Based on lucene 8
1 Lucene Brief Introduction
Lucene is an open source full-text search engine toolkit under apache.
1.1 Full-text Search
Full-text retrieval is the process of creating index by participle and then performing search. Word segmentation is to divide a paragraph of text into words. Full-text retrieval divides a paragraph of text into words to query data.
1.2 The Process of Full Text Retrieval by Lucene
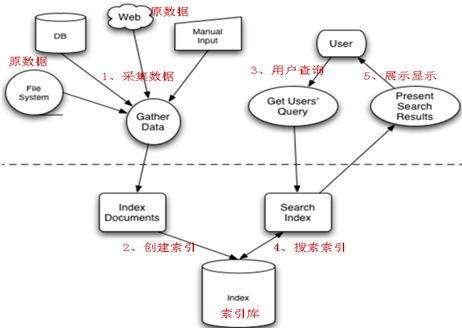
The process of full-text retrieval is divided into two parts: index process and search process.
- Index process: data collection - > Document Object Construction - > index creation (document writing to index library).
- Search process: Create query - > Execute search - > Render search results.
2 Introduction Examples
2.1 Demand
Lucene is used to realize the indexing and searching functions of books in e-commerce projects.
2.2 Configuration steps
- Setting up the Environment
- Creating Index Library
- Search index database
2.3 Configuration steps
2.3.1 Part 1: Build Environment (Create Project, Import Package)
2.3.2 Part 2: Creating Index
Statement of steps:
- Data acquisition
- Converting data into Lucene documents
- Write documents into index libraries to create indexes
2.3.2.1 Step 1: Data acquisition
Lucene full-text retrieval is not a direct query of the database, so it is necessary to collect the data first.
package jdbc.dao;
import jdbc.pojo.Book;
import jdbc.util.JdbcUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class BookDao {
public List<Book> listAll() {
//Create collections
List<Book> books = new ArrayList<>();
//Get the database connection
Connection conn = JdbcUtils.getConnection();
String sql = "SELECT * FROM `BOOK`";
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//Get precompiled statements
preparedStatement = conn.prepareStatement(sql);
//Get the result set
resultSet = preparedStatement.executeQuery();
//Result Set Analysis
while (resultSet.next()) {
books.add(new Book(resultSet.getInt("id"),
resultSet.getString("name"),
resultSet.getFloat("price"),
resultSet.getString("pic"),
resultSet.getString("description")));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//close resource
if (null != resultSet) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (null != conn) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
}
}
return books;
}
}Step 2.3.2.2: Converting data into Lucene documents
Lucene uses document type to encapsulate data, all of which need to be converted into document type first. Its format is:
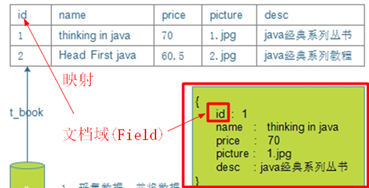
Modify BookDao, add a new method to convert data
public List<Document> getDocuments(List<Book> books) {
//Create collections
List<Document> documents = new ArrayList<>();
//Loop operation books collection
books.forEach(book -> {
//To create Document objects, you need to set one Field object in Document
Document doc = new Document();
//Create individual fields
Field id = new TextField("id", book.getId().toString(), Field.Store.YES);
Field name = new TextField("name", book.getName(), Field.Store.YES);
Field price = new TextField("price", book.getPrice().toString(), Field.Store.YES);
Field pic = new TextField("id", book.getPic(), Field.Store.YES);
Field description = new TextField("description", book.getDescription(), Field.Store.YES);
//Add Field to the document
doc.add(id);
doc.add(name);
doc.add(price);
doc.add(pic);
doc.add(description);
documents.add(doc);
});
return documents;
}2.3.2.3 Step 3: Create an index library
Lucene automatically participles and creates indexes in the process of writing documents into index libraries. So to create an index library, formally speaking, is to write documents into the index library!
package jdbc.test;
import jdbc.dao.BookDao;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.io.File;
import java.io.IOException;
public class LuceneTest {
/**
* Creating Index Library
*/
@Test
public void createIndex() {
BookDao dao = new BookDao();
//The word segmenter is used for character-by-character word segmentation.
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
//Create an index
//1. Create Index Inventory Catalogue
try (Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath())) {
//2. Create IndexWriterConfig objects
IndexWriterConfig ifc = new IndexWriterConfig(standardAnalyzer);
//3. Create IndexWriter objects
IndexWriter indexWriter = new IndexWriter(directory, ifc);
//4. Adding documents through IndexWriter objects
indexWriter.addDocuments(dao.getDocuments(dao.listAll()));
//5. Close IndexWriter
indexWriter.close();
System.out.println("Complete index library creation");
} catch (IOException e) {
e.printStackTrace();
}
}
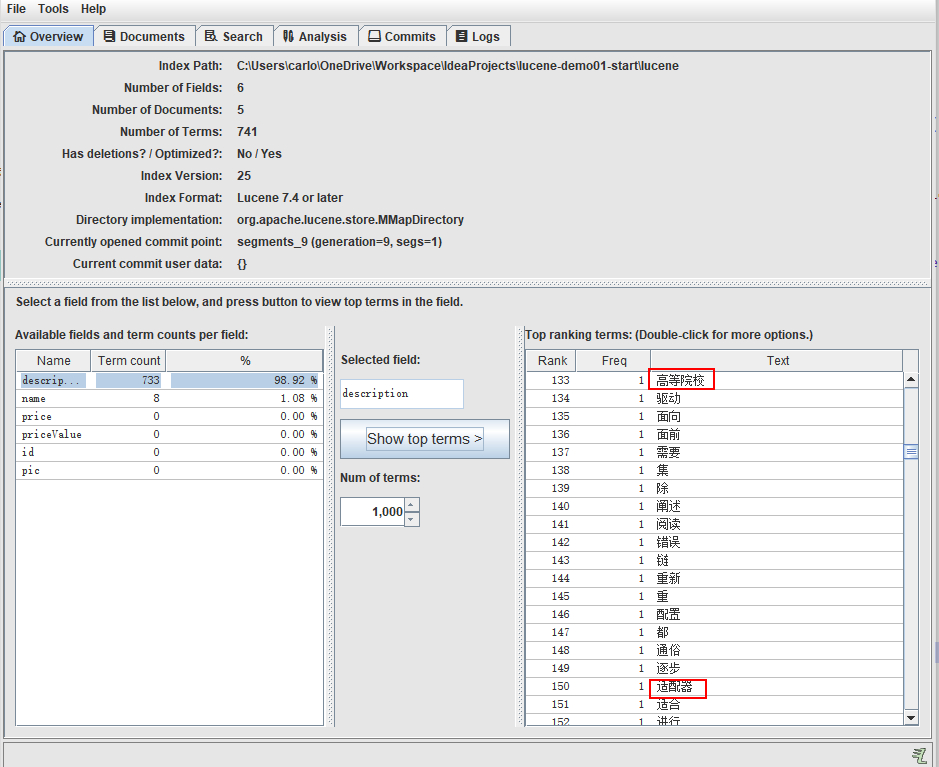
}You can view the results through the luke tool
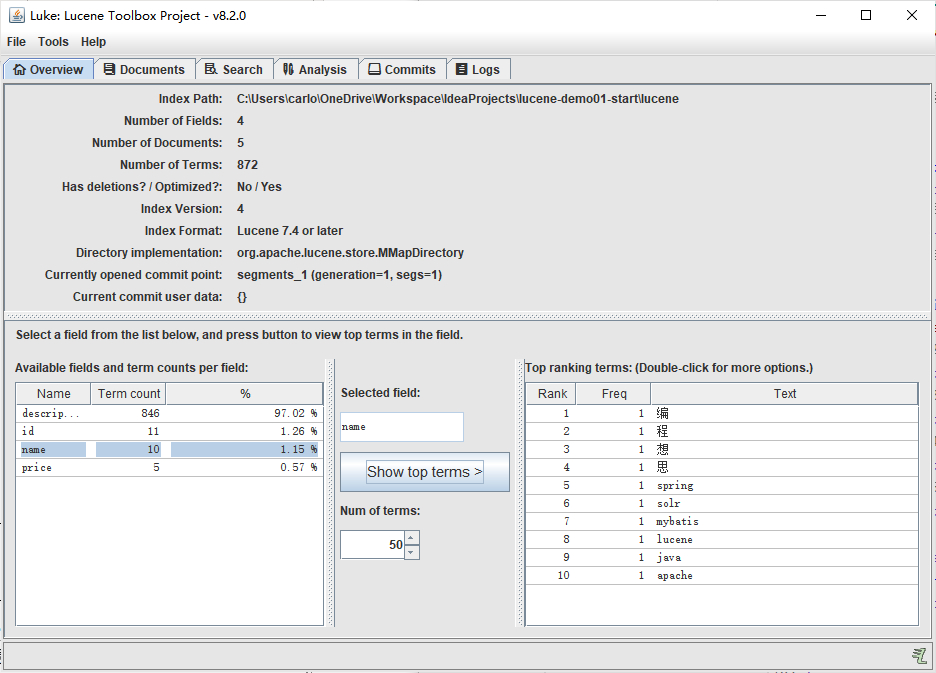
2.3.3 Part 3: Search Index
2.3.3.1 Note
When searching, we need to specify which domain to search (that is, field), and we also need to segment the search keywords.
2.3.3.2 Execute Search
@Test
public void searchTest() {
//1. Create queries (Query objects)
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
// Parameter 1 specifies the search Field
QueryParser queryParser = new QueryParser("name", standardAnalyzer);
try {
Query query = queryParser.parse("java book");
//2. Perform search
//a. Designated index Library Directory
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//b. Create IndexReader objects
IndexReader reader = DirectoryReader.open(directory);
//c. Create IndexSearcher objects
IndexSearcher searcher = new IndexSearcher(reader);
/**
* d. Query the index library through the IndexSearcher object and return the TopDocs object
* Parametric 1: Query object
* Parametric 2: The first n data
*/
TopDocs topDocs = searcher.search(query, 10);
//e. Extracting query results from TopDocs objects
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("The number of query results is:" + topDocs.totalHits);
//Loop Output Data Object
for (ScoreDoc scoreDoc : scoreDocs) {
//Get the document object id
int docId = scoreDoc.doc;
//Getting concrete objects through id
Document document = searcher.doc(docId);
//Title of Output Books
System.out.println(document.get("name"));
}
//Close IndexReader
reader.close();
} catch (ParseException | IOException e) {
e.printStackTrace();
}
}Result
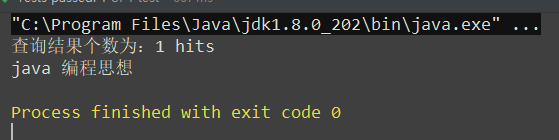
3 participle
We can summarize the process of Lucene participle as follows:
- When partitioning a word, it is based on the domain. Different domains are independent of each other. In the same domain, the same word is separated and treated as the same word (Term). In different domains, the same words are separated, not the same words. Term is Lucene's smallest vocabulary unit and can not be subdivided.
- Word segmentation goes through a series of filters. For example, case conversion, removal of stop words, etc.
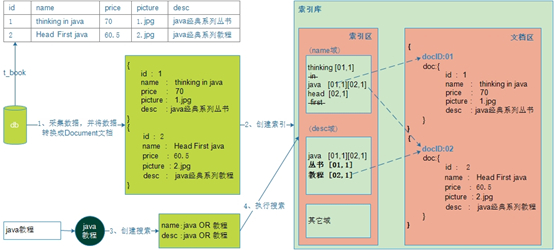
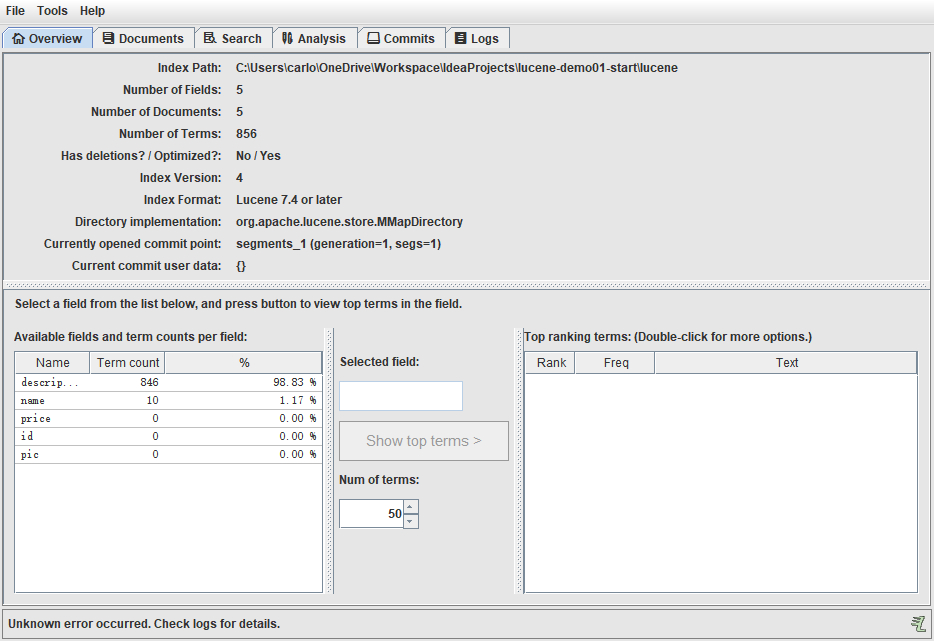
From the picture above, we find that:
- There are two areas in the index database: index area and document area.
- Documents are stored in the document area. Lucene automatically adds a document number docID to each document.
- The index area stores the index. Be careful:
- Index is based on domain, different domains are independent of each other.
- Indexes are created according to word segmentation rules, according to which corresponding documents can be found.
4 Field Domain
We already know that Lucene completes word segmentation and indexing when writing documents. So how does Lucene know how to participle? Lucene determines whether to participle or create an index based on the properties of the domain in the document. So we have to figure out what attributes a domain has.
Attributes of 4.1 Domain
4.1.1 Three attributes
4.1.1.1 Whether or not tokenized
Only when the participle attribute is set to true will lucene participle the domain.
In the actual development, there are some fields that do not need word segmentation, such as commodity id, commodity pictures and so on. And there are some fields that must be participled, such as the name of the product, description information, etc.
4.1.1.2 indexed or not
Only when the index attribute is set to true does lucene create an index for Term words in this field.
In the actual development, there are some fields that do not need to create an index, such as images of goods. We only need to index the fields that participate in the search.
4.1.1.3 Storage or not
Only when the storage property is set to true can the value of this domain be obtained from the document when searching.
In practical development, there are some fields that do not need to be stored. For example: descriptive information of goods. Because commodity description information is usually large text data, it will cause huge IO overhead when it is read. Description information is a field that does not need to be queried frequently, which wastes cpu resources. Therefore, fields like this, which do not need frequent queries and are large text, are not usually stored in index libraries.
4.1.2 Characteristics
- The three attributes are independent of each other.
- Usually word segmentation is to create an index.
- Without storing the text content of the domain, you can also segment and index the domain first.
4.2 Common Types of Field
There are many common types of domains, and each class has its own three default attributes. As follows:
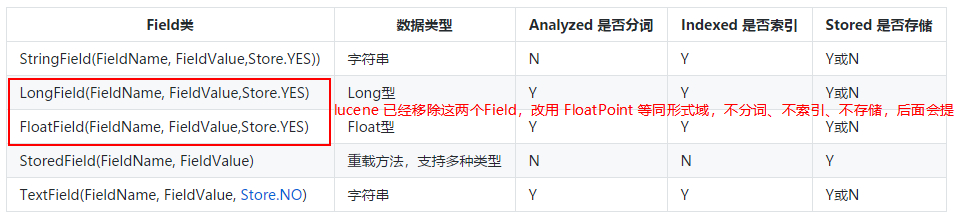
4.3 Modify the domain type in the introductory example
public List<Document> getDocuments(List<Book> books) {
//Create collections
List<Document> documents = new ArrayList<>();
//Loop operation books collection
books.forEach(book -> {
//To create Document objects, you need to set one Field object in Document
Document doc = new Document();
//Create individual fields
//Store but not indexed
Field id = new StoredField("id", book.getId());
//Storage, participle, index
Field name = new TextField("name", book.getName(), Field.Store.YES);
//Store but not indexed
Field price = new StoredField("price", book.getPrice());
//Store but not indexed
Field pic = new StoredField("pic", book.getPic());
//Word segmentation, indexing, but not storage
Field description = new TextField("description", book.getDescription(), Field.Store.NO);
//Add Field to the document
doc.add(id);
doc.add(name);
doc.add(price);
doc.add(pic);
doc.add(description);
documents.add(doc);
});
return documents;
}Result
5 Index Library Maintenance]
5.1 Add Index (Document)
5.1.1 Demand
The new books on the shelves in the database must be added to the index database, otherwise the new books on the shelves can not be searched.
5.1.2 Code Implementation
Call indexWriter.addDocument(doc) to add an index. (Refer to the index creation in the introductory example)
5.2 Delete Index (Document)
5.2.1 Demand
Some books are no longer published and sold. We need to remove them from the index library.
5.2.2 Code Implementation
@Test
public void deleteIndex() throws IOException {
//1. Specify index Library Directory
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//2. Create IndexWriter Config
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
//3. Create IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//4. Delete the specified index
indexWriter.deleteDocuments(new Term("name", "java"));
//5. Close IndexWriter
indexWriter.close();
}5.2.3 Implementing Clear Index Code
@Test
public void deleteAllIndex() throws IOException {
//1. Specify index Library Directory
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//2. Create IndexWriter Config
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
//3. Create IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//4. Delete all indexes
indexWriter.deleteAll();
//5. Close IndexWriter
indexWriter.close();
}5.3 Update Index (Document)
5.3.1 Note
Lucene updating index is special. It first deletes documents that meet the requirements, and then adds new documents.
5.3.2 Code Implementation
@Test
public void updateIndex() throws IOException {
//1. Specify index Library Directory
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//2. Create IndexWriter Config
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
//3. Create IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//4. Create new document objects
Document document = new Document();
document.add(new TextField("name", "testUpdate", Field.Store.YES));
//5. Modify the specified index to a new index
indexWriter.updateDocument(new Term("name", "java"), document);
//6. Close IndexWriter
indexWriter.close();
}6 Search
Question: In the introductory example, we already know that Lucene performs the search through the IndexSearcher object. In actual development, our query business is relatively complex, for example, when we search through keywords, we often filter prices and commodity categories. Lucene provides a set of query schemes for us to implement complex queries.
6.1 Two Ways to Create Queries
Before executing a query, you must create a query Query query object. Query itself is an abstract class and cannot be instantiated. It must be initialized in other ways. Here, Lucene provides two ways to initialize Query query objects.
6.1.1 Use Lucene to provide Query subclasses
Query is an abstract class. lucene provides many query objects, such as TermQuery item exact query, NumericRangeQuery number range query, and so on.
6.1.2 Use Query Parse to parse query expressions
QueryParser parses query expressions entered by users into instances of Query objects. The following code:
QueryParser queryParser = new QueryParser("name", new StandardAnalyzer());
Query query = queryParser.parse("name:lucene");
6.2 Query subclass search
6.2.1 TermQuery
Features: Query keywords will no longer do word segmentation, as a whole to search. The code is as follows:
@Test
public void queryByTermQuery() throws IOException {
Query query = new TermQuery(new Term("name", "java"));
doQuery(query);
}
private void doQuery(Query query) throws IOException {
//Specify index Libraries
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//Create a read stream
DirectoryReader reader = DirectoryReader.open(directory);
//Create an execution search object
IndexSearcher searcher = new IndexSearcher(reader);
//Perform search
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total search results:" + topDocs.totalHits);
//Extracting Document Information
//score is the degree of correlation. That is, the correlation between search keywords and Book names, which is used for sorting.
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
System.out.println("Index library number:" + docId);
//Extracting Document Information
Document doc = searcher.doc(docId);
System.out.println(doc.get("name"));
System.out.println(doc.get("id"));
System.out.println(doc.get("priceValue"));
System.out.println(doc.get("pic"));
System.out.println(doc.get("description"));
//Close the read stream
reader.close();
}
}6.2.2 WildCardQuery
Use wildcards to query
/**
* Query all documents through wildcards
* @throws IOException
*/
@Test
public void queryByWildcardQuery() throws IOException {
Query query = new WildcardQuery(new Term("name", "*"));
doQuery(query);
}
private void doQuery(Query query) throws IOException {
//Specify index Libraries
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//Create a read stream
DirectoryReader reader = DirectoryReader.open(directory);
//Create an execution search object
IndexSearcher searcher = new IndexSearcher(reader);
//Perform search
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total search results:" + topDocs.totalHits);
//Extracting Document Information
//score is the degree of correlation. That is, the correlation between search keywords and Book names, which is used for sorting.
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
System.out.println("Index library number:" + docId);
//Extracting Document Information
Document doc = searcher.doc(docId);
System.out.println(doc.get("name"));
System.out.println(doc.get("id"));
System.out.println(doc.get("priceValue"));
System.out.println(doc.get("pic"));
System.out.println(doc.get("description"));
}
//Close the read stream
reader.close();
}6.2.3 RangeQuery of Digital Type
Specify a numeric range query. (When creating field type, pay attention to its correspondence) Modify the price when indexing.
/**
* Encapsulating Book Collections into Document Collections
* @param books Book aggregate
* @return Document aggregate
*/
public List<Document> getDocuments(List<Book> books) {
//Create collections
List<Document> documents = new ArrayList<>();
//Loop operation books collection
books.forEach(book -> {
//To create Document objects, you need to set one Field object in Document
Document doc = new Document();
//Create individual fields
//Store but not indexed
Field id = new StoredField("id", book.getId());
//Storage, participle, index
Field name = new TextField("name", book.getName(), Field.Store.YES);
//Float Digital Storage and Index
Field price = new FloatPoint("price", book.getPrice()); //Interval queries for numbers, not stored, require additional StoredField
Field priceValue = new StoredField("priceValue", book.getPrice());//Used to store specific prices
//Store but not indexed
Field pic = new StoredField("pic", book.getPic());
//Word segmentation, indexing, but not storage
Field description = new TextField("description", book.getDescription(), Field.Store.NO);
//Add Field to the document
doc.add(id);
doc.add(name);
doc.add(price);
doc.add(priceValue);
doc.add(pic);
doc.add(description);
documents.add(doc);
});
return documents;
}Using the corresponding static method of FloatPoint, RangeQuery is obtained
/**
* Float Type range query
* @throws IOException
*/
@Test
public void queryByNumricRangeQuery() throws IOException {
Query query = FloatPoint.newRangeQuery("price", 60, 80);
doQuery(query);
}
private void doQuery(Query query) throws IOException {
//Specify index Libraries
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//Create a read stream
DirectoryReader reader = DirectoryReader.open(directory);
//Create an execution search object
IndexSearcher searcher = new IndexSearcher(reader);
//Perform search
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total search results:" + topDocs.totalHits);
//Extracting Document Information
//score is the degree of correlation. That is, the correlation between search keywords and Book names, which is used for sorting.
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
System.out.println("Index library number:" + docId);
//Extracting Document Information
Document doc = searcher.doc(docId);
System.out.println(doc.get("name"));
System.out.println(doc.get("id"));
System.out.println(doc.get("priceValue"));
System.out.println(doc.get("pic"));
System.out.println(doc.get("description"));
}
//Close the read stream
reader.close();
}6.2.4 BooleanQuery
Boolean Query, Boolean Query, realizes combination condition query.
@Test
public void queryByBooleanQuery() throws IOException {
Query priceQuery = FloatPoint.newRangeQuery("price", 60, 80);
Query nameQuery = new TermQuery(new Term("name", "java"));
//Create query through Builder
BooleanQuery.Builder booleanQueryBuilder = new BooleanQuery.Builder();
//Occur.MUST at least one time, otherwise the result is empty
booleanQueryBuilder.add(nameQuery, BooleanClause.Occur.MUST_NOT);
booleanQueryBuilder.add(priceQuery, BooleanClause.Occur.MUST);
BooleanQuery query = booleanQueryBuilder.build();
doQuery(query);
}
private void doQuery(Query query) throws IOException {
//Specify index Libraries
Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath());
//Create a read stream
DirectoryReader reader = DirectoryReader.open(directory);
//Create an execution search object
IndexSearcher searcher = new IndexSearcher(reader);
//Perform search
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total search results:" + topDocs.totalHits);
//Extracting Document Information
//score is the degree of correlation. That is, the correlation between search keywords and Book names, which is used for sorting.
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
System.out.println("Index library number:" + docId);
//Extracting Document Information
Document doc = searcher.doc(docId);
System.out.println(doc.get("name"));
System.out.println(doc.get("id"));
System.out.println(doc.get("priceValue"));
System.out.println(doc.get("pic"));
System.out.println(doc.get("description"));
}
//Close the read stream
reader.close();
}6.3 Search through Query Parser
6.3.1 Characteristics
For the search keywords, do word segmentation.
6.3.2 Grammar
6.3.2.1 Basic Grammar
Domain name: keywords such as: name:java
6.3.2.2 Combinatorial Conditional Grammar
- Conditions 1 AND Conditions 2
- Conditions 1 OR Conditions 2
- Conditions 1 NOT Conditions 2
For example: Query query = queryParser.parse("java NOT edition");
6.3.3 QueryParser
@Test
public void queryByQueryParser() throws IOException, ParseException {
//Create a Word Segmenter
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
/**
* Create a query parser
* Parametric 1: The default search domain.
* If the search domain is not specifically specified at the time of the search, the search is performed according to the default domain.
* How to specify the search domain: domain name: keywords such as: name:java
* Parametric 2: Word Segmenter, Word Segmentation for Key Words
*/
QueryParser queryParser = new QueryParser("description", standardAnalyzer);
Query query = queryParser.parse("java Course");
doQuery(query);
}6.3.4 MultiFieldQueryParser
Query multiple domains through MulitField Query Parse.
@Test
public void queryByMultiFieldQueryParser() throws ParseException, IOException {
//1. Define multiple search domains
String[] fields = {"name", "description"};
//2. Loading Word Segmenter
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
//3. Create MultiFieldQueryParser instance object
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(fields, standardAnalyzer);
Query query = multiFieldQueryParser.parse("java");
doQuery(query);
}7 Chinese Word Segmenter
7.1 What is a Chinese Word Segmenter
Everyone who has studied English knows that English is based on words, separated by spaces or commas. Standard word segmenter can not be divided by words as in English, but can only be divided into one Chinese character and one Chinese character. So we need a word segmenter which can recognize Chinese semantics automatically.
7.2 Lucene's Chinese Word Segmenter
7.2.1 StandardAnalyzer:
Word segmentation: Word segmentation is based on Chinese word by word. For example: "I love China"
Effect: "I", "Love", "China" and "Country".
7.2.2 CJKAnalyzer
Dichotomy: Segmentation by two words. For example, "I am Chinese."
Effect: I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, I am, and I am Chinese.
7.2.3 SmartChineseAnalyzer
Intelligent Chinese Recognition Officially Provided, Need to Import New jar Packet
@Test
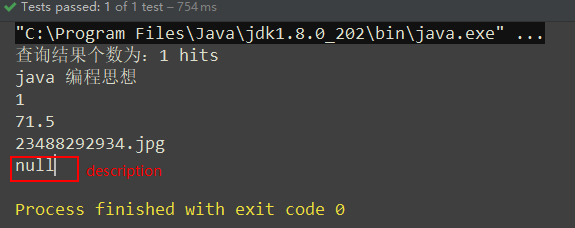
public void createIndexByChinese () {
BookDao dao = new BookDao();
//The Segmenter is used for Chinese Word Segmentation
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();
//Create an index
//1. Create Index Inventory Catalogue
try (Directory directory = FSDirectory.open(new File("C:\\Users\\carlo\\OneDrive\\Workspace\\IdeaProjects\\lucene-demo01-start\\lucene").toPath())) {
//2. Create IndexWriterConfig objects
IndexWriterConfig ifc = new IndexWriterConfig(smartChineseAnalyzer);
//3. Create IndexWriter objects
IndexWriter indexWriter = new IndexWriter(directory, ifc);
//4. Adding documents through IndexWriter objects
indexWriter.addDocuments(dao.getDocuments(dao.listAll()));
//5. Close IndexWriter
indexWriter.close();
System.out.println("Complete index library creation");
} catch (IOException e) {
e.printStackTrace();
}
}The effect is as follows: