preface
Python is a great language. It is one of the fastest growing programming languages in the world. Again and again, it has proven its usefulness in developer positions and cross industry data science positions. The entire ecosystem of Python and its libraries makes it a suitable choice for users (beginners and advanced users) around the world. One of the reasons for its success and popularity is its powerful collection of third-party libraries, which enable it to remain dynamic and efficient.
In this article, we will study some Python libraries for data science tasks, rather than common libraries such as panda, scikit learn and matplotlib. Although libraries such as panda and scikit learn often appear in machine learning tasks, it is always beneficial to understand other Python products in this field.
1, Wget
Extracting data from the network is one of the important tasks of data scientists. WGet is a free utility that can be used to download non interactive files from the network. It supports HTTP, HTTPS and FTP protocols, as well as file retrieval through HTTP proxy. Because it is non interactive, it can work in the background even if the user does not log in. So the next time you want to download all the pictures on a website or page, WGet can help you.
Installation:
$ pip install wget
example:
import wgeturl = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'filename = wget.download(url)100% [................................................] 3841532 / 3841532filename'razorback.mp3'### Pendulum
2, Pendulum
For those who feel frustrated when dealing with dates and times in Python, Pendulum is perfect for you. It is a python package that simplifies date and time operations. It is a simple alternative to Python's native classes. Refer to the documentation for further study.
Installation:
$ pip install pendulum
example:
import pendulumdt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')print(dt_vancouver.diff(dt_toronto).in_hours())3
3, Imbalanced learn
It can be seen that when the number of samples of each class is basically the same, the effect of most classification algorithms is the best, that is, it is necessary to maintain data balance. However, most of the real cases are unbalanced data sets, which have a great impact on the learning stage and subsequent prediction of machine learning algorithm. Fortunately, this library is used to solve this problem. It is compatible with scikit learn and is part of the scikit learn contrib project. The next time you encounter an unbalanced dataset, try using it.
Installation:
pip install -U imbalanced-learn#Or conda # install - c # conda forge # balanced learn
example:
Please refer to the documentation for usage methods and examples.
4, FlashText
In NLP tasks, cleaning up text data often requires replacing keywords in sentences or extracting keywords from sentences. Usually, this can be done using regular expressions, but it becomes troublesome if the number of terms to search reaches thousands. Python's FlashText module is based on the FlashText algorithm, which provides a suitable alternative to this situation. The best thing about FlashText is that the running time is the same regardless of the number of search terms. You can learn more here.
Installation:
$ pip install flashtext
example:
Extract keywords
from flashtext import KeywordProcessorkeyword_processor = KeywordProcessor()# keyword_processor.add_keyword(<unclean name>, <standardised name>)keyword_processor.add_keyword('Big Apple', 'New York')keyword_processor.add_keyword('Bay Area')keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')keywords_found['New York', 'Bay Area']Replace keyword
keyword_processor.add_keyword('New Delhi', 'NCR region')new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')new_sentence'I love New York and NCR region.'Fuzzywuzzy5, Fuzzy wuzzy
The name of this library sounds strange, but fuzzy wuzzy is a very useful library for string matching. It is convenient to calculate string matching degree and token matching degree, and it is also convenient to match the records saved in different databases.
Installation:
$ pip install fuzzywuzzy
example:
from fuzzywuzzy import fuzzfrom fuzzywuzzy import process# Simple matching degree fuzz.ratio("this is a test", "this is a test!")97#Fuzzy matching degree partial_ ratio("this is a test", "this is a test!") 100More interesting examples can be found in the GitHub warehouse.
6, PyFlux
Time series analysis is one of the most common problems in the field of machine learning. PyFlux is an open source library in Python, which is built to deal with time series problems. The library has a series of excellent modern time series models, including but not limited to ARIMA, GARCH and VAR models. In short, PyFlux provides a probabilistic method for time series modeling. It's worth trying.
install
pip install pyflux
example
Please refer to the official documents for detailed usage and examples.
7, Ipyvolume
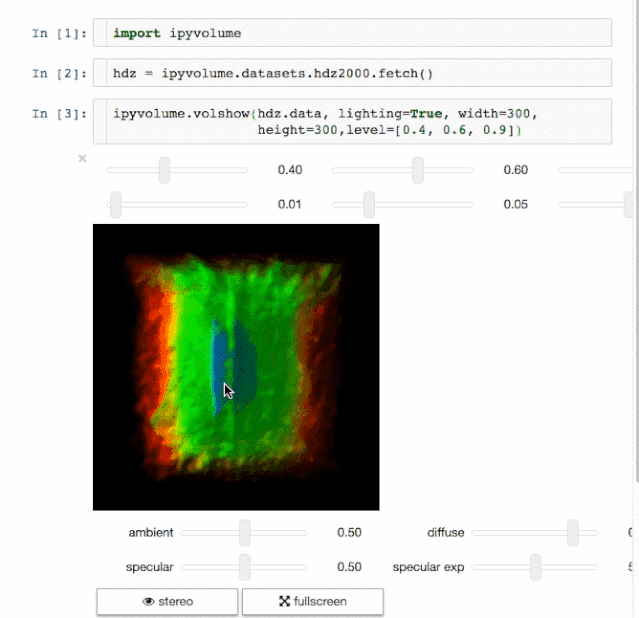
Result presentation is also an important aspect of data science. The ability to visualize the results will have great advantages. IPyvolume is a 3D volume and graph that can be visualized in Jupyter notebook (such as three-dimensional scatter diagram, etc.) and only a small amount of configuration is required. However, it is still in the version before 1.0. A more appropriate metaphor is that the volshow of IPyvolume is as good for three-dimensional arrays as the imshow of matplotlib is for two-dimensional arrays. You can get more information here.
Using pip
$ pip install ipyvolume
Use Conda/Anaconda
$ conda install -c conda-forge ipyvolume
example
- animation
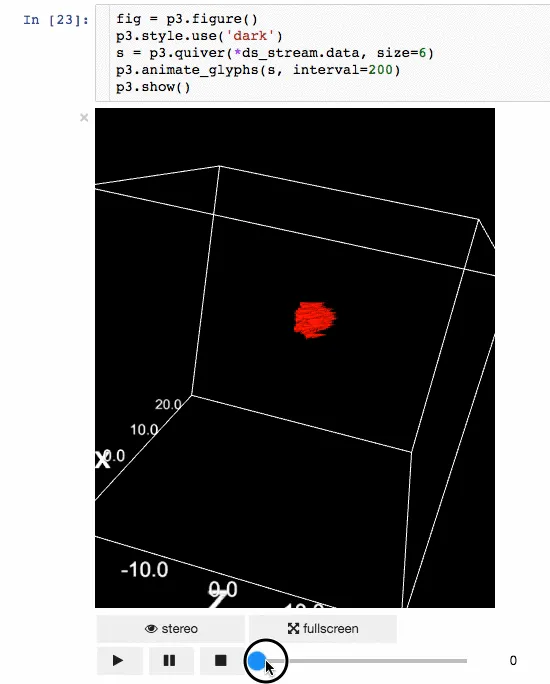
- Volume rendering
8, Dash
Dash is an efficient Python framework for building web applications. It's in Flask, plot JS and react JS, which is bound with many modern UI elements such as drop-down boxes, sliding bars and charts. You can directly use Python code to write relevant analysis without using javascript. Dash is ideal for building data visualization applications. These applications can then be rendered in a web browser. The user guide is available here.
install
pip install dash==0.29.0 # core dash back-end pip install dash-html-components==0.13.2 # HTML assembly pip install dash-core-components==0.36.0 # Enhancement component pip install dash-table==3.1.3 #Interactive DataTable component (latest!)
Example the following example shows a highly interactive chart with a drop-down function. When the user selects a value in the drop-down menu, the application code will dynamically export the data from Google Finance to panda DataFrame.
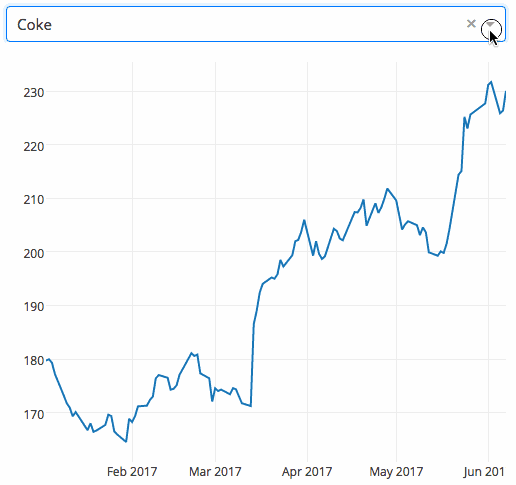
9, Gym
Gym of OpenAI is a toolkit for the development and comparison of reinforcement learning algorithms. It is compatible with any numerical calculation library, such as TensorFlow or Theano. The gym library is an essential tool for testing problem sets, also known as environments - you can use it to develop your reinforcement learning algorithms. These environments have a shared interface that allows you to write general algorithms.
install
pip install gym
Example this example will run an instance in the CartPole-v0 environment. Its time steps are 1000, and each step will render the whole scene.
summary
The above useful data science Python libraries are carefully selected by me, not common libraries such as numpy and pandas. If you know other libraries that can be added to the list, please mention them in the comments below. Also, don't forget to try running them first.