1, Integrated learning
Ensemble learning is a method to combine multiple weak machine learners to build a machine learner with strong performance, that is, to complete the learning task by constructing and merging multiple learners. The weak learners constituting ensemble learning are called base learners and base estimators.
1. According to whether the types of each base estimator of ensemble learning are the same, it can be divided into homogeneous and heterogeneous.
Homogeneity: it means that all individual learners are of the same type.
Heterogeneous: individual learners contain different types of learning algorithms.
2. According to the generation of individual learners, ensemble learning methods can be divided into two categories: boosting and bagging
boosting: it is characterized by the dependency between weak learners.
bagging: it is characterized by no dependency between weak learners and can be fitted in parallel.
2, Common methods of integrated learning
1,Bagging
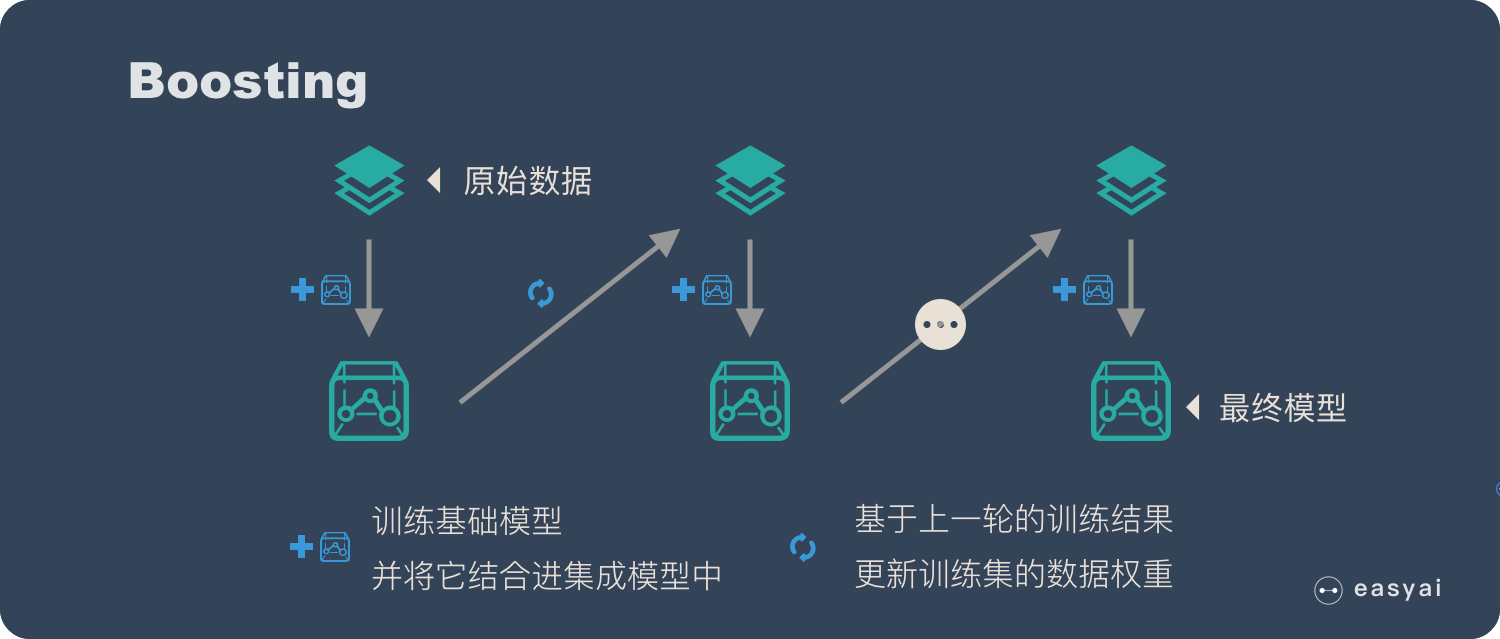
(1) Bagging algorithm process:
The input is sample set D={(x,y1),(x2,y2),...(xm,ym)}, weak learner algorithm, weak classifier iteration times T.
The output is the final strong classifier f(x)
For t = 1,2, T:
a) The training set is randomly sampled t times, and the probability of each sample being sampled is 1/m. A total of M times are collected to obtain the sampling set Dm containing m samples
b) Training the m-th weak learner Gm(x) with the sampling set Dm
If it is predicted by the classification algorithm, the category or one of the categories with the most votes cast by T weak learners is the final category. If it is a regression algorithm, the regression results obtained by T weak learners are arithmetically averaged, and the value obtained is the final model output.
(2) In scikit learn, the Bagging method uses a unified classifier estimator BaggingClassifier or regression estimator BaggingRegressor. The input parameters and random subset extraction strategy can be specified. The parameter that controls the subset size (for swatches and features) is max_samples and max_features, bootstrap and bootstrap_features controls whether samples and features are put back or not.
(3) Integrated learning using BaggingClassifier()
# SVM
import numpy as np
from sklearn import svm,datasets
import matplotlib.pyplot as plt
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
kernel='poly'
clf_svm=svm.SVC(kernel=kernel,gamma=2) # Set model parameters
clf_svm.fit(X_train,y_train)
y_svm_pred=clf_svm.predict(X_test)
svm_wrong_num=len(y[np.where(y_svm_pred!=y_test)])
print('SVM The number of samples with prediction errors is:',svm_wrong_num)
# The support vector machine is used as the basis estimator and Bagging is used for prediction
clf_bagging=BaggingClassifier(svm.SVC(kernel=kernel,gamma=2))
clf_bagging.fit(X_train,y_train)
y_bag_pred=clf_bagging.predict(X_test)
bag_wrong_num=len(y[np.where(y_bag_pred!=y_test)])
print('Bagging The number of samples with prediction errors is:',bag_wrong_num)
We can see from the above that the number of samples with prediction errors in the test using support vector machine is 52. Using Bagging ensemble learning, the number of samples with prediction errors is reduced to 38, indicating that the classification effect of Bagging ensemble learning has been improved to a certain extent.
2. Random forest
(1) Random forest is an improvement of bagging algorithm. Its idea is still bagging, but it has made a unique improvement.
Random forest uses CART decision tree as weak learner, which reminds us of gradient lifting tree GBDT. Second, based on the decision tree, RF improves the establishment of the decision tree. For an ordinary decision tree, we will select an optimal feature from all n sample features on the node to divide the left and right subtrees of the decision tree. However, RF randomly selects some sample features on the node. This number is less than N and is assumed to be n, Then, among these randomly selected n sample features, select an optimal feature to divide the left and right subtrees of the decision tree, which further enhances the generalization ability of the model.
(2) The ensemble module of scikit learn provides RandomForestClassifier classification and RandomForestRegression regression.
(3) Ensemble learning using random forest
import numpy as np
from sklearn import tree,datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
clf_tree=tree.DecisionTreeClassifier(criterion='gini',max_depth=3)
clf_tree.fit(X_train,y_train)
y_tree_pred=clf_tree.predict(X_test)
tree_wrong_num=len(y[np.where(y_tree_pred!=y_test)])
print('The sample number of decision tree prediction errors is:',tree_wrong_num)
# Random forest
clf_rfc=RandomForestClassifier(n_estimators=50,criterion='gini',
max_depth=3,random_state=0)
clf_rfc.fit(X_train,y_train)
y_rfc_pred=clf_rfc.predict(X_test)
rfc_wrong_num=len(y[np.where(y_rfc_pred!=y_test)])
print('The sample number of random forest prediction errors is:',rfc_wrong_num) From the above, we can know that the number of prediction error samples of a single decision tree is 54, and the number of prediction error samples after using random forest is 43, which is lower than that of a single decision, indicating that the integrated learning of random forest improves the classification performance of the data set.
From the above, we can know that the number of prediction error samples of a single decision tree is 54, and the number of prediction error samples after using random forest is 43, which is lower than that of a single decision, indicating that the integrated learning of random forest improves the classification performance of the data set.
3,AdaBoost
(1) Adaboost is an iterative algorithm. Its core idea is to train different classifiers (weak classifiers) for the same training set, and then collect these weak classifiers to form a stronger final classifier (strong classifier). In theory, any learner can be used for Adaboost But generally speaking, the most widely used Adaboost weak learners are decision trees and neural networks. For decision tree, Adaboost classification uses CART classification tree, while Adaboost regression uses CART regression tree.
(2) Scikit learn's ensemble module provides AdaBoost classifier classification and AdaBoost regression.
(3) Integrated learning using Adaboost
import numpy as np
from sklearn import datasets
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
adaboost=AdaBoostClassifier(base_estimator=tree.DecisionTreeClassifier(max_depth=3))
adaboost.fit(X_train,y_train)
y_adaboost_pred=adaboost.predict(X_test)
adaboost_wrong_num=len(y[np.where(y_adaboost_pred!=y_test)])
print('adaboost The number of samples with prediction errors is:',adaboost_wrong_num)
4. Gradient Tree Boosting (GBDT)
(1) GBDT(Gradient Boosting Decision Tree), also known as MART (Multiple Additive Regression Tree), is an iterative decision tree algorithm. The algorithm is composed of multiple decision trees, and the conclusions of all trees are accumulated to make the final answer. It is considered as a generalization algorithm with strong generalization ability together with SVM at the beginning of being proposed.
(2) In the ensemble module of scikit learn, the classification gradientboosting classifier () of GBDT and the regression gradientboosting regressor () of GBDT are provided. The parameter types of the two are exactly the same, but the optional items of some parameters, such as loss function loss, are different.
(3) Integrated learning using GBDT
import numpy as np
from sklearn import datasets
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
gboost=GradientBoostingClassifier()
gboost.fit(X_train,y_train)
print('Gradient Tree Boost The average accuracy of the classifier in predicting the prediction set is:\n',gboost.score(X_test,y_test))
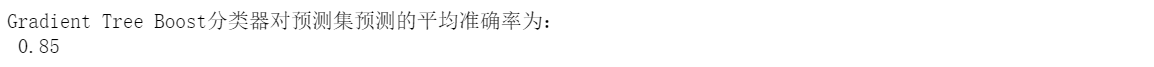
5,XGBoost
(1)XGBoost is an optimized distributed gradient enhancement library. It has the characteristics of efficient, flexible and portable design. It implements the machine learning algorithm under the gradient enhancement framework.
(2)XGBoost provides a special API for scikit learn, but scikit learn does not come with XGBoost. To use XGBoost, you need to use the pip command to install:
pip install xgboost
(3) Integrated learning using XGBoost
from xgboost import XGBClassifier
import xgboost as xgb
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
X,y=datasets.make_classification(n_samples=1000,n_features=10,
n_informative=5,n_redundant=2,
n_classes=3,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
xgboost=XGBClassifier()
xgboost.fit(X_train,y_train)
y_xgboost_pred=xgboost.predict(X_test)
xgboost_wrong_num=len(y[np.where(y_xgboost_pred!=y_test)])
print('XGBoost The number of samples in which the classifier predicts the test set incorrectly is:',xgboost_wrong_num)
III. examples (dataset digits)
Use the dataset digits of scikit learn's datasets module, and use Bagging, AdaBoost, XGBoost and GradientBoosting integrated learning methods to classify them.
from sklearn.ensemble import BaggingClassifier,RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier,GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn import tree,datasets
import numpy as np
from sklearn.model_selection import train_test_split
digits=datasets.load_digits()
X=digits.data
y=digits.target
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)
d_tree=tree.DecisionTreeClassifier()
bagging=BaggingClassifier(base_estimator=tree.DecisionTreeClassifier())
r_forest=RandomForestClassifier()
adaboost=AdaBoostClassifier(base_estimator=tree.DecisionTreeClassifier())
gboost=GradientBoostingClassifier()
xgboost=XGBClassifier()
model_name=['Bagging','Random forest','AdaBoost','XGBoost','Decision tree']
models={bagging,r_forest,adaboost,gboost,xgboost,d_tree}
import time
for name_idx,model in zip([0,1,2,3,4],models):
start=time.perf_counter()
model.fit(X_train,y_train)
end=time.perf_counter()
print(model_name[name_idx],'The model fitting time is:',end-start)
y_pred=model.predict(X_test)
wrong_pred_num=len(y[np.where(y_pred!=y_test)])
print(model_name[name_idx],'The number of samples with prediction errors is:',wrong_pred_num)
time.sleep(2)The operation result is:
Bagging Model fitting time: 0.301932599999418 Bagging The number of samples with prediction errors is: 10 The fitting time of random forest model is: 0.7709702000011021 The sample number of random forest prediction error is: 11 AdaBoost Model fitting time: 0.08479459999944083 AdaBoost Number of samples with prediction errors: 57 XGBoost Model fitting time: 0.05042159999902651 XGBoost The number of samples with prediction errors is 54 The fitting time of decision tree model is 8.682290799999464 The sample number of decision tree prediction errors is: 11
It can be seen from the results that Bagging has the least number of prediction error samples, followed by random forest and decision tree.
From the time used to fit the model, AdaBoost takes the shortest time, but the accuracy is the lowest, indicating that AdaBoost is not suitable for the classification of digits in this data set.