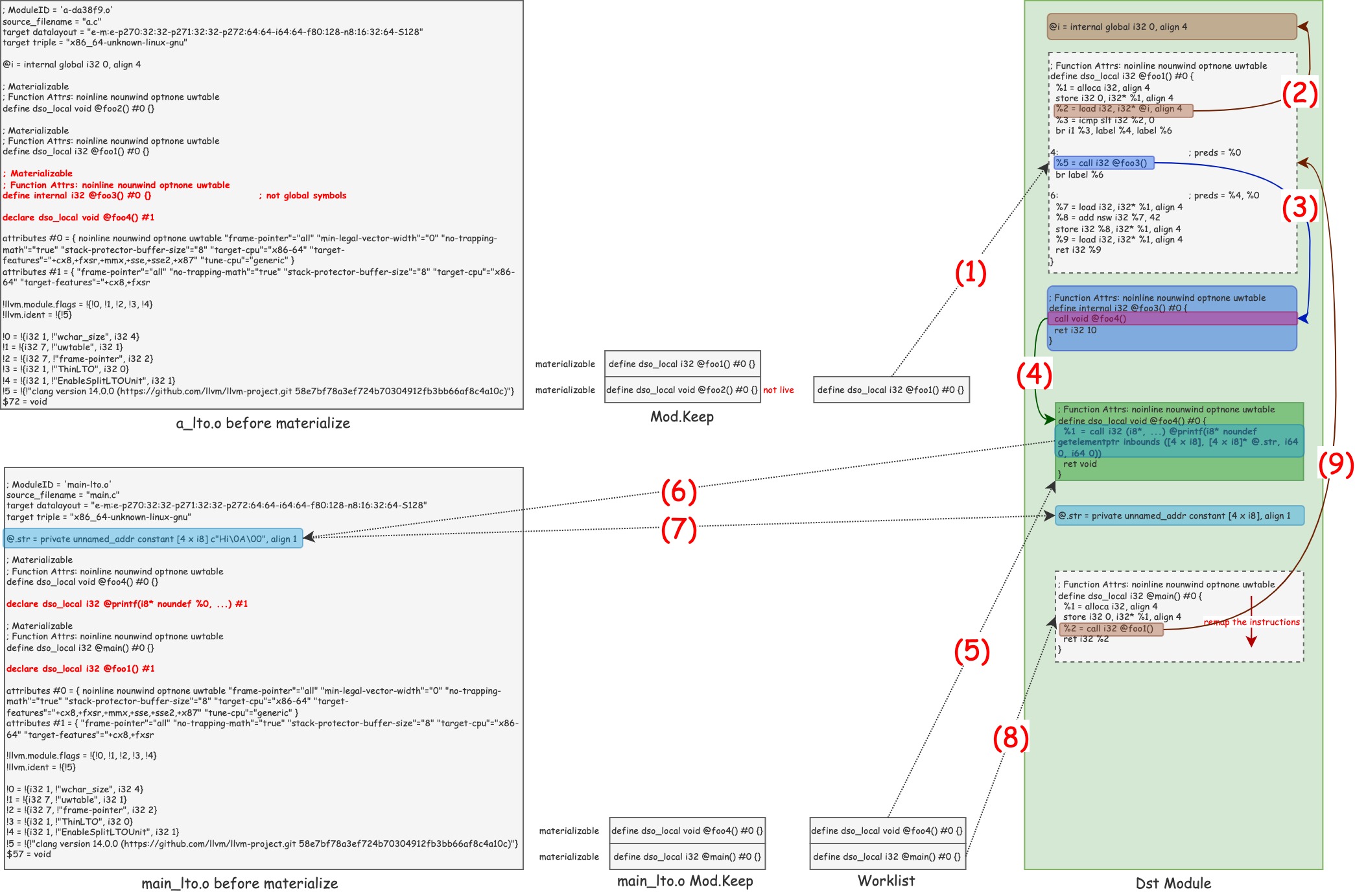
The whole process is that IRLinker "links" each source module to the destination module based on the previous live information, symbol resolution information and symbol visibility, mainly the process of materialize on demand.
5-(3) Update Call Visibility
5-(4) Build LTO Optimization Pipeline
BuilLTODefaultPipeline predefines a set of passes and adds them to ModulePassManager.
/// Build an LTO default optimization pipeline to a pass manager.
///
/// This provides a good default optimization pipeline for link-time
/// optimization and code generation. It is particularly tuned to fit well
/// when IR coming into the LTO phase was first run through \c
/// addPreLinkLTODefaultPipeline, and the two coordinate closely.
///
/// Note that \p Level cannot be `O0` here. The pipelines produced are
/// only intended for use when attempting to optimize code. If frontends
/// require some transformations for semantic reasons, they should explicitly
/// build them.
ModulePassManager buildLTODefaultPipeline(OptimizationLevel Level,
ModuleSummaryIndex *ExportSummary);
5-(5) Optimization
/// Run all of the passes in this manager over the given unit of IR.
/// ExtraArgs are passed to each pass.
PreservedAnalyses run(IRUnitT &IR, AnalysisManagerT &AM,
ExtraArgTs... ExtraArgs) {
}
5-(6) Code Generation
After the LTO is executed, an InputFile named LTO that lld can handle is created by calling createObjectFile() based on what was obtained from the previous codegen. Tmp, according to the general file, for lto.tmp performs a parse() operation once.
Link Stuff
6. Aggregate InputSections
So far, all the links have been prepared. There are currently 38 sections. We can see that there is no a_lto.o and main_lto.o, there's only one main_left Lto. O.

7. GC Sections
8. Finalize InputSections, Compute Offset
// This function scans over the InputSectionBase list sectionBases to create
// InputSectionDescription::sections.
//
// It removes MergeInputSections from the input section array and adds
// new synthetic sections at the location of the first input section
// that it replaces. It then finalizes each synthetic section in order
// to compute an output offset for each piece of each input section.
void OutputSection::finalizeInputSections() {}
// This function is very hot (i.e. it can take several seconds to finish)
// because sometimes the number of inputs is in an order of magnitude of
// millions. So, we use multi-threading.
//
// For any strings S and T, we know S is not mergeable with T if S's hash
// value is different from T's. If that's the case, we can safely put S and
// T into different string builders without worrying about merge misses.
// We do it in parallel.
void MergeNoTailSection::finalizeContents() {}
9. Identical Code Folding
// ICF is short for Identical Code Folding. This is a size optimization to // identify and merge two or more read-only sections (typically functions) // that happened to have the same contents. It usually reduces output size // by a few percent. // // In ICF, two sections are considered identical if they have the same // section flags, section data, and relocations. Relocations are tricky, // because two relocations are considered the same if they have the same // relocation types, values, and if they point to the same sections *in // terms of ICF*. // [1] Safe ICF: Pointer Safe and Unwinding aware Identical Code Folding // in the Gold Linker // http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/36912.pdf