Series contents: Look at the flink source code and learn flink
- Look at the flink source code and learn the flink --- flink state
preface
Tip: Here you can add the general contents to be recorded in this article:
For example, with the continuous development of artificial intelligence, machine learning technology is becoming more and more important. Many people have started learning machine learning. This paper introduces the basic content of machine learning.
Tip: the following is the main content of this article. The following cases can be used for reference
flink state
flink
Apache Flink® — Stateful Computations over Data Streams
Stateful computing on data flow
https://flink.apache.org/
Why do I need state?
● fault tolerance
Batch calculation: if none is successful, recalculate.
Flow computing: failover mechanism
○ in most scenarios, it is incremental calculation, and the data is processed one by one. Each calculation depends on the last calculation result
○ restore the state from the checkpoint when the job is restarted due to program errors (machine, network, dirty data)
● fault tolerance mechanism, the one-time fault tolerance mechanism of flink. Continuously create distributed data stream snapshots, which are lightweight and have little impact on performance. The state is saved in a configurable environment, master node or HDFS. In case of program failure (machine, network, software, etc.), the system restarts all operator s and resets to the recently successful checkpoint. Input reset to the corresponding state snapshot position to ensure that any record processed in the restarted parallel data stream is not part of the checkpoint state.
For the fault tolerance mechanism to work, the data source (message queue or broker) needs to be able to replay the data flow. Such as Flink Kafka connector
Paper: Lightweight Asynchronous Snapshots for Distributed Dataflows https://arxiv.org/abs/1506.08603 This paper describes the mechanism of creating snapshots by flink.
This paper is based on distributed snapshot algorithm
checkpoint&savepoints
Conceptually speaking: Savepoint is the backup of traditional databases, and Checkpoint is the method of restoring logs
● Flink is responsible for reallocating state across parallel instances
● watermark
● barriers
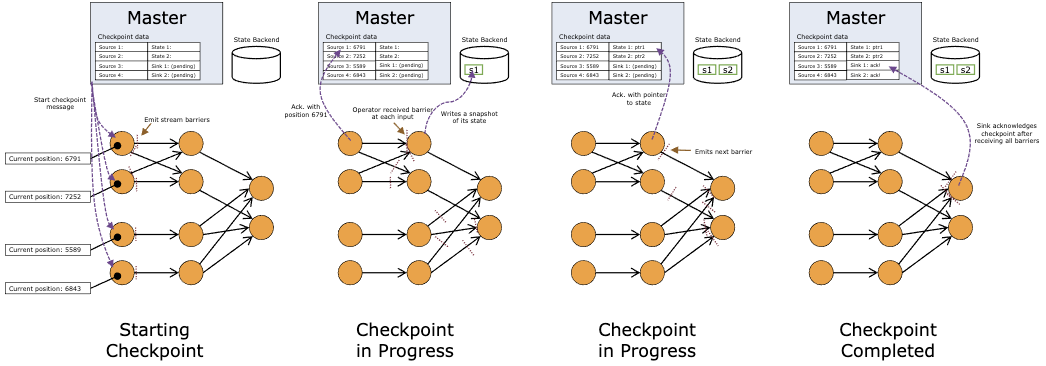
The barrier is inserted into the data stream, flows with the data, and divides the data stream into two parts, one into the current snapshot and the other into the next snapshot. At the same time, the barrier carries the snapshot ID. Multiple barriers of multiple different snapshots will appear at the same time, that is, multiple snapshots may be created at the same time.
● element storage
What is state?
● simple understanding:
Streaming computing data is fleeting. Real scenes often need previous "data", so these required "data" are called state. Also called status.
After the original data enters the user code, it is output to the downstream. If the read-write of state is involved, these States will be stored in the local state backend.
● detailed explanation:
state refers to the intermediate calculation result or metadata attribute of the calculation node during flow calculation.
For example:
○ intermediate aggregation results in the aggregation process.
○ read the offset of the record during data consumption kafka.
○ the operator contains any form of state, which must be included in the snapshot. There are many forms of state:
■ user defined - the state directly created or modified by the transformation function (such as map() or filter()). The user-defined state can be a simple variable of the Java object in the transformation function or the key/value state associated with the function.
■ system status: this status refers to the cached data as part of the operator calculation. A typical example is window buffers, in which the system collects the data corresponding to the window until the window is calculated and transmitted.
Summary: snapshot of internal data (calculated data and metadata attributes) of the flick task.
● State generally refers to the State of a specific task/operator.
Checkpoint represents a Flink Job and a global state snapshot at a specific time, that is, it contains the states of all tasks / operators.
The saving mechanism is statebackend. By default, the State is saved in the memory of TaskManager and the CheckPoint is stored in the memory of JobManager.
The storage location of State and CheckPoint depends on the configuration of StateBackend. Memory based MemoryStateBackend, file system based FsStateBackend, rocksdbstate backend based on RockDB storage media
state definition:
Defined according to state descriptor
The StateTtlConfiguration object is passed to the state descriptor to clean up the state.
● define ttl (Time to Live)
● state lifetime
● state lifetime
state classification:
● does it belong to a key
○ key state: keyedStream save state
○ operator state: normal non key save state
● is it managed by flink
○ raw state: the application manages itself
○ manage state: flink management
● KeyedState
The key here is the field in the corresponding groupby/PartitionBy in the SQL statement. The value of the key is the byte array of the Row composed of the groupby/PartitionBy field. Each key has its own State, and the State between the key and the key is invisible;
● OperatorState
In the implementation of Source Connector inside Flink, OperatorState will be used to record the offset read from source data.
| KeyedState | OperatorState | |
|---|---|---|
| Whether there is a currently processed key (current key) | nothing | current key exists |
| Whether the storage object is on heap | There is only one on heap implementation | There are multiple implementations of on heap and off heap (rocksdb) |
| Do I need to declare snapshot and restore manually | Manual implementation | It is implemented by backend and is transparent to users |
| data size | Generally small scale | Generally large scale |
KeyedState OperatorState
Whether there is a currently processed key (current key) no current key
Is there only one on heap implementation for storage objects? There are multiple implementations of on heap and off heap (rocksdb)
Whether it is necessary to manually declare that the manual implementation of snapshot and restore is implemented by backend, which is transparent to users
The data size is generally small and generally large
After receiving all the barriers in the input data stream, the operator takes a snapshot of the state of the barrier before transmitting it to its output stream. At this time, the data before the barrier has updated the state and will no longer rely on the data before the barrier. Because the snapshot may be very large, the back-end storage system can be configured. By default, it is stored in the memory of JobManager, However, the production system needs to be configured as a reliable distributed storage system (such as HDFS). After the state storage is completed, the operator will confirm that its checkpoint is completed and send out the barrier to the subsequent output stream.
The snapshot now contains:
1. For parallel input data sources: the position offset in the data stream when the snapshot is created
2. For operator: the state pointer stored in the snapshot
state create (write):
● blink operates the code – > tasks (placed in taskmanager) - > each task contains an abstract class AbstractInvokable - > the main function of task is to call AbstractInvokable.invoke() – > there are five implementations of this abstract method

● the corresponding implementations in streaming processing are inherited from StreamTask - > the StreamTask abstract class contains the invoke() method (about 150 lines of code) - > call run()
Runnable interface – > processinput (actioncontext) – > inputprocessor. Processinput(): this method completes the processing of user input data (user data, watermark, checkpoint data) -- > streamOperator. Processelement (record): streamOperator processes data

StreamOneInputProcessor—>streamOperator.processElement(record);
● StreamTask:
Define the complete lifecycle,
protected abstract void init() throws Exception;
private void run() throws Exception {};
protected void cleanup() throws Exception {};
protected void cancelTask() throws Exception {};
Example: OneInputStreamTask (processing an input case)
Taskmanage - > start task - > Task - > implement Runnable interface run() --- > dorun(): 320 lines of code to create invokable objects (reflection – > get classes – > get construction methods – > instantiate objects)
private static AbstractInvokable loadAndInstantiateInvokable(
ClassLoader classLoader, String className, Environment environment) throws Throwable {
final Class<? extends AbstractInvokable> invokableClass;
try {
// Use the specified classloader to load the class corresponding to the className and convert it to AbstractInvokable type
invokableClass =
Class.forName(className, true, classLoader).asSubclass(AbstractInvokable.class);
} catch (Throwable t) {
throw new Exception("Could not load the task's invokable class.", t);
}
Constructor<? extends AbstractInvokable> statelessCtor;
try {
// Get constructor
statelessCtor = invokableClass.getConstructor(Environment.class);
} catch (NoSuchMethodException ee) {
throw new FlinkException("Task misses proper constructor", ee);
}
// instantiate the class
try {
//noinspection ConstantConditions --> cannot happen
// Pass in the environment variable to create a new object
return statelessCtor.newInstance(environment);
} catch (InvocationTargetException e) {
// directly forward exceptions from the eager initialization
throw e.getTargetException();
} catch (Exception e) {
throw new FlinkException("Could not instantiate the task's invokable class.", e);
}
}
– invoke()
|
±—> Create basic utils (config, etc) and load the chain of operators
±—> operators.setup()
±—> task specific init()
±—> initialize-operator-states() : initializeState();
±—> open-operators()
±—> run()
±—> close-operators()
±—> dispose-operators()
±—> common cleanup
±—> task specific cleanup()
● Flink StreamTask thread model based on MailBox implementation
Let's take a look at the original motivation of this transformation / improvement. In the previous Flink thread model, there will be multiple potential threads to access their internal states concurrently, such as event processing and checkpoint triggering. They all ensure thread safety through a checkpoint lock. The problems caused by this implementation scheme are:
○ the lock object will be passed in multiple classes, and the readability of the code is poor
○ if the lock is not obtained during use, many problems may be caused, making it difficult to locate the problem
○ the lock object is also exposed to the user oriented API (see SourceFunction#getCheckpointLock())
MailBox design document:

Create state
The parameter passing abstract class StateDescriptor - > 5 sub class implementation can see that the final state does not limit the state type, operatorstate & keystate
method comes from RichFunction and belongs to the basic interface of rich function, which specifies the RuntimeContext
public interface RichFunction extends Function {
void open(Configuration parameters) throws Exception;
void close() throws Exception;
RuntimeContext getRuntimeContext();
IterationRuntimeContext getIterationRuntimeContext();
void setRuntimeContext(RuntimeContext t);
}
RuntimeContext interface - > Abstract implementation class AbstractRuntimeUDFContext - > implementation class StreamingRuntimeContext
Based on the streamingruntimecontext (other implementation classes are consistent in the end), the getState(ValueStateDescriptor stateProperties) method cuts in:
public <T> ValueState<T> getState(ValueStateDescriptor<T> stateProperties) {
// Check the work, determine whether it is null, and finally operate the keyedStateStore property, but the local variable takes the reference address again
KeyedStateStore keyedStateStore = this.checkPreconditionsAndGetKeyedStateStore(stateProperties);
// Initialize serializer
stateProperties.initializeSerializerUnlessSet(this.getExecutionConfig());
return keyedStateStore.getState(stateProperties);
}
private KeyedStateStore checkPreconditionsAndGetKeyedStateStore(StateDescriptor<?, ?> stateDescriptor) {
// Check that the stateDescriptor cannot be null. The parameter is passed from the beginning to this point
Preconditions.checkNotNull(stateDescriptor, "The state properties must not be null");
// The global variable (property, field) keyedStateStore of the class itself cannot be null
Preconditions.checkNotNull(this.keyedStateStore, "Keyed state can only be used on a 'keyed stream', i.e., after a 'keyBy()' operation.");
return this.keyedStateStore;
}
Keyed state can only be used on a 'keyed stream', i.e., after a 'keyBy()' operation.
The method judged to be null will be frequently referenced inside the flink. The StreamingRuntimeContext statically imports this method, so it can be called directly. You can learn about it:
public static <T> T checkNotNull(@Nullable T reference, @Nullable String errorMessage) {
if (reference == null) {
throw new NullPointerException(String.valueOf(errorMessage));
} else {
return reference;
}
}
It should be noted here that if the property keyedStateStore of StreamingRuntimeContext itself is null, a null pointer exception will be thrown. How to load negative values for this property? See the name for the function of this property, which is related to the storage of state. Next, we'll study it
Here is a key point. This class constructor accepts an abstractstreamoperator <? > Operator, the keyedStateStore field is initialized to operator.getKeyedStateStore(). From this, we can probably draw a conclusion that the acquisition of state is related to the operator (such as map, flatMap),
@VisibleForTesting
public StreamingRuntimeContext(AbstractStreamOperator<?> operator, Environment env, Map<String, Accumulator<?, ?>> accumulators) {
this(env, accumulators, operator.getMetricGroup(), operator.getOperatorID(), operator.getProcessingTimeService(), operator.getKeyedStateStore(), env.getExternalResourceInfoProvider());
}
public StreamingRuntimeContext(Environment env, Map<String, Accumulator<?, ?>> accumulators, MetricGroup operatorMetricGroup, OperatorID operatorID, ProcessingTimeService processingTimeService, @Nullable KeyedStateStore keyedStateStore, ExternalResourceInfoProvider externalResourceInfoProvider) {
super(((Environment)Preconditions.checkNotNull(env)).getTaskInfo(), env.getUserCodeClassLoader(), env.getExecutionConfig(), accumulators, env.getDistributedCacheEntries(), operatorMetricGroup);
this.taskEnvironment = env;
this.streamConfig = new StreamConfig(env.getTaskConfiguration());
this.operatorUniqueID = ((OperatorID)Preconditions.checkNotNull(operatorID)).toString();
this.processingTimeService = processingTimeService;
this.keyedStateStore = keyedStateStore;
this.externalResourceInfoProvider = externalResourceInfoProvider;
}
keyedStateStore is equivalent to operator.getKeyedStateStore(), and the operator is controlled by abstractstreamoperator <? > Operator creation
AbstractStreamOperator
public final void initializeState(StreamTaskStateInitializer streamTaskStateManager) throws Exception {
TypeSerializer<?> keySerializer = this.config.getStateKeySerializer(this.getUserCodeClassloader());
StreamTask<?, ?> containingTask = (StreamTask)Preconditions.checkNotNull(this.getContainingTask());
CloseableRegistry streamTaskCloseableRegistry = (CloseableRegistry)Preconditions.checkNotNull(containingTask.getCancelables());
StreamOperatorStateContext context = streamTaskStateManager.streamOperatorStateContext(this.getOperatorID(), this.getClass().getSimpleName(), this.getProcessingTimeService(), this, keySerializer, streamTaskCloseableRegistry, this.metrics, this.config.getManagedMemoryFractionOperatorUseCaseOfSlot(ManagedMemoryUseCase.STATE_BACKEND, this.runtimeContext.getTaskManagerRuntimeInfo().getConfiguration(), this.runtimeContext.getUserCodeClassLoader()), this.isUsingCustomRawKeyedState());
this.stateHandler = new StreamOperatorStateHandler(context, this.getExecutionConfig(), streamTaskCloseableRegistry);
this.timeServiceManager = context.internalTimerServiceManager();
this.stateHandler.initializeOperatorState(this);
// Here, setKeyedStateStore is to modify the value of StreamingRuntimeContext.keyedStateStore
this.runtimeContext.setKeyedStateStore((KeyedStateStore)this.stateHandler.getKeyedStateStore().orElse((Object)null));
}
keyedStateStore - > is created by StreamOperatorStateHandler
public StreamOperatorStateHandler(StreamOperatorStateContext context, ExecutionConfig executionConfig, CloseableRegistry closeableRegistry) {
this.context = context;
this.operatorStateBackend = context.operatorStateBackend();
this.keyedStateBackend = context.keyedStateBackend();
this.closeableRegistry = closeableRegistry;
if (this.keyedStateBackend != null) {
// keyedStateStore created
this.keyedStateStore = new DefaultKeyedStateStore(this.keyedStateBackend, executionConfig);
} else {
this.keyedStateStore = null;
}
}
Summary: that is, the status backend does not exist, that is, the default is generated, and it is empty for the first time.
You may wonder when and by whom initializeState was called
It comes from the operator chain. Flex will merge multiple operators that meet the conditions into an operator chain. Then, when scheduling, a task actually executes an operator chain. When multiple parallelism degrees, multiple tasks each execute an operator chain
Abstract parent classabstractinvokable - > Abstract subclass StreamTask - > invoke() - > initializestate(); openAllOperators();
initializeState();
private void initializeState() throws Exception {
StreamOperator<?>[] allOperators = operatorChain.getAllOperators();
for (StreamOperator<?> operator : allOperators) {
if (null != operator) {
operator.initializeState();
}
}
}
openAllOperators();
private void openAllOperators() throws Exception {
for (StreamOperator<?> operator : operatorChain.getAllOperators()) {
if (operator != null) {
operator.open();
}
}
}
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
This function call actually comes to the StateDescriptor. I saw that all States are subclasses before
Method: initializes the serializer unless it has been initialized before
//Type information describing the value type. Used only when the serializer is created lazily.
private TypeInformation<T> typeInfo;
//Serializer of type. It may be eagerly initialized in the constructor or lazily initialized once
public boolean isSerializerInitialized() {
return serializerAtomicReference.get() != null;
}
public void initializeSerializerUnlessSet(ExecutionConfig executionConfig) {
// First, judge whether the serializer has been created. The class code is relatively simple, as shown below,
// As seen above, if the default constructor is called, the value field of the object is null, and the first code here must be null
if (serializerAtomicReference.get() == null) {
// Determine whether typeInfo is null. Here is the code analysis constructor
checkState(typeInfo != null, "no serializer and no type info");
// Try to instantiate and set the serializer. In this case, the type is used to create the serializer. You can see that each time the logic executes, a serializer will be created
TypeSerializer<T> serializer = typeInfo.createSerializer(executionConfig);
// use cas to assure the singleton
// cas is used to guarantee the singleton. Here is the creation core. compareAndSet is analyzed below
if (!serializerAtomicReference.compareAndSet(null, serializer)) {
LOG.debug("Someone else beat us at initializing the serializer.");
}
}
}
state clear
Why do I need to clear state?
● state timeliness: it is effective within a certain period of time. Once a certain time point has passed, it has no application value
● control the size of flink state: manage the growing size of state
How to define state clearing?
flink1.6 introduces the State TTL function. Developers configure the expiration time and clear it after defining the Time to Live,
The StateTtlConfiguration object is passed to the state descriptor to clean up the state.
Continuously clean up the historical data of RocksDB and heap state backend (FSStateBackend and MemoryStateBackend), so as to realize the continuous cleaning of expired states
Sample code
public class StateDemo {
public static void main(String[] args) throws Exception {
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 10L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new MyFlatMapFunction())
.print();
// the printed output will be (1,4) and (1,5)
env.execute();
}
}
class MyFlatMapFunction extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private static final long serialVersionUID = 1808329479322205953L;
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
// Status expiration cleanup
// The status cleaning of flink is an inert policy, that is, the status we access may have expired, but the status data has not been deleted. We can configure it
// Whether to return expired data. Whether to return expired data or not, the expired status will be cleared immediately after the data is accessed. And as of version 1.8.0
// Status clearing is for process time. event time is not supported yet. It may be supported in later versions.
// The internal state ttl function of flink is realized through the additional timestamp and actual state value of the last relevant state access. Such a scheme will increase the storage
// But it will allow the flink program to access the expiration status of the data when querying the data and cp
StateTtlConfig ttlConfig =
StateTtlConfig.newBuilder(Time.days(1)) //It is the lifetime value
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//State visibility configures whether expired values are returned on read access
// .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot() // Delete at snapshot time
.build();
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
//Set stage expiration time
descriptor.enableTimeToLive(ttlConfig);
sum = getRuntimeContext().getState(descriptor);
}
}
Core code
StateTtlConfig ttlConfig =
StateTtlConfig.newBuilder(Time.days(1)) //It is the lifetime value
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//State visibility configures whether expired values are returned on read access
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
.cleanupFullSnapshot() // Delete at snapshot time
.build();
flink 1.9
private StateTtlConfig(
UpdateType updateType,
StateVisibility stateVisibility,
TtlTimeCharacteristic ttlTimeCharacteristic,
Time ttl,
CleanupStrategies cleanupStrategies) {
this.updateType = checkNotNull(updateType);
this.stateVisibility = checkNotNull(stateVisibility);
this.ttlTimeCharacteristic = checkNotNull(ttlTimeCharacteristic);
this.ttl = checkNotNull(ttl);
this.cleanupStrategies = cleanupStrategies;
checkArgument(ttl.toMilliseconds() > 0, "TTL is expected to be positive.");
}
● .newBuilder()
: indicates the state expiration time. Once set, the last access timestamp + TTL exceeds the current time, and the flag State expires
Specific implementation:
https://ci.apache.org/projects/flink/flink-docs-master/api/java/org/apache/flink/runtime/state/ttl/class-use/TtlTimeProvider.html
●. setUpdateType() can see the source code
setUpdateType(StateTtLConfig.UpdateType.OnCreateAndWrite)
Indicates the update time of the status timestamp. It is an Enum object.
○ Disabled, it indicates that the timestamp is not updated;
○ OnCreateAndWrite, it indicates that the timestamp will be updated when the status is created or written each time;
○ OnReadAndWrite, in addition to updating the timestamp when the status is created and written, reading will also update the timestamp of the status.
● .setStateVisibility()
Indicates how to handle the expired but not cleaned up status. It is also an Enum object.
○ ReturnExpiredlfNotCleanedUp, even if the timestamp of this status indicates that it has expired, it will be returned to the caller as long as it has not been really cleaned up;
○ NeverReturnExpired, once the status expires, it will never be returned to the caller, only the empty status will be returned, avoiding the interference caused by the expired status.
● .setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
TimeCharacteristic and TtlTimeCharacteristic: indicates the time mode applicable to the State TTL function, which is still an Enum object.
The former has been marked deprecated. It is recommended that the new code adopt the new TtlTimeCharacteristic parameter.
As of Flink 1.8, only ProcessingTime is supported, and the State TTL support for EventTime mode is still under development. (see 1.9, which also only supports processing time)
flink time concept
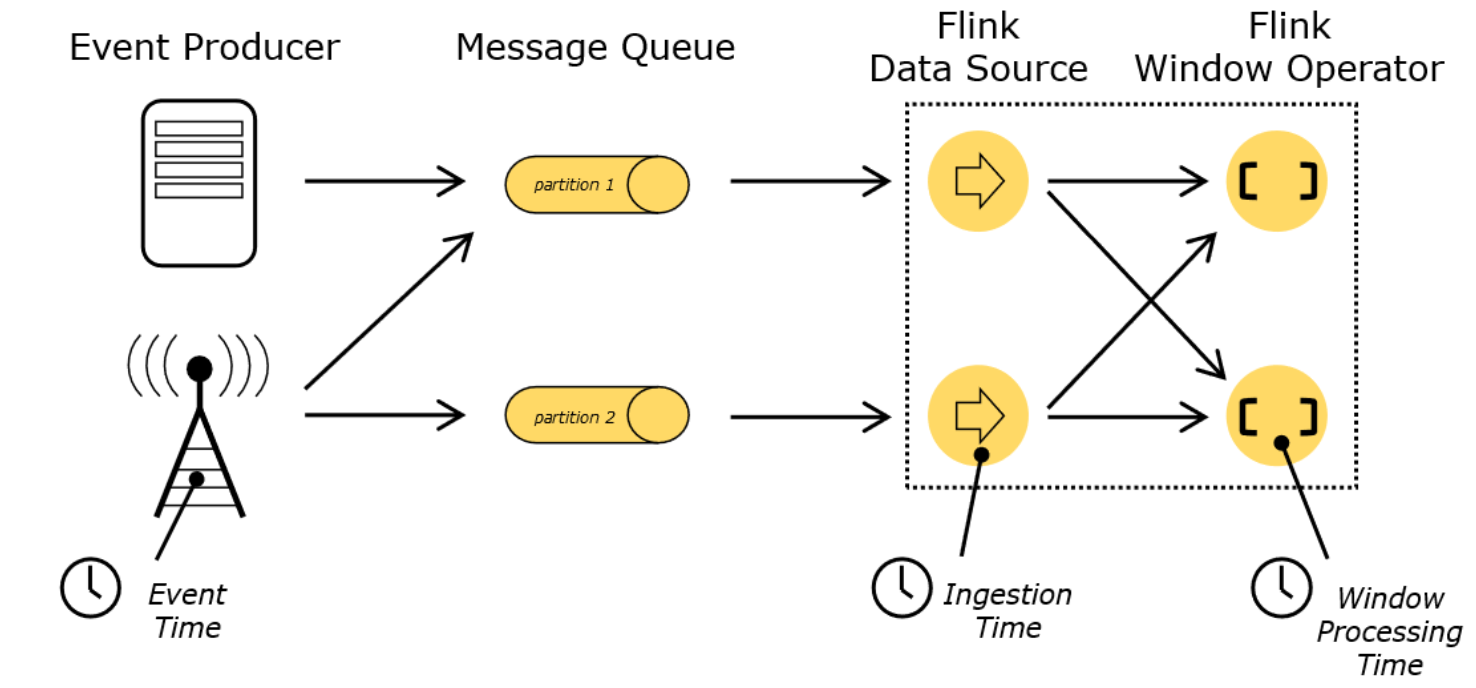
○ EventTime: event creation time
○ Processing Time: the local system time when the data flows to each time-based operator; default
○ Ingestion Time: the time when the data enters the flick
●. cleanupFullSnapshot(): see the source code
Represents the cleaning policy for expired objects. Currently, there are three Enum values.
○ FULL_STATE_SCAN_SNAPSHOT: corresponds to the EmptyCleanupStrategy class, which means that the expired status is not actively cleaned up. When a full snapshot (Snapshot / Checkpoint) is executed, a small status file will be generated, but the local status will not be reduced. Only when the job is restarted and restored from the previous snapshot point, the local state will actually decrease, so the problem of memory pressure may still not be solved.
In order to solve the memory pressure problem, Flink also provides the enumeration value of incremental cleaning. Flink can be configured to perform a cleaning operation every time several records are read, and can specify how many invalid records to clean each time:
○ INCREMENTAL_CLEANUP: for Heap StateBackend
○ ROCKSDB_COMPACTION_FILTER (obsolete in 1.9) is for RocksDB StateBackend. For RocksDB state cleanup, it is implemented by JNI calling flickcomparationfilter written in C + + language. The bottom layer is to filter the invalid state through the background comparison operation provided by RocksDB.
common problem:
● is past status data accessible?
Status expiration clearing: the status clearing of flick is an inert strategy, that is, the status we access may have expired, but the status data has not been deleted. We can configure whether to return the expired data, no matter whether to return the expired data. The expired status will be cleared immediately after the data is accessed.
Within Flink, the status TTL function is realized by storing the additional timestamp and actual status value of the last relevant status access. Although this method increases some storage overhead, it allows Flink programs to access the expired state of data when querying data, checkpointing and data recovery.
It is worth noting that:
As of version 1.8.0, the status is cleared for process time and does not support event time. Users can only define the status TTL according to the Processing Time. Event time is planned to be supported in future versions of Apache Flink
● how to avoid reading expired data?
When a state object is accessed during a read operation, Flink checks its timestamp and clears whether the state has expired (depending on the configured state visibility, whether the expired state is returned). Due to this delayed deletion feature, expired status data that will never be accessed again will always occupy storage space unless it is garbage collected.
So how to delete expired status without application logic explicitly handling it? Usually, we can configure different policies for background deletion.
○ full snapshots automatically delete expired status
○ incremental cleanup of the back end of the heap state
○ RocksDB background compression can filter out expired status
○ use Timers to delete
state storage implementation?
How Flink saves state data has an interface StateBackend - > abstract class AbstractStateBackend, which has three implementations
● MemoryStateBackend, memory based HeapStateBackend
It is used in debug mode and is not recommended to be applied in production mode
● FsStateBackend based on HDFS
For distributed file persistence, the memory is manipulated every time you read and write, and the OOM problem needs to be considered
● RocksDBStateBackend based on RocksDB
Local file + Remote HDFS persistence
The default is StateBackendLoader, which loads RocksDBStateBackend
State stored procedure
Two stages
- Store locally to RocksDB first
- Asynchronous synchronization to remote HDFS
Purpose: it not only eliminates the limitations of HeapStateBackend (memory size, machine failure, loss, etc.), but also reduces the network IO overhead of pure distributed storage.
summary
That's what I'm going to talk about today.